arXiv-2021
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
- 5 Experiments
- 5.1 Datasets and Metrics
- 5.2 Ablation Study
- 5.3 Comparison with State-of-the-Arts
- 6 Conclusion(own)
1 Background and Motivation
尺度变化是人脸检测中最具挑战性的问题之一

Modern face detectors employ feature pyramids to deal with scale variation
但是特征金字塔存在如下问题:
it might break the feature consistency across different scales of faces(想表达的是一定范围的尺寸人脸,eg 50~100大小的,都落在一张特征图上,怕特征图 hold 不住)
作者对特征金字塔进行改进,提出 EMFace(EXPLORING RECEPTIVE)
2 Related Work
- CNN-based face detection
- receptive fields for recognition tasks
- ASPP
- RFB Net
- Deformable convolution
3 Advantages / Contributions
- 提出 EMFace,核心模块为感受野金字塔(Receptive Field Pyramid)
- 感受野金字塔中的 pooling 模块,多分支训练,单分支测试,速度得以提升
- 在 WIDER FACE 和 UFDD 数据集上,验证了其速度和精度

The branch pooling balances the representations of parallel branches during training and enables a single branch to implement inference during testing
4 Method

特征金字塔 P2~P7,这个本身应该提点很猛,哈哈哈
RFP 的细节如下
- multi-branch convolution layer
- branch pooling layer

先经过三个权重共享的空洞卷积+残差结构

再接个 Branch Pooling 结构

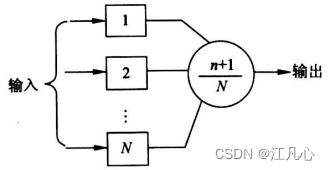
B = 3
RFP 输入输出维度相同
代码:https://github.com/emdata-ailab/EMface
class MRF(nn.Module):def __init__(self,in_planes):super(MRF,self).__init__()self.share_weight=nn.Parameter(torch.randn(in_planes,in_planes,3,3)) # 共享权重,卷积核 3x3self.bn1=nn.BatchNorm2d(in_planes)self.bn2=nn.BatchNorm2d(in_planes)self.bn3=nn.BatchNorm2d(in_planes)self.relu1=nn.ReLU(inplace=True)self.relu2=nn.ReLU(inplace=True)self.relu3=nn.ReLU(inplace=True)def forward(self,x):residual=xx1=F.conv2d(x,self.share_weight, stride=1, padding=1,bias=None, dilation=1)x1=self.bn1(x1)x1=x1+residualx1=self.relu1(x1)x2=F.conv2d(x,self.share_weight, stride=1, padding=3,bias=None, dilation=3)x2=self.bn2(x2)x2=x2+residualx2=self.relu2(x2)x3=F.conv2d(x,self.share_weight,stride=1, padding=5,bias=None, dilation=5)x3=self.bn3(x3)x3=x3+residualx3=self.relu3(x3)y=torch.cat((x1, x2, x3), dim=1) # (n, 3*in_planes, h, w)b,c,h,w=y.size()y=y.view(b,3,c//3,h,w) # (n, 3, in_planes, h, w)y1=y.mean(dim=1,keepdim=True) # (n, 1, in_planes, h, w)y=y1.view(b,-1,h,w) # (n, in_planes, h, w)return y
调用
self.MR1=MRF(256)
self.MR2=MRF(256)
self.MR3=MRF(256)
self.MR4=MRF(256)
self.MR5=MRF(256)
self.MR6=MRF(256)
5 Experiments
ResNet50 + FPN
5.1 Datasets and Metrics
WIDER FACE and UFDD




metrics 为 AP
5.2 Ablation Study
(1)Number of Branches

3 个 Branch 计算量和精度权衡最好
(2)Weight Sharing.

RFP 中 multi-branch convolution 的权重 share 参数量减少很多,精度略微下降
(3)Branch Pooling.

训练的时候 3 branches,测试的时候选择不同的输出方式,输出数量,输出组合形式(BP,add,concat)
we drop out the Branch-1 and Branch-3 (d=1 and d=5 in Figure 4) in RFP and only keep the Branch-2 to output in the
inference phase.
作者测试时最终仅保留了 branch-2 作为输出

5.3 Comparison with State-of-the-Arts
(1)WIDER FACE

(2)UFDD

6 Conclusion(own)
- 标题单词都搞错了,哈哈,pyramids