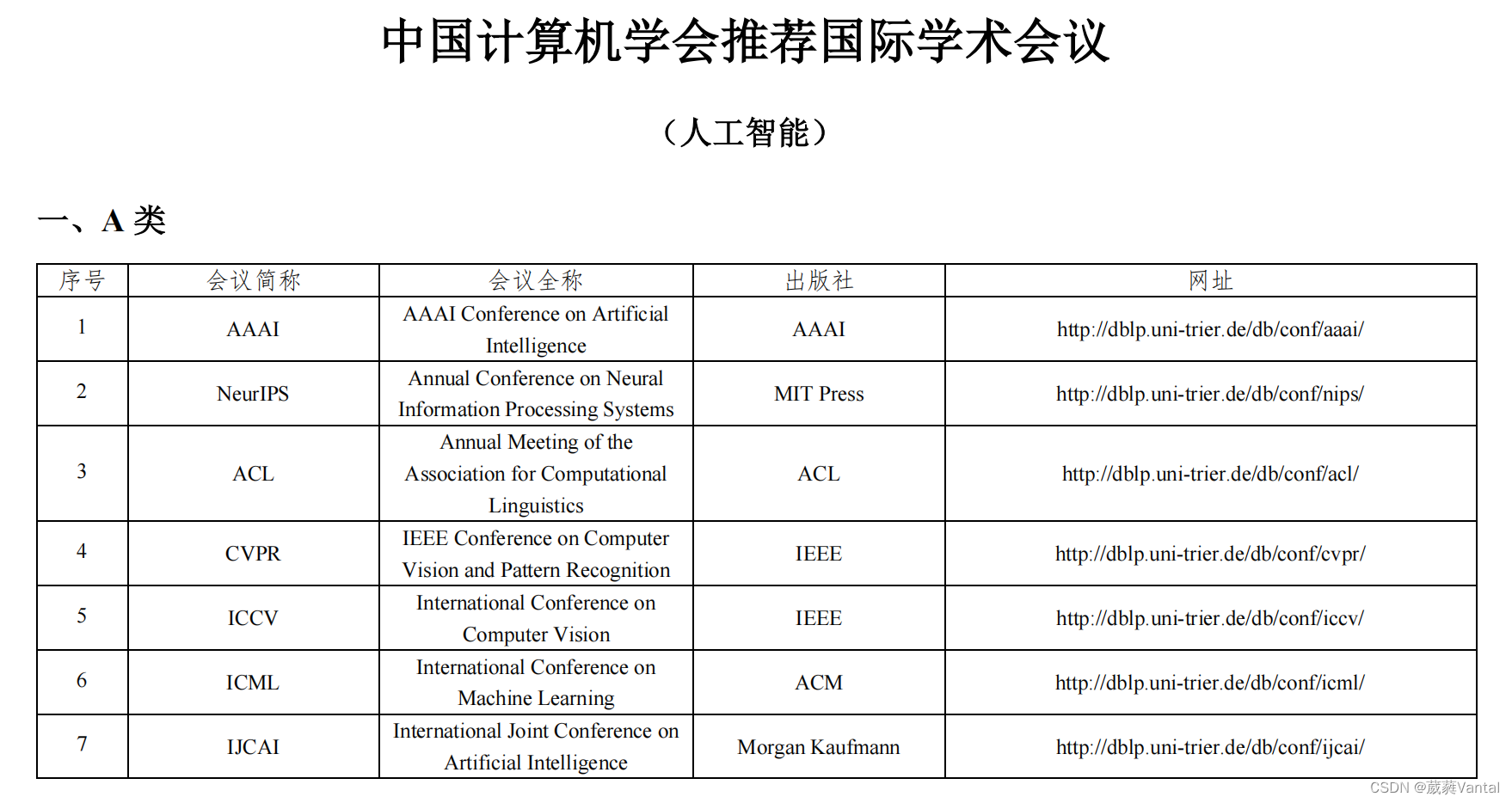
Adaptive background mixture models for real-time tracking
用于实时跟踪的自适应背景混合模型
1999年的MOG,作者是麻省理工学院前校长——埃里克格里姆森(W. Eric L. Grimson)。
目录
摘要
结论
1 介绍
1.1 以往的工作和现在的缺点
1.2 我们的方法
2 方法
2.1 在线混合模型
2.2 背景模型估计
2.3 连接部件
2.4 多假设跟踪
3 结果
4 适用性
5 未来工作
摘要
实时分割图像序列中运动区域的一种常见方法包括“背景减法”,即对没有运动对象的图像估计值与当前图像之间的误差进行阈值处理。解决这个问题的多种方法因所使用的背景模型类型和更新模型的程序而异。
MOG 算法计算步骤:
- 本文讨论了将每个像素建模为高斯混合,并使用在线近似来更新模型。
- 然后评估自适应混合模型的高斯分布,以确定哪些最有可能由背景过程产生。
- 根据最有效地表示每个像素的高斯分布是否被视为背景模型的一部分,对每个像素进行分类。
结论
本文提出了一种新的背景减法的概率方法,它包括将每个像素建模为一个单独的混合模型。我们实现了一种实时近似方法,该方法稳定可靠。该方法只需要两个参数,α 和 T。这两个参数对不同的相机和不同的场景都是鲁棒的。
这种方法通过缓慢调整高斯值来处理缓慢的照明变化。它还处理了由阴影、镜面反射、树枝摆动、计算机显示器和其他在计算机视觉中不常提及的现实世界的麻烦特征引起的多模态分布。当背景再次出现时,它会快速恢复,并具有自动像素阈值。所有这些因素都使该跟踪器成为我们活动和对象分类研究的重要组成部分。
MOG性能:该系统已成功用于跟踪室内环境中的人员、室外环境中的人和车、水箱中的鱼、地板上的蚂蚁以及实验室环境中的远程控制车辆。所有这些情况都涉及不同的摄像机、不同的照明和不同的被跟踪对象。该系统实现了我们在无需人工干预的情况下长时间实时性能的目标。
1 介绍
过去,计算障碍限制了实时视频处理应用的复杂性。因此,大多数系统要么太慢而不实用,要么通过将自身限制在非常可控的情况下而成功。最近,更快的计算机使研究人员能够考虑更复杂、更稳健的模型来实时分析流数据。这些新方法使研究人员能够开始对不同条件下的真实世界过程进行建模。
考虑视频监控的问题。一个稳健的系统不应该依赖于相机的小心放置。它还应该对其视野中的任何东西或发生的任何照明效果都很坚固。它应该能够处理通过杂乱区域的移动、视野中的物体重叠、阴影、照明变化、场景中移动元素的影响(如摇摆的树木)、缓慢移动的物体以及从场景中引入或移除的物体。基于背景方法的传统方法在这些一般情况下通常会失败。我们的目标是创建一个强大的自适应跟踪系统,该系统足够灵活,能够处理照明变化、移动场景杂波、多个移动对象和观察到的场景的其他任意变化。由此产生的跟踪器主要面向场景级视频监控应用。
1.1 以往的工作和现在的缺点
由于需要手动初始化,大多数研究人员已经放弃了非自适应的背景方法。在没有重新初始化的情况下,背景中的错误会随着时间的推移而积累,这使得这种方法仅在高度监督的短期跟踪应用中有用,而场景不会发生重大变化。
自适应背景的一种标准方法是随着时间的推移对图像进行平均,创建与当前静态场景相似的背景近似,但运动发生的地方除外。虽然这在物体连续移动且背景在很大一部分时间可见的情况下是有效的,但对于有许多移动物体的场景来说,尤其是在物体移动缓慢的情况下,这是不稳定的。它也不能处理双峰背景,当背景被覆盖时恢复缓慢,并且对整个场景具有单一的预定阈值。
场景照明的更改可能会导致任何背景方法出现问题。Ridder等人[5]使用卡尔曼滤波器对每个像素进行建模,这使他们的系统对场景中的照明变化更具鲁棒性。虽然这种方法确实具有逐像素的自动阈值,但它仍然恢复缓慢,并且不能很好地处理双峰背景。Koller等人[4]已成功地将该方法集成到自动传输监控应用程序中。
芬德[7]对被跟踪对象使用多类统计模型,但背景模型是每个像素的单个高斯模型。在房间为空的初始化期之后,系统报告良好的结果。目前还没有关于这种追踪器在户外场景中成功的报道。
Friedman和Russell[2]最近实现了一个用于检测车辆的逐像素EM框架,该框架与我们的工作最相似。他们的方法试图将像素值明确地分类为三个独立的预定分布,分别对应于道路颜色、阴影颜色和车辆颜色。他们试图调解阴影的影响似乎有些成功,但尚不清楚他们的系统对不包含这三种分布的像素会表现出什么行为。例如,像素可能呈现单一背景色或由重复运动、阴影或反射产生的多种背景色。
1.2 我们的方法
我们不是将所有像素的值明确地建模为一种特定类型的分布,而是将特定像素的值简单地建模为高斯混合。基于混合物中每个高斯的持久性和方差,我们确定哪些高斯可能对应于背景色。不符合背景分布的像素值被视为前景,直到有一个高斯包括它们,并有充分、一致的证据支持它。
我们的系统能够稳健地处理照明变化、场景元素的重复运动、在杂乱区域中跟踪、缓慢移动的物体以及从场景中引入或移除物体。缓慢移动的对象需要更长的时间才能融入背景,因为它们的颜色比背景的变化更大。此外,还学习了重复的变化,并且通常保持背景分布的模型,即使它被另一个分布临时替换,这在移除对象时导致更快的恢复。
我们的背景方法包含两个重要参数——学习常数 α 和 数据的比例部分 T ,应该由背景来解释。在不需要更改参数的情况下,我们的系统已用于室内人机交互应用程序,在过去的16个月里,我们一直在持续监控室外场景。
2 方法
如果每个像素都是在特定照明下由特定表面产生的,那么在考虑采集噪声的同时,单个高斯将足以对像素值进行建模。如果光照随着时间的推移而改变,那么每个像素的单个自适应高斯将是有效的。问题:在实践中,多个曲面经常出现在特定像素的视锥体中,并且照明条件会发生变化。因此,多重自适应高斯是必要的。我们使用自适应高斯混合来近似这个过程。

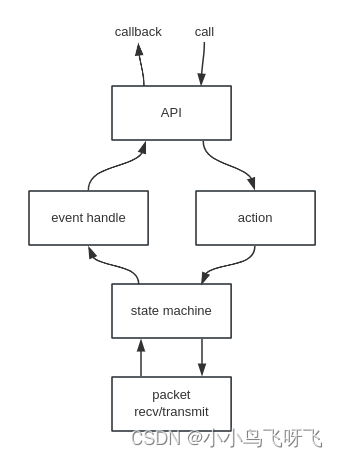
图1:程序的执行过程。
- (a)当前图像;
- (b)由背景模型中最可能的高斯均值组成的图像;
- (c)前景像素;
- (d)叠加了跟踪信息的当前图像。
- 注意:虽然阴影在这种情况下是前景,但如果表面在相当长的一段时间内被阴影覆盖,那么代表这些像素值的高斯可能足以被视为背景。(MOG2解决阴影检测问题)
每次Gaussians的参数更新时,都会使用一种简单的启发式方法来评估Gaussianss,以假设哪些最有可能是“背景过程”的一部分。与像素的某个“背景”高斯不匹配的像素值将使用连接的组件进行分组。最后,使用多假设跟踪器逐帧跟踪连接的组件。该过程如图1所示。
2.1 在线混合模型
我们把一个特定像素的值视为一个“像素过程”,它是一个像素值的时间序列,例如灰度值的标量或彩色图像的矢量。在任何时候,t,关于特定像素 已知的是它的历史
![]()
其中 I 是图像序列。图2(a)-(c)中的(R,G)散点图显示了一些“像素过程”,说明了对具有自动阈值的自适应系统的需求。图2(b)和(c)也强调了对多模态表示的需求。
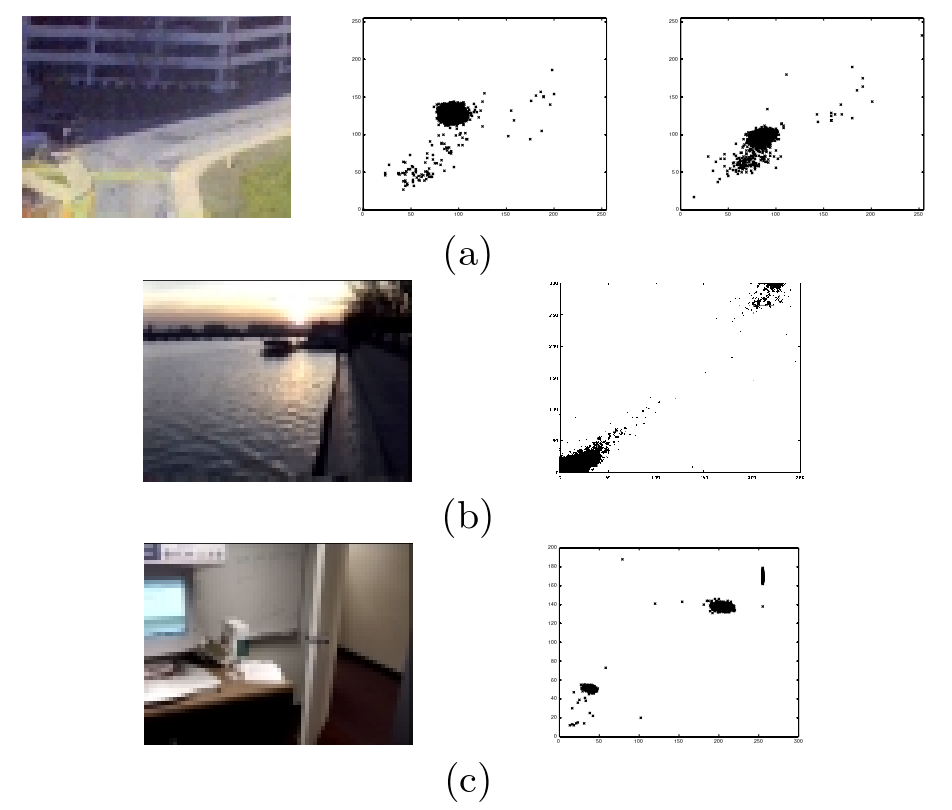
图2:该图包含图像中单个像素随时间变化的红色和绿色值的图像和散点图。它说明了现实环境中的一些困难。
- (a) 显示了相隔2分钟拍摄的同一像素的两个散点图。这需要两个阈值。
- (b) 显示了由水面上的镜面反射性产生的像素值的双模型分布。
- (c) 显示了另一种由显示器产生的双模态。
每个像素的值表示与像素光线相交的第一个物体的传感器方向上的辐射度测量值。对于静态背景和静态照明,该值将相对恒定。如果我们假设在采样过程中产生独立的高斯噪声,则其密度可以用以平均像素值为中心的单个高斯分布来描述。不幸的是,最有趣的视频序列涉及灯光变化、场景变化和移动对象。
如果在静态场景中发生照明更改,则高斯有必要跟踪这些更改。如果一个静态对象被添加到场景中,并且直到它在那里的时间比前一个对象长时才被合并到背景中,那么相应的像素可以被认为是任意长时间的前景。这将导致前景估计中的累积误差,从而导致较差的跟踪行为。这些因素表明,在确定高斯参数估计时,最近的观测可能更重要。
如果场景中存在移动对象,则会出现变化的另一个方面。即使是颜色相对一致的运动物体,通常也会比“静态”物体产生更多的变化。此外,通常情况下,应该有更多的数据支持背景分布,因为它们是重复的,而不同对象的像素值通常不相同。
这些是我们选择模型和更新程序的指导因素。每个像素 的最近历史由K个高斯分布的混合物建模。观察当前像素值的概率为:
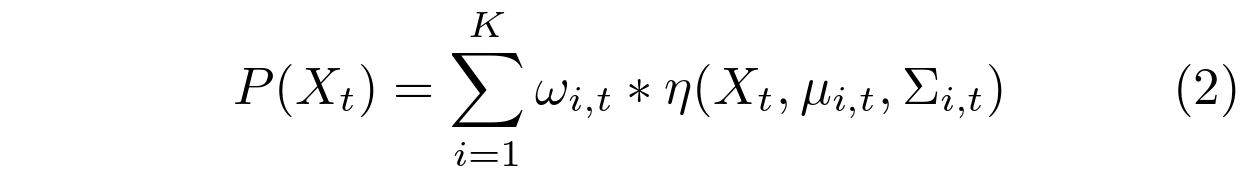
其中,K 是分布的数量, 是混合物中第 i 个高斯在时间t的权重估计值(数据的哪个部分由该高斯计数),
为混合物中第 i 个高斯在时刻 t 的平均值,
表示混合物中第 i 个高斯在时间 t 的协方差矩阵,其中
为高斯概率密度函数:
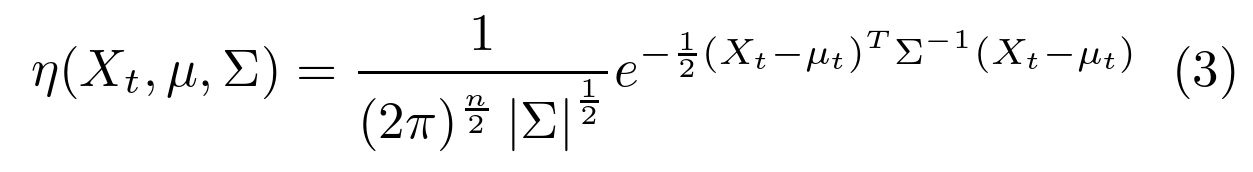
K 由可用内存和计算能力决定。目前,使用3到5个。此外,由于计算原因,假设协方差矩阵的形式为:
![]()
这假设红色、绿色和蓝色像素值是独立的,并且具有相同的方差。虽然事实并非如此,但该假设使我们能够避免以牺牲某些精度为代价,进行代价高昂的矩阵反演。
因此,场景中每个像素的最近观测值的分布由高斯混合来表征。通常,新的像素值将由混合模型的主要组件之一表示,并用于更新模型。
如果像素过程可以被认为是一个平稳过程,那么最大化观测数据可能性的标准方法是期望最大化[1]。不幸的是,随着世界状态的变化,每个像素过程都会随着时间的推移而变化,因此我们使用了一种近似方法,该方法基本上将每个新观察结果视为大小为 1 的样本集,并使用标准学习规则来整合新数据。
因为图像中的每个像素都有一个混合模型,所以在最近数据的窗口上实现精确的EM算法将是昂贵的。相反,我们实现了在线K-means近似。将每个新的像素值 与现有的 K 高斯分布进行检查,直到找到匹配。匹配被定义为分布的 2.5 标准偏差内的像素值。该阈值可能会受到干扰,对性能几乎没有影响。这实际上是一个每个像素 / 每个分布的阈值。当不同的区域具有不同的照明时,这是非常有用的(见图2(a)),因为出现在阴影区域的物体通常不会像照亮区域的物体那样表现出太多的噪声。统一的阈值通常会导致对象在进入着色区域时消失。
如果K个分布中没有一个与当前像素值匹配,则最不可能的分布被替换为以当前值作为其平均值、初始高方差和低先验权重的分布。
K 分布在时间 t 的先验权重 调整如下
![]()
的另一种表达形式:
![]()
其中,α 是学习率, 对于匹配的模型为 1,对于其余模型为 0。近似后,权重被重新归一化。1/α 定义了时间常数,该常数决定了分布参数变化的速度。
有效地是给定时间 1 到 t 的观测值,像素值与模型 k 匹配的(阈值)后验概率的因果低通滤波平均值。这相当于对该值的期望,该值具有过去值的指数窗口。
不匹配分布的 µ 和 σ 参数保持不变。与新观测结果相匹配的分布参数更新如下:

它实际上是与上述相同类型的因果低通滤波器,只是估计中只包括与模型匹配的数据。
这种方法的一个显著优点是,当某些东西被允许成为背景的一部分时,它不会破坏现有的背景模型。原始背景色重新出现在混合物中,直到它成为第 K 个最可能的颜色,并观察到新的颜色。因此,如果一个物体静止的时间刚好足以成为背景的一部分,然后它移动,那么描述先前背景的分布仍然存在,具有相同的 和
,但 ω 较低,并且将很快重新融入背景。
2.2 背景模型估计
随着每个像素的混合模型参数的变化,我们想确定混合中哪一个高斯最有可能是由背景过程产生的。启发式地,我们对具有最多支持证据和最小方差的高斯分布感兴趣。
要理解这种选择,请考虑支持证据的积累,以及当静态、持久对象可见时“背景”分布的相对较低方差。相反,当新对象遮挡背景对象时,它通常不会与现有分布之一匹配,这将导致创建新分布或增加现有分布的方差。此外,期望移动对象的方差保持大于背景像素,直到移动对象停止为止。为了对此进行建模,我们需要一种方法来决定混合模型的哪一部分最能代表背景过程。
首先,高斯根据ω/σ的值排序。该值随着分布获得更多证据和方差的减小而增加。在重新估计混合物的参数后,从匹配分布到最可能的背景分布进行排序是有效的,因为只有匹配模型的相对值才会发生变化。模型的这种排序实际上是一个有序的、开放的列表,其中最有可能的背景分布保持在顶部,不太可能的瞬态背景分布被吸引到底部,并最终被新的分布所取代。
然后选择第一个B分布作为背景模型,其中
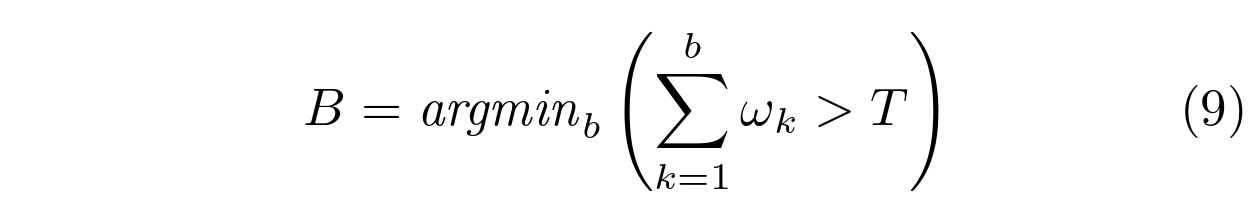
其中T是应当由背景考虑的数据的最小部分的度量。这采用“最佳”分布,直到最近数据的某一部分T被考虑在内。如果选择T的小值,则背景模型通常是单峰的。如果是这种情况,只使用最可能的分布将节省处理。
如果T更高,由重复的背景运动(例如树上的树叶、风中的飘动、建筑的飘动等)引起的多模态分布可能会导致背景模型中包含多个颜色。这会产生一种透明效果,使背景可以接受两种或多种不同的颜色。
2.3 连接部件
上述方法允许我们识别每个新帧中的前景像素,同时更新每个像素的过程的描述。然后,这些标记的前景像素可以通过两遍连接组件算法[3]分割成多个区域。
[3] B.K.P.Horn.Robot Vision,pp.66-69,299-333.The MITPress,1986.
因为这个过程可以有效地确定整个移动对象,所以移动区域不仅可以通过其位置来表征,还可以通过大小、力矩和其他形状信息来表征。这些特征不仅对以后的处理和分类有用,而且有助于跟踪过程。
2.4 多假设跟踪
虽然本节在背景减法的基础上并不重要,但它将使人们更好地理解和评估以下各节的结果。
使用结合了位置和大小的线性预测多假设跟踪算法来建立帧之间连接分量的对应关系。我们已经实现了一种用于播种和维护卡尔曼滤波器集的在线方法。
在每一帧,我们都有一个可用的卡尔曼模型库和一个新的可用的连接组件库,它们可以解释。首先,模型在概率上与它们可以解释的连通区域相匹配。其次,对无法充分解释的连通区域进行检查,以确定新的卡尔曼模型。最后,去除其拟合度(由预测误差方差的倒数确定)低于阈值的模型。
将模型与连接的组件匹配包括对照大于一两个像素的连接组件的可用池来检查每个现有模型。所有匹配项都用于更新相应的模型。如果更新后的模型有效,将在以下框架中使用。如果没有发现匹配,则可以假设“零”匹配,这会按预期比例缩放模型,并以恒定因子降低其适用性。
然后使用当前帧和前两帧中不匹配的模型来假设新的模型。使用前两帧中不匹配的连接组件对,对模型进行了假设。如果当前框架包含一个匹配项,则更新后的模型将添加到现有模型中。为了避免在有噪声的情况下可能发生的组合爆炸,当存在过多的模型时,可能希望通过移除最不可能的模型来限制现有模型的最大数量。在嘈杂的情况下(例如,低光照条件下的ccd相机),去除随机对应可能产生的短轨迹通常是有用的。有关此方法的更多详细信息,请访问Index of /projects/vsam (mit.edu).
3 结果
在具有R10000处理器的SGI O2上,该方法每秒可以处理11到13帧(帧大小160x120像素)。帧速率的变化是由于前景存在量的变化。我们的跟踪系统已经有效地存储了五个场景的跟踪信息超过16个月[6]。图3显示了一天中一个场景中的累积轨迹。

图3:该图显示了从早上6点到9点以及从下午3点到7点的连续跟踪时间。
- (a)显示了存储模板时的图像;
- (b)显示了对象在该时间内的累积轨迹。颜色编码方向,强度编码大小。
- 特定区域内颜色的一致性会影响已获取的速度、方向和尺寸参数的一致性。
虽然云量的快速变化(相对于α,学习率)有时可能需要一组新的背景分布,但它将在10-20秒内稳定下来,跟踪将不受阻碍地继续。

图4:该图显示了场景中的哪些对象被分类为人或汽车,使用对观察对象的纵横比的简单启发法。其准确性会影响正在跟踪的连接区域的一致性。
由于呈现的稳定性和完整性,可以进行一些简单的分类。图4显示了在10分钟内出现在场景中的对象的分类,使用对象的时间平均纵横比的简单二进制阈值。持续时间不到一秒的轨迹被删除。
进入现场的每一个物体——总共33辆车和34个人——都被追踪到了。它成功地对每辆车进行了分类,但有一种情况除外,它将两辆车分类为同一对象,因为一辆车同时进入场景,另一辆车在同一点离开。研究发现,在两人行走时有身体接触的情况下,只有两人中有一人。它还加倍计算了2个对象,因为它们的轨迹没有正确匹配。
4 适用性
在决定要实现的跟踪器时,对研究人员来说,最重要的信息是跟踪器的适用位置。本节将努力传递我们通过使用该跟踪器的经验获得的一些知识。跟踪系统在包含视觉重叠的大量对象的场景中具有最大的困难。多重假设跟踪器在可靠地消除交叉对象的歧义方面并不是非常复杂。这个问题可能会受到长阴影的影响,但对于我们的应用程序来说,跟踪对象及其阴影并避免裁剪或丢失暗对象比尝试移除阴影更可取。根据我们的经验,在阴影最明显的明亮日子里,深色物体的阴影区域和阴影面都是黑色的(不是深绿色,也不是深红色等)。
好消息是,该跟踪器对所有光线变化都相对稳健,但对相对快速的光线变化(例如,弱光灯打开和部分多云、刮风的日子)除外。它成功地跟踪了下雨、下雪、雨夹雪、冰雹、阴天和晴天的室外场景。它还被用于追踪喂食器中的鸟类、夜间使用Sony NightShot追踪老鼠、水箱中的鱼、进入实验室的人以及户外场景中的物体。在这些环境中,它减少了树枝摆动、水波起伏、镜面反射、缓慢移动的物体以及相机和采集噪声等重复运动的影响。该系统已被证明具有强大的白天/晚上周期和长期场景变化。有关最新结果和项目更新,请访问 Index of /projects/vsam (mit.edu).
5 未来工作
随着计算机的改进和并行架构的研究,该算法可以在更大的图像上更快地运行,并在混合模型中使用更多的高斯。所有这些因素都将提高性能。完整的协方差矩阵将进一步提高性能。将预测添加到每个高斯(例如卡尔曼滤波器方法)中,也可能导致对照明变化的更稳健的跟踪。
除了这些明显的改进之外,我们还在研究对像素过程的一些相互依赖性进行建模。在这方面,相邻像素的相对值以及与相邻像素的分布的相关性可能是有用的。这将允许系统通过对其一些邻居的观察来对被遮挡像素的变化进行建模。
我们的方法已用于灰度、RGB、HSV和局部线性滤波器响应。但这种方法应该能够对我们的假设和启发式方法通常有效的任何流输入源进行建模。我们正在研究这种方法在帧速率立体声、红外相机中的使用,并将深度作为第四通道(R、G、B、D)。深度是多模态分布有用的一个例子,因为尽管视差估计由于虚假对应而具有噪声,但当这些噪声值由背景中的虚假对应产生时,它们通常是相对可预测的。
在过去,我们经常被迫处理相对少量的数据,但有了这个系统,我们可以在实时流媒体视频上一次收集移动物体的图像并稳健地跟踪数据数周。这种能力使我们能够调查过去无法获得的未来方向。我们正在使用数百万个例子进行活动分类和对象分类[6]。
[6] W.E.L.Grimson,Chris Stauffer,Raquel Romano,and LilyLee.“Using adaptive tracking to classify and monitor activities in a site,”In Computer Vision and Pattern Recognition1998 (CVPR98),Santa Barbara,CA.June 1998.
>>>> 如有疑问,欢迎评论区一起探讨。