redis的数据库是存放在内存当中,所以对内存的监控至关重要
redis内存监控和解析
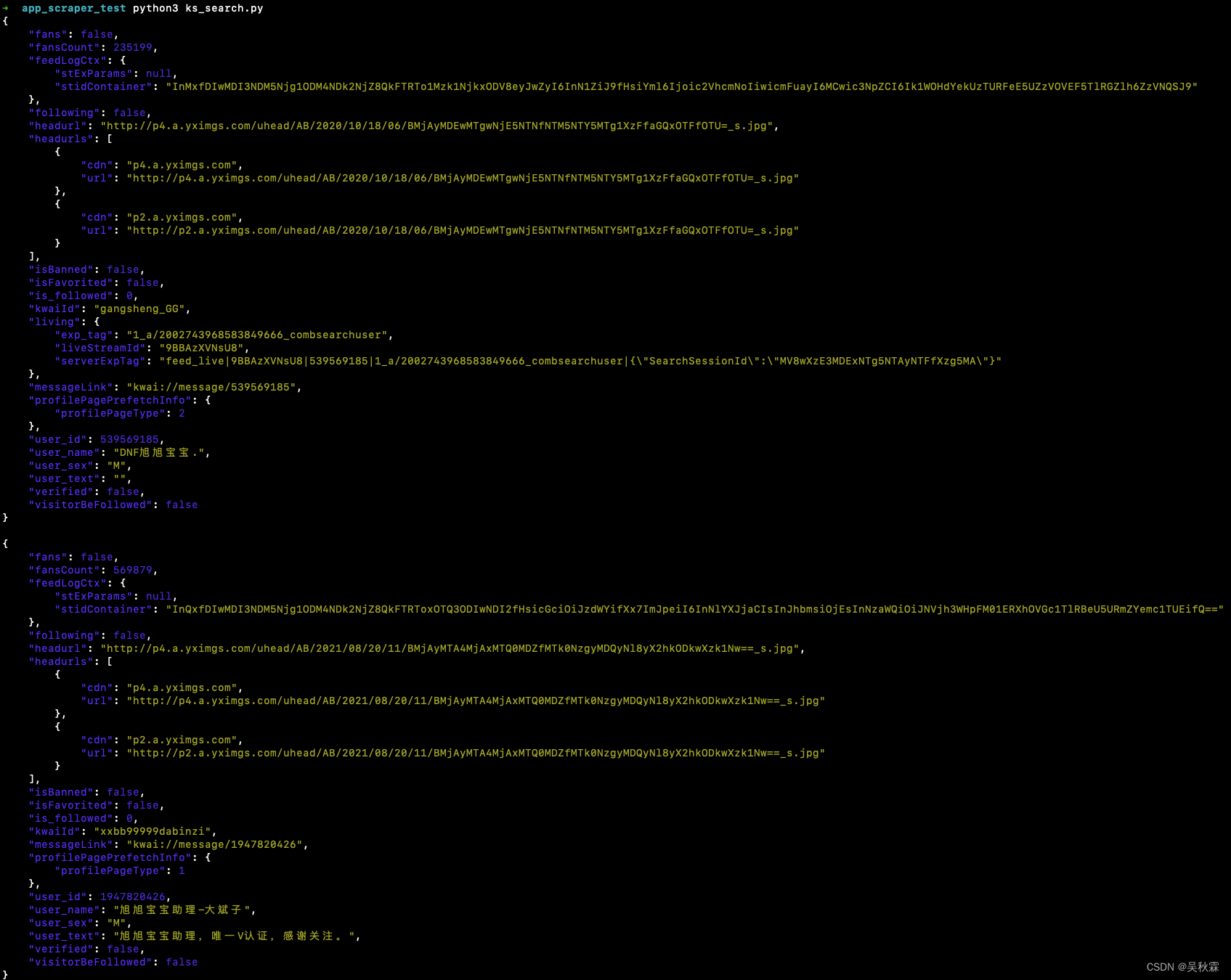
1.如何查看redis内存使用情况
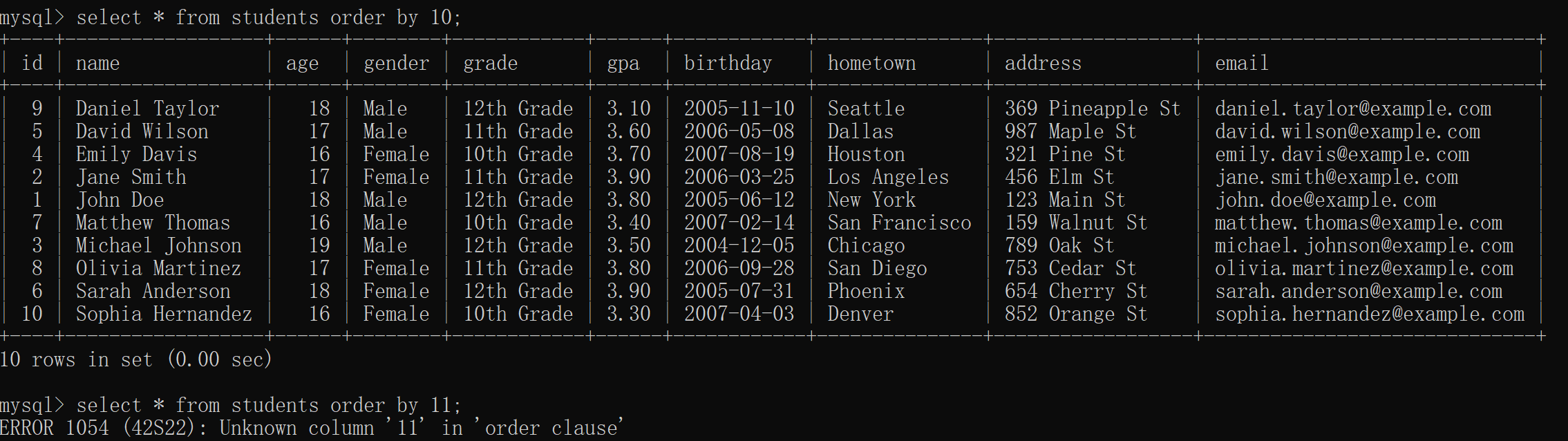
[root@localhost utils]# redis-cli -h 20.0.0.170 -p 6379
20.0.0.170:6379> info memory
used_memory:853336 //redis中数据占用的内存
used_memory_rss:10473472 //redis向操作系统申请的内存
used_memory_peak:854312 //redis使用内存的峰值
作为一个运维工程师,每天的系统巡检工作是必不可少的。(比如硬件巡检,数据库 nginx redis docker k8s )
但是在redis内存方面,最重要的就是以上三点
2.内存碎片率
内存碎片率=Redis向操作系统申请的内存 / Redis中的数据占用的内存
mem_fragmentation_ratio = used_memory_rss / used_memory
mem_fragmentation_ratio:内存碎片率。
系统以及分配给了redis,但是redis未能够有效利用的内存
[root@localhost ~]# redis-cli info memory | grep ratio
allocator_frag_ratio:1.29
//分配器碎片比例,redis主进程调度时产生的内存空间,越小越好
值越高,代表内存越高,内存的浪费就越多allocator_rss_ratio:5.99
分配器占用物理内存的比例,就算告诉大家主进程调度执行时占用了多少物理内存rss_overhead_ratio:1.22
rss是向系统申请的内存空间,表示redis占用物理内存额外的开销比例,比例越低越好。redis实际占用的物理内存和向系统申请的内存越接近,额外的开销越低mem_fragmentation_ratio:13.23
内存碎片的比例,越低越好,占用内存数值越低,表示内存使用率越高。
内存碎片产生的原因
- Redis内部有自已的内存管理器,为了提高内存使用的效率,来对内存的申请和释放进行管理。
- Redis中的值删除的时候,并没有把内存直接释放、交还给操作系统,而是交给了Redis内部有内存管理器。
- Redis中申请内存的时候,也是先看自己的内存管理器中是否有足够的内存可用。
- Redis的这种机制,提高了内存的使用率,但是会使Redis中有部分自己没在用,却不释放的内存,导致了内存碎片的发生。
如何自动清理碎片
vim /etc/redis/6379.conf
最后一行插入
activedefrag yes
手动清理
[root@localhost ~]# redis-cli memory purge
OK
手动清理
内存使用率
redis实例的内存使用率超过可用最大内存,操作系统将开始进行内存与swap空间交换。
避免内存交换发生的方法:
- 针对缓存数据大小选择安装Redis 实例
- 尽可能的使用Hash数据结构存储
- 设置key的过期时间
设置redis最大内存阀值

一旦到达阀值,自动清理碎片,开启key的回收机制。
key的回收机制策略
vim /etc/redis/6379.conf
line 599maxmemory-policy volatile-lru
使用redis内置的LRU算法,把已经设置了过期时间的键值对中淘汰数据,移除最近最少使用键值对(针值对已经设置了过期时间的键值对)maxmemory-policy volatile-ttl
已经设置了过期时间的键值对,从当中挑选一个即将过期的键值对(针对有设置过期时间的键值对)maxmemory-policy volatile-random:
从已经设置了过期时间的键值对当中随即淘汰一个键值对,挑选数据随机淘汰键值对。(对设置了过期时间的键值对进行随机移除。)allkeys-lru:
LRU算法当中,对所有的键值对进行淘汰,移除最少使用的键值对。(针对所有键值对)allkeys-random:
从所有键值对当中任意选择选择数据进行淘汰(无差别淘汰,不使用)maxmemory-policy noeviction
禁止键值对回收(不删除任何键值对,直到redis把内存塞满,写不了,报错)在工作中,一定要给redis 占用内存设置阀值 !!!!
而且在实际工作中,尽量使用禁止键值对回收,或者使用将最少使用键值对删除。
随机删除万万不可使用!!!!!
redis占用内存的效率问题如何解决
- 1.日常巡检当中,对redis的占用情况做监控
- 2.设置redis占用系统内存的阀值,避免占用系统全部内存
- 3.内存碎片清理 手动,自动
- 4.配置一个合适的key回收机制
redis的雪崩,缓存击穿,缓存穿透的原因和解决方案
redis的雪崩
大量的应用请求无法在redis 缓存当中处理,请求会全部发送到吗后台数据库,数据库本身并发能力本身就很差,一旦高并发数据库会很快崩溃。
什么情况会导致雪崩?
- redis集群大面积故障
- redis缓存中,大量数据同时过期,大量请求无法得到处理
- redis实例宕机
解决方案
- 事前:高可用架构,方式整个缓存故障。主从复制和哨兵模式,redis集群
- 事中:在国内用的比较多的方式:HySTRIX,熔断(到达阀值自动断开),降级(到达阀值立刻降级),限流三个手段来降低雪崩发生之后的损失。
- 数据库不死即可,慢可以,但不能没有响应
- 事后:数据备份
redis的缓存击穿
缓存击穿主要是热点数据缓存过期,或者被删除,多个请求并发访问热点数据,请求也是转发到数据库了,导致数据库的性能快速下降。
经常被请求的缓存数据,最好设置为永不过期。
键值对还在,但是值被替换,原有的请求找不到之后,同样也回去请求后台数据库,也是击穿的类型一种
redis的缓存穿透:
缓存中没数据,数据库中也没有对应数据,但是有用户一直在发起这个都没有的请求,而且请求的数据格式很大。黑客在利用漏洞攻击,压垮应用数据库。