利用Flask+Postman为深度学习模型进行快速测试,以及算法中的一些实例,以后会更新一些新的模板~~
#本文环境:服务器Ubuntu20.04(docker)
目录
1.下载postrman
2.编写flas的app文件
3.在postrman发送请求
4.实例
在服务器创建app.py文件
在服务器运行app.py文件
打开Win上的postman
输入刚运行提示的网址和端口编辑
打开form-data,在Value出输入需要合成的文本
点击发送(Send)
参考文献
1.下载postrman
在win10上下载postrman
下载地址:Download Postman | Get Started for Free

下载后双击安装就可以啦~
2.编写flas的app文件
在服务器编写app.py文件
from flask import Flaskapp = Flask(__name__)@app.route("/")
def hello_world():return "<p>Hello, World!</p>"app.run(host='0.0.0.0', port=1180)
#默认端口号5000,如果运行api后出现404,可能是端口号被占用,改一下端口号就好啦~运行后就就会出现

3.在postrman发送请求
依次点击New->Collections->
输入网址后,点击Send发送,如图

4.语音合成实例
在服务器创建app.py文件
# @ Date: 2023.12.04
# @ Elenaimport sys
from flask import Flask, request, jsonify,render_template
from flask.views import MethodView
from flask_cors import CORS
import argparse
import base64
import librosa
import numpy as np
import matplotlib.pyplot as plt
import io
import loggingimport soundfile
import torchfrom flask import Flask, request, send_file,jsonify
from flask_cors import CORS
from flask.views import MethodView
import commons
import utils
from data_utils import TextAudioLoader, TextAudioCollate, TextAudioSpeakerLoader, TextAudioSpeakerCollate
from models import SynthesizerTrn
from text.symbols import symbols
from text import text_to_sequence
import langdetectfrom scipy.io.wavfile import write
import re
from scipy import signal
import time
from inference import vcss# check device
if torch.cuda.is_available() is True:device = "cuda:0"
else:device = "cpu"def get_text(text, hps):text_norm = text_to_sequence(text, hps.data.text_cleaners)if hps.data.add_blank:text_norm = commons.intersperse(text_norm, 0)text_norm = torch.LongTensor(text_norm)return text_normapp = Flask(__name__)
#CORS(app, resources={r'/*': {"origins": '*'}})@app.route("/")
def index():return render_template('index.html')@app.route('/test', methods=['GET','POST'])
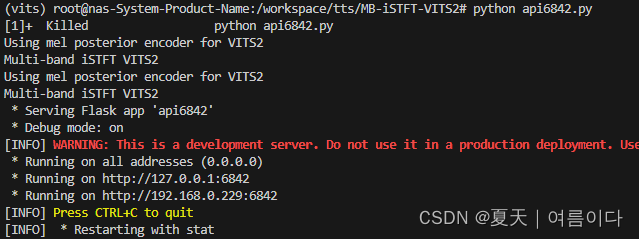
def test():#if request.method == 'POST':# 请求用户输入的合成文本 text = request.form["text"]print('text:', text)fltstr = re.sub(r"[\[\]\(\)\{\}]", "", text)stn_tst = get_text(fltstr, hps)speed = 1output_dir = 'output'sid = 0start_time=time.time()with torch.no_grad():x_tst = stn_tst.to(device).unsqueeze(0)x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(device)audio = net_g.infer(x_tst, x_tst_lengths, noise_scale=.667, noise_scale_w=0.8, length_scale=1 / speed)[0][0, 0].data.cpu().float().numpy()output = write(f'./{output_dir}/out.wav', hps.data.sampling_rate, audio)out_path = "./output/out.wav"return send_file(out_path,mimetype="audio/wav", as_attachment=True,download_name="out.wav")#return jsonify({'Input Text':text})if __name__ == '__main__':path_to_config = "./config.json" path_to_model = "./G_179000.pth"hps = utils.get_hparams_from_file(path_to_config)if "use_mel_posterior_encoder" in hps.model.keys() and hps.model.use_mel_posterior_encoder == True:print("Using mel posterior encoder for VITS2")posterior_channels = 80 # vits2hps.data.use_mel_posterior_encoder = Trueelse:print("Using lin posterior encoder for VITS1")posterior_channels = hps.data.filter_length // 2 + 1hps.data.use_mel_posterior_encoder = Falsenet_g = SynthesizerTrn(len(symbols),posterior_channels,hps.train.segment_size // hps.data.hop_length,n_speakers=hps.data.n_speakers, #- >0 for multi speaker**hps.model).to(device)_ = net_g.eval()_ = utils.load_checkpoint(path_to_model, net_g, None)app.run(port=6842, host="0.0.0.0", debug=True, threaded=False)在服务器运行app.py文件
python app.py这里是我自己随便起的python名称
打开Win上的postman
-
输入刚运行提示的网址和端口
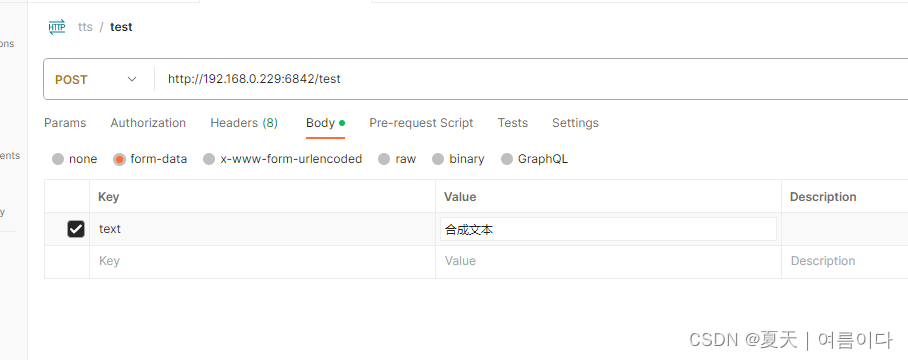
-
打开form-data,在Value出输入需要合成的文本

-
点击发送(Send)
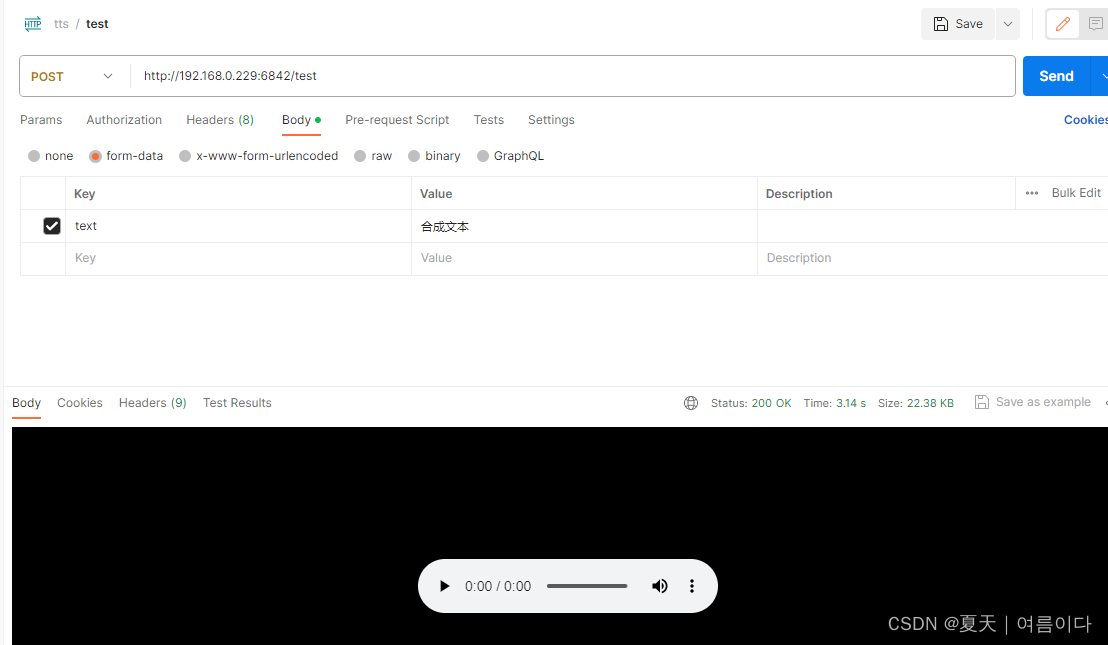
参考文献
【1】Templates — Flask Documentation (3.0.x) (palletsprojects.com)





![[ISCTF 2023]——Web、Misc较全详细Writeup、Re、Crypto部分Writeup](https://img-blog.csdnimg.cn/img_convert/24a49828657632c6ba5c7dbabeaceb60.png)