一:为什么学习flink?
相比较spark,flink对于实时这块,使用过流的方式进行实现。
spark是通过批流的方式实现,通过减少批的时间间隔来实现流的功能。
二:什么是flink?
flink是一个针对于实时进行处理的框架。高可用,低延迟。
三:flink怎么使用?
1. flink的俩种架构模式。
- Standalone模式。
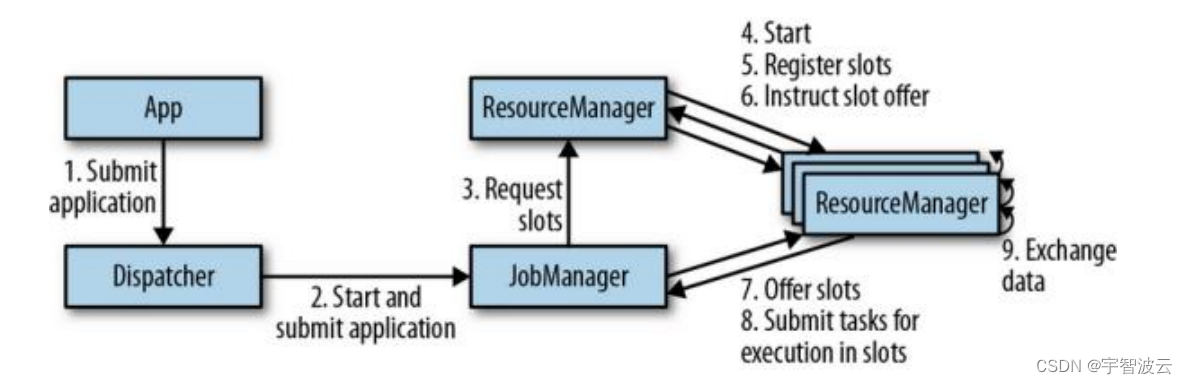
-
JobManager
1.将程序转为物理执行图。
2. 申请资源。
3. 监控taskmanager运行情况和checkpoint的协调。 -
ResourceManager
资源管理器主要负责管理任务管理器(TaskManager)的插槽(slot)。 -
TaskManager
执行任务 -
Dispatcher
- Flink on yarn模式。


2. TaskSlot与Parallelism。
slot是指taskmanager的并发执行能力。
parallelism是指taskmanager实际使用的并发能力
3. flink 窗口,时间,水位线。
窗口
1. 滚动
2. 滑动
3. 累加
时间
- 事件时间。
- 处理时间。
- 摄入时间。
水位线
4. 状态。
- source端保证。
在kafka的源头,我们有偏移量,当重跑的时候,会找到上次的offest进行重新加载数据。 - 中间进行保证。
checkpoint
savepoint
当jobmanager发送任务的时候,会伴随发送一个barriers(栅栏),每一个操作都会进行一次拍照,最后sink。跑完会将数据存储起来。完成一次保存。最后通知jobmanager。
存储的方式- 内存
- 磁盘
- 数据库
- sink端进行保证。
俩阶段提交。