阅读笔记
模型选择:是否一定要选择参数量巨大的模型?如果需要更好的泛化能力,用于处理非单一的任务,例如对话,则可用选更大的模型;而对于单一明确的任务,则不一定越大越好,参数小一些的模型也能调教得很好。
接口交互:大语言模型可以使用网络请求接口获取其本身在预训练中没有的额外信息。
多模态:大语言模型展现出良好的多模态理解能力,特别是对于图片数据的处理能力。因此其对于一个网络中拓扑结构、流量矩阵等数据也是存在了可以理解和处理的可能的。
语言如何输入:自然语言首先需要被tokenize,从而将其用数字进行表示,使其可以正式输入模型。在输入模型后,还会进行词嵌入表示(或者是词的分布式表示),也就是进一步用多维向量表示一个词。词嵌入并非Transformer首创,此前的工作中已经在广泛使用词嵌入方法了,大名鼎鼎的Word2Vec就是其中一种。
“预训练和微调”学习范式:预训练是从CV兴起而后借鉴到NLP的一种训练方法,通常是无监督的。对于PLM,通常使用大量语料进行预训练,其过程无需人工标记,而是利用已有的词句信息对某一词进行预测。微调是指在PLM的基础上,进一步根据下游子任务的要求,对PLM进行更具针对性的有监督训练(包括对齐)并更新参数,使其适应子任务。微调主要分为指令微调和对齐微调。对于一些领域的子任务,PLM甚至无需微调也能依靠自身的上下文学习能力达到不错的效果。
与人类对齐:由于预训练数据不可避免参杂与主流价值观不符的内容,模型需要与人类价值观或偏好进行对齐,以减少危害并增加性能。相关工作利用带人类反馈的强化学习(RLHF)进行微调对齐。
扩展与扩展法则:语言模型在模型规模、数据规模和总计算量上的扩展,一般会使模型具备更好的特性与理解输出能力,并更可能涌现能力(包括上下文学习、指令遵循、逐步推理等)。LLMs由于规模扩展而产生的影响的现象成为扩展效应,有相关研究定量描述了LLMs的扩展法则。
代码数据训练提高CoT提示能力:Codex是在PLM基础上使用大量Github代码微调的GPT模型,可以解决困难的编程问题并在数学问题上有显著性能提升,猜测称代码训练可提高其思维链(CoT)提示能力。
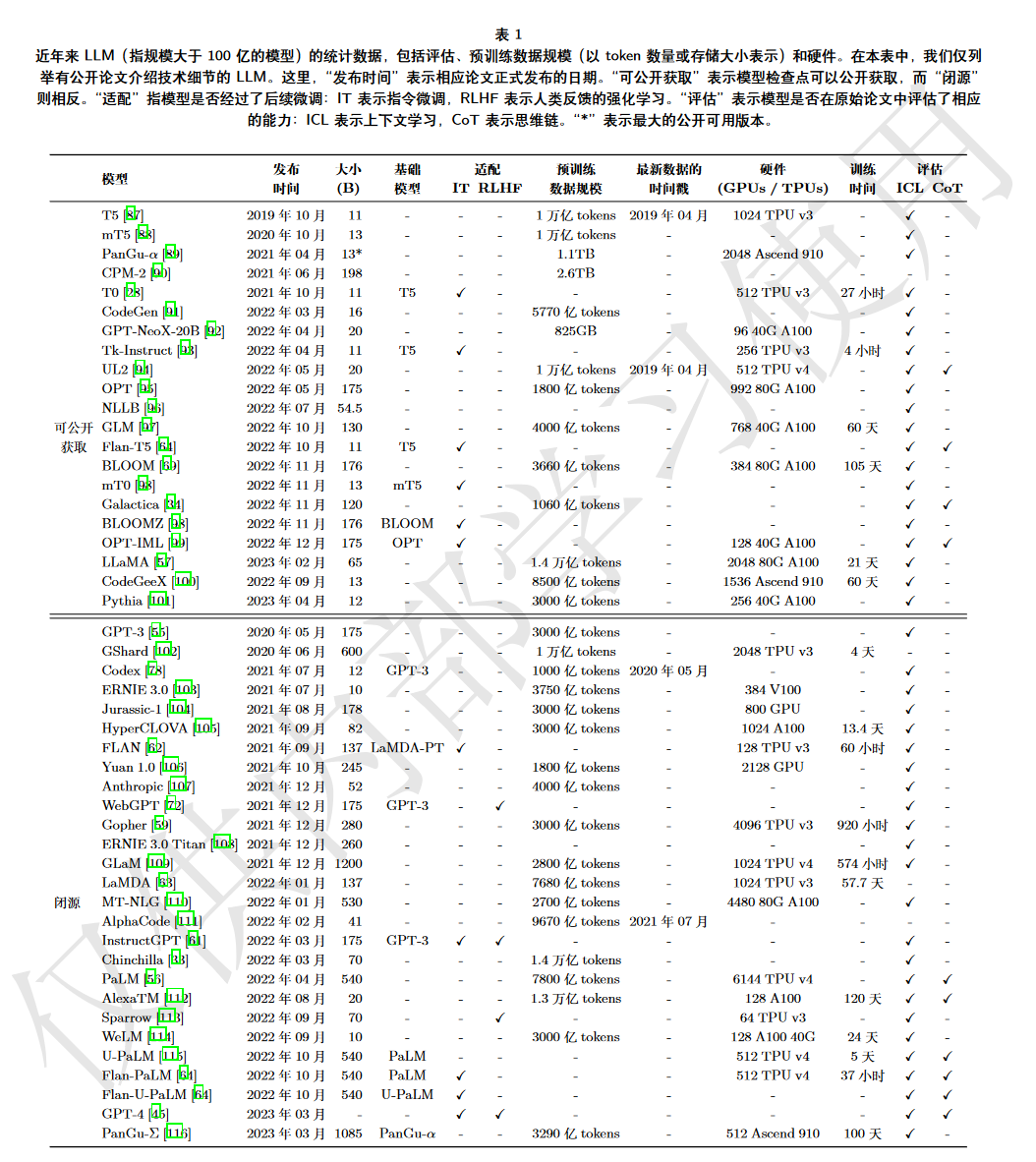
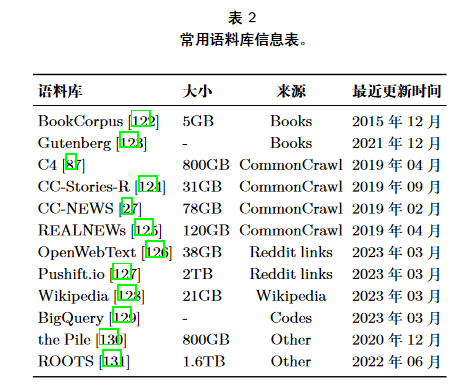
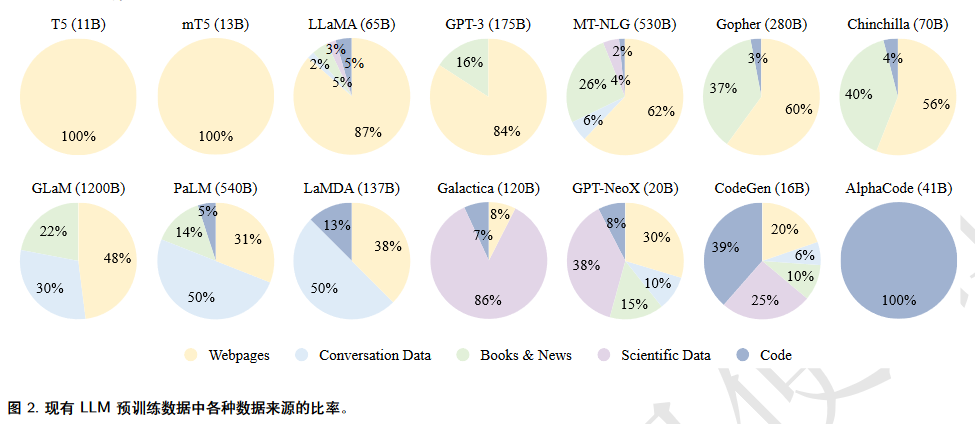
LLMs资源:LLMs的预训练需要耗费大量资源(微调更新权重也很消耗),建议在已有开源资源基础上进行开发,包括开源模型和公共API(可微调),以及公开语料库,详细信息下面四张图总结得很好。

模型训练:预训练阶段的任务通常有语言建模和去噪自编码,语言建模任务针对不同模型结构(因果解码器casual decoder、前缀解码器prefix decoder等)有不同任务变体。此外,训练LLM时最为重要的便是设置和技巧。
-
训练中动态增大batch size以有效稳定LLM训练过程
-
动态学习率策略如初始采用线性增加预热策略,后续采用余弦衰减策略
-
使用权重衰减和梯度裁剪来稳定训练,避免模型崩溃。
-
采用数据并行、流水线并行、张量并行、ZeRO和混合精度训练等方法在有限资源情况下进行高效的并行化训练。
RLHF用于微调:在有监督微调结束后,可以应用基于人类反馈的强化学习来进行对齐微调,更好地学习人类偏好。其中较为关键的我认为有两方面,一方面是奖励模型,相关工作使用有标注数据有监督地训练一个奖励模型预测人类偏好;另一方面是将LLM的微调形式化为强化学习问题。
LLM使用:经过预训练或微调后,模型的使用也别有学问,OpenAI的报告中大量做了这方面的文章。较为著名的使用策略有上下文学习和思维链提示。
LLM评估:主流的评估方法是在公共NLP任务数据集上进行测试评估。而专用于网络配置或是其他类似子任务的公共数据集暂时没有看到。因此这方面的评估需要进一步的设计和探讨。
LLM主要问题:在语言生成方面,其可控生成和专业化生成能力仍然面临挑战,例如在一般类型数据集训练的LM用于涉及专业知识的医学报告时。在知识利用方面,LM存在幻觉和知识实时性问题。前者表示LM会捏造事实,后者表示LM难以处理需要更新鲜知识的任务。在复杂推理方面,LM存在不一致性和数值计算问题。前者表示LM的推理路径与结果并不一致,后者表示LM的数值计算能力仍然有待提高。
个人感想
- 此篇论文很好地揭示了LLM在结构、预训练、微调、评估等等诸多方面的细节。但由于技术日新月异,比较遗憾地是没有看到更新的关于多模态方面的介绍。
- LLM的训练与微调有资源门槛,但有公开的模型可通过API进行微调,这一点可以考虑加以利用。







![[蓝桥杯 2019 省 B] 特别数的和-C语言的解法](https://img-blog.csdnimg.cn/65eed59a4f1044378c95f3d03e7d3cd1.png)