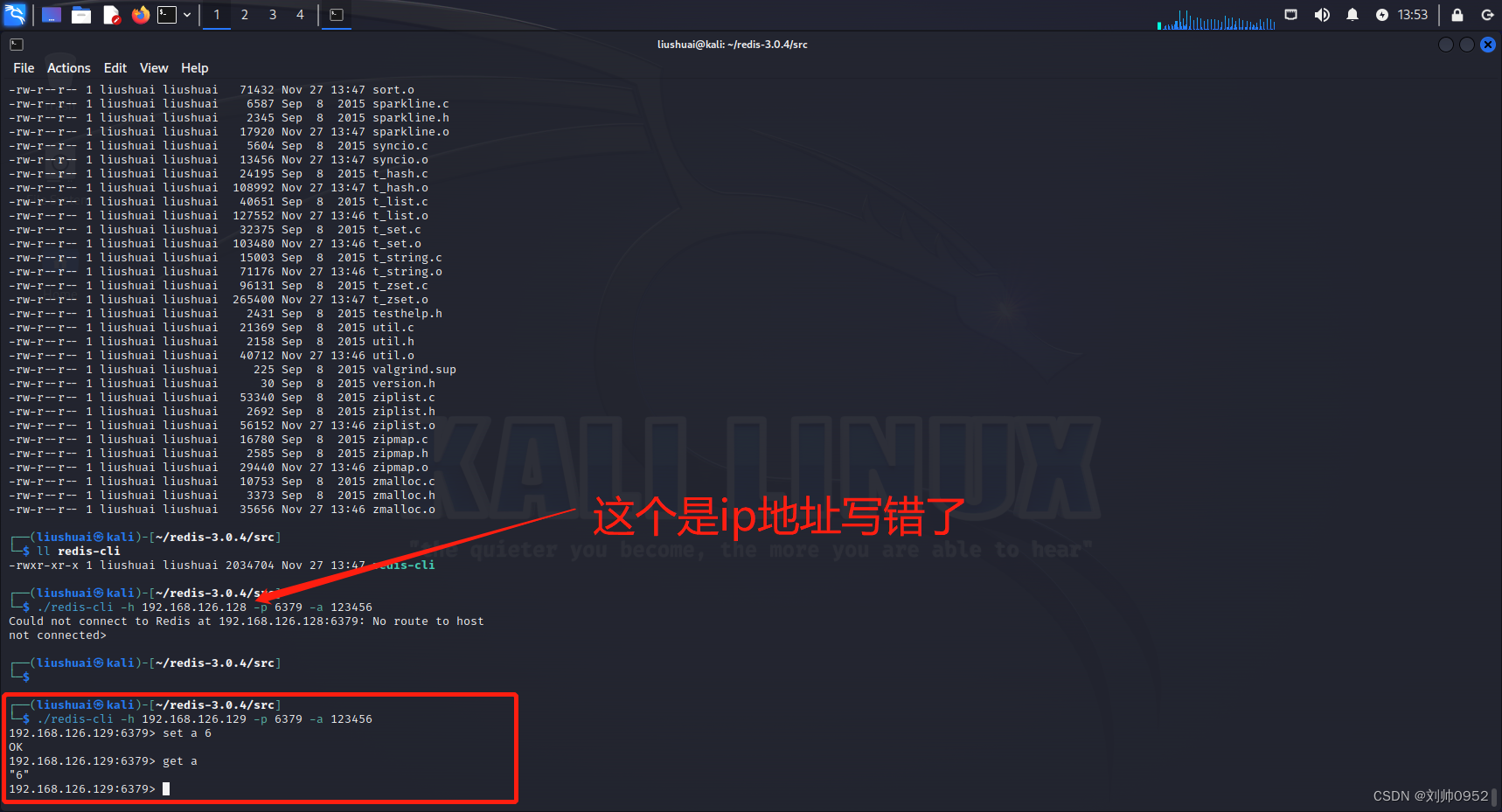
shared_buffers 是 PostgreSQL 中一个非常关键的参数,用于配置服务器使用的共享内存缓冲区的大小。这些缓冲区用于存储数据页,以便数据库可以更快地访问磁盘上的数据。
这个参数在 PostgreSQL 的性能方面有着重要的影响。增加 shared_buffers 可以提高数据库的性能,尤其是对于频繁的读取操作。但是,设置得太大可能会导致内存不足,影响其他系统进程的性能,需要谨慎平衡。
以下是关于 shared_buffers 的一些重要信息:
-
作用: 控制 PostgreSQL 服务器用于缓存数据页的共享内存大小。这些数据页是数据库从磁盘读取的数据的副本,在内存中存储以提高后续读取操作的速度。
-
默认值: 默认情况下,
shared_buffers的值是相对于系统总内存的一部分。默认设置通常比较保守,以兼顾系统的其他资源需求。 -
调整建议: 适当设置
shared_buffers的值取决于多个因素,包括系统的可用内存、数据库负载、运行中的查询类型等。增加shared_buffers可以提高性能,但并不是所有情况下都能带来线性的性能提升。 -
内存计算: 通常建议将
shared_buffers设置为物理内存的 25% 到 40% 之间。这只是一个起点,最佳值需要根据实际情况和性能测试来确定。 -
影响: 将
shared_buffers设置得过小可能导致频繁的磁盘 I/O 操作,影响性能;而设置得过大可能占用大量内存,影响系统的稳定性和其他进程的性能。
修改 shared_buffers 后通常需要重启 PostgreSQL 服务器才能使更改生效。
1. 计算机缓存机制
计算机缓存是指用于临时存储数据的一种高速存储器,其目的是提高数据访问速度并加速计算机系统的性能。缓存系统通过在数据的访问路径中引入更快的存储介质,减少了对慢速存储(如硬盘)的访问次数,从而加快数据的读取和写入。
1.1. 类型和工作原理:
-
CPU 缓存(Cache Memory): 在现代计算机系统中,CPU 缓存是其中最重要的缓存之一。它通常分为三级:一级缓存(L1 Cache)、二级缓存(L2 Cache)和三级缓存(L3 Cache)。这些缓存以层级结构的方式嵌入在 CPU 内部,并用于存储CPU经常需要访问的数据和指令。这些缓存级别按速度和容量递减排列,L1 最快但容量最小,L3 最慢但容量最大。
-
硬盘缓存(Disk Cache): 操作系统和文件系统会使用部分内存作为硬盘缓存,用于存储磁盘上最近访问的数据块的副本。这样的缓存减少了从慢速的机械硬盘读取数据的需求,提高了文件访问速度。
-
数据库缓存: 数据库系统通常有自己的缓存机制,如之前提到的 PostgreSQL 的 Shared Buffers。这些缓存用于存储数据库中经常被访问的数据,以减少对存储介质(如磁盘)的访问,提高数据库查询的性能。
1.2. 缓存优势和局限性:
-
优势:
- 提高数据读取速度:通过存储最近使用的数据副本,可以快速响应对相同数据的再次访问。
- 减少延迟:由于缓存通常位于 CPU 或内存之类的更快速介质中,因此访问这些缓存的延迟更低。
- 改善性能:优化内存和磁盘之间的数据传输,降低系统响应时间,提高整体性能。
-
局限性:
- 有限容量:缓存的容量有限,因此可能无法容纳所有的数据。
- 数据一致性问题:缓存数据更新不及时可能导致一致性问题。
- 成本:更大容量、更快速的缓存通常成本更高。
1.3. 管理和优化缓存:
- 合理配置大小: 根据应用需求和硬件条件,合理配置缓存的大小以平衡性能和成本。
- 监控和优化: 定期监控缓存使用情况,优化缓存命中率,避免缓存污染(淘汰频繁使用的数据)等问题。
- 使用合适的缓存策略: 包括先进先出(FIFO)、最近最少使用(LRU)、最不经常使用(LFU)等策略以及写回、写通过等写入策略。
综合来说,缓存在计算机系统中扮演着至关重要的角色,对于提高系统的整体性能至关重要。因此,合理利用和管理缓存是优化系统性能的关键一环。
1.4. OS Cache
-
Linux: 在 Linux 上,可以通过修改内核参数(如 vm.dirty_* 和 vm.swappiness)来影响磁盘缓存的行为。这些参数控制着内核对于脏页(未写入磁盘的数据页)的处理方式以及内存交换(swapping)行为。但是,修改这些参数需要谨慎,最好了解其影响和风险。
-
Windows: Windows 操作系统也有一些控制文件系统缓存的参数,但通常情况下,Windows 会自动管理这些参数。
2. BGWriter在PostgreSQL中的作用是什么?
`BGWriter`(Background Writer)是 PostgreSQL 中的一个重要后台进程,负责管理缓冲区(Buffer Cache)并尽可能将脏页(已被修改但尚未写入磁盘)异步地写入到磁盘,以确保数据的持久性和系统性能的最优化。以下是 `BGWriter` 后台进程的主要功能和作用:1. **脏页管理**:`BGWriter` 负责管理共享缓冲区中的脏页,这些脏页包含了已经被修改但尚未写入磁盘的数据。2. **异步写入脏页**:它定期检查缓冲区中的脏页,并尝试将这些脏页异步地写入到磁盘。这样做有助于降低对磁盘的频繁访问,提高数据库系统的性能。3. **减少后续写入操作的影响**:通过将脏页定期写入磁盘,`BGWriter` 可以减少后续写入操作对系统性能的影响。这有助于确保写入操作不会阻塞太多,并且减少了系统性能突然下降的风险。4. **优化磁盘写入**:`BGWriter` 通过尝试合并或共享磁盘写入操作,以提高写入磁盘的效率,减少对磁盘的访问次数,进而优化系统性能。需要注意的是,`BGWriter` 进程的行为相对被动,其工作是在后台周期性地进行。默认情况下,它会根据配置中的参数自动执行,通常不需要额外的手动调整。然而,在某些高负载或特定场景下,对 `BGWriter` 参数的微调可能有助于进一步优化数据库的性能。
3. 修改参数的优点和缺点
在 PostgreSQL 中,修改 shared_buffers 参数后,重启数据库服务器并重新启动之后,对于 UPDATE 操作的速度可能会有一定影响,但影响的具体程度取决于多种因素。
shared_buffers 参数控制着数据库系统用于缓存数据的共享内存区域大小。增大 shared_buffers 的值通常会增加数据库系统在内存中缓存数据的能力,从而提高查询性能,尤其是能够更快地访问和操作缓存中的数据。
然而,增大 shared_buffers 参数值可能会导致数据库系统在启动时需要更多的内存,并且在运行过程中可能占用更多的系统资源。因此,如果您在修改 shared_buffers 参数后重启 PostgreSQL,可能会出现以下情况:
-
启动时间增加:如果您将
shared_buffers值增大到一个较大的数值,可能会导致 PostgreSQL 在启动时需要更长的时间来分配和管理这部分较大的内存空间。 -
内存占用增加:增大
shared_buffers参数会占用更多的内存。如果系统可用内存不足,可能会导致其他进程的内存竞争,甚至可能出现交换(swap)。 -
影响 UPDATE 操作速度:在某些情况下,增大
shared_buffers可能会提高 UPDATE 操作的速度,尤其是对于频繁读取的数据,因为缓存命中率可能会提高。但并不是所有的 UPDATE 操作都会直接受益于这种变化。
总体来说,修改 shared_buffers 后对 UPDATE 操作速度的影响因多种因素而异,包括系统的硬件资源、数据库的使用模式、查询访问模式等。为了评估对性能的影响,建议在生产环境之前在测试环境中进行测试和评估,以便更好地了解参数调整对系统的影响。