1.练习一
| 1.数据准备 在hdfs上创建文件夹,上传csv文件 [root@kb129 ~]# hdfs dfs -mkdir -p /app/data/exam
查看csv文件行数 [root@kb129 ~]# hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l |
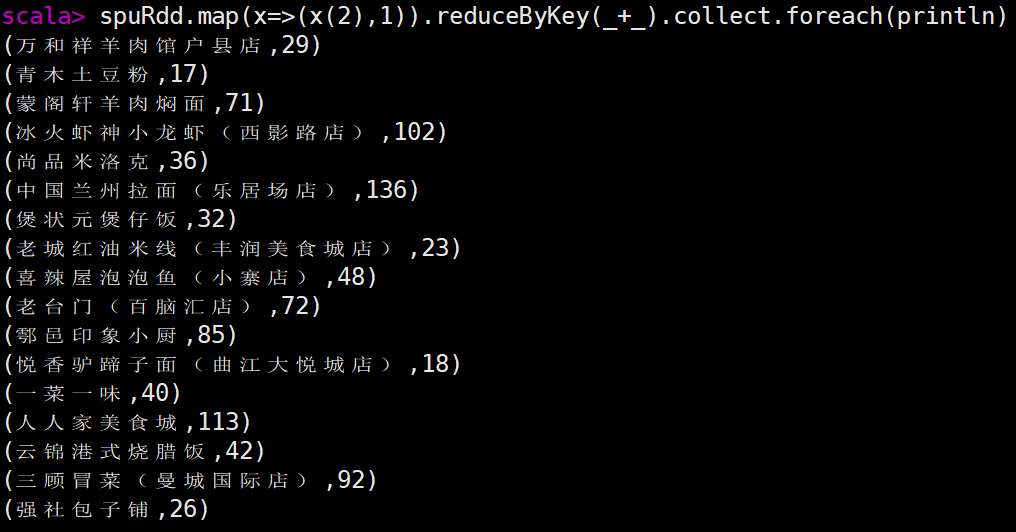
| 2.分别使用 RDD和 Spark SQL 完成以下分析(不用考虑数据去重) 开启spark shell [root@kb129 ~]# spark-shell (1)加载csv文件,创建RDD scala> val fileRdd = sc.textFile("/app/data/exam/meituan_waimai_meishi.csv") 打印查看 scala> fileRdd.collect.foreach(println) split两种用法 scala> a.map(x=>x.split(",")).collect.foreach(x=>println(x.toList)) List(a, b, c) List(a, b, c, d) List(a, b) scala> a.map(x=>x.split(",",-1)).collect.foreach(x=>println(x.toList)) List(a, b, c) List(a, b, c, d) List(a, b, , , ) 初步准备RDD,清洗数据(过滤掉首行,通过split切割数据(保留空字段),筛选保留字段长度为12的数据) scala> val spuRdd = fileRdd.filter(x=>x.startsWith("spu_id")==false).map(x=>x.split(",",-1)) .filter(x=>x.size==12) (2)使用 Spark,加载 HDFS 文件系统 meituan_waimai_meishi.csv 文件, 并分别使用 RDD和 Spark SQL 完成以下分析(不用考虑数据去重) 1)RDD操作 scala> spuRdd.collect.foreach(x=>println(x.toList)) 统计每个店铺分别有多少商品(SPU) scala> spuRdd.map(x=>(x(2),1)).reduceByKey(_+_).collect.foreach(println)
统计每个店铺的总销售额 scala> spuRdd.map(x=>(x(2),x(5).toDouble*x(7).toInt)).filter(x=>x._2>0).reduceByKey(_+_) .collect.foreach(println)
统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额, 其中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计 scala>spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1) .mapValues(x=>x.toList.sortBy(item=>0-item._3).take(3)).flatMapValues(x=>x).map(x=>x._2) .collect.foreach(println) 第二种方式 scala>spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1) .flatMap(x=>{x._2.toList.sortBy(item=>0-item._3).take(3)}).collect.foreach(println) 第三种方式 scala>spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1) .map(x=>{x._2.toList.sortBy(i=>0-i._3).take(3)}).flatMap(x=>x).collect.foreach(println)
2)使用spark Sql方式查询 读取hdfs中的文件,创建RDD scala>val spuDF = spark.read.format("csv").option("header",true).option("inferSchema",true) .load("hdfs://kb129:9000/app/data/exam/meituan_waimai_meishi.csv") 创建表视图,通过SQL语句查询 scala> spuDF.createOrReplaceTempView("spu") 统计每个店铺分别有多少商品(SPU) scala> spark.sql("select shop_name, count(spu_name) as num from spu group by shop_name").show
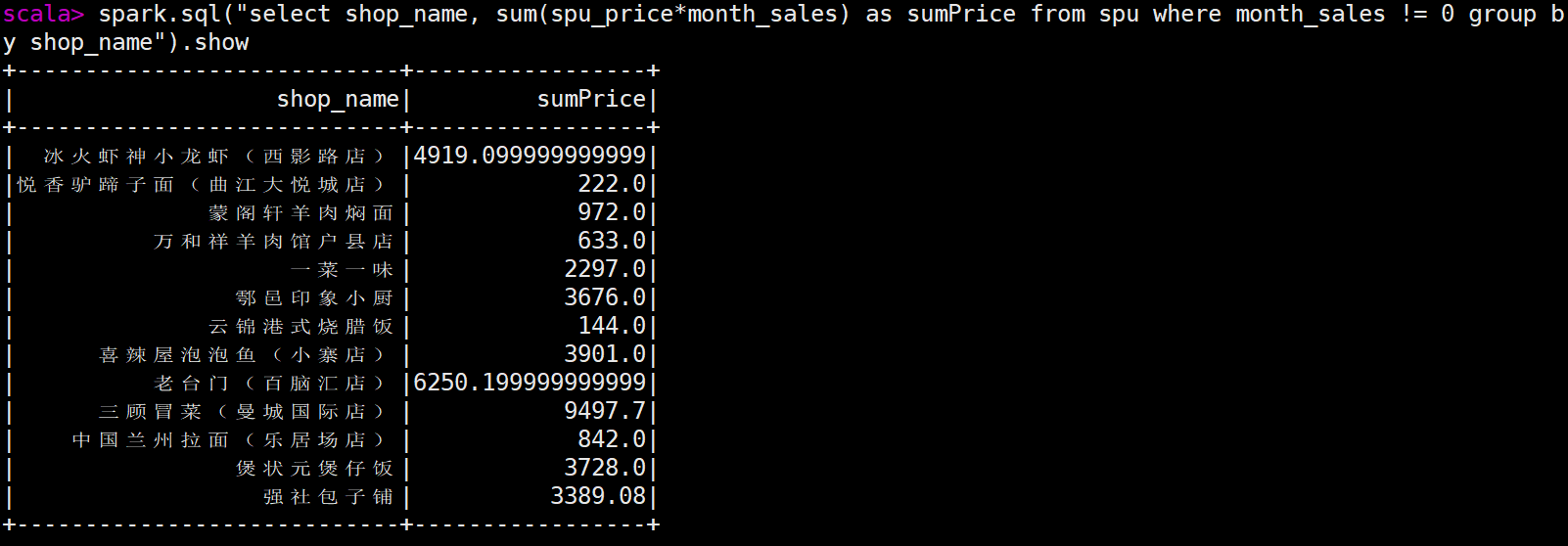
统计每个店铺的总销售额 scala> spark.sql("select shop_name, sum(spu_price*month_sales) as sumPrice from spu where month_sales != 0 group by shop_name").show
统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计 spark.sql("select t.shop_name, t.spu_name, t.money, t.rank from (select shop_name, spu_name, spu_price*month_sales as money, row_number() over(partition by shop_name order by spu_price*month_sales desc) as rank from spu where month_sales != 0) t where t.rank < 4").show(100)
|
| 3. 在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 spu 表,该表下有1 个列族 result。 启动zookeeper并启动Hbase [root@kb129 ~]# zkServer.sh start [root@kb129 ~]# start-hbase.sh [root@kb129 ~]# hbase shell 创建namespace hbase(main):004:0> create_namespace 'exam202009' 创建表 hbase(main):006:0> create 'exam202009:spu','result' 查看表 hbase(main):007:0> list_namespace_tables 'exam202009' 在 Hive 中 创 建 数 据 库 spu_db , 在 该 数 据 库 中 创 建 外 部 表 ex_spu 指 向/app/data/exam 下的测试数据 ;创建外部表 ex_spu_hbase 映射至 HBase 中的 exam:spu表的 result 列族 启动hive [root@kb129 ~]# hive 创建数据库 hive (default)> create databases spu_db; 切换数据库 hive (default)> use spu_db; 创建外部表ex_spu指向/app/data/exam下的测试数据 ex_spu 表结构如下: 字段名称 中文名称 数据类型 spu_id 商品 spuID string shop_id 店铺 ID string shop_name 店铺名称 string category_name 类别名称 string spu_name SPU 名称 string spu_price SPU 商品价格 double spu_originprice SPU 商品原价 double month_sales 月销售量 int praise_num 点赞数 int spu_unit SPU 单位 string spu_desc SPU 描述 string spu_image 商品图片 string 创建外部表 ex_spu_hbase 映射至 HBase 中的 exam:spu表的 result 列族 ex_spu_hbase 表结构如下: 字段名称 字段类型 字段含义 key string rowkey sales double 销售额 praise int 点赞数 创建表映射Hbase 统计每个店铺的总销售额 sales, 店铺的商品总点赞数 praise,并将 shop_id 和shop_name 的组合作为 RowKey,并将结果映射到 HBase 导入查询数据至HBase中 完成统计后,分别在 hive 和 HBase 中查询结果数据 hive (spu_db)> select * from ex_spu_hbase limit 3; hbase(main):009:0> scan 'exam202009:spu' |




2.练习二
| 1.数据准备 1)在 HDFS 中创建目录/data/userbehavior,并将 UserBehavior.csv 文件传到该目 录 [root@kb129 ~]# hdfs dfs -mkdir -p /data/userbehavior [root@kb129 ~]# hdfs dfs -mkdir -put /opt/examdata/UserBehavior.csv /data/userbehavior 2)通过 HDFS 命令查询出文档有多少行数据 [root@kb129 ~]# hdfs dfs -cat /data/userbehavior/UserBehavior.csv | wc -l |
| 2.数据清洗 1)在 Hive 中创建数据库 exam hive (exam)> create database exam; hive (exam)> use exam; 2)在 exam 数据库中创建外部表 userbehavior,并将 HDFS 数据映射到表中 3)在 HBase 中创建命名空间 exam,并在命名空间 exam 创建 userbehavior 表,包 含一个列簇 info hbase(main):003:0> create_namespace 'exam202010' hbase(main):004:0> create 'exam202010:userbehavior','info' 4)在 Hive 中创建外部表 userbehavior_hbase,并映射到 HBase 中,并将数 据加载到 HBase 中 hive (exam)> insert into userbehavior_hbase (select * from userbehavior); 查看 hive (exam)> select * from userbehavioe_hbase limit 3; hbase(main):006:0> scan 'exam202010:userbehavior' 5)在 exam 数据库中创建内部分区表 userbehavior_partitioned(按照日期进行分区), 并通过查询 userbehavior 表将时间戳格式化为”年-月-日 时:分:秒”格式,将数据插 入至 userbehavior_partitioned 表中 插入数据 hive (exam)> set hive.exec.dynamic.partition=true; hive (exam)> set hive.exec.dynamic.partition.mode=nonstrict; hive (exam)> insert into table userbehavior_partitioned partition (dt) select user_id, item_id,category_id,behavior_type ,from_unixtime(`time`) as `time`,from_unixtime(`time`,'yyyy-MM-dd') as dt from userbehavior; 查看分区 hive (exam)> show partitions userbehavior_partitioned; |
| 3.用户行为分析 请使用 Spark,加载 HDFS 文件系统 UserBehavior.csv 文件,并分别使用 RDD 完成以下 分析。 scala> val fileRdd = sc.textFile("/data/userbehavior/UserBehavior.csv") 1)统计 uv 值(一共有多少用户访问淘宝) scala> fileRdd.map(_.split(",")).filter(_.length==5).map(_(0)).distinct().count res2: Long = 5458 或 scala> fileRdd.map(_.split(",")).filter(_.length==5).groupBy(_(0)).count 2)分别统计浏览行为为点击,收藏,加入购物车,购买的总数量 scala> fileRdd.map(_.split(",")).filter(_.length==5) .map(x=>(x(3),1)).reduceByKey(_+_).collect.foreach(println) (cart,30888) (buy,11508) (pv,503881) (fav,15017) 或 scala> fileRdd.map(_.split(",")).filter(_.length==5).map(x=>(x(3),1)).groupByKey() .map(x=>(x._1,x._2.toList.size)).collect.foreach(println) |
| 4.找出有价值的用户 1)使用 SparkSQL 统计用户最近购买时间。以 2017-12-03 为当前日期,计算时间范围 为一个月,计算用户最近购买时间,时间的区间为 0-30 天,将其分为 5 档,0-6 天,7-12 天,13-18 天,19-24 天,25-30 天分别对应评分 4 到 0 2)使用 SparkSQL 统计用户的消费频率。以 2017-12-03 为当前日期,计算时间范围为 一个月,计算用户的消费次数,用户中消费次数从低到高为 1-161 次,将其分为 5 档,1-32,33-64,65-96,97-128,129-161 分别对应评分 0 到 4 |
3.练习三
| 1.数据准备 在 HDFS 中创建目录/app/data/exam,并将 countrydata.csv 传到该目录 查看数据行数 [root@kb129 ~]# hdfs dfs -cat /app/data/exam/countrydata.csv | wc -l |
| 2.在 Spark-Shell 中,加载 HDFS 文件系统 countrydata.csv 文件,并使用 RDD 完成以下统计计算。 scala> val fileRdd = sc.textFile("/app/data/exam/countrydata.csv") scala> val yqRdd = fileRdd.map(x=>x.split(",")) 1)统计每个国家在数据截止统计时的累计确诊人数。 scala>yqRdd.map(x=(x(4),x(1).toInt)).reduceByKey((v1,v2)=>Math.max(v1,v2)).collect.foreach(println) scala> yqRdd.map(x=>(x(4),x(2).toInt)).reduceByKey(_+_).collect.foreach(println) 2)统计全世界在数据截止统计时的总感染人数。 scala>fileRdd.filter(x=>(x(3).toInt-20200702<=0)).map(x=>("sum",x(2).toInt)).reduceByKey(_+_).map(x=>x._2).collect.foreach(println) scala> yqRdd.map(x=>(x(4),x(2).toInt)).reduceByKey(_+_).reduce((x,y)=>("all",x._2+y._2)) res5: (String, Int) = (all,10755671) 3)统计每个大洲中每日新增确诊人数最多的国家及确诊人数,并输出 20200408 这一天各 大洲当日新增确诊人数最多的国家及确诊人数。 第一问 scala> yqRdd.map(x=>((x(6),x(3)),(x(1).toInt,x(2).toInt,x(4)))) .reduceByKey((v1,v2)=>{if(v1._2>v2._2) v1 else v2}).collect.foreach(println) 第二问 scala> yqRdd.map(x=>((x(6),x(3)),(x(1).toInt,x(2).toInt,x(4)))) .reduceByKey((v1,v2)=>{if(v1._2>v2._2) v1 else v2}) .filter(x=>x._1._2=="20200408") .map(x=>(x._1._1,x._1._2,x._2._3,x._2._1,x._2._2)).collect.foreach(println)
4)统计每个大洲中每日累计确诊人数最多的国家及确诊人数,并输出 20200607 这一天各 大洲当日累计确诊人数最多的国家及确诊人数。 第一问 scala> yqRdd.map(x=>((x(6),x(3)),(x(1).toInt,x(2).toInt,x(4)))) .reduceByKey((v1,v2)=>{if(v1._1>v2._1) v1 else v2}) .map(x=>(x._1._1,x._1._2,x._2._3,x._2._1,x._2._2)).collect.foreach(println) 第二问 scala> yqRdd.map(x=>((x(6),x(3)),(x(1).toInt,x(2).toInt,x(4)))) .reduceByKey((v1,v2)=>{if(v1._1>v2._1) v1 else v2}) .filter(x=>x._1._2=="20200607") .map(x=>(x._1._1,x._1._2,x._2._3,x._2._1,x._2._2)).collect.foreach(println) (北美洲,20200607,美国,1938931,19501) (南美洲,20200607,巴西,691962,32848) (亚洲,20200607,印度,246628,9971) (其他,20200607,钻石公主号邮轮,712,0) (非洲,20200607,南非,48285,2312) (欧洲,20200607,俄罗斯,467673,8984) (大洋洲,20200607,澳大利亚,7255,4) 5)统计每个大洲每月累计确诊人数,显示 202006 这个月每个大洲的累计确诊人数 scala> yqRdd.map(x=>((x(6),x(3).substring(0,6)),(x(2).toInt))).reduceByKey(_+_) .filter(x=>x._1._2 == "202006").collect.foreach(println) ((北美洲,202006),1069682) ((欧洲,202006),461525) ((大洋洲,202006),690) ((亚洲,202006),1151411) ((其他,202006),0) ((南美洲,202006),1357019) ((非洲,202006),258433) |
| 3.创建 HBase 数据表 在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 covid19_world 表,使用大洲和统计日期的组合作为 RowKey(如“亚洲 20200520”),该表下有 1 个列族record。record 列族用于统计疫情数据(每个大洲当日新增确诊人数最多的国家record:maxIncreaseCountry 及其新增确诊人数 record:maxIncreaseCount)。 hbase(main):009:0> create_namespace 'exam202011' hbase(main):009:0> create 'exam202011:covid19_world','record' |
| 4.在 Hive 中创建数据库 exam,在该数据库中创建外部表 ex_exam_record 指向/app/data/exam 下的疫情数据 ;创建外部表 ex_exam_covid19_record 映射至 HBase 中的exam:covid19_world 表的 record 列族 ex_exam_record 表结构如下: 字段名称 字段类型 字段含义 id string 记录 ID confirmedCount int 累计确诊人数 confirmedIncr int 新增确诊人数 recordDate string 记录时间 countryName string 国家名 countryShortCode string 国家代码 continent string 大洲 ex_exam_covid19_record 表结构如下: 字段名称 字段类型 字段含义 key string rowkey maxIncreaseCountry string 当日新增确诊人数最多的国家 maxIncreaseCount int 新增确诊人数 |
| 5. 使用 ex_exam_record 表中的数据 1)统计每个大洲中每日新增确诊人数最多的国家,将 continent 和 recordDate 合并成 rowkey,并保存到 ex_exam_covid19_record 表中。 2)完成统计后,在 HBase Shell 中遍历 exam:covid19_world 表中的前 20 条数据。 hbase(main):009:0> scan 'exam202011:covid19_world',LIMIT=>20 |

4.练习四
| 1.数据准备 请在 HDFS 中创建目录/app/data/exam,并将 answer_question.log 传到该目录。 [root@kb129 ~]# hdfs dfs -cat /app/data/exam202101/answer_question.log | wc -l |
| 2.在 Spark-Shell 中,加载 HDFS 文件系统 answer_question.log 文件,并使用 RDD 完成 以下分析,也可使用 Spark 的其他方法完成数据分析。 scala> val rdd = sc.textFile("/app/data/exam202101/answer_question.log") 1)提取日志中的知识点 ID,学生 ID,题目 ID,作答结果 4 个字段的值 2)将提取后的知识点 ID,学生 ID,题目 ID,作答结果字段的值以文件的形式保存到 HDFS的/app/data/result 目录下。一行保留一条数据,字段间以“\t”分割。文件格式如下所示。(提示:元组可使用 tuple.productIterator.mkString("\t")组合字符串,使用其他方法处 理数据只要结果正确也给分) 34434481 8195023659599 1018 0 34434425 8195023659599 7385 1 34434457 8195023659596 7346 1 34434498 8195023659597 6672 0 34434449 8195023659594 4809 1 34434489 8195023659596 7998 0.5 34434492 8195023659595 9406 0 34434485 8195023659597 8710 1 |
| 3.创建 HBase 数据表 在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 analysis 表,使用学生 ID 作为 RowKey,该表下有 2 个列族 accuracy、question。accuracy 列族用于保存学 员 答 题 正 确 率 统 计 数 据 ( 总 分 accuracy:total_score , 答 题 的 试 题 数accuracy:question_count,正确率 accuracy:accuracy);question 列族用于分类保存学员正确,错 误和半对的题目 id (正确 question:right,错误 question:error,半对question:half) hbase(main):019:0> create_namespace 'exam202101' hbase(main):019:0> create 'exam202101:analysis','accuracy','question' |
| 4.请在 Hive 中创建数据库 exam,在该数据库中创建外部表 ex_exam_record 指向/app/data/result 下 Spark 处理后的日志数据 ;创建外部表 ex_exam_anlysis 映射至 HBase中的 analysis 表的 accuracy 列族;创建外部表 ex_exam_question 映射至 HBase 中的analysis 表的 question 列族 ex_exam_record 表结构如下: 字段名称 字段类型 字段含义 topic_id string 知识点 ID student_id string 学生 ID question_id string 题目 ID score float 作答结果 ex_exam_anlysis 表结构如下: 字段名称 字段类型 字段含义 student_id string 学生 ID total_score float 总分 question_count int 答题的试题数 accuracy float 正确率 ex_exam_question 表结构如下: 字段名称 字段类型 字段含义 student_id string 学生 ID right string 所有作对的题目的 ID 列表 half string 所有半对的题目的 ID 列表 error float 所有做错的题目的 ID 列表 |
| 5.使用 ex_exam_record 表中的数据统计每个学员总分、答题的试题数和正确率,并保存 到 ex_exam_anlysis 表中,其中正确率的计算方法如下: 正确率=总分/答题的试题数 |
| 6.使用 ex_exam_record 表中的数据统计每个作对,做错,半对的题目列表。 1)题目 id 以逗号分割,并保存到 ex_exam_question 表中 2)完成统计后,在 HBase Shell 中遍历 exam:analysis 表并只显示 question 列族中的数据 hbase(main):011:0> scan 'exam202101:analysis',COLUMN=>'question' |