文章目录
- 1.InnoDB引擎中的逻辑存储结构
- 2.事务的基本概念
- 3.Redo log的核心概念
- 3.1.什么是Redo log
- 3.2.如果没有redo log面临的问题
- 3.3.使用redo log之后是怎样的流程
- 4.Undo log的核心概念
1.InnoDB引擎中的逻辑存储结构
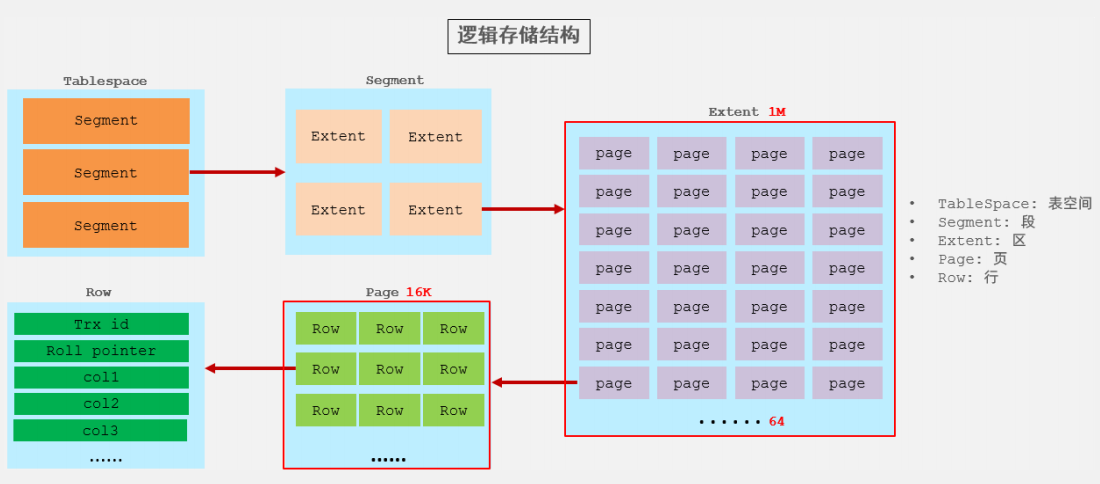
InnoDB存储引擎的逻辑结构分为以下几层:
-
TableSpace:表空间
- 表空间是InnoDB存储引擎逻辑结构中的最高层,如果开启了innodb_file_per_table参数,那么每张表都会有一个表空间文件(xxx.ibd),在一个MySQL实例中可以对应多个表空间,表空间用于存储行数据以及索引数据。
- 在表空间中可以包含多个Segment段。
-
Segment:段
- 表空间就是由很多个段组成的,分为数据段、索引段、回滚段。
- InnoDB是索引来组织表的,数据段就是B+树的叶子节点,叶子节点中包含的是表中的每一条数据,索引段是B+树结构中的非叶子节点,非叶子节点中记录的都是索引元素。
-
Extent:区
- 区是表空间中的单元结构,每个区的固定大小为1M,一个区中会有很多个页,默认情况中,InnoDB存储引擎页的大小为16KB,因此一个区中一共有64个连接的页。
-
Page:页
- 页是InnoDB存储引擎在磁盘管理中最小的单元,每个页的大小为16KB,为了保证页的连续性,InnoDB存储引擎每次会从磁盘中申请4-5个区,每个页下又拥有很多个行。
- 页的上层是区,一个区中可以包含64个页,每次页需要的4-5个区,都是从区中申请的。
-
Row:行
- InnoDB存储引擎是面向行的,也就是说数据时安装行进行存放的,在每一行中除了定义表的所有字段外,还包含Trxid和roll pointer两个隐藏的字段。
- Trx_id:每次对某条记录进行改动时,将对应的事务id赋值给trx_id作为隐藏列。
- Roll_pointer:每次对某条记录进行改动时,都会将旧版本的数据写入到undo日志中,这个隐藏列相当于一个指针,可以通过这个指针来找到记录被修改前的数据。
2.事务的基本概念
事务指的是一组操作的集合,事务会把集合中所有的操作看成是一个整体,一起向数据库提交这些操作,或者撤销这些操作,这些操作可以是增加数据、修改数据、插入数据、查询数据,但是这一个集合中的所有操作必须要么全部成功,要么全部失败。
事务的重点概念就是:要么全部执行成功、要么全部执行失败。
事务这种操作经常应用于银行、金融等业务场景,只要涉及金额、交易等这类场景,就需要用到事务操作。
事务的四大特性分别是原子性、一致性、隔离性、持久性。
- 原子性(Atomicity):事务是不可分割的最小操作单元,事务里的多个操作单元,要么全部执行成功,要么全部执行失败。
- 一致性(Consistency):事务完成时,所有的数据都保持一致的状态,以转账场景为例,一旦提交事务后,转账双方的金额变化必须符合业务逻辑,小明余额减1000元,小红余额就必须加1000元,数据要保持一致状态。
- 隔离性(Isolation):数据库系统提供事务的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行,在很多场景下,会有多个事务同时对一个数据表进行操作,此时有了隔离机制,事务A运行的时候并不会影响事务B的运行。
- 持久性(Durability):事务一旦提交或者回滚后,对于数据库的数据改变将是永久性的,数据都会被写入到磁盘中。
我们研究事务的原理时,主要研究InnoDB引擎如何保证事务的四大特性的。
对于事务的四大特性,实际上是分为两个部分的,其中原子性、一致性、持久性是由InnoDB中的redo log日志和undo log日志来保证的。而隔离性是通过数据库中的锁加上MVCC来保证。
下面我们重点来讲解redo log和undo log。隔离性中的MVCC放在下一篇详细讲解。
redo log主要是将事务提交之后的数据写入到redo log日志文件中,用于数据的持久化或者数据恢复。
undo log主要是将事务提交之前的数据写入到undo log日志文件中,当事务回滚时会从这里读取数据。
事务的原子性由undo log日志保障,持久性由redo log日志保障,一致性由undo log和redo log保障,隔离性由锁+MVCC保障。
3.Redo log的核心概念
3.1.什么是Redo log
redo log称为重做日志,在redo log中记录的是事务提交时数据页的物理修改,所有事务提交时的数据都会记录在redo log中,用来实现事务的持久性。
redo log日志由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中存放,后者在磁盘中存放,当事务提交之后,会把事务提交后所有的修改信息都保存到redo log中,当刷新脏页到磁盘发送错误时,可以通过redo log进行数据的恢复。
3.2.如果没有redo log面临的问题
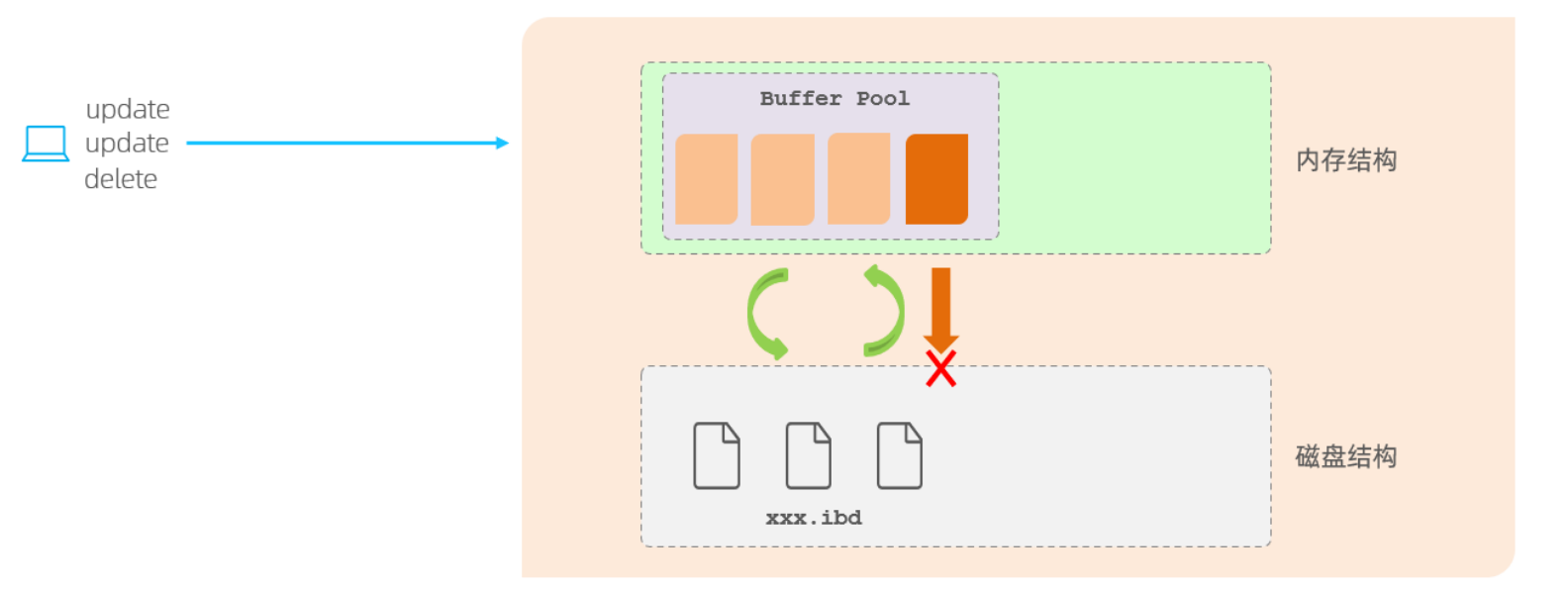
在InnoDB存储引擎中分为内存结构和磁盘结构,在内存结构中的主要区域就是Buffer Pool缓冲池了,在缓冲池中会有很多个数据页,数据最终是要写在磁盘进行持久化的。
当我们通过一个事务执行多个增删改的操作时,InnoDB存储引擎首先会操作缓冲池中的数据,如果缓冲池中没有我们要操作的数据,那么会通过后台线程从磁盘中将要操作的数据加载到缓冲池中进行缓存,然后由事务操作缓冲池中的数据,数据被修改后,所在的数据页我们就会称为脏页,脏页会在一定的时机,通过后台线程将数据刷新到磁盘中,从而保证缓冲区和磁盘的数据是一致的,保证数据的持久性。
但是缓冲区的脏页数据并不是实时刷新的,而是通过一段时间之后将缓冲区的数据刷新到磁盘中,如果在刷新磁盘的过程中出错了,但是提示用户事务提交成功了,最终数据并没有持久化,这就出现问题了,事务的持久性没有得到保障。
3.3.使用redo log之后是怎样的流程
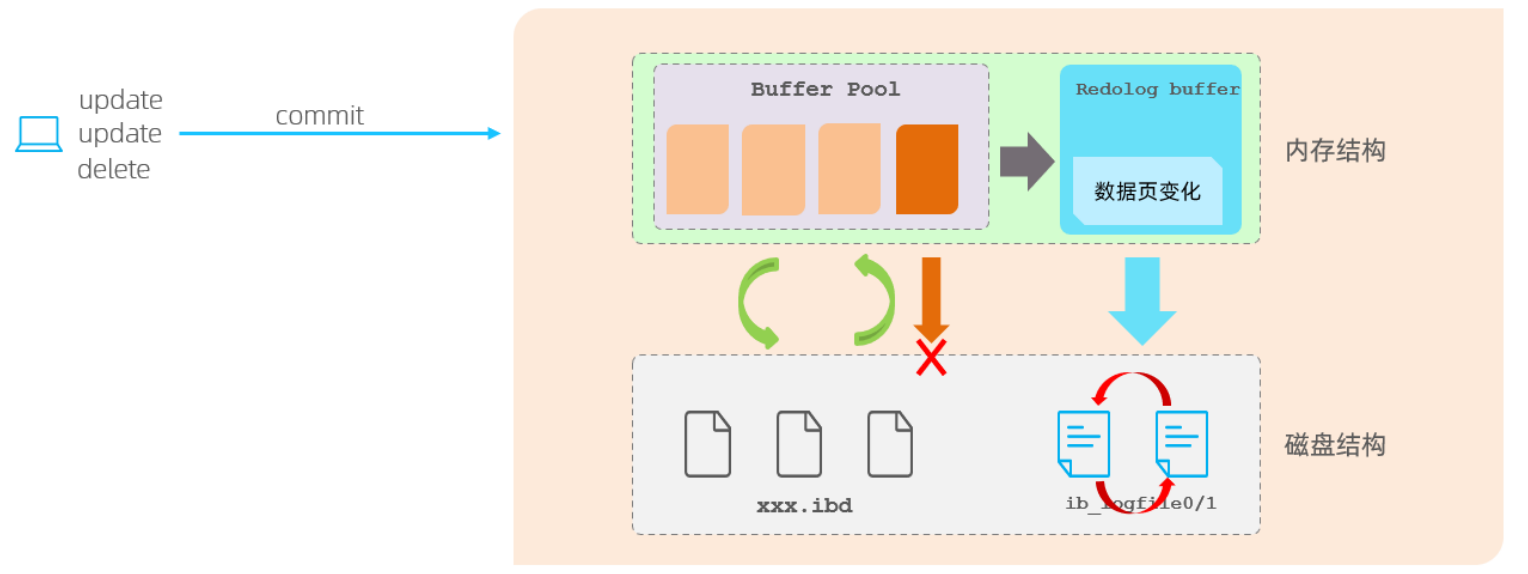
为了避免事务的持久性出现的问题,在INnoDB存储引擎中提供了一份日志redo log。
有了redo log之后,当对缓冲池中的数据进行增删改之后,会将数据页的变化记录在redo log buffer缓冲区中,当事务提交之后,会将redo log buffer中的数据刷新到redo log的磁盘文件中。
当一段时间之后要刷新缓冲区的脏页数据到磁盘时,发生了错误,此时就可以借助redo log进行的数据恢复,这样就保证了事务的持久性。
当脏页数据成功刷新到磁盘,此时redolog就没有作用了,可以被回收,所以redo log是有大小限制的,当超过限制后会循环写入,覆盖掉最早的数据。
我们可以再思考一个问题,为什么每次提交时候之后,要刷新redo log buffer中的数据导磁盘,并不是直接将buffer pool中的脏页数据刷新到磁盘呢?其实也非常简单,因为操作数据一般都是随机读写磁盘的,并不是顺序读写磁盘,随机读写磁盘对I/O的消耗很高,而redo log在磁盘中是日志文件,所以是顺序写入的,顺序写入的效率要远高于随机写。
这种先写日志也有名词:WAL(Write-Ahead Logging)
4.Undo log的核心概念
undo log日志是回滚日志,主要记录事务提交之前的数据信息,当事务需要回滚时会从undo log日志文件中读取旧的数据内容。另外在MVCC多版本并发控制中也会用到undo log。
undo log和redo log记录物理日志不同,undo log记录的是逻辑日志,因为是用于回滚数据时使用,所以undo log会将一条delete语句在undo log中记录一条对应的insert语句,当是update语句时,则在undo log中记录一条相反的update语句,当要执行回滚操作时,就可以从undo log中读取相应的内容并进行回滚。
当事务提交后并不会立即删除undo log,这些日志还可能应用于MVCC。
undo log采用段的方式进行管理和记录,存放在rollback segment回滚段中,内部包含了1024个undo log segment。