目录
1 机器学习中的Helloworld _鸾尾花分类项目
2 导入项目所需类库和鸾尾花数据集
2.1 导入类库
2.2 scikit-learn 库介绍
(1)主要特点:
(2)常见的子模块:
3 导入鸾尾花数据集
3.1 概述数据
3.2 数据维度
3.3 查看数据自身
3.4 统计描述数据
3.5 数据分类分布
4 数据可视化
4.1 单变量图表
4.2 多变量图表
1 机器学习中的Helloworld _鸾尾花分类项目
鸢尾花分类是机器学习领域中的一个经典示例,也是一个适用于入门级学习者的 "Hello World" 项目。这个项目使用鸢尾花数据集,其中包含了三个不同种类的鸢尾花:Setosa、Versicolor 和 Virginica。这三个亚属分别属于鸢尾属(Iris)中的不同物种。
2 导入项目所需类库和鸾尾花数据集
2.1 导入类库
# 导入鸢尾花数据集
from sklearn import datasets# 导入数据处理和分割工具
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 导入分类器模型
from sklearn.neighbors import KNeighborsClassifier# 导入性能评估指标
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 导入可视化工具
import matplotlib.pyplot as plt
import seaborn as sns
这段代码导入了以下类库和模块:
datasets:从 scikit-learn 中导入数据集。train_test_split:用于将数据集分割成训练集和测试集的模块。StandardScaler:用于数据标准化的模块,对特征进行缩放。KNeighborsClassifier:K近邻分类器,用于鸢尾花分类任务。accuracy_score、classification_report、confusion_matrix:用于评估分类器性能的模块。matplotlib.pyplot和seaborn:用于可视化数据和评估结果的模块。
请确保在运行这段代码之前已经安装了这些库,可以使用以下命令安装:
pip install scikit-learn matplotlib seaborn
导入这些类库后,你就可以在鸢尾花分类项目中使用它们进行数据处理、建模和评估。
2.2 scikit-learn 库介绍
scikit-learn 是一个用于机器学习的 Python 库,提供了丰富的工具和模型,用于数据挖掘和数据分析。它建立在 NumPy、SciPy 和 Matplotlib 基础之上,是机器学习领域中最受欢迎的库之一。
(1)主要特点:
简单而高效:
scikit-learn提供了简单且一致的接口,易于学习和使用。它支持多种机器学习任务,包括分类、回归、聚类、降维等。丰富的文档: 该库具有详细的文档,包括用户指南、教程和示例,使用户能够更好地理解和使用不同的算法和工具。
广泛的算法:
scikit-learn包含了许多经典和先进的机器学习算法,如支持向量机(SVM)、随机森林、K均值聚类等。数据预处理: 提供了丰富的数据预处理工具,包括数据标准化、特征选择、缺失值处理等。
模型评估: 支持模型性能评估的工具,包括交叉验证、网格搜索调参、性能度量等。
可扩展性: 允许用户通过创建自定义转换器和评估器来扩展功能,也支持集成其他库。
(2)常见的子模块:
datasets 模块: 包含一些常用的数据集,如鸢尾花数据集、手写数字数据集等。
model_selection 模块: 提供了用于交叉验证、超参数调优等的工具。
preprocessing 模块: 包含数据预处理的工具,如标准化、缩放、编码等。
metrics 模块: 包含模型评估的指标,如准确率、精确度、召回率等。
ensemble 模块: 包含集成学习方法,如随机森林、梯度提升树等。
neighbors 模块: 包含近邻算法,如 K 近邻分类器。
svm 模块: 包含支持向量机算法。
cluster 模块: 包含聚类算法,如 K 均值聚类、层次聚类等。
decomposition 模块: 包含降维算法,如主成分分析(PCA)等。
3 导入鸾尾花数据集
3.1 概述数据
鸢尾花数据集是由统计学家和生物学家Ronald A. Fisher于1936年创建的,用于展示多变量统计方法。该数据集包含了三个不同种类的鸢尾花(Setosa、Versicolor 和 Virginica)的测量数据。
导入数据集
from sklearn import datasets# 导入鸢尾花数据集
iris = datasets.load_iris()# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target
你可以在 UCI Machine Learning Repository 网站上找到鸢尾花数据集的信息和下载链接:Iris Data Set![]() https://archive.ics.uci.edu/ml/datasets/iris然后,你可以下载数据集并使用适当的工具进行导入和处理。
https://archive.ics.uci.edu/ml/datasets/iris然后,你可以下载数据集并使用适当的工具进行导入和处理。
3.2 数据维度
查看数据维度
from sklearn import datasets
import pandas as pd# 导入鸢尾花数据集
iris = datasets.load_iris()# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target# 创建数据框
df = pd.DataFrame(data=X, columns=iris.feature_names)
df['target'] = y# 查看数据集的维度
print(f"数据集维度:{df.shape}")

数据集的特征包括:
- 萼片长度(Sepal Length)
- 萼片宽度(Sepal Width)
- 花瓣长度(Petal Length)
- 花瓣宽度(Petal Width)
每个特征都以厘米为单位进行测量。
3.3 查看数据自身
首先,让我们看一下数据集的一些样本和它们的标签:
from sklearn import datasets
import pandas as pdiris = datasets.load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
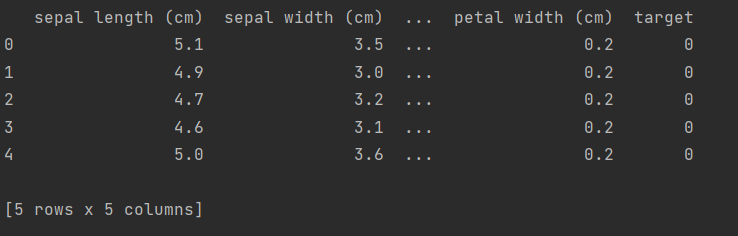
df['target'] = iris.target# 打印数据集的前几行
print(df.head())
输出:
3.4 统计描述数据
我们可以使用 pandas 库的 describe() 方法获取关于数据的统计描述信息:
from sklearn import datasets
import pandas as pdiris = datasets.load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target# 打印数据集的前几行
print(df.head())
# 统计描述
print(df.describe())
输出:

3.5 数据分类分布
查看鸢尾花数据集中每个类别的分布:
from sklearn import datasets
import pandas as pdimport matplotlib.pyplot as plt
import seaborn as snsiris = datasets.load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target# # 打印数据集的前几行
# print(df.head())
# # 统计描述
# print(df.describe())# 绘制数据集中每个类别的计数分布
sns.countplot(x='target', data=df)
plt.title('Class Distribution in Iris Dataset')
plt.show() 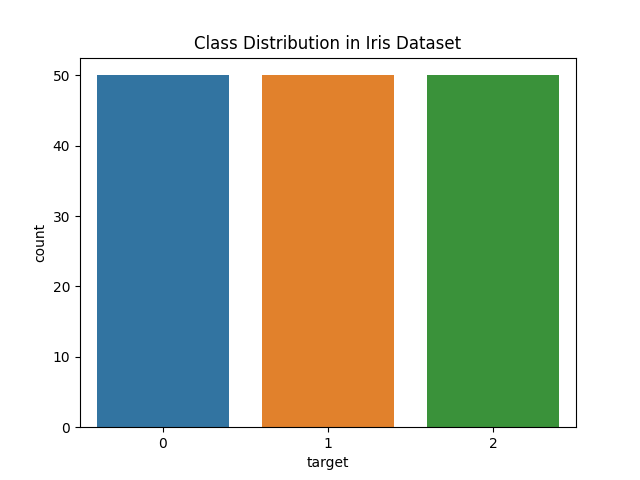
以上步骤可以让你更好地了解鸢尾花数据集,包括特征的维度、样本的分布情况等。这些信息对于进行机器学习任务之前的数据探索和理解非常重要。
4 数据可视化
通过对数据集的审查,对数据有一个基本的了解。接下来将通过图标来进一步查看数据特征的分布情况和数据不同特征之间的相互关系。
使用单变量图表可以更好地理解每一个特征属性。
多变量图表用于理解不同特征属性之间的关系。
4.1 单变量图表
from sklearn import datasets
import pandas as pd# 导入鸢尾花数据集
iris = datasets.load_iris()# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target# 创建数据框
df = pd.DataFrame(data=X, columns=iris.feature_names)
df['target'] = y# 查看数据集的维度
print(f"数据集维度:{df.shape}")import matplotlib.pyplot as plt
import seaborn as sns# 设置图形样式
sns.set(style="whitegrid")# 创建单变量图表
plt.figure(figsize=(12, 6))# 绘制花萼长度的直方图
plt.subplot(2, 2, 1)
sns.histplot(df['sepal length (cm)'], kde=True, color='skyblue')
plt.title('Distribution of Sepal Length')# 绘制花萼宽度的直方图
plt.subplot(2, 2, 2)
sns.histplot(df['sepal width (cm)'], kde=True, color='salmon')
plt.title('Distribution of Sepal Width')# 绘制花瓣长度的直方图
plt.subplot(2, 2, 3)
sns.histplot(df['petal length (cm)'], kde=True, color='green')
plt.title('Distribution of Petal Length')# 绘制花瓣宽度的直方图
plt.subplot(2, 2, 4)
sns.histplot(df['petal width (cm)'], kde=True, color='orange')
plt.title('Distribution of Petal Width')plt.tight_layout()
plt.show()
4.2 多变量图表
from sklearn import datasets
import pandas as pd# 导入鸢尾花数据集
iris = datasets.load_iris()# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target# 创建数据框
df = pd.DataFrame(data=X, columns=iris.feature_names)
df['target'] = y# 查看数据集的维度
print(f"数据集维度:{df.shape}")import matplotlib.pyplot as plt
import seaborn as sns# 设置图形样式
sns.set(style="whitegrid")# 创建多变量图表
plt.figure(figsize=(12, 6))# 绘制花萼长度和宽度的散点图
plt.subplot(1, 2, 1)
sns.scatterplot(x='sepal length (cm)', y='sepal width (cm)', hue='target', data=df, palette='viridis')
plt.title('Scatter Plot of Sepal Length vs. Sepal Width')# 绘制花瓣长度和宽度的散点图
plt.subplot(1, 2, 2)
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='target', data=df, palette='viridis')
plt.title('Scatter Plot of Petal Length vs. Petal Width')plt.tight_layout()
plt.show()
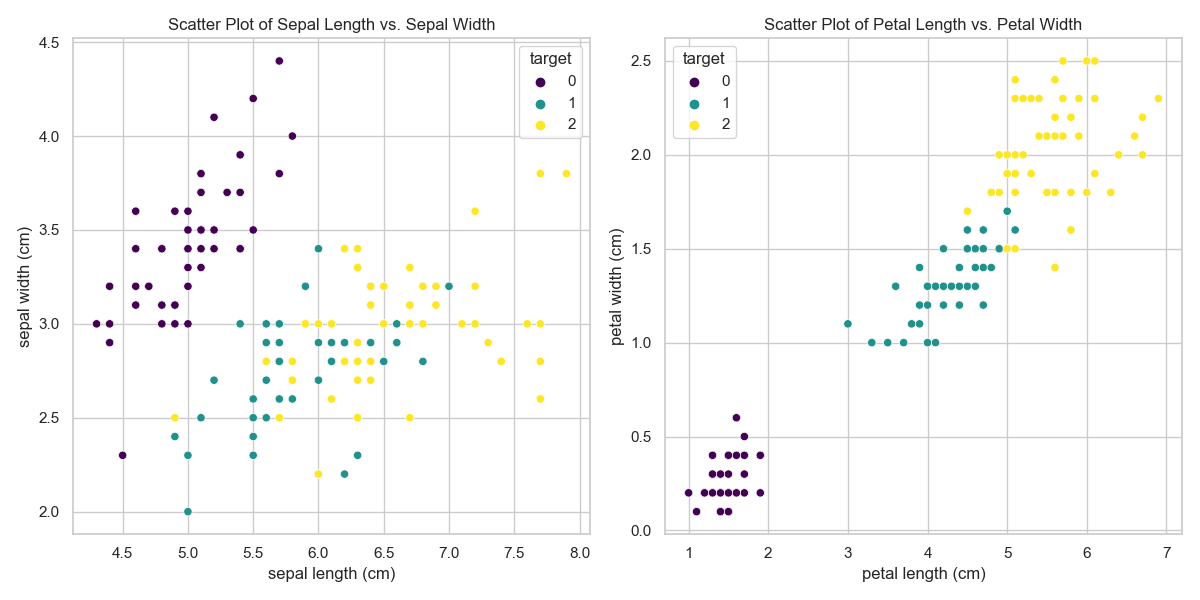
这些代码使用了
seaborn库,通过直方图展示了花萼和花瓣的长度和宽度的分布情况,并使用散点图展示了花萼长度和宽度以及花瓣长度和宽度之间的关系。这些可视化图表可以帮助你更好地了解数据集的特征和类别之间的差异。

![[ 蓝桥杯Web真题 ]-Markdown 文档解析](https://img-blog.csdnimg.cn/direct/05ec9015f07242cfaf4c8147c864286b.png)

![无参RCE [GXYCTF2019]禁止套娃1](https://img-blog.csdnimg.cn/direct/dde7ee448886493ead312baffe75b7de.png)