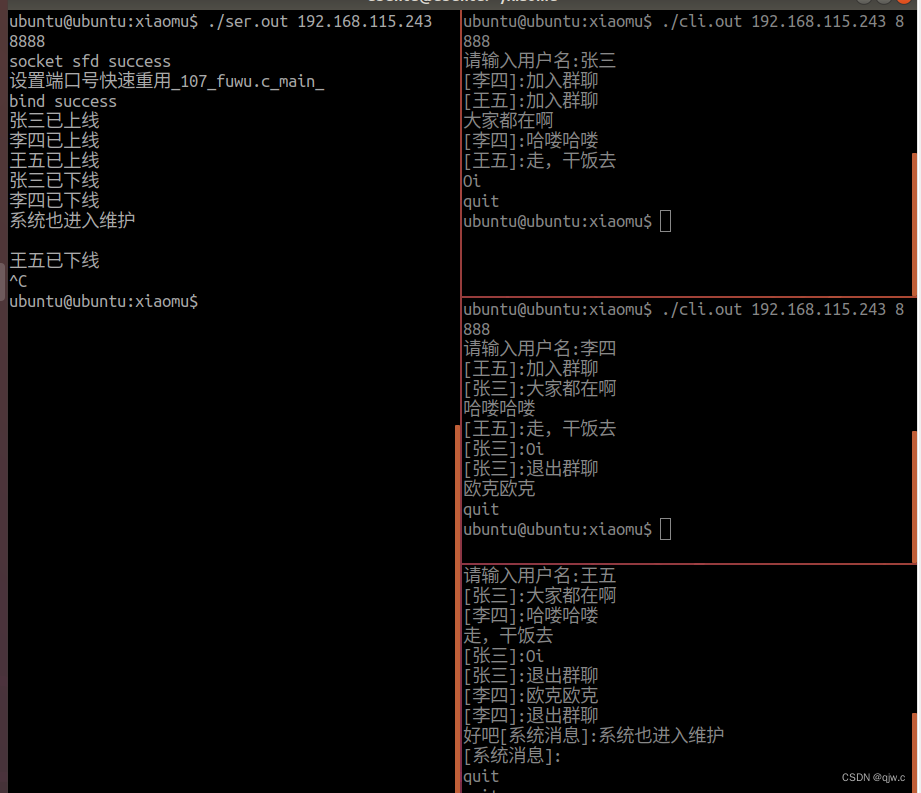
1 Redis 为什么快
- 数据存在内存中, 直接操作内存中的数据
- 单线程处理业务请求避免了多线的上下文切换, 锁竞争等弊端
- 使用 IO 多路复用支撑更高的网络请求
- 使用事件驱动模型, 通过事件通知模式, 减少不必要的等待
- …
这些都是 Redis 快的原因。 但是这些到了代码层面是如何实现的呢?
这篇文章会简单的梳理 Redis 的代码实现 – 事件轮询。
主要涉及到上面的单线程, IO 多路复用和事件驱动。
注: 下面的分析也是按照 Redis 5.x 进行分析。
2 IO 多路复用
因为 Redis 中大量的使用到了 IO 多路复用, 这边我们先简单的了解一下 IO 多路复用。
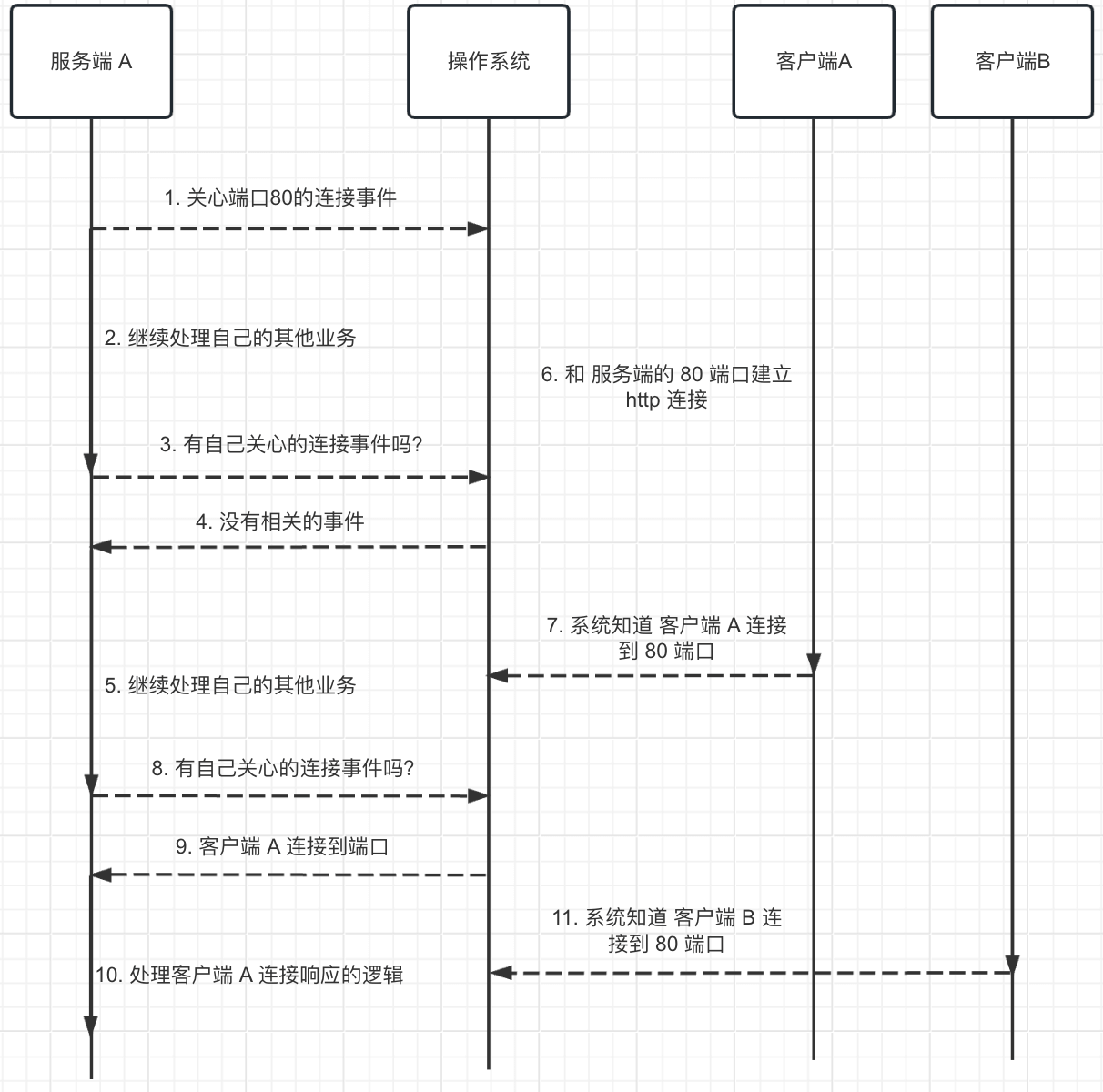
上面的 IO 多路复用的简单流程, 还有另外一种回调的实现方式, 大体的逻辑差不多。
而传统的阻塞式 IO 的大体流程如下:
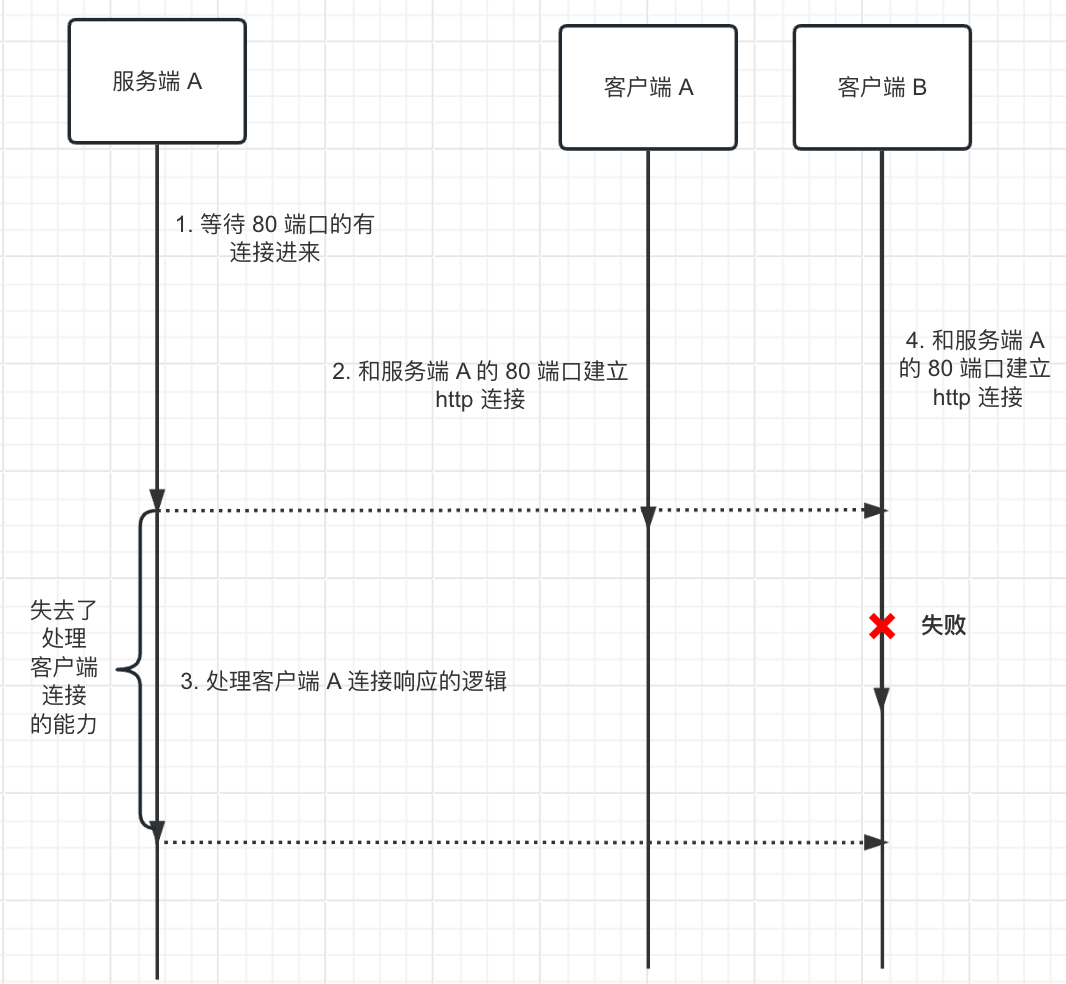
线程一直阻塞在监听端口处, 其间无法进行任何的事务的处理, 没有连接进来, 线程就一直就阻塞着。 同时自己无法兼顾处理多个并发的请求。
而 IO 多路复用, 则将监听的操作交由系统进行处理, 自己在处理事务的过程中, 不定时的过来询问有自己关心的事件吗, 有就执行相应的事务, 否则继续处理别的业务。
3 IO 多路复用在各个系统的实现
从上面的流程可以知道, IO 多路复用需要系统层面的支撑, 就如存在多种操作系统一样, IO 多路复用的具体实现也有多种
- select 大部分系统都支持
- epoll Linux
- evport Solaris
- kqueue UNIX (Mac)
- …
不同的实现, 理所当然的映射到程序中, 就是不同的 api, 也就是不同的函数。
以 epoll 为例, 在 C 语言中, 提供了 3 个函数来帮助开发者使用多路复用。
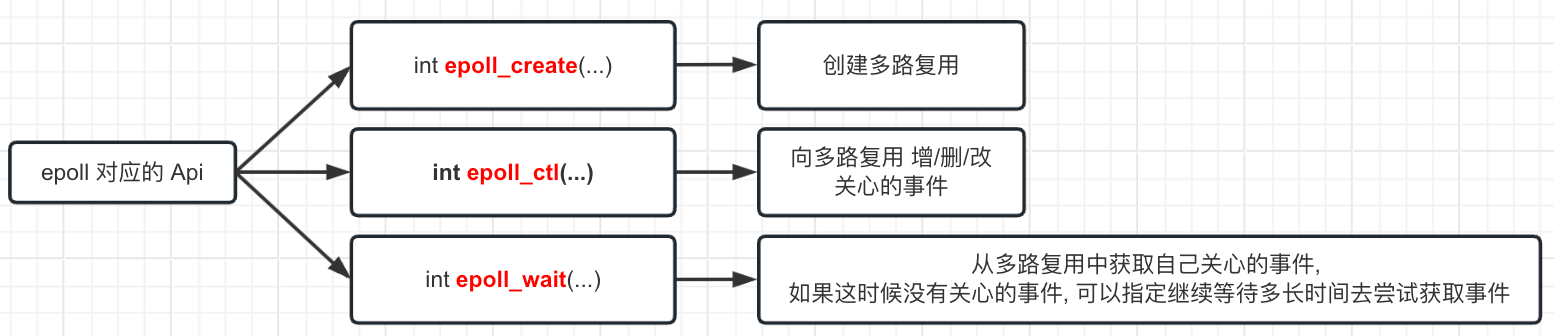
Linux 提供的 epoll 多路复用就上面是 3 个方法, 很简单。
但是到了 Mac 的 evport 具体实现, 对应的实现是 kevent, meset 等函数, 完全不一样的逻辑。
不同的多路复用实现有着不同的 Api, 而 Redis 是一个可以支撑多平台的中间件, 那么就不能简单的选择其中一种了, 那么怎么办呢?

4 Redis 对多路复用的统一
全都要是有代价的, 首当其冲的就是编码上复杂性将会提高很多。最简单的写法应该就是如下:
/*** 创建多路复用*/
public static void createIoMultiplex(){if(os_system=="Linux"){// TODO} else if(os_system=='mac'){// TODO}...
}
首先上面的代码逻辑是没错的, 但是从一个开发出发
- 增加了自己的编码量
- 对知识储备有挑战, 需要了解不同的多路复用的实现原理
- …
作为开发人员想要的是一套统一的 Api, 就能操作所有的多路复用。我不需要知道各个的多路复用的 Api, 差异什么, 什么时候用哪个。
下面就进入 Redis Java 版代码环节了 (Redis 是基于 C 语言实现的, 而 C 是一门面向过程的语言, 下面会以 Java 语言的形式进行分析总体逻辑是类似的)。
虽然多路复用的实现在不同的方式有很多种, 但是对于开发通过多路复用要实现的事情都是一样的
- 创建和销毁多路复用
- 向多路复用添加删除我们关心的事件
- 从多路复用中获取我们关心的事件, 然后进行处理
所以 Redis 中对多路复用进行了封装。
先说一下结论吧: Redis 中对多路复用的封装有 2 层 AeApiState + AeApi。
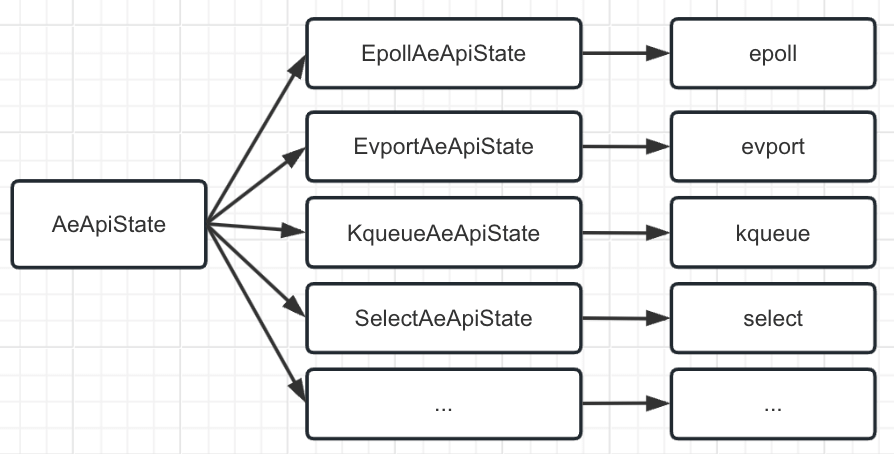
AeApiState: 对各种多路复用本身实现逻辑的封装, 屏蔽各种实现细节。
可以理解为 AeApiState 就是代表了多路复用, AeApiState == 多路复用, 就像我们一直说多路复用有多种实现一样 AeApiState 下面也有多种实现, EpollAeApiState, SelectAeApiState 等。
AeApi: 对多路复用支持的行为的封装, 对底层的多路复用进行了屏蔽, 开发人员只需要持有它的实现就可以对多路复用进行操作。
4.1 AeApiState
首先需要对各个系统的多路复用的统一:
public class AeApiState {
}
AeApiState 是 Redis 中各个操作系统重多路复用的统一声明。就和我们一直说多路复用一样, 是一个统称, 落实到实际中, 会有不同的实现, epoll, select 等。
AeApiState 也一样是 Redis 多路复用的一个统称, 其本身空空如也, 不具备任何的多路复用的功能。
而各个系统中已经给我们准备好了现成的功能, 我们完全可以利用起。
public class EpollAeApiState extends AeApiState {/*** 监听的文件描述符, 可以简单理解为一个文件的 id*/private int epFd;/*** Epoll 会将调用方关心并符合条件的事件存放到这里* EpollEvent 就 2 个属性 * int fd 对应的文件描述符, 这里一般就是客户端的标识, 简单理解就是某个事件的 id* int events 触发的事件类型, 可以理解为可读可写等*/private List<EpollEvent> events;public int epollCreate(){// 调用系统提供的 epoll_create() 创建 Epoll 类型的}// 省略其他 2 个方法
}
将各个系统的多路复用技术全部封装起来, 统一为 AeApiState 了。
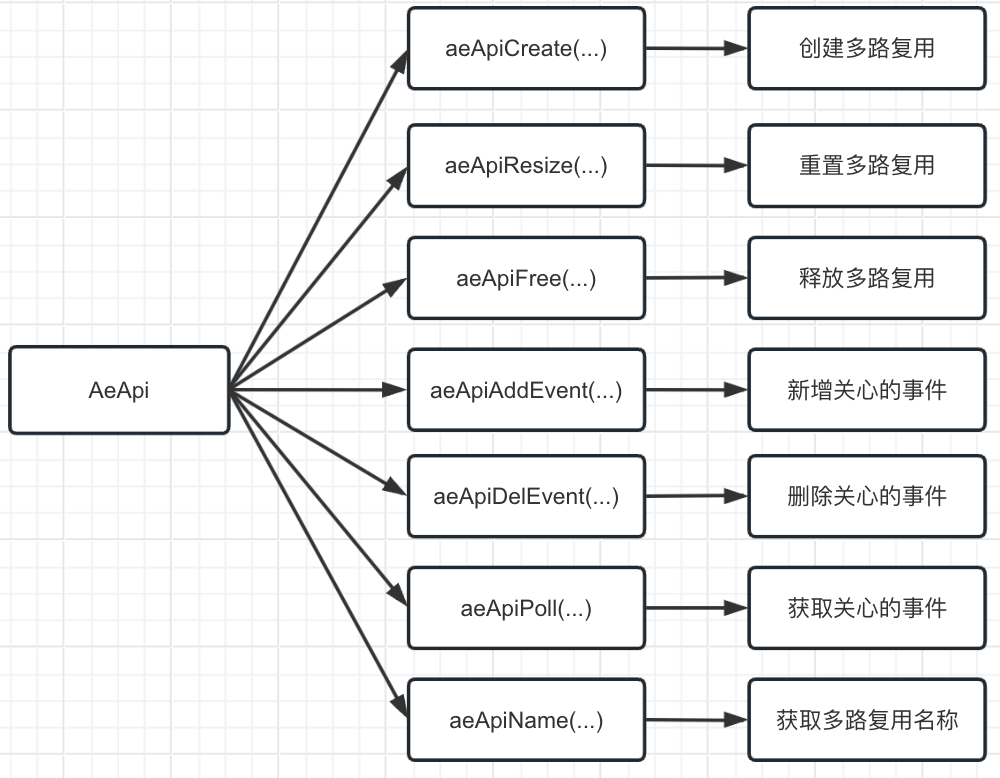
4.2 AeApi
现在有多路复用 AeApiState 了, 但是不同的多路复用的 Api 不同, 同样的行为可以有不同的实现, 还是没解决多种实现的问题, 统一的 Api, 底层的屏蔽呢?
这是就轮到 AeApi 出现了, 对常用的多路复用 Api 行为进行抽象
public interface AeApi {/*** 获取 aeApi 的名称, 也就是多路复用的实现名称* @return aeApi 的名称*/String aeApiName();/*** 创建 AeApiState, 也就是创建具体的多路复用* @param setSize 关心的事件最大数量* @return 创建结果, 1:成功, 其他失败*/int aeApiCreate(int setSize);/*** 重新设置 AeApiState 中监听文件描述符的上限* @param setSize 重新设置的大小* @return 释放结果, 1:成功, 其他失败*/int aeApiResize(int setSize);/*** 释放 AeApiState, 也就是关闭具体的多路复用*/void aeApiFree();/*** 向多路复用中新增关心事件* @param aeEventLoop 事件轮询对象* @param fd 文件描述符* @param mask 标识* @return 新增结果, 1:成功, 其他失败*/int aeApiAddEvent(AeEventLoop aeEventLoop, int fd, int mask);/*** 向多路复用中删除事件* @param aeEventLoop 事件轮询对象* @param fd 文件描述符* @param delMask 删除标识* @return 删除结果, 1:成功, 其他失败*/int aeApiDelEvent(AeEventLoop aeEventLoop, int fd, int delMask);/*** 阻塞指定毫秒数, 返回阻塞时间段内就绪的事件* @param aeEventLoop 事件轮询对象* @param waitTime 阻塞时间, 毫秒* @return 准备就绪的事件条数*/int aeApiPoll(AeEventLoop aeEventLoop, long waitTime);
}
上面是对 Redis 中对使用多路复用的支持的行为的定义。 不同的多路复用实现, 实现上面的接口, 实现自己的行为。
public class EpollAeApi implements AeApi {/** Epoll 多路复用自身的封装 */private AeApiState aeApiState;@Overridepublic String aeApiName() {return "epoll";}@Overridepublic int aeApiCreate(int setSize) {// 将 epoll 封装到自定义的 AeApiState 中EpollAeApiState epollAeApiState = new EpollAeApiState();epollAeApiState.epollCreate(setSize);this.aeApiState = epollAeApiState;return 1;}// 其他方法省略
}
到此, Redis 对多路复用的封装就达成了。
上面都是底层的封装实现, 而到了开发层面, 在使用时, 就很简单了, 完全屏蔽了多路复用的存在, 基于统一的 Api 就能操作自己想要的效果
AeApi aeApi = geteApi();// 创建多路复用
aeApi.aeApiCreate();// 添加事件
aeApi.aeApiAddEvent();// 取消关心的事件
aeApi.aeApiDelEvent(fd);// 阻塞 waitTime 毫秒, 等待多路复用返回关心的事情
aeApi.aeApiPoll(waitTime);
5 事件驱动
多路复用只是 Redis 运行中的一个辅助功能, 需要和 Redis 的事件轮询共同配合, 才支持起了高并发。
事件轮询可以拆分成事件 + 轮询。
5.1 轮询
这里我们先说一下轮询。轮询: 实际上就是一个死循环。
while(true){// TODO 执行逻辑
}
- 将这个死循环封装到一个对象 AeEventLoop 中去, 同时加上一个控制循环结束的变量,就达到了 Redis 中事件轮询中轮询的雏形了。

- 丰富轮询的功能 --> 将我们的多路复用的 AeApi 添加进去,此时的事件轮询,将会变成这样

- 丰富轮询的功能 --> 在循环中调用多路复用时, 添加阻塞前后的回调函数

很多人认为 Redis 整个单线程是完成不会阻塞的。
实际上, 还是存在阻塞情况, 如果你有查看上面的 AeApi 的 Api 就可以发现 aeApiPoll 是一个阻塞的方法, 只是 Redis 阻塞时间设置的比较巧妙, 后面再分析。
上面就是我们常说的事件驱动模型, 事件轮询的轮询主体了。在使用上, 也很简单
public class Application {public static void main(String[] args) {// 创建事件轮询对象AeEventLoop aeEventLoop = new AeEventLoop();System.out.println("Redis 启动");// 启动事件轮询 (进入了一个死循环) aeEventLoop.aeMain();System.out.println("Redis 停止");}
}
5.2 事件
有了循环了, 但是从整体看的话, 循环中是没有任何的执行逻辑的, 是因为 Redis 将所有的逻辑都封装到了每一个事件上, 事件是将 Redis 中多路复用和轮询组合起来的核心。
在 Redis 中定义了 2 种事件
文件事件: 需要满足某个条件才触发的事件, 但是不确定触发时机
时间事件: 需要多次有间隔的执行事件
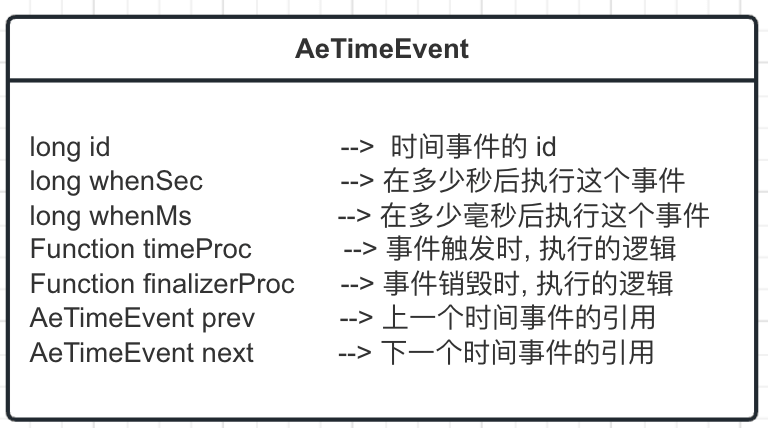
5.2.1 时间事件
因为文件事件和多路复用挂钩, 有点绕了一点, 我们先将时间事件组合到事件轮询中。
public class AeEventLoop {// 程序自定义的时间事件, 双写链表private AeTimeEvent aeTimeEvent;// 对外暴露的函数: 向事件轮询中的时间事件链表添加新的时间事件public void aeCreateTimeEvent() {// 向事件轮询添加时间事件, 就是简单的链表操作}// 对外暴露的函数: 通过事件的 id 从事件轮询中的时间事件链表删除对应的时间事件public int aeDeleteTimeEvent(long id) {// 从事件轮询删除时间事件, , 就是简单的链表操作}// 启动函数没有任何变化public void aeMain() {while (this.stop == 0) {aeProcessEvents();}}// 事件处理函数private int aeProcessEvents() {// 1. 从时间链表中获取最快需要触发的时间事件, 距离触发还需要多少毫秒// 这里就是为什么 Redis 阻塞时间设置的比较巧妙的地方, 阻塞的这段时间理论是无时间触发, 所以对性能影响比较小long waitTime = handlerWaitTime(aeTimeEvent);// 2. 执行阻塞前的函数 beforeSleepFunction(this);// 3. 阻塞式的从多路复用中获取文件事件int numEvents = aeApi.aeApiPoll(this, waitTime);// 4. 执行阻塞后的函数 afterSleepFunction(this);// 5. 执行需要触发的时间事件的函数processTimeEvents();}// 时间事件的触发处理private int processTimeEvents() {// 1. 获取双向链表的头节点AeTimeEvent timeEvent = this.aeTimeEvent;while (timeEvent != null) {// 节点的 id == -1, 表示这个节点需要删除// 节点的删除是延迟删的, 需要删除时, 先打标为 -1,下次执行时, 在删除if (timeEvent.getId() == -1) {// 2. 双向链表的节点删除, 同时将下一个节点赋值给 timeEvent// TODO 逻辑省略, 就是常见的双向链表的节点删除continue;}// 3. 计算当前的时间和当前节点的时间是否匹配,匹配这个时间事件需要执行if (timeEventNeedHander(timeEvent)) {// 执行时间事件的函数,同时会返回一个数字, 大于等于 0 表示多少秒后再执行, 小于 0, 表示不在需要了int retVal = timeEvent.getFunction().run();if (retVal == -1) {// 需要销毁, 设置 id 为 -1, 下次再删除timeEvent.setId(-1);} else {// 重新计算这个时间下次执行的时间updateAeTimeEventTime(aeTimeEvent, retVal);}}}}}
上面的逻辑很简单, 在事件轮询中, 加了 2 个方法, 用来给外部调用, 一个是添加时间事件, 一个是删除时间事件。
然后添加到事件轮询中的时间事件, 会在存储在事件轮询中的一个双向链表。
然后在事件轮询的死循环中, 每一次操作
- 计算整个事件双向链表中最快需要触发的时间事件, 距离触发还需要多少毫秒
- 阻塞式地从多路复用中获取文件事件, 阻塞的时间就是上一步计算出来的时间
- 从多路复用中的阻塞中返回后, 遍历整个时间事件双向链表
- 遍历整个时间双向链表
4.1 遍历的时间事件的 fd == -1, 表示这个时间事件需要删除, 进行删除 (Redis 对文件事件的删除都是延迟到下一轮循环删除)
4.2 遍历的时间事件没达到执行的时间, 跳过这个时间事件, 继续遍历下一个时间事件
4.3 遍历的时间事件需要达到了执行的时间, 执行这个时间事件里面的函数
4.4 执行的事件函数会返回一个整数, 整数值为 -1, 表示这个时间事件不需要了, 这时会将这个时间事件的 fd 设置为 -1, 下一轮循环删除
4.5 执行的事件函数返回的整数为大于等于 0, 表示这个时间事件还需要执行, 这个时间表示多久后执行, 根据这个时间计算这个时间事件下次执行的时间点, 继续遍历下一个时间事件
5.2.2 文件事件
了解多路复用和时间轮询的协助前, 需要先了解一个对象 AeFiredEvent: 已满足触发条件的文件事件。

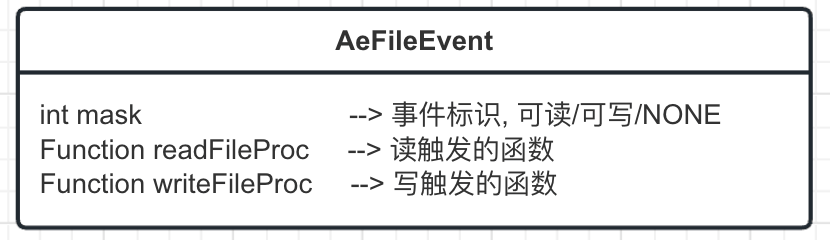
AeFiredEvent 中有 2 个属性
- fd 文件描述符, 可以简单的理解为文件事件的 id
- mask 文件事件的触发类型, 可读, 可写等
public class AeEventLoop {// 程序自定义的文件事件, 程序初始时, 指定好了最大容量了private List<AeFileEvent> aeFileEvents;// 存储多路复用中通知的已触发的事件数组private List<AeFiredEvent> aeFiredEvents;public AeEventLoop(int maxSize) {this.aeFileEvents = new ArrayList<>(maxSize);this.aeFiredEvents = new ArrayList<>(maxSize);for (int i = 0; i < maxSize; i++) {this.aeFileEvents.add(new AeFileEvent());this.aeFiredEvents.add(new AeFiredEvent());}}
}
在事件轮询中, 有 2 个文件事件相关的数组
- aeFileEvents: 存储的就是注册到事件轮询中的文件事件
- aeFiredEvents: 存储的就是多路复用中通知的已触发的事件数组
这 2 个数组的长度是一致的, 长度都是入参的 maxSize。
maxSize: 表示当前时间轮询支持的文件事件的个数, 也是所有文件事件 fd 的最大值, 也就是理解为所有文件事件 id 的最大的值。
这个设计可以达到一个好处, 任意一个文件事件的 fd, 也就是 id, 都可以在上面 2 个数组对应的位置找到, aeFileEvents[fd], 得到的就是对应的文件事件。
aeFileEvents 和 aeFiredEvents 共同配合, 达到获取到已触发的文件事件的效果
- 事件轮询 AeEventLoop 调用 AeApi 尝试获取已触发的文件事件, 会将自身 AeEventLoop 和阻塞的毫秒数作为参数传给 AeApi 的 aeApiPoll 方法
- AeApi 的 aeApiPoll 方法在阻塞指定毫秒数后, 可以得到已触发的事件 (也可能这段时间的确一个文件事件都没触发)
- 根据触发的事件的个数, 获取到事件轮询中的 aeFiredEvents (已触发事件数组) 的前几个 AeFiredEvent, 将触发的事件的 fd 和 mask 逐个赋值给获取到的 AeFiredEvent
- 然后将已触发的个数返回给调用的事件轮询 AeEventLoop
- 事件轮询 AeEventLoop 根据已触发的个数, 获取 aeFiredEvents 的前几个 AeFiredEvent, 根据 AeFiredEvent 的 fd, 也就是事件的 id, 到 aeFileEvents 数组中获取对应的 AeFileEvent, 执行函数
大体的流程如下:
- 事件轮询 AeEventLoop 通过 AeApi 的 aeApiPoll 到多路复用 AeApiState 获取已触发的文件事件, 同时将自身作为参数传递过去, 并且说明最多支持在里面阻塞 1000 毫秒 (举例)

- 多路复用 AeApiState 在阻塞 1000 毫秒后, 获取到已触发的文件事件, 假设现在有文件描述符为 2 和 19 的 2 个文件事件触发了
- 多路复用 AeApiState 通过入参的事件轮询 AeEventLoop, 获取到事件轮询中的 aeFiredEvents 数组的前 2 个, 将他们的 fd 和 mask 修改为触发的 2 个事件的 fd 和 mask
- 多路复用修改为 AeApiState 的 aeFiredEvents 数组后, 然后通知调用方 AeEventLoop, 有 2 个文件事件触发了

- AeEventLoop 根据返回的 2, 获取到 aeFiredEvents 数组的前 2 个, 根据 AeFiredEvent 的 fd, 2 和 19, 到自己的文件事件数组的 aeFileEvents 的第 2 位和第 19 位获取 2 个文件事件
- 执行获取到的 2 个文件事件的函数

了解完大体的过程, 下面的代码逻辑应该就很清晰了
public class AeEventLoop {private List<AeFileEvent> aeFileEvents;private List<AeFiredEvent> aeFiredEvents;// 对外暴露的函数: 向事件轮询中的文件事件添加新的文件事件public int aeCreateFileEvent(int fd, int mask, Function function) {// 1. 先向多路复用注册这个事件, 后续才能感知到什么时候触发aeApi.aeApiAddEvent(fd, mask);// 2. 根据文件描述符从文件事件数组中获取对应的位置的文件事件AeFileEvent aeFileEvent = aeFileEvents.get(fd);// 3. 将当前关注的事件类型和执行函数覆盖过去aeFileEvent.setXXX();}// 对外暴露的函数: 向事件轮询中的文件事件删除对应的文件事件public int aeDeleteTimeEvent(int fd) {// 逻辑差不多, 从多路复用中删除即可}// 启动函数没有任何变化public void aeMain() {while (this.stop == 0) {aeProcessEvents();}} public int aeProcessEvents() {// 1. 调用多路复用, 将符合条件的事件,放到 this(也就是当前的 AeEventLoop) 的 aeFiredEvents 中// 同时返回了, 总共触发了多少个函数int numEvents = aeApi.aeApiPoll(this, waitTime);for (int j = 0; j < numEvents; j++) {// 2. 遍历触发的已触发事件数组AeFiredEvent aeFiredEvent = aeFiredEvents.get(j);// aeFiredEvent 的 fd 就是对应的文件描述符// 而 aeFileEvent 已经将最大的 fd 声明成一个数组了, 可以在数组中找到其对应的事件AeFileEvent aeFileEvent = aeFileEvents.get(aeFiredEvent.getFd());// 触发的是可读事件,执行可读函数, 是可写函数, 执行可先函数if (aeFileEvent.getMask() == 1) {aeFileEvent.getReadFileProc().run();} else {aeFileEvent.getWriteFileProc().run();}}}
}
6 事件轮询在 Redis 在运行中的简单分析
- Redis 启动, 加载大量的配置信息, 初始化需要初始的配置等
- 创建唯一一个的事件轮询 AeEventLoop, 在创建时, 指定了最大的文件描述符 (默认为 10128), 这里我们假设为 100, 这时我们就得到了一个事件轮询对象

- 向事件轮询注册一个 1 毫秒执行一次的时间事件, 执行的函数为 serverCron (这个函数是 Redis 初始的唯一一个定时事件, 里面包含了内存的定时释放, 主从心跳的维持等, 同时虽然是 1 毫秒执行 1 次, 但是内部通过维护一个频率的函数, 可以达到不同的时机触发不同的逻辑), 最新的事件轮询就变成这样:
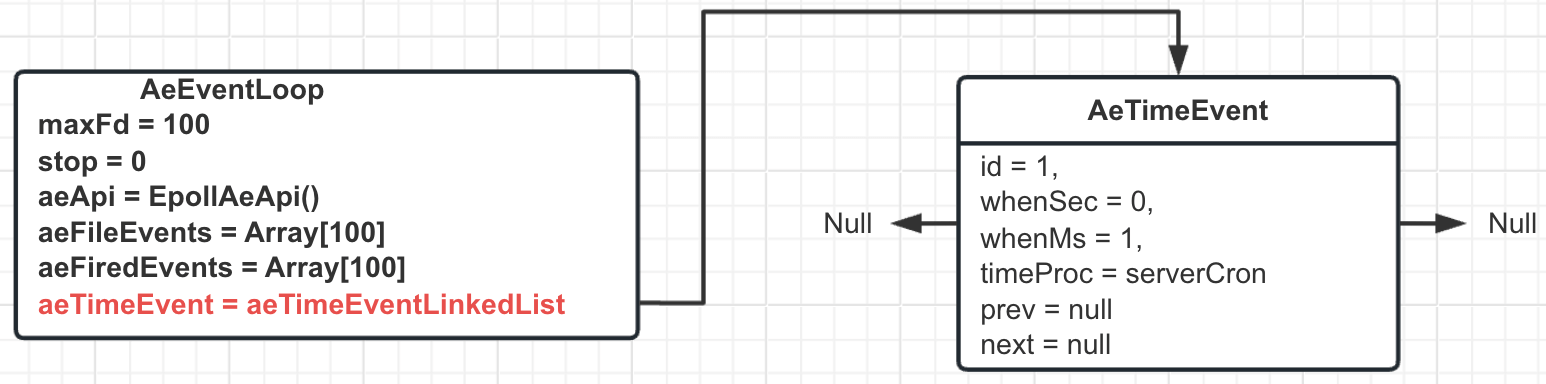
- 和 6379 端⼝建⽴起 Socket 监听, 得到了对应这个端⼝的⼀个⽂件描述符 (这⾥假设为 1)
- 向事件轮询注册⼀个可读事件, ⽂件描述符 1 (这⾥可以之间认为 1 就是 6379 端⼝), 关⼼他的可读事件(有客户端连接到这个端⼝了), 执⾏的函数为 acceptTcpHandler (后续所有的客户端连接到这个 Redis 的事件都会被多路复⽤监听到, 同时通知时间轮询触发 acceptTcpHandler 函数), 最新的事件轮询就变成这样:
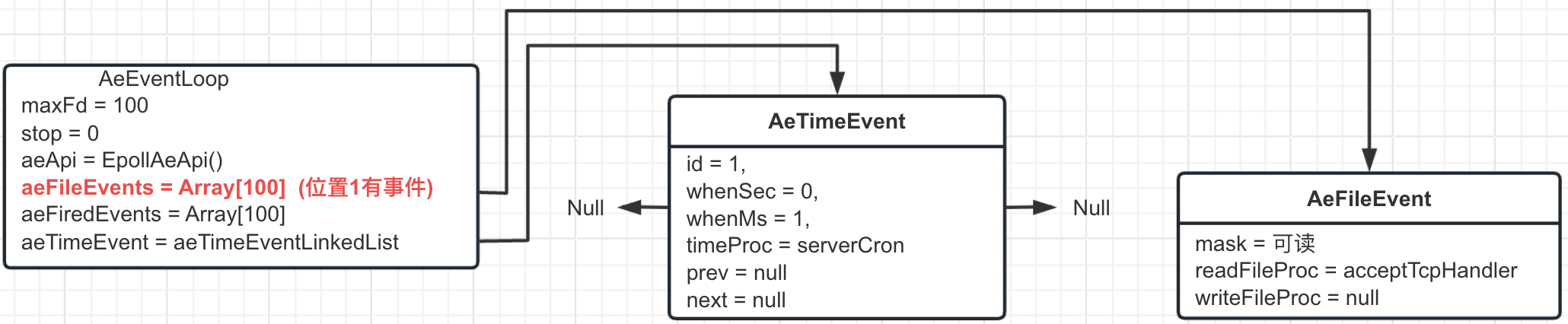
- 向事件轮询注册阻塞前后的回调函数 beforeSleep/afterSleep (beforeSleep 的逻辑很多, 包括先保存 AOF 缓存, ⽴即向从节点发送⼀次 ack 等操作), 最新的事件轮询就变成这样了
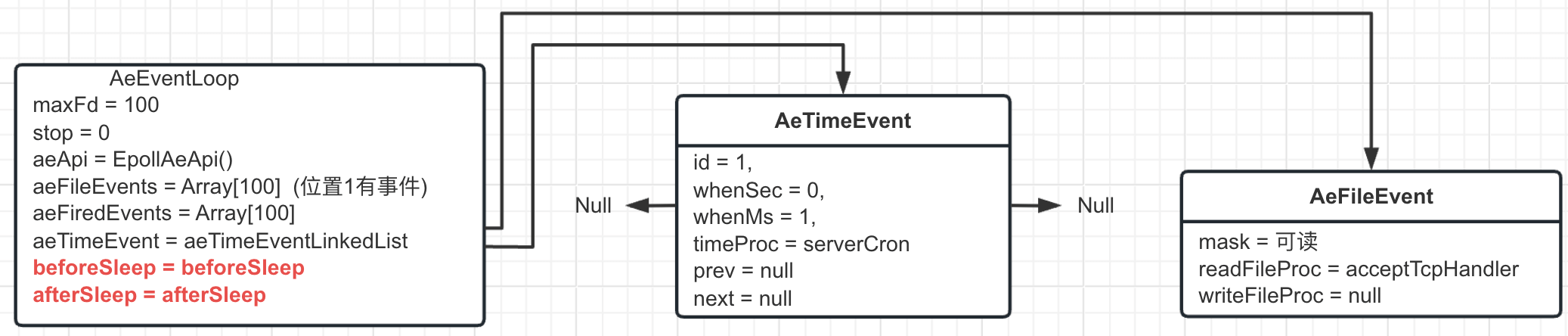
- 调⽤事件轮询 AeEventLoop 的 aeMain ⽅法, 启动事件轮询的死循环
- 从时间链表中找到执⾏时间距离当前最近的⼀个时间事件, 计算出⼀个阻塞时间
- 调⽤阻塞前的函数 beforeSleep
- 调⽤ aeApi 的阻塞⽅法获取关⼼的事件, 阻塞时间为上⾯计算出来的事件 (这时返回值为 0, 没有关⼼的事件)
- 调⽤阻塞后的函数 afterSleep
- aeApi 返回了 0, 没有关⼼的⽂件事件, 跳过⽂件事件的触发
- 遍历整个时间事件链表, ⾥⾯有需要触发的, 就进⾏触发, 同时触发的函数返回值为 -1, 就将 fd 设置为 -1, 下次遍历时间事件链表时, 会从链表中移除, 不为 -1, 根据返回值设置其下次执⾏的时间
- 死循环,回到⽅法头, ⼜继续重复上⾯的 8 -13 步骤
- 突然 IP: 192.168.1.11 向 Redis 发起了 Socket 连接, 多路复⽤这时发现是上层关⼼的可读事件, 保留起来
- 死循环⼜执⾏到了第 10 步, 这时 aeApi 会得到 6379 端⼝的⽂件描述符, 也就是上⾯我们说的⽂件描述符 1 , 将事件轮询的 aeFiredEvents 数组的第⼀个覆盖为⼀个新的 AeFiredEvent, fd 为 1, mask 为可读标识, 最新的事件轮询就变成这样了
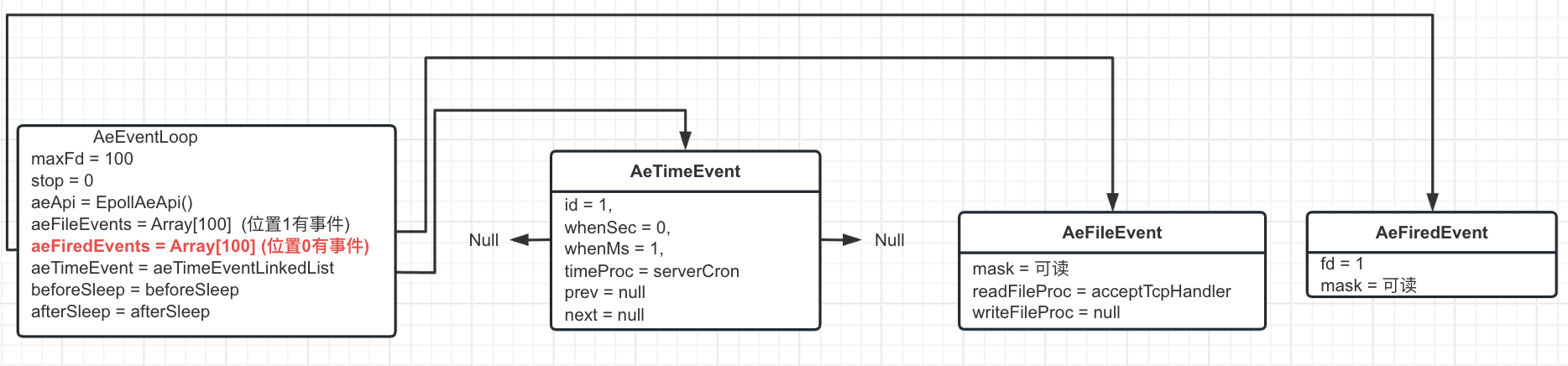
- 死循环得到 aeApi 的返回值不为 0, 根据返回值, 依次从 aeFiredEvents 中获取多少个对象, 这⾥只获取到⼀个, 从第⼀个中获取到⽂件描述符为 1, 从 aeFileEvent 中获取到位置 1 的⽂件事件, 触发其函数, 这⾥是 acceptTcpHandler (acceptTcpHandler 主要是⽤来处理客户端的 socket 连接, 被判定可以处理后,可以通过 ip 得到⼀个⽂件描述符, 然后根据这个⽂件描述符向事件轮询注册⼀个可读事件 (等待客户端发送请求参数),处理函数为 readQueryFromClient, 而 readQueryFromClient ⾥⾯处理完客户端的请求后, ⼜会将这个 ip 也就是⽂件描述符从事件轮询中移除, 不在关心这个 ip 任何事件)
- 执⾏完⽂件事件, ⼜回到 13, 执⾏完,⼜回到⽅法头, ⼜继续重复上⾯的 8 - 13 步骤
至此, Redis 事件轮询就大体分析完了。