前言
这里只对RBO优化进行简单的讲解。讲解RBO之前必须对spark sql的执行计划做一个简单的介绍。
这个里讲解的不是很清楚,需要结合具体的执行计划来进行查看
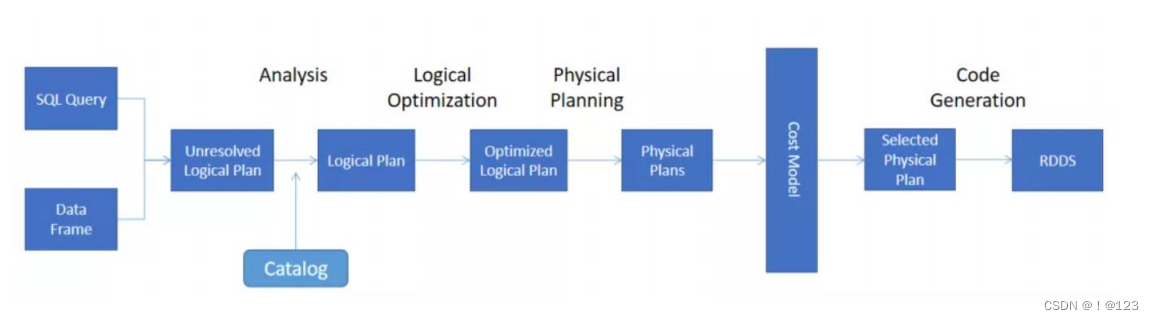
1、执行计划
在spark sql的执行计划中,执行计划分为两大类,即逻辑执行计划、物理执行计划。物理执行计划才是sql最终执行的执行计划
逻辑执行计划
- Unresolved逻辑执行计划:Parsed Logical Plan
件检查 SQL 语法上是否有问题,然后生成 Unresolved(未解析)的逻辑计划,不检查表名、不检查列名 - Resolved逻辑执行计划:Analyzed Logical Plan
通过访问 Spark 中的 Catalog 存储库来解析验证语义、列名、类型、表名等。 - 优化后的逻辑执行计划:Optimized Logical Plan
Catalyst 优化器根据各种规则进行优化 - Catalyst 优化器根据各种规则进行优化。
物理执行计划
- 物理执行计划: Physical Plan
确定连接的类型、分区的数量、过滤器、where、groupBy子句的执行顺序等
执行计划处理流程
核心步骤

2、RBO详解
RBO是基于规则的优化,是在Analyzed Logical Plan基础上的优化,基于规则有三种
- 常量替换
对于纯常量的运算的表达式,例如1+2,会将其替换为等值的3。如果列很多的话,需要对每一列都进行计算(如果表达式更加复杂会耗费更多的时间),能够消除不必要的计算。 - 谓词下推
使用where条件或者left on对数据进行过滤的操作提前执行,可以减少输入的数据量,减少计算的压力。想对于ORC和Parquet类型的存储,可以根据文件脚注的统计信息 ,下推谓词能够大幅减少数据扫描量,降低磁盘IO
谓词下推规则:

- 列裁剪
只读取那些与查询相关的字段