目录
一、循环依赖概述
1.2 spring中的循环依赖
二、循环依赖问题模拟
2.1 循环依赖代码演示
2.2 问题分析与解决
2.2.1 使用反射+中间容器
三、spring循环依赖问题解析
3.1 spring中的依赖注入
3.1.1 field属性注入
3.1.2 setter方法注入
3.1.3 构造器注入
3.2 spring中不同的循环依赖解决方案
3.2.1 spring中bean的生命周期
3.2.2 循环依赖处理时机
四、spring 三级缓存解决方案
4.1 前置准备
4.2 三级缓存源码分析过程
4.2.1 代码调试技巧
4.3 为什么使用三级缓存?
4.4 spring循环依赖解决方案小结
五、写在文末
一、循环依赖概述
循环依赖,叫做循环引用,指一个或者多个bean对象之间互相引用,最后形成一种类似环形的依赖关系,循环依赖的大致情形如下几种:

从上图不难发现,循环依赖其实就是一个逻辑上的闭环,像中间的那张图,bean-A中注入bean-B,创建bean-A的时候就会去容器中查找bean-B,发现没有,就会去创建bean-B,而创建bean-B的时候,发现又注入了bean-A,于是又去容器检查bean-A......,接下来就会不断的循环重复上面的过程。有心的同学似乎发现,这个是不是有点像死锁了呢?其实循环依赖就是一个死循环的过程。
1.2 spring中的循环依赖
在使用spring进行编码时,可能你会见到下面这样的写法,这里有两个被spring容器管理的类UserService和RoleService,由于加了@Service注解,都可以注册到bean容器中;
其中UserService中注入了RoleService
@Service
public class UserService {@Autowiredprivate RoleService roleService;}RoleService中注入了UserService
@Service
public class UserService {@Autowiredprivate RoleService roleService;}这样的写法就形成了相互引用的循环依赖,这种互相注入引用的方式是我们平时开发中使用最多的,原因是这种方式使用起来非常简单,代码看起来也很简洁。
二、循环依赖问题模拟
2.1 循环依赖代码演示
在下面这段代码中,有两个类,在第一个类CircularTest1实例化对象时,需要创建CircularTest2的类对象,同时CircularTest2类实例化时,也需要CircularTest1类的创建,这样就形成了循环依赖。
public class CircularTestError {public static void main(String[] args) {new CircularTest1();}
}
class CircularTest1{private CircularTest2 circularTest2 = new CircularTest2();
}class CircularTest2{private CircularTest1 circularTest1 = new CircularTest1();
}运行这段代码,最终会看到栈溢出的错误
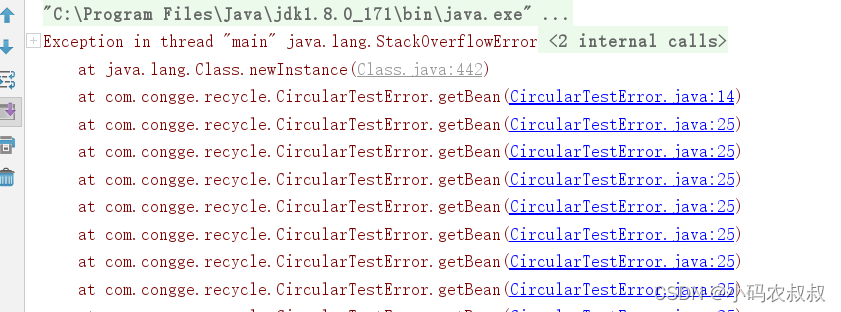
上面的案例就是最基本的循环依赖场景,你需要我,我需要你,然后就报错了。而且上面的这种设计情况我们是没有办法解决的。那么针对这种场景我们应该要怎么设计呢?这个是关键!
2.2 问题分析与解决
深入分析这个问题时,首先要明确的一点就是如果这个对象A还没创建成功,在创建的过程中要依赖另一个对象B,而另一个对象B也是在创建中要依赖对象A,这种肯定是无解的。
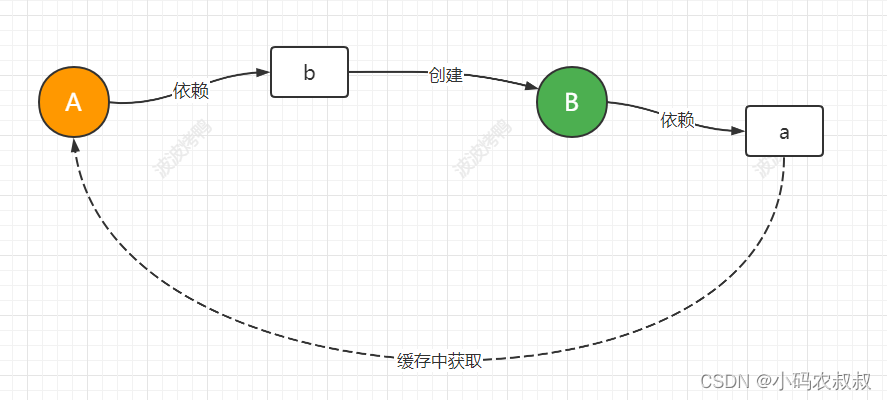
此时我们需要转换思路,先把A创建出来,但是还没有完成初始化操作,也就是这是一个半成品的对象,然后在赋值的时候先把A暴露出来,然后创建B,让B创建完成后找到暴露的A完成整体的实例化,这时再把B交给A完成A的后续操作,从而揭开了循环依赖的密码。整个过程如下图所示:

2.2.1 使用反射+中间容器
明白了上面两个对象之间循环依赖的原理,可以尝试引入一个中间容器,比如这里可以选择map来解决这个问题,完整的代码如下:
import java.lang.reflect.Field;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;public class CircularTestHalf {// 保存提前暴露的对象,也就是半成品的对象private final static Map<String,Object> singletonObjects = new ConcurrentHashMap<>();public static void main(String[] args) throws Exception{System.out.println(getBean(CircularTest1.class).getCircularTest2());System.out.println(getBean(CircularTest2.class).getCircularTest1());}private static <T> T getBean(Class<T> beanClass) throws Exception{//1.获取类对象对应的名称String beanName = beanClass.getSimpleName().toLowerCase();// 2.根据名称去 singletonObjects 中查看是否有半成品的对象if(singletonObjects.containsKey(beanName)){return (T) singletonObjects.get(beanName);}// 3. singletonObjects 没有半成品的对象,那么就反射实例化对象Object obj = beanClass.newInstance();// 还没有完整的创建完这个对象就把这个对象存储在了 singletonObjects中singletonObjects.put(beanName,obj);// 属性填充来补全对象Field[] declaredFields = obj.getClass().getDeclaredFields();// 遍历处理for (Field field : declaredFields) {field.setAccessible(true); // 针对private修饰// 获取成员变量 对应的类对象Class<?> fieldClass = field.getType();// 获取对应的 beanNameString fieldBeanName = fieldClass.getSimpleName().toLowerCase();// 给成员变量赋值 如果 singletonObjects 中有半成品就获取,否则创建对象field.set(obj,singletonObjects.containsKey(fieldBeanName)?singletonObjects.get(fieldBeanName):getBean(fieldClass));}return (T) obj;}
}在这段代码中,我们引入了一个中间容器map,map在这里的作用就是,通过反射创建A对象的实例,但是还没有初始化(填充字段等属性)之前,作为一个中间态的容器存放A、B两个未实例化的对象,通俗理解就是所谓的“半成品”对象容器,以对象A来说,在反射创建对象之后进行属性值填充的时候发现B对象没有,这时就要去做对象B的创建,此时对象B也重复A的过程,但不同的是,由于上一步对象A初始创建后放到了MAP中,此时A就可以拿到并填充到自己的属性里面了,这样就不会陷入无限的死循环里面了。
运行上面的程序,可以发现通过这种方式就解决了这个问题

总结这种方案的解决流程如下图所示
三、spring循环依赖问题解析
在谈到spring中循环依赖的时候,很多同学第一反应就是只要A中注入B,B中注入A,肯定就会出现循环依赖问题。其实这种理解是片面的。需要首先弄清楚spring中的几种依赖注入的方式。
3.1 spring中的依赖注入
依赖注入是Spring IOC(控制反转)模块的一个核心概念,DI (Dependency Injection):依赖注入是指在 Spring IOC 容器创建对象的过程中,将所依赖的对象通过配置进行注入,我们可以通过依赖注入的方式来降低对象间的耦合度。
这里的配置注入可以基于XML配置文件也可以基于注解配置,当下注解配置开发是主流,所以在这里主要讨论基于注解的注入方式,基于注解的常规注入方式通常有三种:
-
基于field属性注入
-
基于setter方法注入
-
基于构造器注入
下面分别来看下这几种常用的注入方式。
3.1.1 field属性注入
这种方式是平时开发中使用最多的,原因是这种方式使用起来非常简单,代码也比较简洁。
@Service
public class UserService {@Autowiredprivate UserDAO userDAO;}3.1.2 setter方法注入
这种方式使用的不是很多
@Service
public class UserService {private UserDAO userDAO;@Autowiredpublic void setUserDAO(serDAO userDAO) {this.userDAO = userDAO;}
}3.1.3 构造器注入
@Service
public class UserService {private UserDAO userDAO;@Autowired //构造器注入public UserService(UserDAO userDAO) {this.userDAO = userDAO;}
}补充说明:
事实上,项目中如果存在大量的Bean的循环依赖,其实是Bean对象职责划分不明确、代码质量不高的表现,SpringBoot在后续的版本(大概是是2.6.X的某个版本)中默认把循环依赖给禁用了!从2.6版本开始,如果你的项目里还存在循环依赖,SpringBoot将拒绝启动!
如果你的版本高于2.6,仍然需要保留允许循环依赖,需要手动在配置文件中开启
spring:main:allow-circular-references: true3.2 spring中不同的循环依赖解决方案
基于上面的探讨,在不同的依赖注入模式下, spring中也对应着不同的循环依赖解决方案,如下图

以设值注入,即属性注入的方式为例进行说明,看看spring中是如何解决循环依赖问题的 。
3.2.1 spring中bean的生命周期
在搞清楚spring是如何解决循环依赖的问题之前,有必要搞清楚spring中bean的完整生命周期,因为只有搞清生命周期中各个阶段要做的事情,才知道spring为何要这样解决,spring生命周期如下图所示
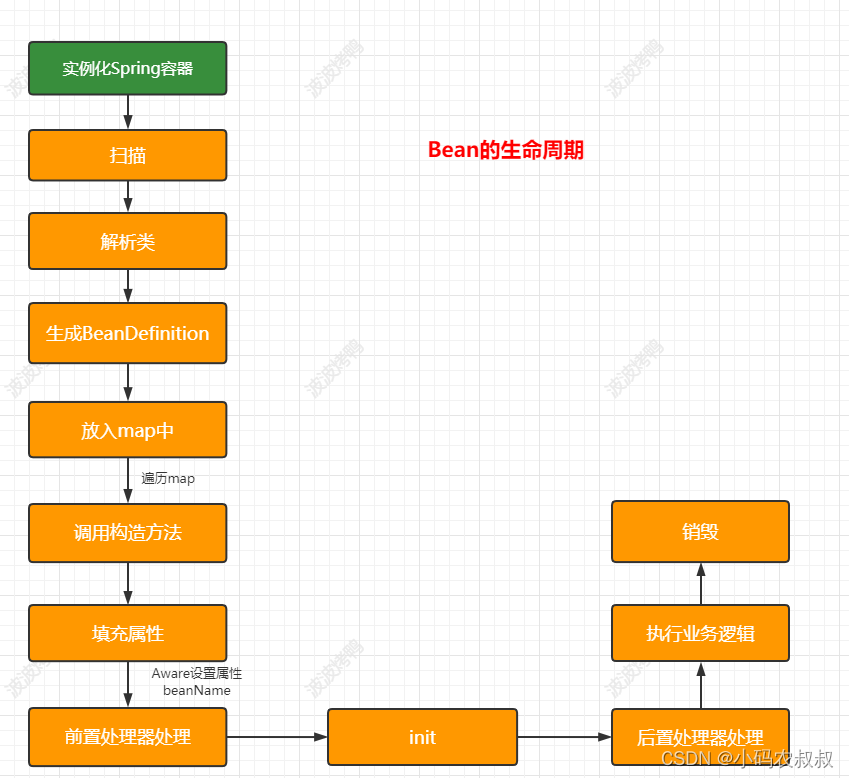
基于上面的案例,结合对spring的理解,对象的生命周期的核心就两个
1、创建对象;
2、对象属性填

3.2.2 循环依赖处理时机
基于前面案例的了解,我们知道肯定需要在调用构造方法方法创建完成后再暴露对象,在Spring中提供了三级缓存来处理这个事情,对应的处理节点如下图:

对应到源码中具体处理循环依赖的流程如下:
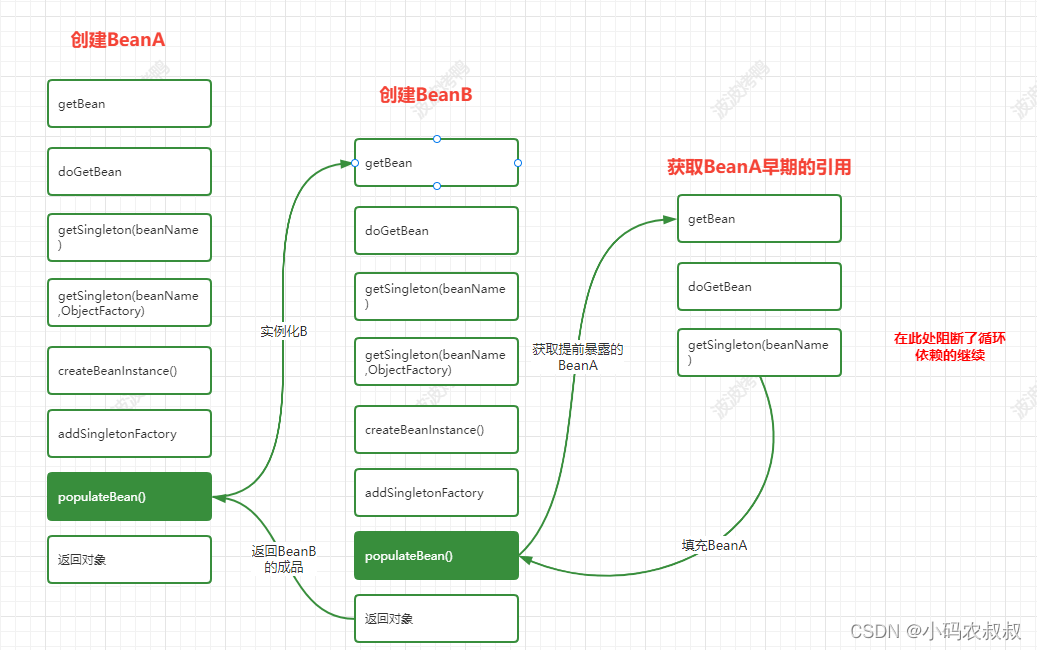
上面就是在Spring的生命周期方法中和循环依赖出现相关的流程了。那么源码中的具体处理是怎么样的呢?接下来从源码来详细看下。
四、spring 三级缓存解决方案
通过上面的分析我们基本了解了一个情况就是,如果出现了循环依赖,在spring的bean的生命周期方法中,由两个重要的节点,第一是提前暴露对象A,第二需提供一个中间存储的容器存放提前暴露的对象A,spring的设计中,即采用了一种叫做三级缓存的思想完美解决了这个问题。
4.1 前置准备
为了方便下文我们对源码的分析有一个更深入的理解,建议从源码debug进去分析,可以一步步追根溯源,搞清三级缓存的底层原理。
在spring工程中创建两个业务类,UserService和RoleService,两个类分别互相引用,代码如下:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class UserService {@Autowiredprivate RoleService roleService;}import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class RoleService {@Autowiredprivate UserService userService;}4.2 三级缓存源码分析过程
在spring源码中,找到DefaultSingletonBeanRegistry这个类,在该类中使用了3个map作为三级缓存,代码如下:
public class DefaultSingletonBeanRegistry ... {//1、最终存储单例Bean成品的容器,即实例化和初始化都完成的Bean,称之为"一级缓存"Map<String, Object> singletonObjects = new ConcurrentHashMap(256);//2、早期Bean单例池,缓存半成品对象,且当前对象已经被其他对象引用了,称之为"二级缓存"Map<String, Object> earlySingletonObjects = new ConcurrentHashMap(16);//3、单例Bean的工厂池,缓存半成品对象,对象未被引用,使用时在通过工厂创建Bean,称之为"三级缓存"Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
}我们知道,在项目启动时会进行Bean加载注入到Spring容器中,当创建某个Bean时发现引用依赖于另一个Bean,就会进行依赖查找,就会来到顶层接口BeanFactory的#getBean()方法,所以接下来看看AbstractBeanFactory的#doGetBean()的实现逻辑,发现首先会根据 beanName 从单例 bean 缓存中获取,如果不为空则直接返回
Object sharedInstance = getSingleton(beanName);这个#getSingleton()是在DefaultSingletonBeanRegistry实现的,详细代码如下:
@Nullableprotected Object getSingleton(String beanName, boolean allowEarlyReference) {// Quick check for existing instance without full singleton lock// 从单例缓存中加载beanObject singletonObject = this.singletonObjects.get(beanName);// 单例缓存中没有获取到bean,同时bean在创建中if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {// 从 earlySingletonObjects 获取singletonObject = this.earlySingletonObjects.get(beanName);// 还是没有加载到bean,并且允许提前创建if (singletonObject == null && allowEarlyReference) {// 对单例缓存map加锁synchronized (this.singletonObjects) {// Consistent creation of early reference within full singleton lock// 再次从单例缓存中加载beansingletonObject = this.singletonObjects.get(beanName);if (singletonObject == null) {// 再次从 earlySingletonObjects 获取singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) {// 从 singletonFactories 中获取对应的 ObjectFactoryObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {// 获得 beansingletonObject = singletonFactory.getObject();// 添加 bean 到 earlySingletonObjects 中this.earlySingletonObjects.put(beanName, singletonObject);// 从 singletonFactories 中移除对应的 ObjectFactorythis.singletonFactories.remove(beanName);}}}}}}return singletonObject;}这个方法就是从三级缓存中获取Bean对象,不难发现这里先从一级缓存singletonObjects中查找,如果没找到,接着从二级缓存earlySingletonObjects,还是没找到的话最终会去三级缓存singletonFactories中查找,需要注意的是如果在三级缓存中找到,就会从三级缓存升级到二级缓存了。所以,二级缓存存在的意义,就是缓存三级缓存中的 ObjectFactory 的 #getObject() 方法的执行结果,提早曝光的单例 Bean 对象。
getSingleton()返回空就会接着执行AbstractBeanFactory的#doGetBean()的下面逻辑
if (isPrototypeCurrentlyInCreation(beanName)) {throw new BeanCurrentlyInCreationException(beanName);
}可以看到,如果配置的是原型模式,bean循环依赖直接报错,对于单例模式下的bean,循环依赖Spring通过三级缓存提前曝光bean来解决,因为单例bean在整个容器中就一个,但原型模式每次都会创建一个新的bean,无法使用缓存解决,所以直接报错了。
经过一系列代码之后还是没有找到当前需要的bean,就会执行如下创建bean的逻辑:
// 上面的缓存中没找到,需要根据不同的模式创建
// bean实例化
// Create bean instance.
if (mbd.isSingleton()) { // 单例模式sharedInstance = getSingleton(beanName, () -> {try {return createBean(beanName, mbd, args);}catch (BeansException ex) {// Explicitly remove instance from singleton cache: It might have been put there// eagerly by the creation process, to allow for circular reference resolution.// Also remove any beans that received a temporary reference to the bean.// 显式从单例缓存中删除 Bean 实例// 因为单例模式下为了解决循环依赖,可能他已经存在了,所以销毁它destroySingleton(beanName);throw ex;}});bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}最终来到了AbstractAutowireCapableBeanFactory的#createBean(),真正执行逻辑实现的是#doCreateBean()方法:
// Eagerly cache singletons to be able to resolve circular references// even when triggered by lifecycle interfaces like BeanFactoryAware.// <4> 解决单例模式的循环依赖boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&isSingletonCurrentlyInCreation(beanName));if (earlySingletonExposure) {if (logger.isTraceEnabled()) {logger.trace("Eagerly caching bean '" + beanName +"' to allow for resolving potential circular references");}// 提前将创建的 bean 实例加入到 singletonFactories 中// 这里是为了后期避免循环依赖addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));}这里将创建的bean工厂对象加入到 singletonFactories 三级缓存中,用来生成半成品的bean并放入到二级缓存,提前曝光bean,意味着别的bean引用它的时候,依赖查找就可以在前面的#getSingleton()中拿到当前bean直接返回,从而解决循环依赖。如下代码
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {if (!this.singletonObjects.containsKey(beanName)) {this.singletonFactories.put(beanName, singletonFactory);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}}
}通过代码可以看到,singletonFactories 这个三级缓存是解决 Spring Bean 循环依赖的重要所在。这段代码发生在 #createBeanInstance(...) 方法之后,也就是说这个 bean 其实已经被创建出来了,但它还不完美(没有进行属性填充和初始化),但对其他依赖它的对象而言已经可以使用了(可以根据对象引用定位到堆中对象)。所以 Spring 在这个时候将该对象提前曝光出来,可以被其他对象所使用。
当然也需要注意到addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean))的() -> getEarlyBeanReference(beanName, mbd, bean)匿名函数调用,使用lambda方式生成一个ObjectFactory对象放到三级缓存中,提前曝光的是ObjectFactory对象,在被注入时才在ObjectFactory.getObject方式内实时生成代理对象,也就是调用#getEarlyBeanReference()进行实现的。
// 这里如果当前Bean需要aop代理增强,就是这里生成代理Bean对象的
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {Object exposedObject = bean;if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {for (BeanPostProcessor bp : getBeanPostProcessors()) {if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);}}}return exposedObject;
}这就是为什么 Spring 需要额外增加 singletonFactories 三级缓存的原因,目的是为了解决 Spring 循环依赖情况下Bean存在动态代理的情况,否则循环注入到别人的 Bean 就是原始的,而不是经过动态代理的
4.2.1 代码调试技巧
在上文中,我们使用了两个互相引用依赖的类,可以直接在上面的DefaultSingletonBeanRegistry类中,找到addSingleton这个方法,然后再在 synchronized 代码块中打上断点(注意设置断点的条件),重启项目时,即可进入到singletonObjects的put方法中。
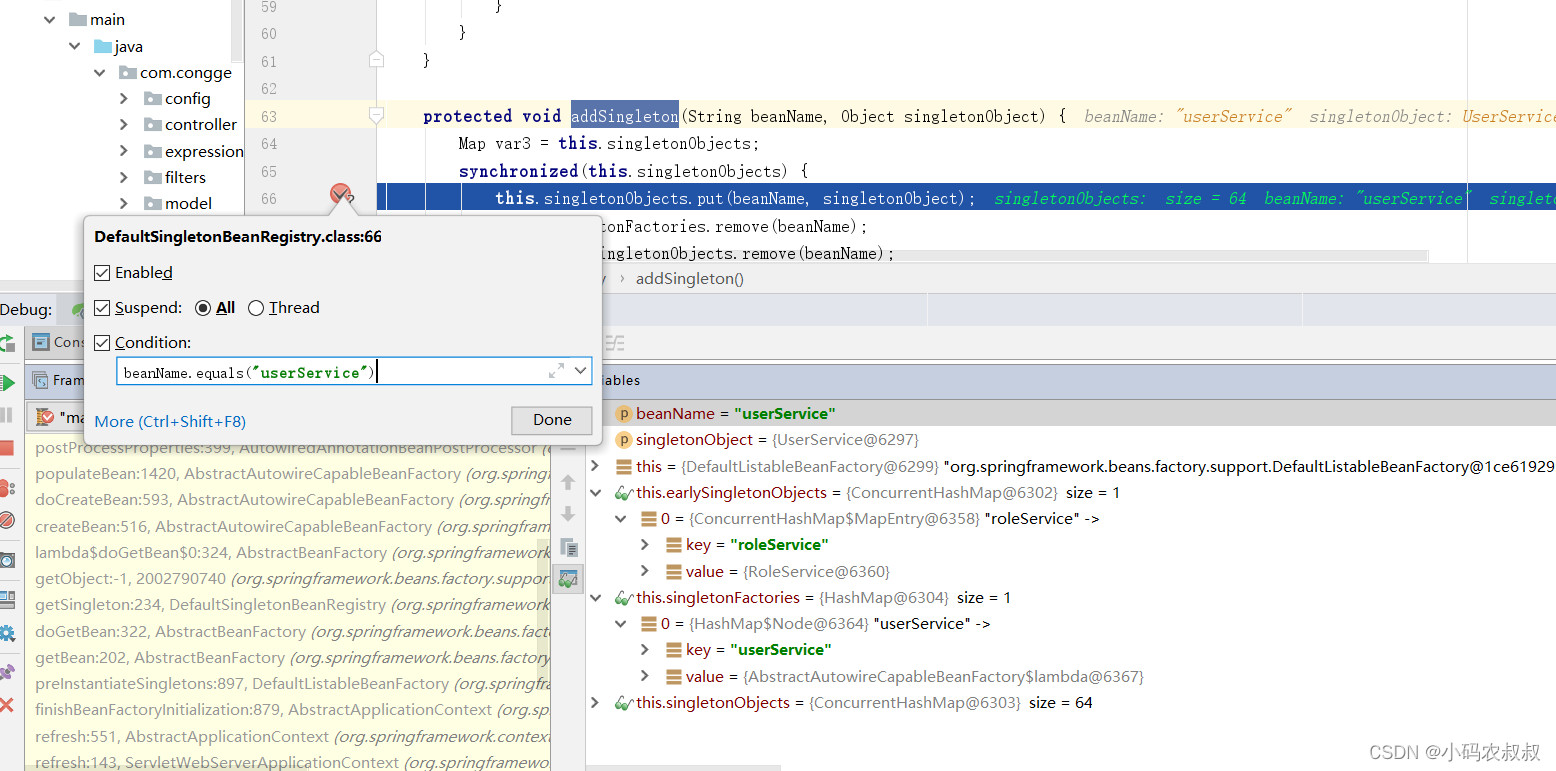
当断点进入到这个地方时,从断点的执行链路可以知道互相依赖的两个bean的完整创建过程
4.3 为什么使用三级缓存?
这里有个值得思考的问题,为什么要包装一层ObjectFactory对象存入三级缓存,上面说是为了解决Bean对象存在aop代理情况。如果直接生成代理对象半成品Bean放入二级缓存,这样就可以不用三级缓存了,这么说使用三级缓存的意义在哪里呢?
首先需要明确一点:正常情况下(没有循环依赖),Spring都是在创建好成品Bean之后才创建对应的代理对象。为了处理循环依赖,Spring有两种选择:
1)不管有没有循环依赖,都提前创建好代理对象,并将代理对象放入缓存,出现循环依赖时,其他对象直接就可以取到代理对象并注入;
2)不提前创建好代理对象,在出现循环依赖被其他对象注入时,才实时生成代理对象。这样在没有循环依赖的情况下,Bean就可以按着Spring设计原则的步骤来创建;
显然spring使用了三级缓存,选择第二种方案,为什么呢?原因如下:
如果要使用二级缓存解决循环依赖,意味着Bean在构造完后就创建代理对象,这样违背了Spring设计原则。Spring结合AOP跟Bean的生命周期,是在Bean创建完全之后通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
经过实例化,初始化、属性赋值等操作之后,bean对象已经是一个完整的实例了,最终会调用DefaultSingletonBeanRegistry的#addSingleton()将完整bean放入一级缓存singletonObjects。
protected void addSingleton(String beanName, Object singletonObject) {synchronized (this.singletonObjects) {this.singletonObjects.put(beanName, singletonObject);this.singletonFactories.remove(beanName);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}
}到这里一个完整的Bean已经存入Spring容器中,就可以被其他对象注入使用了。
4.4 spring循环依赖解决方案小结
以上全部就是Spring对单例bean循环依赖的解决方案,核心就是使用三级缓存提前暴露bean对象,对于两个互相引用循环依赖的bean,Spring解决过程如下:
-
通过构建函数创建A对象(A对象是半成品,还没注入属性和调用init方法);
-
A对象需要注入B对象,发现缓存里还没有B对象,将半成品对象A放入半成品缓存;
-
通过构建函数创建B对象(B对象是半成品,还没注入属性和调用init方法);
-
B对象需要注入A对象,从半成品缓存里取到半成品对象A;
-
B对象继续注入其他属性和初始化,之后将完成品B对象放入完成品缓存;
-
A对象继续注入属性,从完成品缓存中取到完成品B对象并注入;
-
A对象继续注入其他属性和初始化,之后将完成品A对象放入完成品缓存;
五、写在文末
本文详细总结了spring循环依赖问题的解决方案,并通过源码分析详细探讨了spring如何使用三级缓存解决在单例bean模式下的解决过程,循环依赖的解决思想具有很好的借鉴意义,在日常工作中也很有指导作用,有兴趣的同学可以借此深入研究,本篇到此结束,感谢观看!