Stable Diffusion 的整个算法组合为: UNet + VAE + 文本编码器
UNet:就是我们大模型里的核心。
文本编码器:将我们的prompt进行encoder为算法能理解的内容(可以理解为SD外包出去的项目CLIP)。
VAE:对UNet生成的图像作后处理。
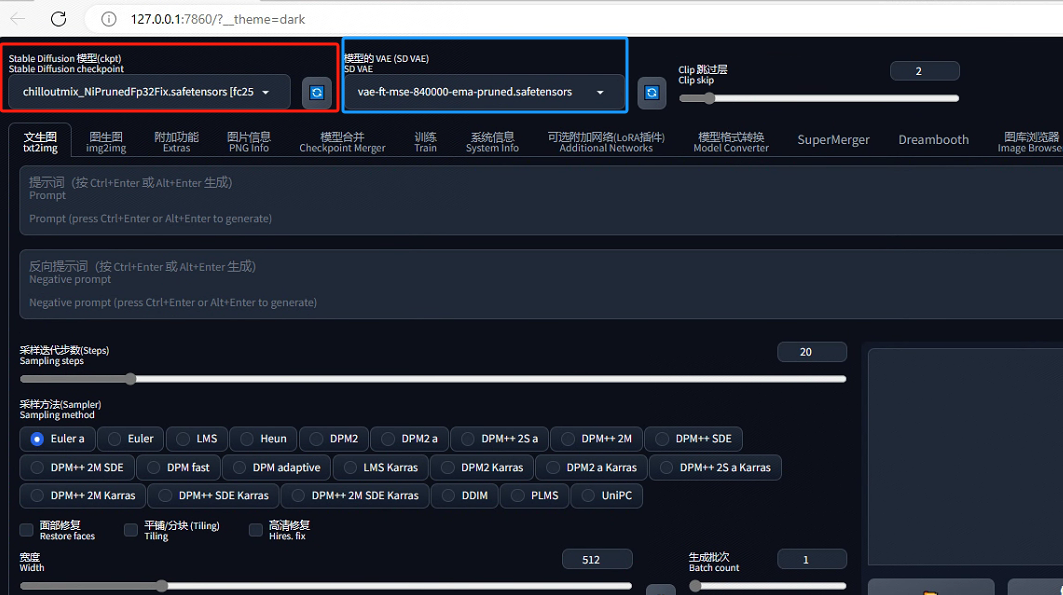
上图中红框代表的是大模型,可以通过下拉的方式来替换自己所需要的大模型。该参数控制着出图内容的基调,如真实场景、二次元或建筑模型。我们可以将其理解为拥有无数图像的数据库,根据prompt拿出一堆相关图像拼到一起生成出最终的图像。也就是说想要生成什么样的内容,就得需要一个什么样的数据库。通常,我们所使用的大模型都是在最原始的大模型SD1.5或者XL1.0上进行微调的,如dreambooth,其大小一般在2G,4G或7G不等。其存放目录如下所示:
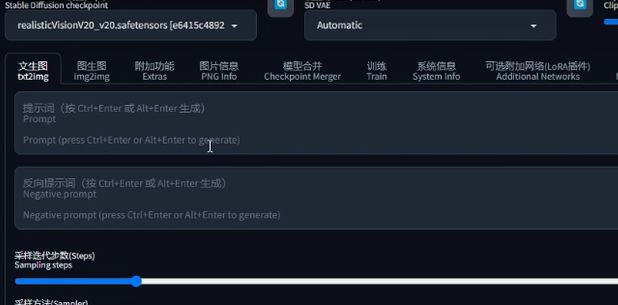
大模型本身是自带VAE的,正常情况下蓝框只需要选择无或自动匹配即可。如果蓝框做了选择,即使用了外挂VAE,那么大模型本身的VAE就不会起作用。
CLIP(Contrastive language-image pre-training):其作用是将文字和图像转化为AI能够识别的数据后再将它们一一对应。在蓝框旁边,有一个“CLIP跳过层”选项。主要作用是将CLIP模型提前停止。数值设几就代表在倒数第几层停止。通俗一点来说,CLIP模型的推理是一个添加N次提示词的内容,每添加一次,生成的内容就越接近prompt。因此这个数值可以控制prompt和生成图片的相关程度,但不会控制图像风格的变化。实际作用大不大,只能说仁者见仁,智者见智。因为有时候前向跑的过多了反而含义就错了。

以下是对文生图的部分使用说明:
提示词和反向提示词:控制着生成图片中想要的元素和不想要的元素。
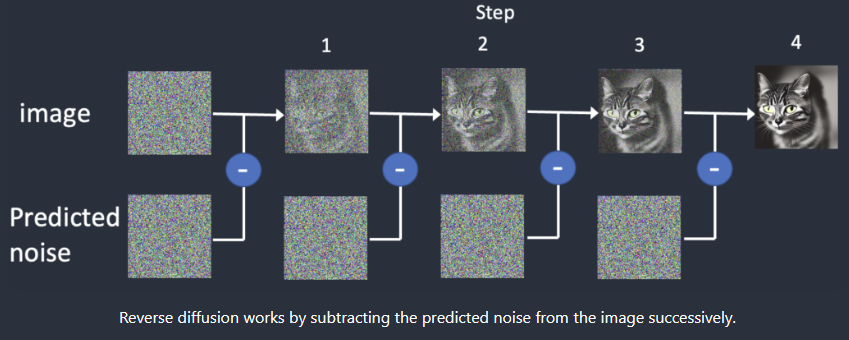
采样迭代步数和采样方法:在说这个前,我们首先得明白SD的工作原理。首先,模型会生成一张完全随机的噪声图像。随后噪声预测器将生成需要剔除部分的噪声并和原始图像运算得到下一步的输出。随后不断重复这个过程,得到最终的结果。整个去噪的过程就是采样的过程,每次采样就算迭代一次,去噪的手段就是采样方法。其中采样器有以下几个:
- 经典ODE采样器:Eular采样器:欧拉采样方法,好用却不太准确。Heun采样器:欧拉的一个更准确但更慢的版本。LMS采样器:线性多步法,与欧拉采样器速度相仿,但是更准确。
- DPM:扩散概率模型求解器。DPM会自适应调整步长,不能保证在约定的采样步骤内完成任务,速度较慢。DPM++相对来说结果更准确,但速度更更慢。
- 祖先采样器:名称中带有a标识的采样器都是祖先采样器。这一类采样器在每个采样步中都会向图像添加噪声,导致结果具有随机性。部分没有带a的采样器也属于祖先采样器,如Eular a,DPM2 a,DPM++2S a,DPM++2S a KARRAS,DPM++ SDE,DPM++SDE KARRAS。
- Karras Noise Schedule:带有Karras字样的采样器,最大的特色是使用了Karras论文中的噪声计划表,主要表现是去噪的程度在开头会比较高,在接近尾声时会变小,有助于提升图像质量。
- UniPC:统一预测矫正器。一种可以在5~10步实现高质量图像的方法。
- DPM Adaptive:采样器不会跟着步数去收敛,会一直收敛至最好的效果。
有一个知乎大佬对采样方法做了测试得到以下结论:
- Eular和Heun:日常训练中,只想看一看出图的内容是什么样的,相对准确且快。
- DPM++2M KARRAS和UniPc:能够输出一张各方面均衡且高质量的图片。
- DPM++SDE KARRAS:能够输出一张有一定随机变化的且高质量的图片。
关于采样步数的设定:不要太大也不要太小。太小则来不及把细节都画完,太大则容易在某一个地方不断的精细化导致光斑或裂缝。推荐50以下。
面部修复:解决SD1.5在画人脸上的一些问题。对真人的人脸进行一定程度的调整,有效但不绝对。尤其是画特定脸时就不要开启这个面部修复了。
平铺分块:生成的图像复制多份时能够彼此无缝衔接。
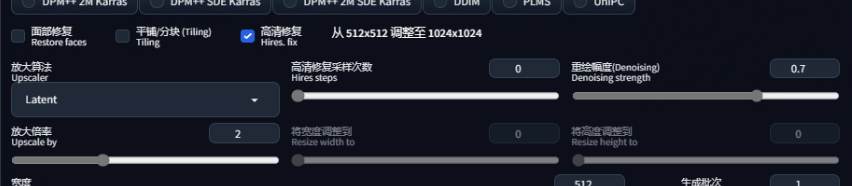
高清修复:解决SD1.5无法生成像素较高的图像。除去XL1.0模型是以1024分辨率为基础的。常用的SD1.5的底模是512分辨率的,导致出图时只有接近512的像素才会得到一个比较好的效果(增大尺寸可能会导致多头多手)。高清修复采样次数如果为0,则以采样迭代步数作为实际步数。重绘幅度如果为0就代表修复后的图片不会有任何变化。对于放大算法的选择:
- 4x-UltraSharp:基于ESRGAN做了优化模型,更适合常见的图片格式真人模型最佳选择。各方面能力出众,目前最实用,最优的选择,更贴合真实效果。
- SwinIR 4x:使用SwinTransformer模型,拥有局部自适应的内容,更好的提取可特征,提高图像细节,保证放大图片真实感稳定训练,很全面却没有一方面超过别的算法。
- Nearest:非常传统的归类找近似值的方法,计算新的东西和旧的东西的相似度,以最相似的内容去出图,大数据时效果好,实际一般。
- Lanczos:把正交矩阵将原始矩阵变换为一个三对角矩阵,一种用于对称矩阵的特征值分解的算法,比起其他几种算法没有什么优势。
- R-ESRGAN 4x+:基于RealESRGAN的优化模型,针对照片效果不错。提高图像分辨率的同时,也可以增强图像的细节和纹理,并且生成的图像质量比传统方法更高。
- R-ESRGAN 4x+ Anime6B:基于RealESRGAN的优化模型,在生成二次元图片时更加准确且高效。
- Latent:一种基于原始图像编码图像增强算法,对其进行随机采样和重构,从而增强图像的质量、对比度和清晰度。显存消耗比较小,效果中上,且贴合提示词。
- ESRGAN:对SRGAN关键部分网络结构、对抗损失、感知损失的增强。从这里开始就不是单纯的图像算法,进入人工智能的领域了。实测确实增加了很多看上去很真实的纹理,但是有时又会把一张图片弄得全是锯齿或怪异的纹理。可能对待处理的图片类型有要求。
- ESRGAN 4x:它是ESRGAN算法的一种改进版本,可以将低分辨率的图像通过神经网络模型增强到4倍的分辨率,在增强图像的细节信息和保留图像质量方面有了明显的提升。
- LDSR:潜在扩散超分辨率,效果写实,但是慢。
以下是不同高清修复算法的原理:
Text2Image页面中的Highres Upscaling:首先通过SD前半部分(给定提示词,CLIP会将提示词翻译为可理解的向量,随后喂入神经网络生成Latent结果)。不同的是不会立即进行解码,如果选择了Latent Upscaler的话,会基于Latent做Upscaling,得到另外一个Latent。再去进行解码。得到比原始输入(512×512)还大的图(1024×1024)。优势:基于Latent速度比较快,且是在SD的模型中做的Upscaling,所以会更加好的去理解prompt,对图片上下文进行处理。
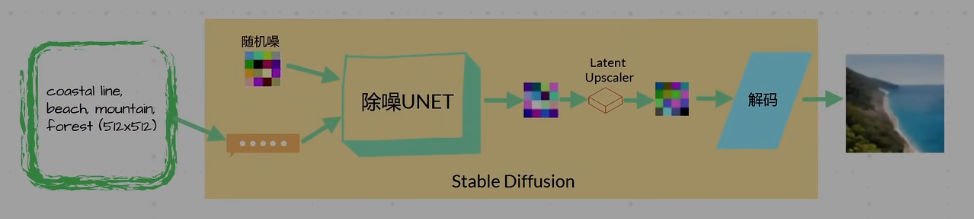
Image2Image Upscaling:需要的输入有两部分:512×512的图和一段说明(指定输入为1024×1024)。首先需要用编码器将图变为Latent,随后再生成一个随即噪音,何其进行Concat(可以理解为给图像打了马赛克)。文字说明则依旧通过CLIP变为一个可理解的向量。把这两个东西同时输入到SD的后半部分就完事了。(相比于上一个算法上下文的理解会稍微弱一点,而且仅用了SD模型本身的特性来生成这张图像。)

Extra Upscaling:直接输入一张图,用通用的Upscaling算法生成一张大图。没有上下文,但更加灵活多用。

SD UPscale Upscaling:Image2Image Upscaling的扩展版本。即通过通用的Upscaling的算法先把图像扩大一倍。随后将图像分成小块。在进行Image2Image Upscaling的过程,只不过是对每一个小块做处理。最后将生成的四个小块做拼接。

提示词相关性(CFG Scale):越低越自由越放飞,越高则越严格按照prompt。太高也容易产生撕裂和光斑。推荐7~9。
Denoising strength:给一张原图,想在原图的基础上画新的图。越低则越忠于原图,越高则越放飞自我。






![[每周一更]-(第76期):Go源码阅读与分析的方式](https://img-blog.csdnimg.cn/direct/8dc0a8cc00dd417496b2d9778712bccb.jpeg#pic_center)