我在知乎关于《微软小冰智能聊天是如何实现的?》做的回答
刚好做过一个类似的产品,虽然没有那么高大上,但一些核心技术原理应该也参考意义,说一下做的思路。
类似小冰这样的产品说简单也简单,说复杂也复杂。单纯从外面看你会觉得小冰与去年人人网上流行的小黄鸡类似,但在技术实现上有本质的差异。
此类应用的大致流程都是:用户输入一段话(不一定只是单词)->后端语义引擎对用户输入的语句进行语义解析->推断用户最可能的意图->调用对应的知识库、应用、计算引擎->返回结果给用户。
1、最初级的实现方法:关键词匹配
建一个关键词词库,对用户输入的语句进行关键词匹配,然后调用对应的知识库。
此种方式入门门槛很低,基本上是个程序员都能实现,例如现在微信公众平台的智能回复、诸多网站的敏感词过滤就是此类。
但此种方式存在诸多问题,例如:
a、由于是关键词匹配,如果用户输入的语句中出现多个关键词,此时由于涉及关键词权重(与知识库的关键词对比)等等问题,此时关键词匹配的方法就不擅长了
b、不存在对用户输入语句语义的理解,导致会出现答非所问的现象。当然在产品上对回答不上的问题就采用卖萌的方式来规避掉。
c、基本上无自学习能力,规则只能完全由人工维护,且规则基本是固定死的。
d、性能、扩展性较差。还是上面的一句话中包含多个关键词的例子,采用普通程序语言来做关键词匹配,性能奇差。即便采用一些文本处理的算法来做(例如Double-array trie tree),也很难满足大规模场景需求。
2、稍微高级点的实现方法:基于搜索引擎、文本挖掘、自然语言处理(NLP)等技术来实现
相对于1的关键词匹配,此种实现方法要解决的核心的问题可以大致理解为:根据一段短文本(例如用户问的一句话)的语义,推测出用户最可能的意图,然后从海量知识库内容中找出相似度最高的结果。
具体技术实现就不细说了。举一个很粗糙的例子来简单说一下此种实现方法处理的思路(不严谨,只是为了说明思路)。
假如用户问:北京后天的温度是多少度?
如果采用纯搜索引擎的思路(基于文本挖掘、NLP的思路不尽相同,但可参考此思路),此时实际流程上分成几步处理:
1、对输入语句分词,得到北京、后天、温度3个关键词。分词时候利用了预先建好的行业词库,“北京”符合预先建好的城市库、“后天”符合日期库、“温度”符合气象库
2、将上述分词结果与规则库按照一定算法做匹配,得出匹配度最高的规则。假定在规则库中有一条天气的规则:城市库+日期库+气象库,从而大致可以推测用户可能想问某个地方某天的天气。
3、对语义做具体解析,知道城市是北京,日期是后天,要获取的知识是天气预报
4、调用第三方的天气接口,例如中国天气网-专业天气预报、气象服务门户 的数据
5、将结果返回给用户
以上例子其实很粗糙,实际上还有诸多问题没提到:语义上下文、语义规则的优先级等等。
例如用户上一句问:北京后天的温度是多少度?下一句问:后天的空气质量呢?这里实际上还涉及语义上下文、用户历史喜好数据等等诸多问题。
此种处理方法存在的最大问题:规则库还主要依赖于人工的建立,虽然有一定的学习能力,但自我学习能力还是较弱。可以借助一些训练算法来完善规则,但效果并不是很好。而这也是目前流行的深度挖掘技术所擅长的。
3、当下时髦且高级的玩法:基于深度挖掘、大数据技术来实现
这是cornata、google now等后端的支撑技术,至于小冰,感觉应该是以2为主+部分领域知识的深度挖掘。
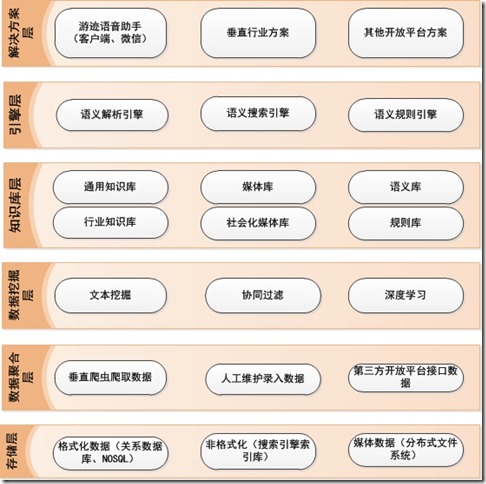
下图是自己做的产品的架构图,供参考: