亚马逊运营推荐数仓项目实战项目技术栈
Hadoop+Spark +(Python)Scala + SparkSQL+SparkStreaming + MongoDB + Redis + Kafka + Flume +( SpringMVC + vue) |
1 项目介绍
1.1 项目系统架构
项目以推荐系统建设领域知名的经过修改过的中文亚马逊电商数据集作为依托,以某电商网站真实业务数据架构为基础,构建了符合教学体系的一体化的电商推荐系统,包含了离线推荐与实时推荐体系,综合利用了协同过滤算法以及基于内容的推荐方法来提供混合推荐。提供了从前端应用、后台服务、算法设计实现、平台部署等多方位的闭环的业务实现。
推荐系统最重要是2个阶段:召回 + 排序
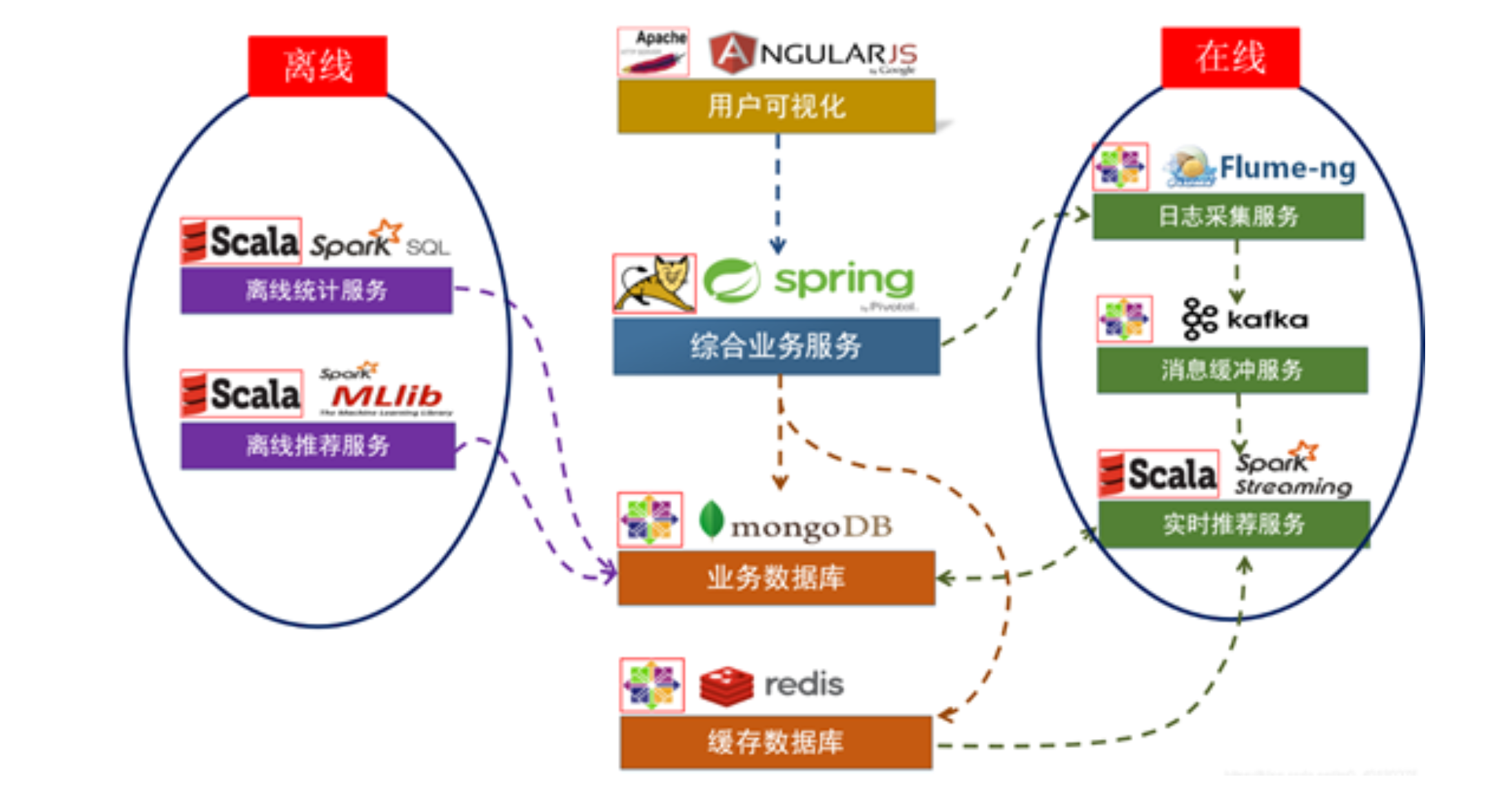
用户可视化:
主要负责实现和用户的交互以及业务数据的展示,主体采用AngularJS2进行实现,部署在 Apache服务上。
综合业务服务:
主要实现JavaEE层面整体的业务逻辑,通过Spring进行构建,对接业务需求。部署在 Tomcat上。
【数据存储部分】
业务数据库:
项目采用广泛应用的文档数据库MongDB作为主数据库,主要负责平台业务逻辑数据的存储。
缓存数据库:
项目采用Redis作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需 求。
【离线推荐部分】
离线统计服务:
批处理统计性业务采用Spark Core + Spark SQL进行实现,实现对指标类数据的统计任务。
离线推荐服务:
离线推荐业务采用Spark Core + Spark MLlib进行实现,采用ALS算法进行实现。
【实时推荐部分】
日志采集服务:
通过利用Flume-ng对业务平台中用户对于商品的一次评分行为进行采集,实时发送到 Kafka集群。
消息缓冲服务:
项目采用Kafka作为流式数据的缓存组件,接受来自Flume的数据采集请求。并将数据 推送到项目的实时推荐系统部分。
实时推荐服务:
项目采用Spark Streaming作为实时推荐系统,通过接收Kafka中缓存的数据,通过设 计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到MongoDB数据库。
1.2 项目数据流程
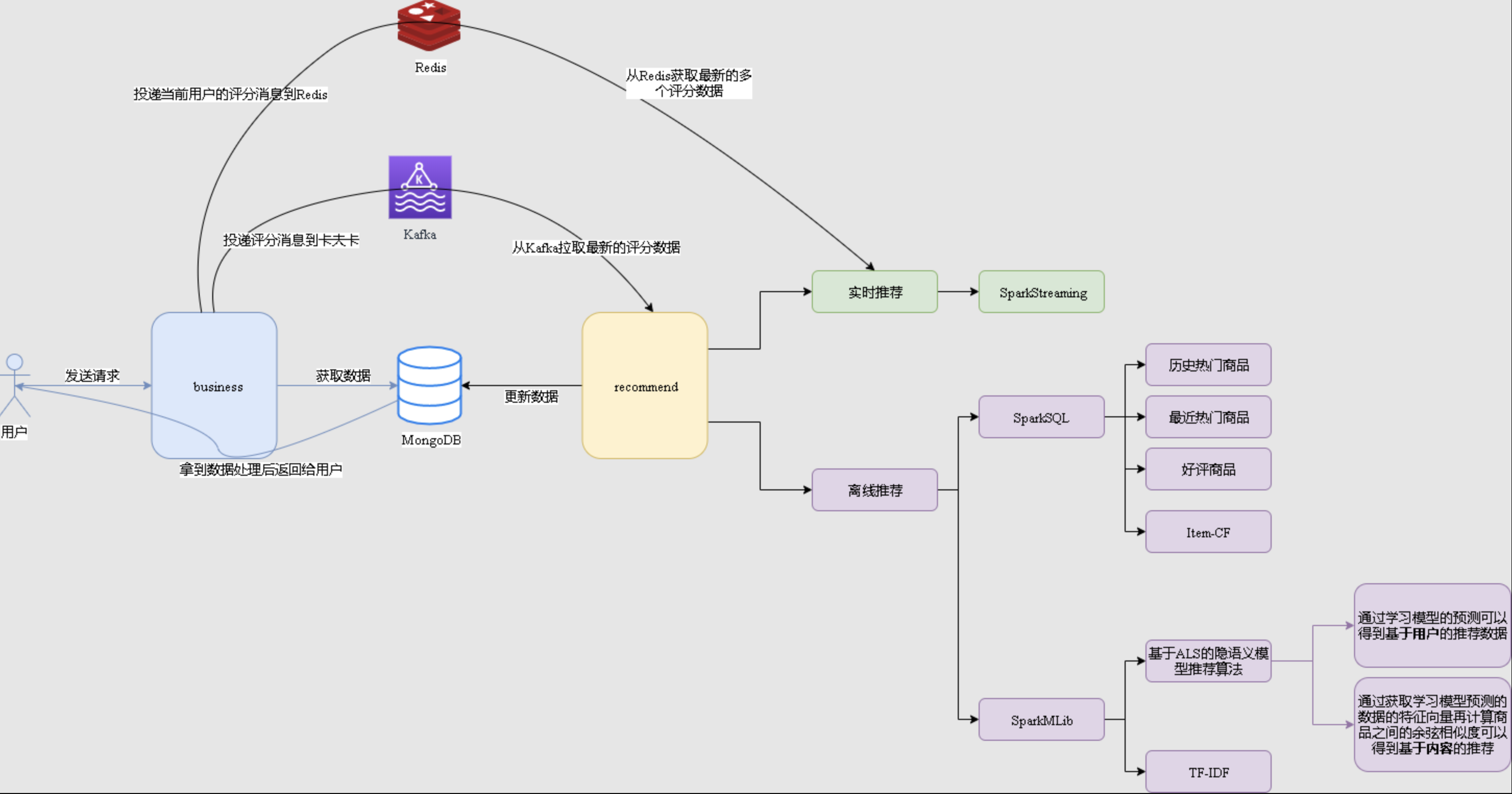
【系统初始化部分】
通过Spark SQL将系统初始化数据加载到MongoDB中。
【离线推荐部分】
可以通过Azkaban实现对于离线统计服务以离线推荐服务的调度,通过设定的运行时间完成对任务 的触发执行。
离线统计服务从MongoDB中加载数据,将【商品平均评分统计】、【商品评分个数统计】、【最 近商品评分个数统计】三个统计算法进行运行实现,并将计算结果回写到MongoDB中;离线推荐 服务从MongoDB中加载数据,通过ALS算法分别将【用户推荐结果矩阵】、【影片相似度矩阵】 回写到MongoDB中。
【实时推荐部分】
Flume从综合业务服务的运行日志中读取日志更新,并将更新的日志实时推送到
Kafka
中;
Kafka
在收到这些日志之后,通过
kafkaStream
程序对获取的日志信息进行过滤处理,获取用户评分数 据流
【UID|MID|SCORE|TIMESTAMP】
,并发送到另外一个
Kafka
队列;
Spark Streaming
监 听
Kafka
队列,实时获取
Kafka
过滤出来的用户评分数据流,融合存储在
Redis
中的用户最近评分 队列数据,提交给实时推荐算法,完成对用户新的推荐结果计算;计算完成之后,将新的推荐结果和
MongDB
数据库中的推荐结果进行合并。
【业务系统部分】
推荐结果展示部分,从MongoDB中将离线推荐结果、实时推荐结果、内容推荐结果进行混合,综 合给出相对应的数据。
商品信息查询服务通过对接MongoDB实现对商品信息的查询操作。
商品评分部分,获取用户通过UI给出的评分动作,后台服务进行数据库记录后,一方面将数据推动到Redis群中,另一方面,通过预设的日志框架输出到Tomcat中的日志中。
商品标签部分,项目提供用户对商品打标签服务。
二、大数据梗概
1.1什么是大数据
数据:指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新模式才能具有更强大的决策力,洞察发现力和流程优化能力的海量,高增长率和多样化的信息资产
最小的基本单位是bit,按顺序给出所有单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
1 KB = 1,024 Bytes = 8192 bit` 1 MB = 1,024 KB = 1,048,576 Bytes` 1 GB = 1,024 MB = 1,048,576 KB` 1 TB = 1,024 GB = 1,048,576 MB` 1 PB = 1,024 TB = 1,048,576 GB` 1 EB = 1,024 PB = 1,048,576 TB` 1 ZB = 1,024 EB = 1,048,576 PB` 1 YB = 1,024 ZB = 1,048,576 EB` 1 BB = 1,024 YB = 1,048,576 ZB` 1 NB = 1,024 BB = 1,048,576 YB` 1 DB = 1,024 NB = 1,048,576 BB`
大数据,官方定义是指那些数据量特别大、数据类别特别复杂的数据集,这种数据集无法用传统的数据库进行存储,管理和处理。 大数据的主要特点为:
数据量大(Volume)
数据类别复杂(Variety)
数据处理速度快(Velocity)
数据真实性高(Veracity)
合起来被称为4V。
还有的将大数据特点定义为6V模型,即增加了Valence(连接)、Value(价值)2V。
大数据常见概念分类 大数据相关的概念大家都听过不少:HDFS、MapReduce、Spark、Storm、Spark Streaming、Hive、Hbase、Flume、Logstash、Kafka、Flink、Druid、ES等等。 是否感觉眼花缭乱? 下面我们将这些常见的概念进行分组。 同一组的框架(工具)可以完成相同的工作,但各自使用的场景有所差异。
01 计算框架 离线计算:Hadoop MapReduce、Spark 实时计算:Storm、Spark Streaming、Flink
02 存储框架 文件存储:Hadoop HDFS、Tachyon、KFS NOSQL数据库:HBase、MongoDB、Redis 全文检索:ES、Solr
03 资源管理 YARN、Mesos
04 日志收集 Flume、Logstash
05 消息系统 Kafka、StormMQ、ZeroMQ、RabbitMQ
06 查询分析 Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Kylin、Druid
1.2大数据应用
从证券行业到医疗领域,越来越多公司意识到大数据的重要性。2015年Gartner调查显示,超过75%的公司正在投资或计划在未来两年内投资大数据。而在2012年进行的类似调查中,仅有58%的公司在未来两年内计划投资大数据。
增强客户体验、降低成本、精准营销以及提高流程效率、数据安全是公司关注大数据的主要目的。本文将研究正在使用大数据的10个垂直行业及面临的挑战,以及大数据如何解决这些难题。
1 银行和证券
挑战:
通过对10家投行券商的16个项目的研究表明,该行业面临的挑战包括:证券欺诈预警、蜱虫分析、检测卡片欺诈、审计跟踪档案、企业信用风险报告、贸易可视性、客户数据转换、用于交易的社交分析、IT运营分析和IT策略合规性分析等。
应用:
证券交易委员会(SEC)正在使用大数据网络分析和自然语言处理器来捕捉金融市场中的非法交易活动。
商业银行,对冲基金和其他金融公司在高频交易的交易分析,交易前的决策支持分析,情绪测量,预测分析等方向使用大数据。
该行业还严重依赖大数据进行风险分析,这其中包括:反洗钱,企业风险管理,客户画像,以及减少欺诈行为等。
2 通讯,媒体和娱乐
挑战:
每个观众消费着不同形式的娱乐,以及不同的娱乐设备,因此通信,媒体和娱乐行业正面临以下大数据挑战:
1 收集,分析和利用消费者习惯
2 利用移动和社交媒体内容
3 实时追踪媒体内容使用形式
应用:
公司同时分析客户数据和行为数据,以创建详细的客户档案,可用于:
1 个性化定制内容
2 按需推荐内容
3 衡量内容结果
一个典型的例子是国外视频网站YouTube上的温网比赛,它利用大数据实时向电视、移动和网络用户提供网球比赛的详尽的情感分析。亚马逊Prime大量使用大数据,在一站式商店提供视频,音乐和Kindle书籍来提供卓越的客户体验。
1.3大数据发展前景
大数据技术目前正处在落地应用的初期,从大数据自身发展和行业发展的趋势来看,大数据未来的前景还是不错的,具体原因有以下几点:
第一:大数据自身能够创造出更多的价值。大数据相关技术紧紧围绕数据价值化展开,数据价值化将开辟出广大的市场空间,重点在于数据本身将为整个信息化社会赋能。随着大数据的落地应用,大数据的价值将逐渐得到体现。目前在互联网领域,大数据技术已经得到了较为广泛的应用。
第二:大数据推动科技领域的发展。大数据的发展正在推动科技领域的发展进程,大数据的影响不仅仅体现在互联网领域,也体现在金融、教育、医疗等诸多领域。在人工智能研发领域,大数据也起到了重要的作用,尤其在机器学习、计算机视觉和自然语言处理等方面,大数据正在成为智能化社会的基础。
第三:大数据产业链逐渐形成。经过近些年的发展,大数据已经初步形成了一个较为完整的产业链,包括数据采集、整理、传输、存储、分析、呈现和应用,众多企业开始参与到大数据产业链中,并形成了一定的产业规模,相信随着大数据的不断发展,相关产业规模会进一步扩大。
第四:产业互联网将推动大数据落地。当前互联网正在经历从消费互联网向产业互联网过渡,产业互联网将利用大数据、物联网、人工智能等技术来赋能广大的传统产业,可以说产业互联网的发展空间非常大,而大数据则是产业互联网发展的一个重点,大数据能否落地到传统行业,关乎产业互联网的发展进程,所以在产业互联网阶段,大数据将逐渐落地,也必然落地。
通过以上分析可以得出,未来大数据领域的发展空间还是比较大的,而且目前大数据领域的人才缺口比较大,所以从就业的角度来说,当前学习大数据相关知识是个不错的选择。
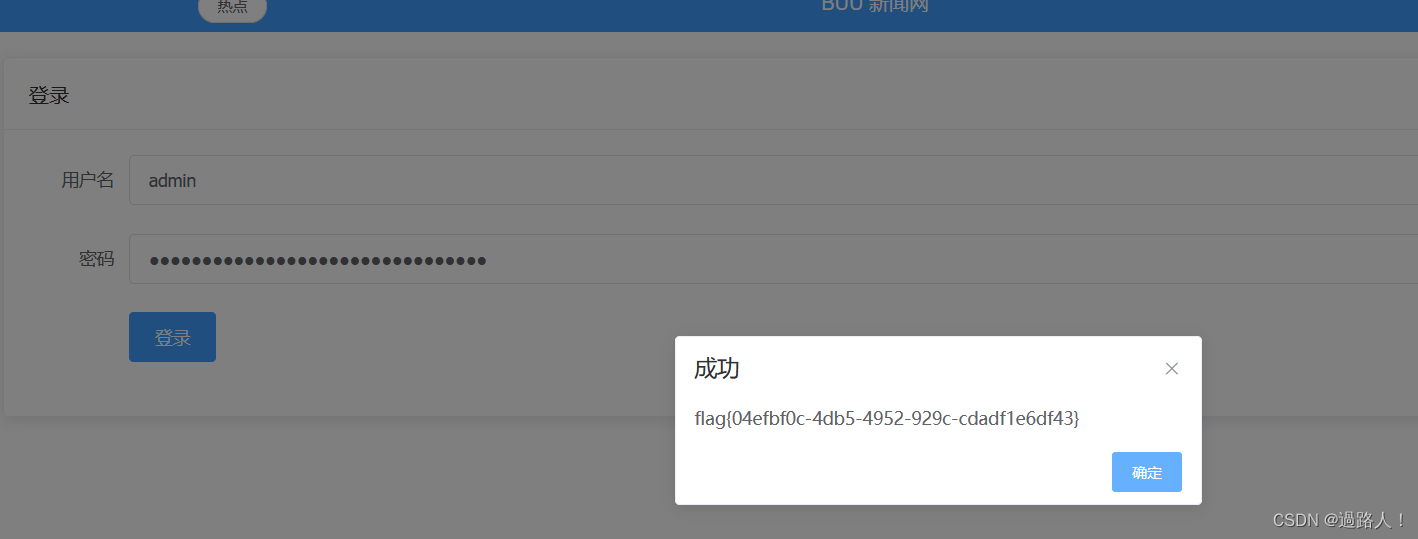
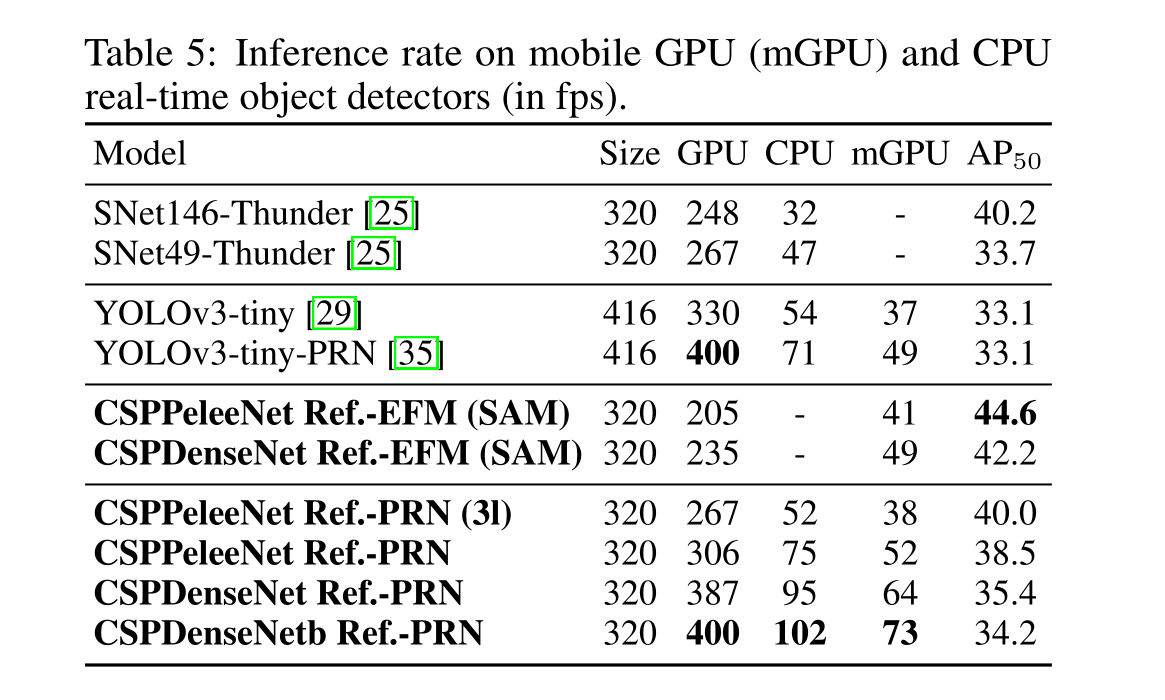
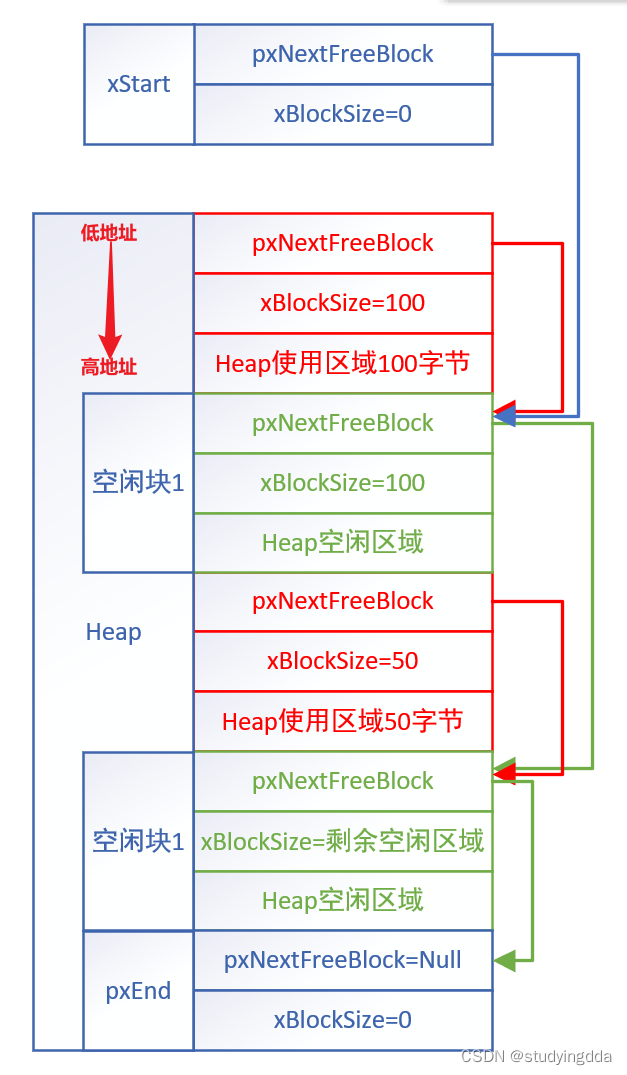
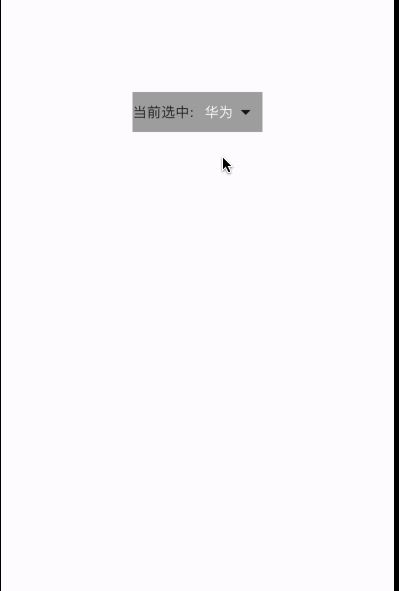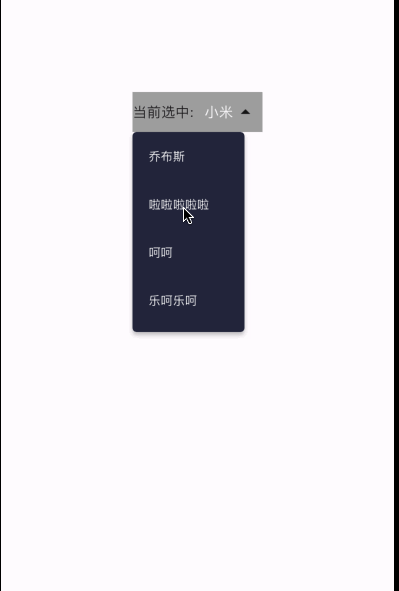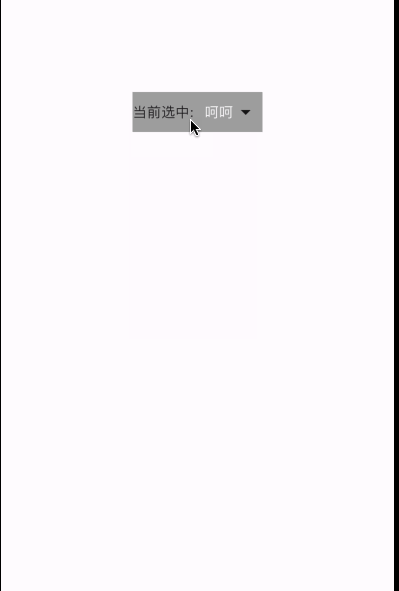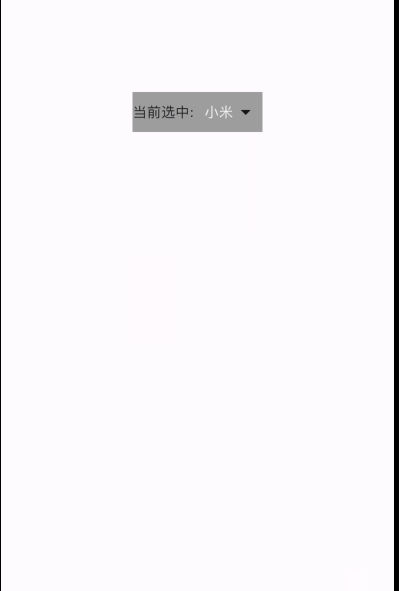
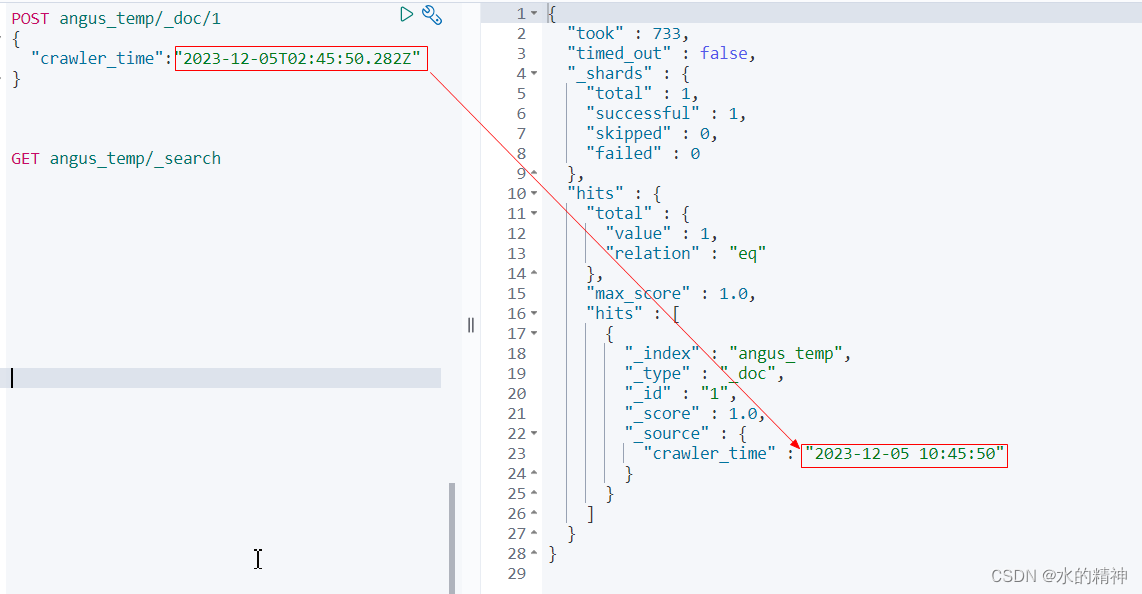
项目运行截图