1.树的存储结构
和线性表一样,树可以用顺序和链式两种存储结构。
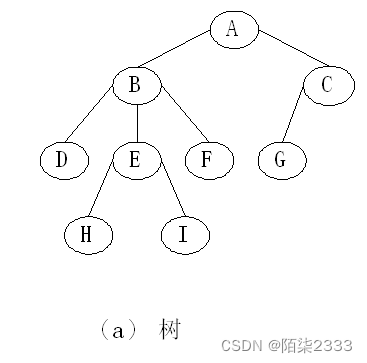
树的顺序存储结构适合树中结点比较“满”的情况。根据树的非线性结构特点,常用链式存储方式来表示树。树常用的存储方法有:双亲表示法、孩子表示法和孩子兄弟表示法。
1.双亲存储表示法
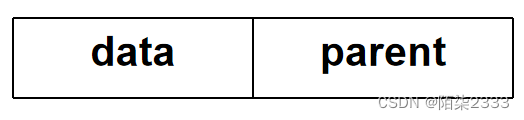
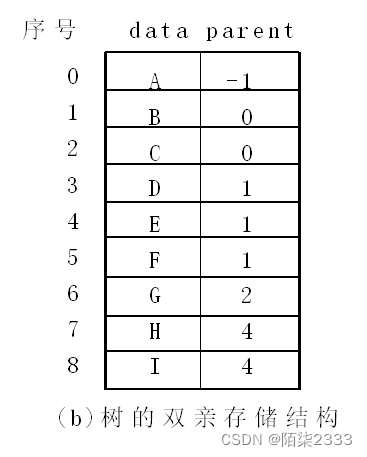
用一维数组来存放一棵树的所有结点,每个结点除了存放本身信息外,还要存放其双亲在数组中的位置。 每个结点有两个域:
data---存放结点的信息;
parent---存放该结点双亲在数组中的位置
特点:求结点的双亲很容易,但求结点的孩子需要遍历整个向量。
存储结构:
//存储结构
#define MaxTreeSize 100 /* 定义数组空间的大小*/
#define ElemType int /* ElemType表示树中结点的数据类型,这里为int */
typedef struct PTreeNode
{ ElemType data; /* 结点数据 */int parent; /* 双亲指示器,指示结点的双亲在数组中的位置 */
} PTreeNode;
typedef struct PTree
{ PTreeNode nodes[MaxTreeSize]; int r,n; /* r表示根结点在数组中的位置,n表示树中结点总数*/
} Ptree;
查找双亲:
//查找双亲
int NodeLocate(PTree *t, ElemType e)/* 在树中查找结点e ,返回其在数组中的位置*/
{ int i = 0; /* 在链表中查找结点e */ while (i<t -> n && t->nodes[i].data != e) i++; if (i < t-> n) return i;else return (-1);
}
ElemType ParentLocate (PTree *t, ElemType e)
{ int i;i = NodeLocat(t, e); /* 查找结点e在数组中的位置 */if(i == -1) /* 树中无此结点 */{ printf("no this node!"); return 0; }else if(t->nodes[i].parent==-1) /* 结点e是树的根结点 */ { printf("this is the root, no parent!"); return 0; }else /* 返回结点e的双亲*/return( t->nodes[nodes[i].parent].data );
}
2.孩子链表表示法
这是树的链式存储结构。每个结点的孩子用单链表存储,称为孩子链表。
n个结点可以有n个孩子链表(叶结点的孩子链表为空表)。
n个孩子链表的头指针用一个向量表示。
特点:与双亲相反,求孩子易,求双亲难。

存储结构:
#define ElemType char /* ElemType 是树结点元素类型,这里定义为char*/
#define MaxTreeSize 20
typedef struct CTNode /* 孩子链表中的结点结构 */
{ int child; /* child域存放结点在一维数组中的位置 */struct CTNode *next;
}*ChildPtr; /* ChildPtr为指向孩子结点的指针 */
typedef struct /* 指向孩子链表结点的头指针结构 */
{ ElemType data; /* data域存放结点的本身信息*/ChildPtr firstchild; /* firstchild域存放第一个孩子的指针*/
}CTBox;
typedef struct /* 孩子链表结构 */
{ CTBox nodes[MaxTreeSize];int n, r; /*n域存放树的结点数,r域存放根结点的位置*/
} CTree;
可以把双亲表示法和孩子链表表示法结合起来。
相应地上述指向孩子链表结点的头指针结构修改如下:
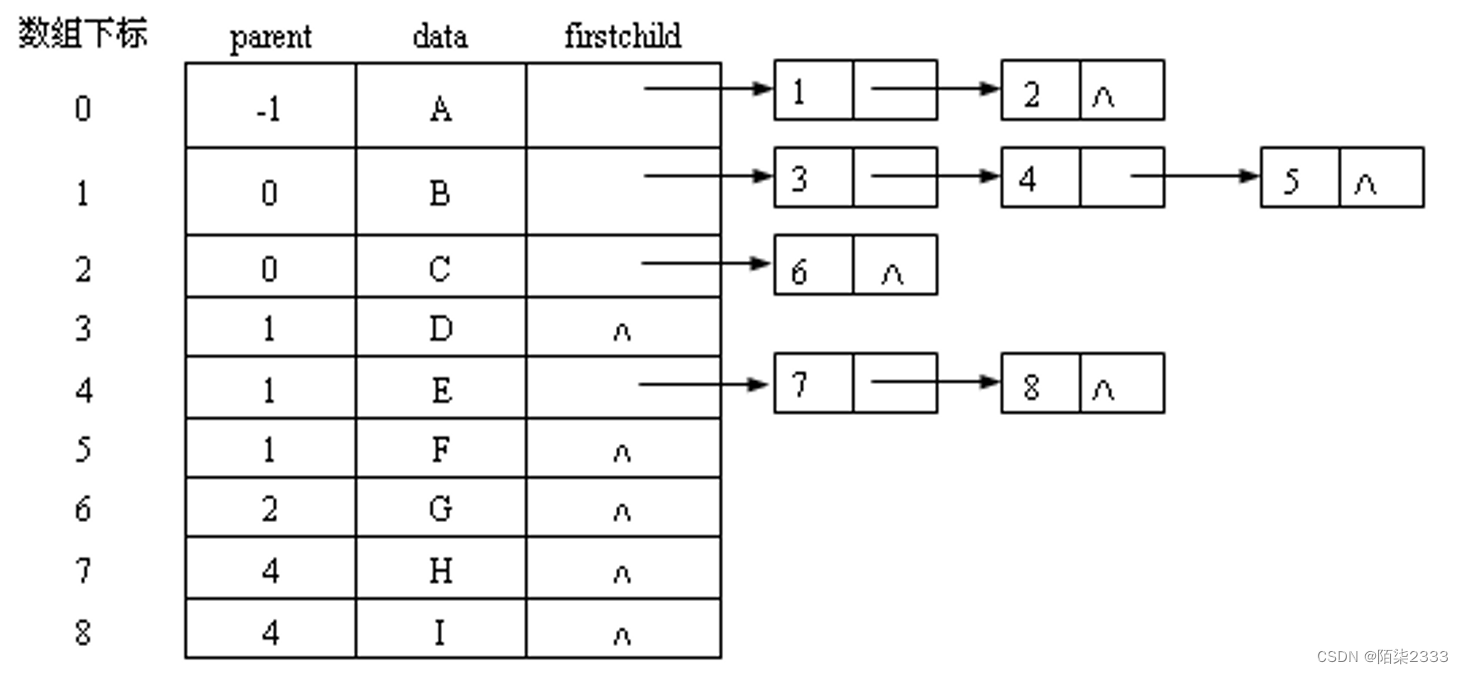
3.孩子兄弟表示法
用二叉链表作为树的存储结构,每个结点的左链域指向该结点的第一个孩子,右链域指向下一个兄弟结点。
由于结点中的两个指针指示的分别为“孩子”和“兄弟”,故称为“孩子-兄弟链表”。这种结构也称为二叉链表。
特点:双亲只管长子 长子连接兄弟

存储结构:
typedef struct CSNode
{ ElemType data;struct CSNode *firstchild, *nextsibling;
}CSNode;
孩子兄弟存储结构的最大优点是可以方便地实现树和二叉树的相互转换和树的各种操作。如果在结点中增设一个parent域,那么查找结点的双亲也很方便。
2.森林的存储结构
1、森林的定义
零棵或有限棵互不相交的树的集合称为森林。
2、森林的存储结构
双亲表示法、孩子表示法和孩子兄弟表示法。
(1)森林的双亲表示法。
和树的双亲表示法一样,用一个一维数组A来存储森林,每个元素有两个域:结点的数据和其双亲在数组的位置。只是其中有多个元素的双亲域值为-1,它们对应于森林各棵树的根结点。在具体存储时,可用增设一个一维数组B存储各棵树的树根在数组A中的位置。
(2)森林的孩子表示法。
它将森林中每个结点的孩子用单链表连接起来,再用一大小为n(结点个数)的一维数组A存储每个结点信息,包括结点本身的数据信息和指向第一个孩子的指针。孩子结点有两个域:数据域为此结点在一维数组中位置,指针域为指向下一个兄弟(即结点双亲的下一个孩子)的指针。具体存储时也可以增设一个一维数组B存储各棵树的树根在数组A中的位置。
(3)森林的孩子兄弟表示法。
此表示法以二叉链表作为树的存储结构,链表中的两个链域firstchild和nextsibling分别指向此结点的第一个孩子结点和下一个兄弟结点。这时,可将森林中各棵树的树根看成是兄弟,因此,在存储时,将森林中第二棵树树根作为第一棵树树根的兄弟,即第一棵树树根的nextsibling指向第二棵树树根,如此下去。
3.树和森林的基本操作
1.树和森林与二叉树的相互转换
树与二叉树均可用二叉链表作为存储结构,因此给定一棵树,用二叉链表存储,可唯一对应一棵二叉树,反之亦然。
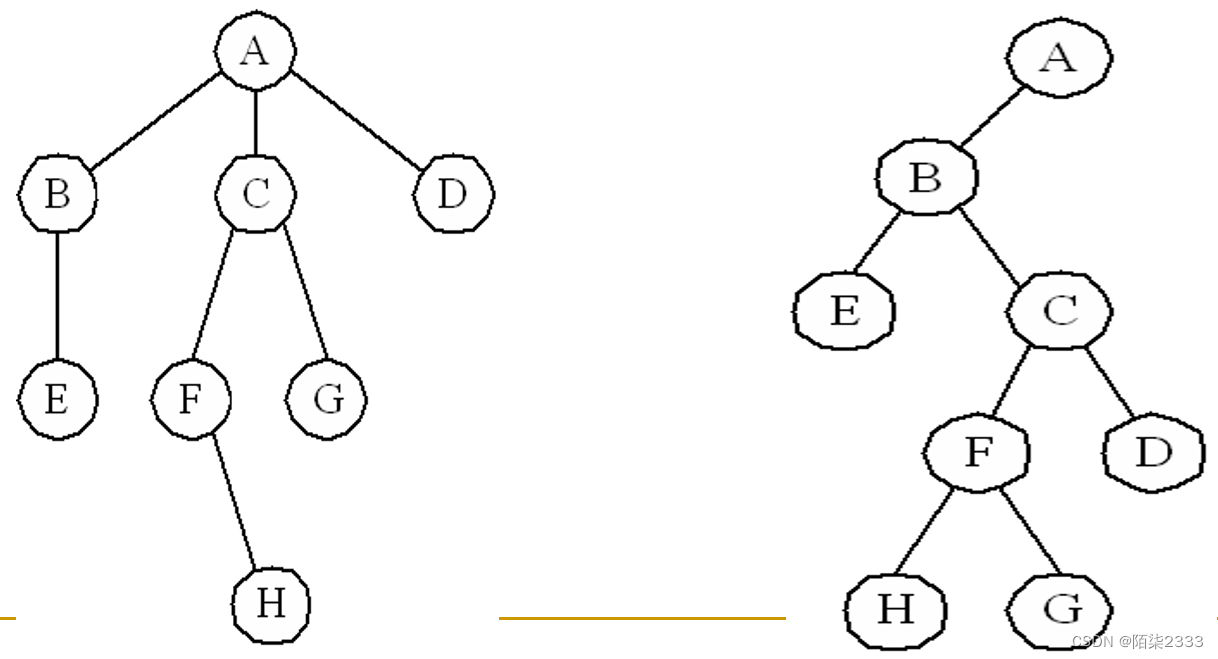
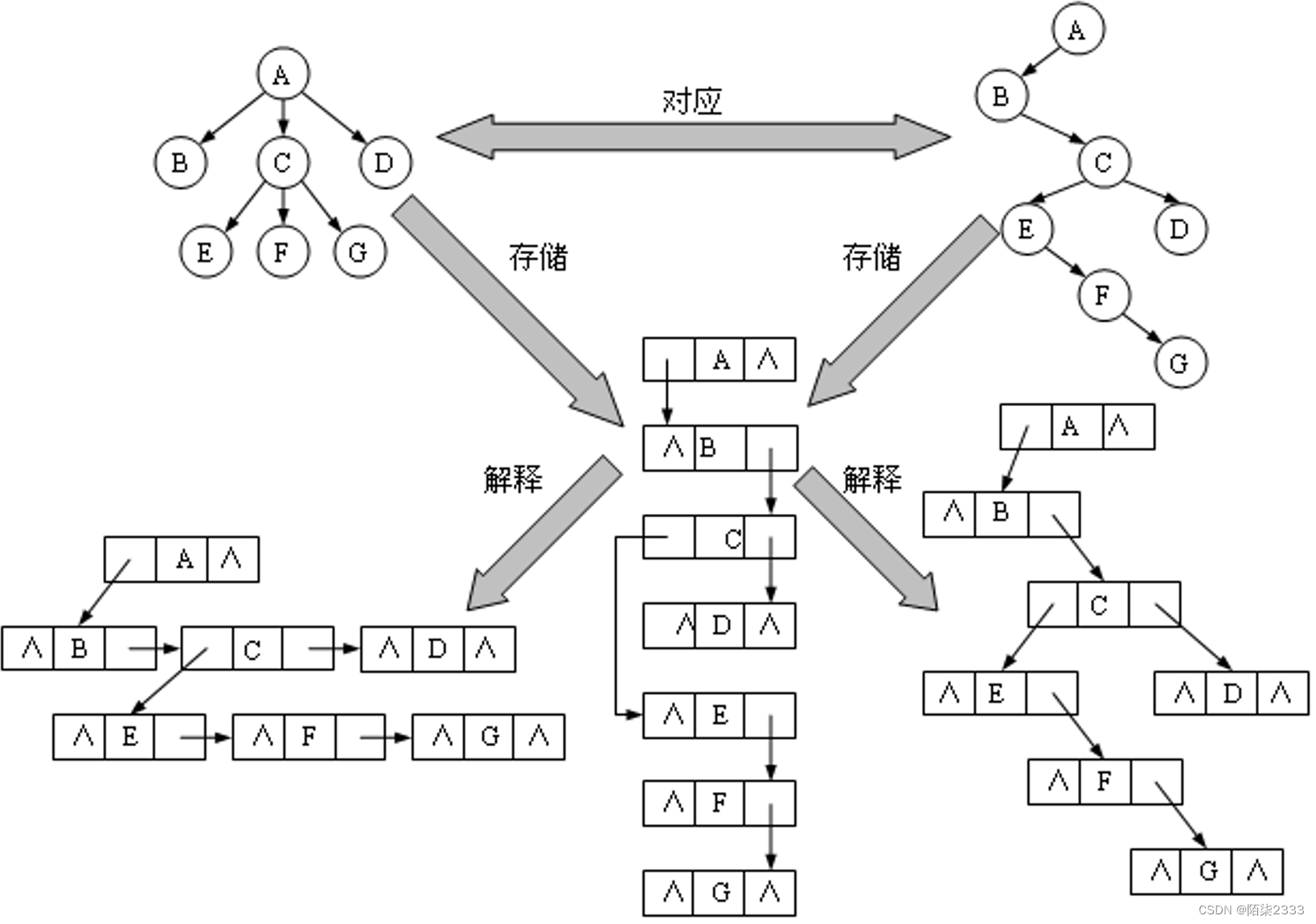
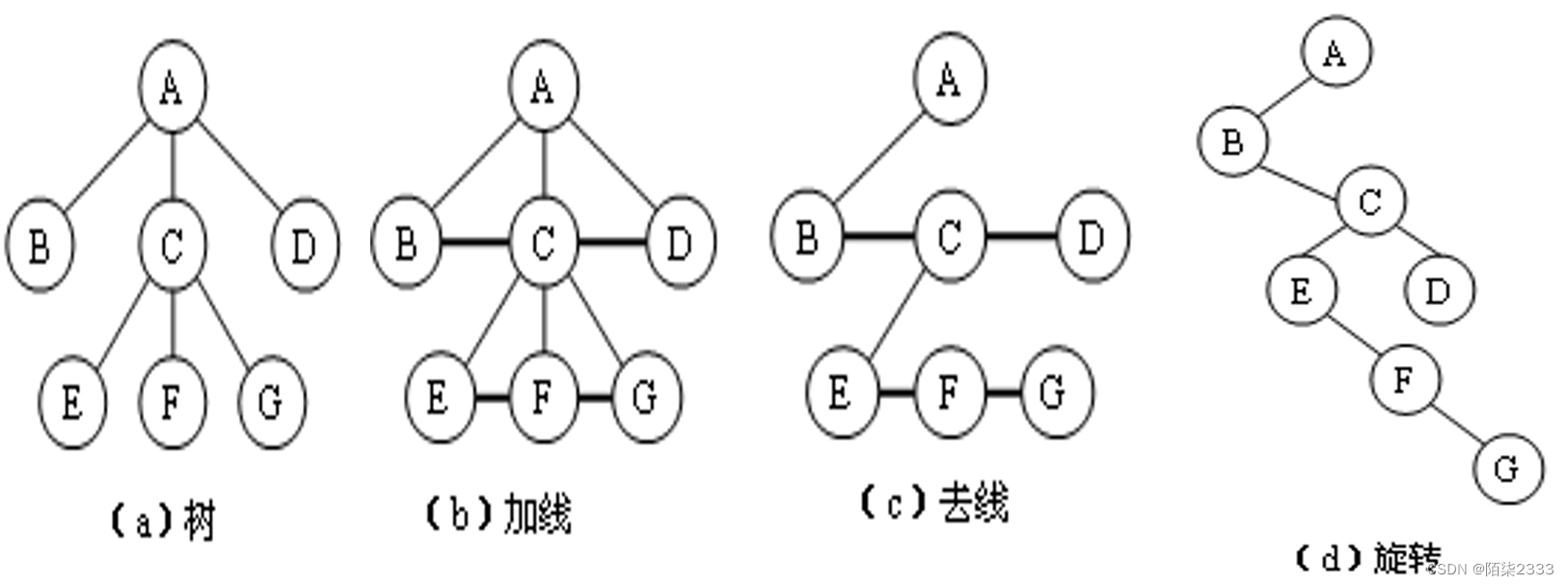
1) 树转换为二叉树
转换方法是:
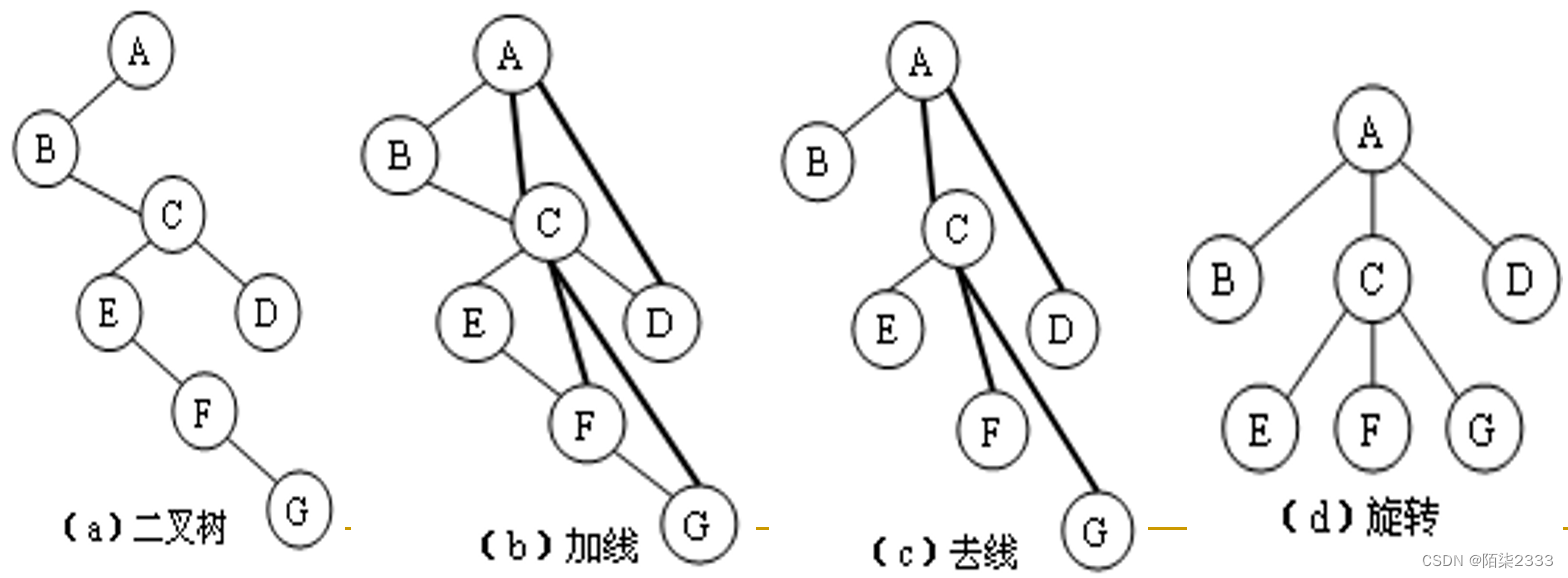
①加线:在树中各兄弟(堂兄弟除外)之间加一根连线。
②去线:对树中的每个结点,只保留其与第一个孩子结点之间的连线,删去其与其它孩子结点之间的连线。
③旋转:以树的根结点为轴心,将整棵树顺时针旋转一定的角度,使之结构层次分明。
特点:根无右子树
可以证明,树做这样的转换所构成的二叉树是唯一的。 下图给出了将这棵树树转换为二叉树的转换过程示意。
反过来,要将一棵二叉树转换为树,也是经过三步:
① 加线:将树中的每个结点和其左孩子结点的右孩子以及右孩子的右孩子加线相连。
② 去线:去掉树中的每个结点和右孩子的连线。
③ 旋转:以树的根结点为轴心,将整棵树逆时针旋转一定的角度,使之结构层次分明,就得到旋转后的树。
2)森林与二叉树的相互转换
一棵树转换为一棵二叉树后,其根结点的右子树为空。
在二叉树转换为树时,所取二叉树的根结点的右子树也为空。
如果二叉树根结点的右子树不空,根据前面的转换可知,二叉树中结点的右孩子是结点的兄弟。
那么对于根结点有右孩子的二叉树,根结点的右孩子以及右孩子的右孩子都是兄弟,这时,转换出来的结果就是森林。
反过来,森林将转换成根结点有右子树的二叉树。
森林与二叉树的相互转换还是采用加线、去线、旋转的规则进行转换,转换过程和树与二叉树的相互转换规则类似。
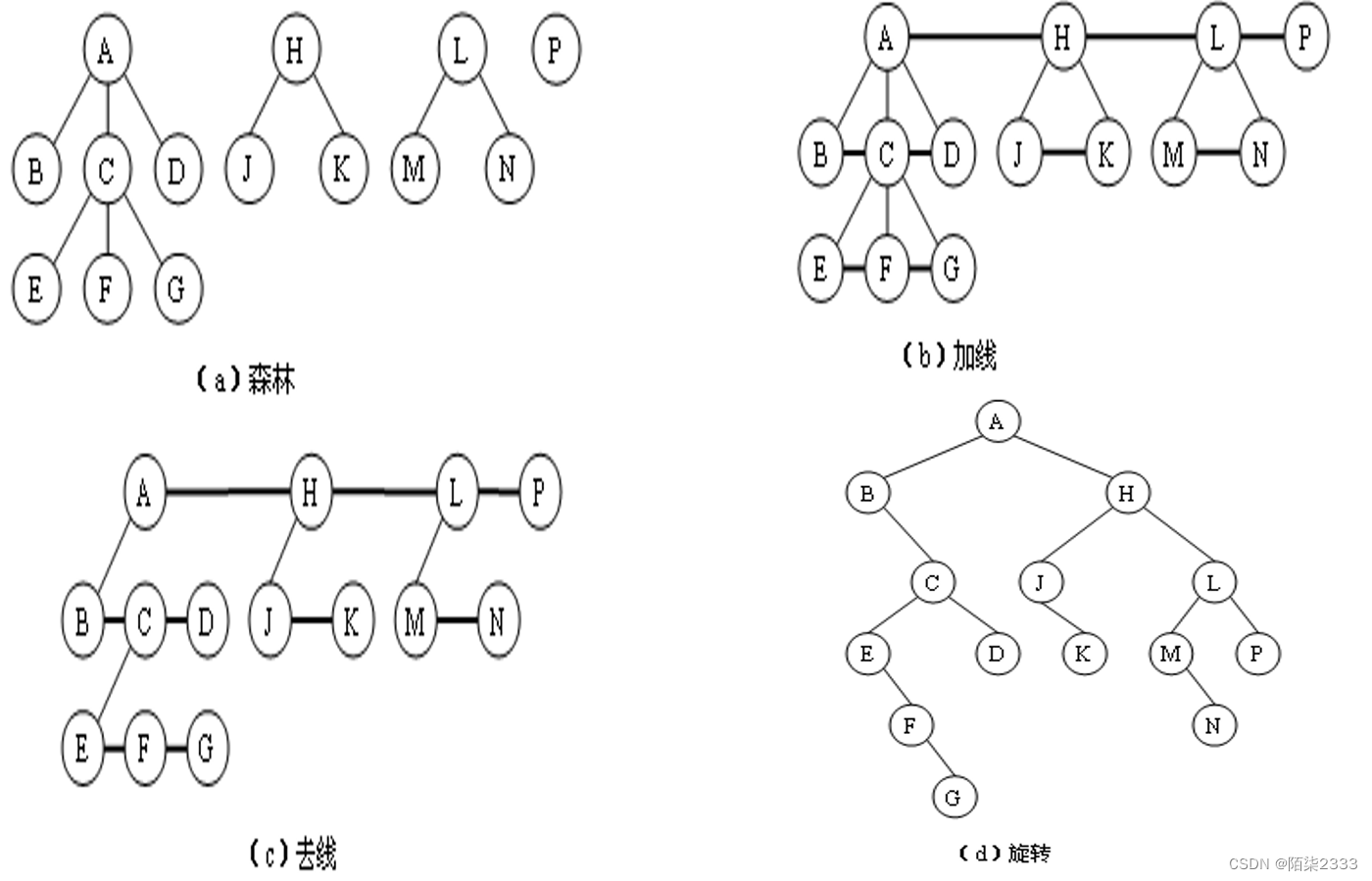
森林转换为二叉树:
森林是若干棵树的集合。
树可以转换为二叉树, 森林同样也可以转换为二叉树。 因此,森林也可以方便地用孩子兄弟链表表示。森林转换为二叉树的方法如下:
(1) 将森林中的每棵树转换成相应的二叉树。
(2)第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树根结点的右孩子, 当所有二叉树连在一起后,所得到的二叉树就是由森林转换得到的二叉树。

二叉树还原为树或森林:
树和森林都可以转换为二叉树,二者的不同是:
树转换成的二叉树, 其根结点必然无右孩子。
而森林转换后的二叉树,其根结点有右孩子。
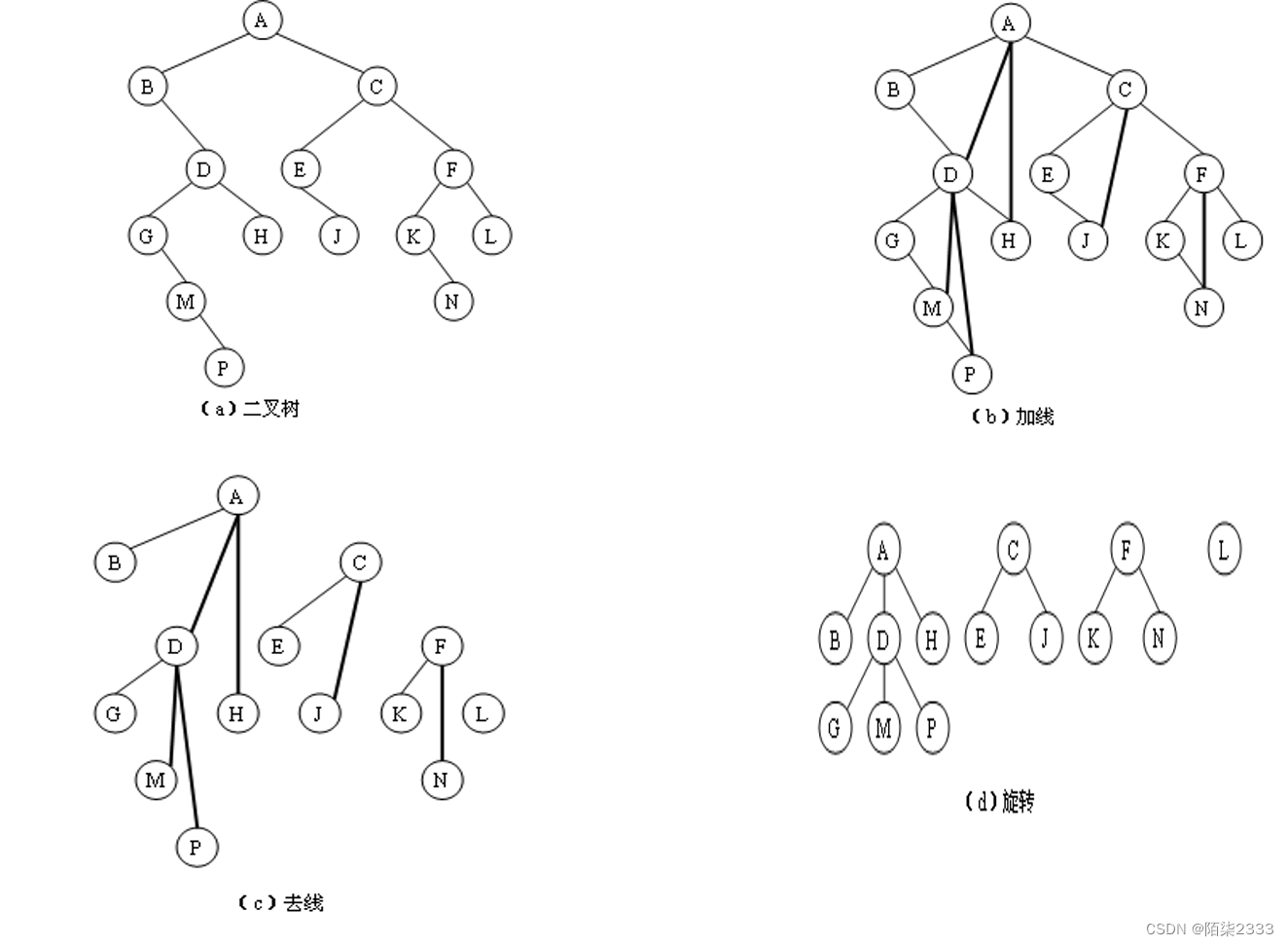
将一棵二叉树还原为树或森林,具体方法如下:
(1) 若某结点是其双亲的左孩子,则把该结点的右孩子、 右孩子的右孩子……都与该结点的双亲结点用线连起来。
(2) 删掉原二叉树中所有双亲结点与右孩子结点的连线。
(3) 整理由(1)、(2)两步所得到的树或森林, 使之结构层次分明。

2、树和森林的遍历
(1)树的遍历
① 先序(根)遍历:访问树的根结点,再依次先序遍历根的每棵子树(从左到右)。
② 后序(根)遍历:依次后序遍历根的每棵子树(从左到右),最后访问根结点。
③ 层次遍历:从上到下、从左至右访问树的每一个结点。
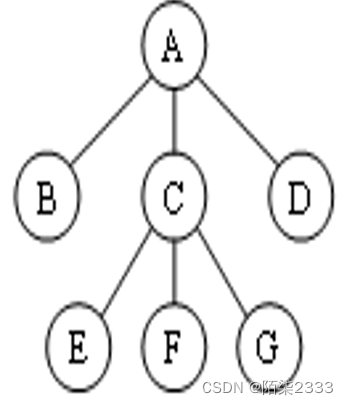
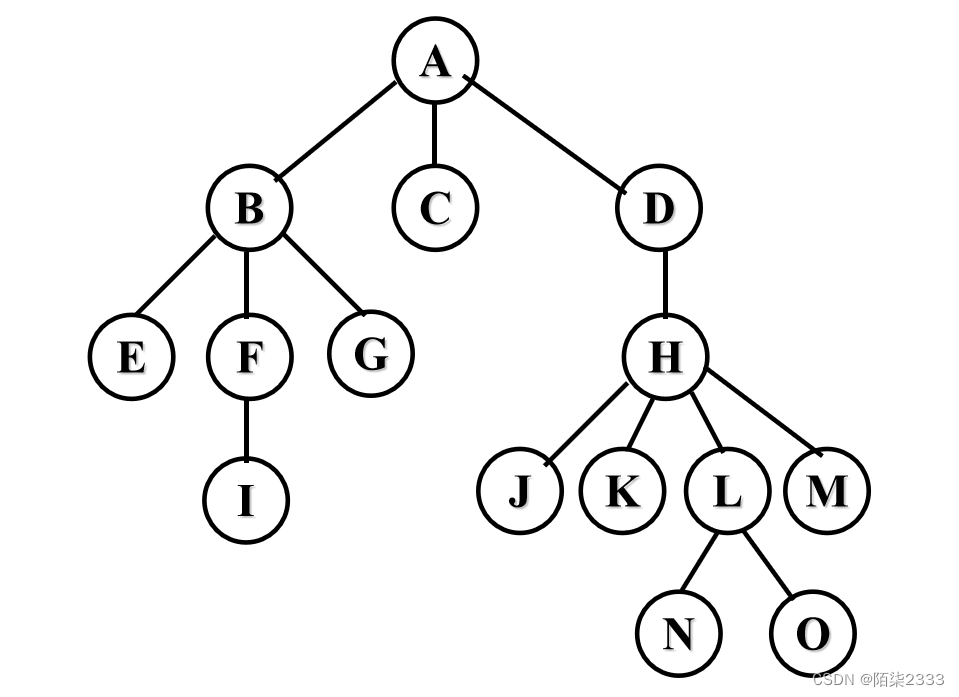
先序遍历序列为ABCEFGD
后序遍历序列为BEFGCDA
层次遍历序列为ABCDEFG
当以二叉链表作为树的存储结构时,树的先根遍历和后根遍历分别对应二叉树的先序遍历和中序遍历算法。
结论:
①树后序遍历相当于对应二叉树的中序遍历;
②树没有中序遍历,因为子树无左右之分。
练习:写出下面树的先根,后根和按层次遍历序列。

(2)森林的遍历
① 先序遍历。若森林非空,按下述规则遍历:
访问森林中第一棵树的根结点。
先序遍历第一棵树根结点的子树森林。
先序遍历除去第一棵树后剩余树构成的森林。
② 后序遍历。若森林非空,按下述规则遍历:
后序遍历森林中第一棵树根结点的子树森林。
访问第一棵树的根结点。
后序遍历除去第一棵树后剩余树构成的森林。
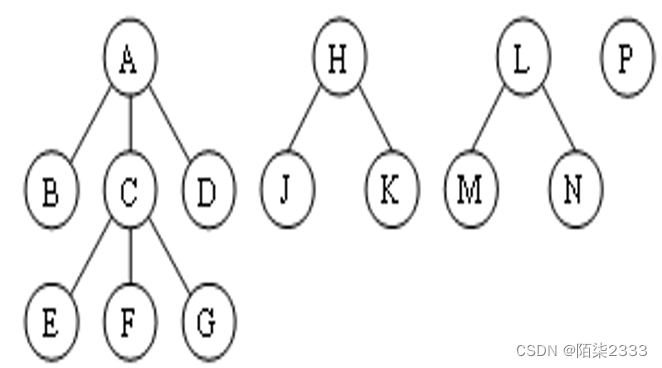

由森林转换成二叉树时,其第一棵树的子树森林转换成左子树,剩余树构成的森林转换成右子树。因此,森林的先序遍历和后序遍历即为其对应二叉树的先序遍历序列和中序遍历序列。
4.哈夫曼树
最优二叉树,也称哈夫曼(Haffman)树,是指对于一组带有确定权值的叶结点,构造的具有最小带权路径长度的二叉树。
1. 路径和路径长度
路径是指从一个结点到另一个结点之间的分支序列
路径长度是指从一个结点到另一个结点所经过的分支数目
树的路径长度PL定义为: 从树根到每一个结点的路径长度之和。
2. 结点的权和带权路径长度
在实际的应用中,人们常常给树的每个结点赋予一个具有某种实际意义的实数,我们称该实数为这个结点的权。
在树形结构中,我们把从树根到某一结点的路径长度与该结点的权的乘积,叫做该结点的带权路径长度。
3. 树的带权路径长度
树的带权路径长度为树中所有叶子结点的带权路径长度之和,通常记为

其中n为叶子结点的个数,wi为第i个叶子结点的权值,li为第i个叶子结点的路径长度。

WPL(a)=7×2+5×2+2×2+4×2=36
WPL(b)=4×2+7×3+5×3+2×1=46
WPL(c)=7×1+5×2+2×3+4×3=35
一棵树的路径长度为0, 结点至多只有1个(根);
路径长度为1, 结点至多只有2个(两个孩子);
路径长度为2, 结点至多只有4个;
依此类推,路径长度为k, 结点至多只有2k个, 所以n个结点二叉树其路径长度至少等于如图所示序列的前n项之和。
4.构造哈夫曼算法的步骤
(1) 用给定的n个权值{w1, w2, …, wn}对应的n个结点构成n棵二叉树的森林F={T1, T2, …, Tn},其中每一棵二叉树Ti(1≤i≤n)都只有一个权值为wi的根结点,其左、右子树为空。
(2) 在森林F中选择两棵根结点权值最小的二叉树,作为一棵新二叉树的左、右子树,标记新二叉树的根结点权值为其左右子树的根结点权值之和。
(3) 从F中删除被选中的那两棵二叉树, 同时把新构成的二叉树加入到森林F中。
(4) 重复(2)、(3)操作, 直到森林中只含有一棵二叉树为止, 此时得到的这棵二叉树就是哈夫曼树。
5.哈夫曼编码算法
根据哈夫曼树的构造过程可知,哈夫曼树中没有度为1的结点,因此,一棵具有n个叶子结点的哈夫曼树共有2n-1个结点,可以把它们存储在一个大小为2n-1的一维数组中。为了在编码、译码时能立即找到它的双亲和孩子,同时,在建立哈夫曼树时,需要选择权值最小的两棵树,因此,每个结点还需要有结点的权重信息、双亲和左右孩子信息。
# define MAXBIT 10
# define MAXVALUE 1000
typedef struct HNode /*定义结点结构*/
{ int weight;int parent , lchild , rchild;
}HNode;void HuffmanCoding(HNode *HT,HCode *HC , int *w , int n)
{ /* w存储n个字符的权值,构造哈夫曼树HT,并求出n个字符的哈夫曼编码HC*/int m, m1, m2, x1, x2, i, j, start; HNode *p; char* cd;if (n <= 1) return;m= 2*n-1; /*哈夫曼树的构造*/HT = (HNode *)malloc (m*sizeof(HNode) );for(p = HT, i = 0; i < n; ++ i, ++ p, ++w)/*初始化叶子结点信息*/{ p->weight = *w; p->lchild = -1;p->rchild = -1; p->parent = -1; }for( ; i < m; ++ i, ++ p) /*初始化分支结点信息*/{ p->weight = 0; p->lchild = -1; p->rchild = -1; p->parent = -1;}
for( i = n; i < m; ++ i) /*构造哈夫曼树 */{ m1 = m2 = MAXVALUE;x1 = x2 = 0; /*寻找parent为-1且权值最小的两棵子树*/for(j = 0; j < i; ++ j) { if(HT[j].parent == -1 && HT[j].weight < m1){m2 = m1; x2 = x1; m1 = HT[j].weight; x1 = j; }else if(HT[j].parent == -1 && HT[j].weight < m2){ m2 = HT[j].weight; x2 = j; }}/*合并成一棵新的子树*/HT[x1].parent = i; HT[x2].parent = i;HT[i].lchild = x1; HT[i].rchild = x2;HT[i].weight = m1 + m2;}
/*字符编码*/HC = (HCode *) malloc (n*sizeof(HCode) );cd = (char *) malloc(n*sizeof(char));cd[n-1] = ’\0’;for(i = 0; i < n; ++ i) /* 从叶子到根逆向求每个字符的哈夫曼编码 */{ start= n-1;for(c = i, f = HT[i].parent; f != -1; c = f, f = HT[f].parent)if(HT[f].lchild = c) cd[--start] = ’0’;else cd[--start] = ’1’;HC[i] = ( char*) mallic(n-start)*sizeof(char)); /*为第i个字符编码分配空间*/strcpy(HC[i], &cd[start]); /*从cd复制编码串到HC[i] */}free(cd);
}