文章目录
- 1. 业务处理
- 作用
- 功能
- 2. 代码框架编写
- 构造函数
- UpLoad ——文件上传请求
- ListShow —— 展示页面请求处理实现
- Download —— 下载请求的处理实现
- 断点续传实现
1. 业务处理
作用
业务处理模块是对客户端的业务请求进行处理
功能
1.文件上传请求:备份客户端上传的文件 响应上传成功
2.文件列表请求:客户端浏览请求备份一个备份文件的展示页面和响应页面
3.文件下载请求:通过展示页面 点击下载 响应客户端要下载的文件数据
2. 代码框架编写

_server_port ——服务端端口号
_server_ip ——服务端ip地址
_download_prefix ——下载请求前缀

因为业务处理模块 也会访问数据管理类
所以在service.hpp中 使用 extern 修饰 在cloud命名空间中的DataManger类中的 全局变量 _data 就可以在其他.c 或者.cpp中使用
构造函数

调用 Config类中的 GetInstance 函数 创建对象 config
再调用 config类中的 GetServerPort 函数 获取客户端端口号
调用GetServerIp 函数 获取客户端IP地址
调用 GetDownloadPrefix 函数 获取URL前缀路径

Post请求方法的 upload资源 表示文件上传
Get请求方法的listshow资源 表示文件列表请求
若只输入 / 表示什么都没有 没有任何资源路径请求
Get请求方法的 download资源,表示文件下载
使用正则表达式
.表示匹配除\n和\r之外的任何单个字符
*表示 匹配前面的子表达式任意次
. *表示匹配任意一个字符 任意次
UpLoad ——文件上传请求

首先判断有没有上传的文件区域
若没有上传的文件区域,就将其状态码设置为400 并返回

若有上传文件区域 ,则获取文件包含的各项数据
通过Config类中的getinstance函数 创建对象,再通过该对象去调用 GetBackDir函数 获取备份文件存放目录

realpath表示实际路径 由备份文件目录 加上 文件名组成
但是file文件中的filename 是包含路径的 ,所以通过调用FileUtil类的匿名对象 去调用FileName函数 获取文件名称即可

通过realpath 实例化一个 FileUtil类的 fu对象
调用Secontent函数 将realpath的数据写入文件中
通过Cloud类中的BackupInfo类 实例化一个对象 info
调用 NewBackupInfo函数 获取各项属性信息到 info中
再通过 DataManger类中的 Insert函数 将info中的信息 添加到 _table哈希表中

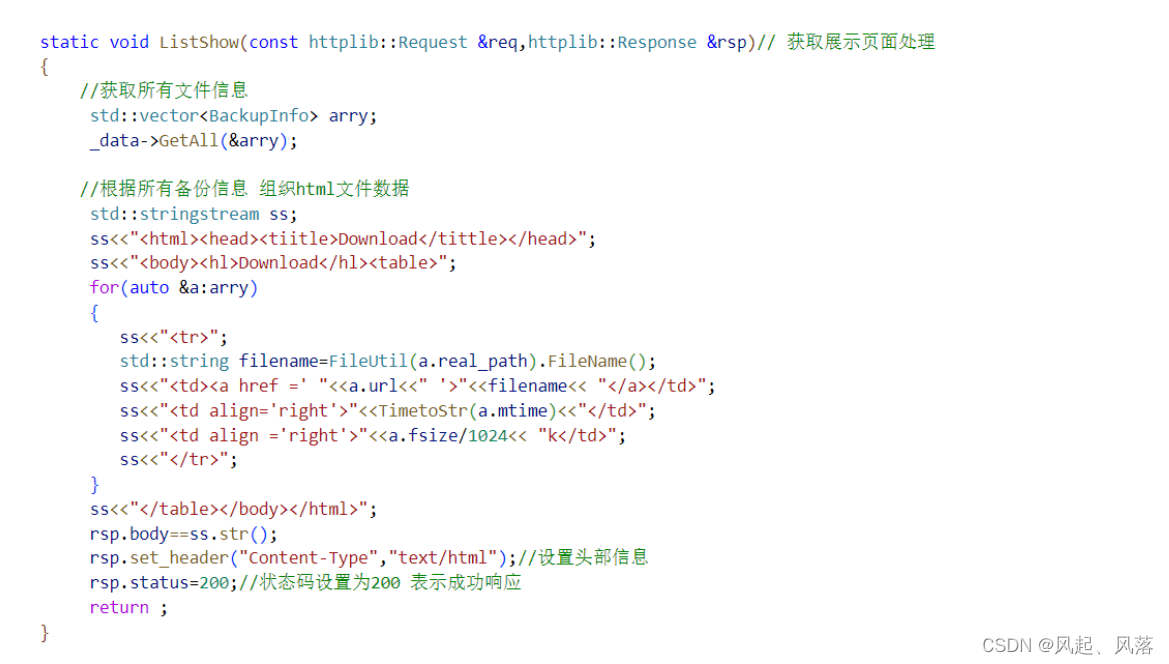
ListShow —— 展示页面请求处理实现

定义一个 BackupInfo类型的数组 arry
调用DataManger类中的 GetAll 函数 将table哈希表中的数据 全部放入 arry数组中

以当前html格式 将备份文件数据放入其中

定义一个 stringstream流 类型的变量 ss
将html格式的前两行数据先进行导入到ss中
由于中间的数据是每一个备份文件信息 所以需要遍历arry数组

而 URL链接 和文件名 应该随着每一个文件的不同而改变
所以就不能整体复制过来,需要分别复制
由于URL链接 是由一个双引号扩起来的,与字符串的双引号会造成冲突
在html中不区分双引号和单引号 因此改为单引号
文件名称通过文件实际存储路径 real_path 实例化一个匿名对象 来调用FileName 获取文件名
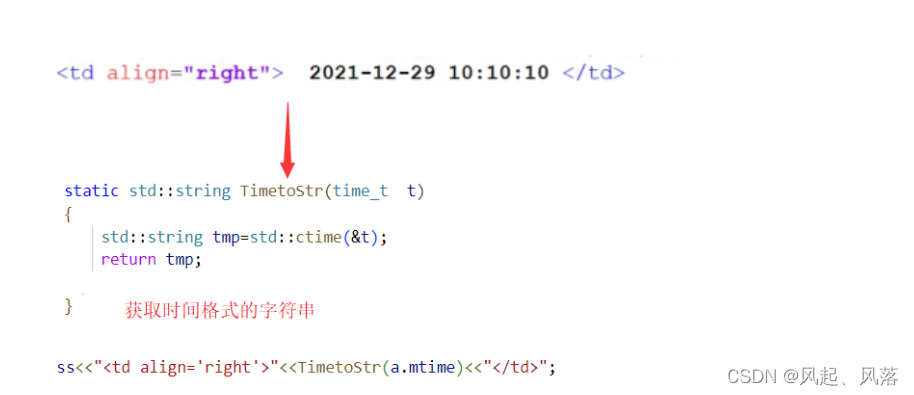
存储的是文件的最后一次修改时间,正常来说 只需用 mtime 即可
但是mtime是一个时间戳 所以调用接口 ctime 将时间戳转化为时间格式的字符串

调用 fsize函数 获取 文件大小 以字节为单位
而html中 是按照KB表示的,而1KB等于1024字节
所以使其除以1024 获取对应的KB个数
Download —— 下载请求的处理实现
http中的 ETag 字段 存储一个资源的唯一标识
客户端第一次下载文件时,会受到这个响应信息
第二次下载 就会将这个信息发送给服务器 想要让服务器根据唯一标识 判断这个资源有没有被修改过
如果没有被修改过 直接使用原先缓存的数据 不用重新下载了
http协议本身对与ETag中是什么数据并不关心 只要服务端能够自己处理即可
ETag 由 文件名 - 文件大小 - 最后一次修改时间 组成

设置 GetETag 函数 获取http中的 ETage字段

在 table哈希表中寻找 req.path ,若找到了req.path 则返回 对应的 value 值 并传给 info

BackupInfo 类的 pack_flag 变量 表示压缩标志
若pack_flag 为 true 则表示 被压缩 则进入判断中
pack_path 表示 压缩包路径
使用pack_path 实例化一个 FileUtil类的对象 fu
real_path 表示 文件实际存储路径
调用 UnCompress 函数 将 pack_path 解压缩 并将其中的数据 放入 real_path 备份目录中
将pack_flag 改为 false 并使用 update函数 向 table 哈希表中 对应的 path中 更新对应的key值 info

通过 real_path 实例化一个 FileUtil类的对象 fu
调用 GetContent 函数 将 real_path中的数据 放入 body 中

断点续传实现
功能: 当文件下载过程中 因为某种异常而中断 如果再次进行从头下载 效率比较低
因为需要将之前已经传输过的数据 再次传输一遍
因此断点续传 就是从上次下载断开的位置 重新下载即可 之前已经传输过的数据 将不需要重新传输
目的:提高文件的重新传输效率
实现思想:客户端在下载文件的时候 要每次接收到数据 写入文件后记录自己当前下载的数据量
当异常下载中断时,下次断点续传时候 将要重新下载的数据区间(下载的起始位置 和结束位置)
发送给服务器 服务器收到后 仅仅回传 客户端需要的区间数据即可
需要考虑的问题:
若上传下载文件之后 这个文件在服务器上被修改了 则这时候将不能重新断点续传
而是应该重新进行文件下载操作
在http协议中断点续传的实现:
告诉服务器下载区间范围
服务器上要检测 上一次下载之后 这个文件是否被修改过
206状态码 状态码描述为 Partial Content
表示 部分内容 服务器成功处理部分GET请求
即处理区间范围内的请求
在上述 Download函数中 进行修改

retrans表示断点续传 默认设置为false
定义一个string类型的字符串 old_etag 将If-Range字段对应的value值 传给 old_etag
调用 GetETag函数 获取 Etag字段
将 if_range字段的value值 与 请求文件最新的etag比较 ,若一致 则说明为断点续传

httplib 内部 对 Range 请求 已经 做出了 额外的操作
外部用户只需把文件的所有数据 读取到 response的 body中即可
自己就会根据 所请求的区间范围 进行处理 从body中截取指定范围的数据 进行客户端的响应