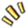最近,ChatGPT 几乎刷屏国内外各大社交媒体,它流畅对答、写剧本、写代码等各项功能令人惊奇,许多技术人也不断深究其强大的背后原理,本文作者就是其中之一。
原文链接:https://www.jonstokes.com/p/chatgpt-explained-a-guide-for-normies
未经授权,禁止转载!
作者 | Jon Stokes
译者 | 弯月 责编 | 郑丽媛
出品 | CSDN(ID:CSDNnews)
最近,很多非常聪明、精通技术的人都在讨论 ChatGPT,但我感觉他们都没有说到点上,他们对这款机器人的核心组件以及各个部分如何协同工作,并没有透彻理解。
需要说明的是,我并不是说自己了解 ChatGPT 的一切。我和其他人一样,包括活跃的机器学习研究人员,仍在学习和思考中。
我希望通过本文说明一下自己的理解,帮助其他“落伍”的人。


机器学习:基础知识
ChatGPT 的核心是生成式机器学习模型家族的大型语言模型。这个系列还包括 Stable Diffusion 以及所有其他提示驱动的文本模型,现在每天新闻讨论的都是这些模型。
简单来说,生成式模型是一种函数,它可以将结构化的符号集合作为输入,并生成相关的结构化符号集合作为输出。
下面是结构化符号集合的一些示例:
单词中的字母
句子中的单词
图像中的像素
视频中的帧
将一个符号集合转换为另一个相关符号集合的方法有很多种,这些方法并不限于计算机程序。你可以编写一个使用规则和查找表的计算机程序,就像 60 年代的聊天机器人。

概念介绍:确定性与随机性
在讨论关系之前,我们先来介绍两个概念,它们将在本文中反复出现:
确定性:确定的过程指的是,在输入既定的情况下,必然能得到相同的输出。
随机性:随机过程指的是,在输入既定的情况下,得到的输出有一定随机性,即有时得出这样的输出,有时则会得出其他输出。
例如,糖果机就是确定性的,投入一块钱,转动手柄,每次都能拿到一块糖。也就是说,一块钱=一块糖,永远不变。
但从另一个角度来看,糖果机也是随机的,投入一块钱,转动手柄,每次都能拿到一块糖,但这块糖的颜色基本上是随机的,且每种颜色的概率取决于机器内部不同颜色的比例。五台不同的糖果机,五种不同的颜色比例,就会有五种不同的颜色输出概率分布。
暂时抛开这些关键概念,下面我们来说一说为什么关系很难。

关系很重要
符号集合可以按照不同的方式关联在一起,关系越抽象越微妙,我们就需要投入越多技术来解决需要捕捉这种关系的问题。
1. 假设我们将集合 {cat} 与 {at-cay} 关联在一起,这是一个标准的“猪拉丁”转换(Pig Latin,一种英语语言游戏,形式是在英语上加上一点规则使发音改变,小孩子经常通过这种游戏秘密交流),我可以用一个简单的手写规则集来管理这种关系。
2. 假设我们将集合 {cat} 与 {dog} 关联在一起,那么这两个集合可以在多个抽象级别上关联。
作为有序的符号集合(序列),二者都有三个符号。
作为三个符号的序列,二者都是单词。
作为单词,二者都指代生物有机体。
作为有机体,二者都是哺乳动物。
作为哺乳动物,二者都是家养宠物。
等等。
3. 假设我们将集合 {the cat is alive} 与 {the cat is dead} 关联在一起,那么就可以使用更多、甚至更高阶的概念来比较和对比这两个符号序列。
所有与猫相关的概念都可以考虑,所有“活着”与“死”相关的概念也在考虑范围内。
在另一个层面上,许多读者会发现我们可以称之为对薛定谔猫的互文引用。
4. 我们再添加一种关系,{the cat is immature} 与 {the cat is mature}。那么此处,我们讨论的是身体发育阶段还是情感发展状态?
因为它是一只猫,“immature”(不成熟)的意思就是“年轻”、“孩子”等。
如果句子的主语是人,那么这个句子更有可能讨论的是适龄行为的一些情感概念。
在阅读上述内容时,你可以想象,随着列表项从 1 到 4,符号之间的可能关系会出现爆炸式增长。随着可能关系数量的增加,关系本身的抽象性、复杂性和微妙性方面也在加剧。
上述,不同的关系采用不同类别的符号存储和检索(从纸笔到数据中心),以有用的方式捕获和编码。
对于第 1 个关系,我们只需在一张纸上画出简单地“猪拉丁”关系,任何人看了这张图,就可以将英语单词转换为“猪拉丁”。但是到第 4 个例子的时候,我们就会思考一个问题:为什么机器学习会需要价值几千万美元的资源?
1. 我们发现这两个集合之间可能存在的关系就像一个小宇宙。这是一个令人眼花缭乱、紧密相连的概念网络,从简单的物理特征到生物分类学,再到身体和情感发展的微妙概念,一直沿着抽象阶梯向上延伸。
2. 一些更抽象的可能关系出现的可能性更大。因此,我们就需要考虑概率元素。
正如我在例子中所说,如果我谈论的是一只猫,那么成熟和不成熟更有可能是与身体发育相关的一组概念,而不太可能围绕情感或智力发育。
对于上述第 2 条中提到的概念,“不太可能”并不意味着不可能,特别是如果我们拓宽背景。例如,我们添加一些额外的词:
{Regarding the cat in the hat: the cat is mature.}
{Regarding the cat in the hat: the cat is immature.}
突然间,所有的可能性都发生了变化。此处,成熟和不成熟代表的含义可能就是另一个领域。
概括:
当符号集合之间的关系简单且确定时,你不需要太多存储或计算能力即可将一个集合与另一个集合关联起来。
当符号集合之间的关系复杂且随机时,将一个集合与另一个集合相关联,就需要投入更多的存储和计算能力,从而以更丰富、更复杂的方式关联这些集合。

概念介绍:概率分布
高中的化学曾介绍过一个概念,有助于我们思考生成式 AI:原子轨道。
原子轨道指的是电子在原子核外空间出现机率较大的区域。不同能级的电子具有不同形状的轨道,这意味着它们可能会出现在不同的区域。
下图是氢原子的轨道:
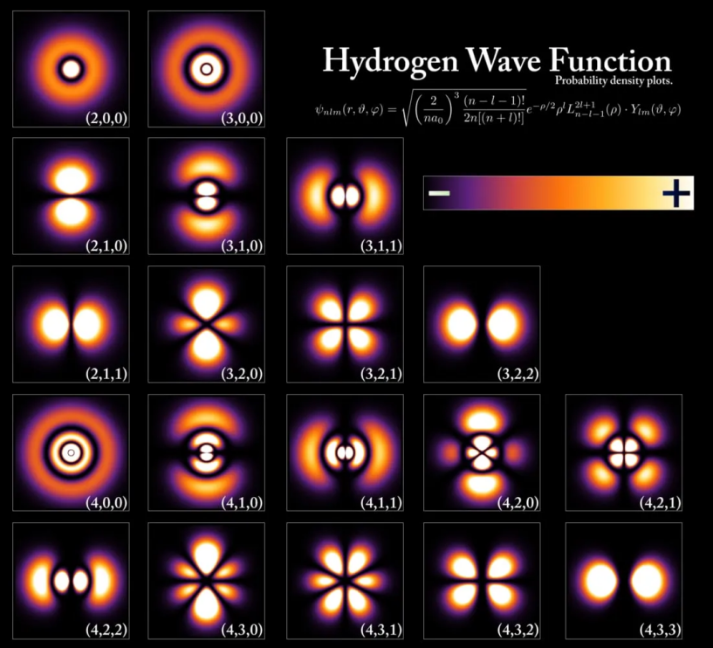
我们单独挑出一个来看看:

对于上图中的轨道,如果你用比电子更小的东西戳原子,区域越亮,你戳到电子的几率就越高。对于图片中的黑色区域,并不意味着找到电子的概率为零,只是说这个区域出现电子的概率低到几乎为零。
这些轨道是概率分布,它们具有特定的形状,上图中的轨道像四个花瓣,所以如果你观察这四个区域之一的一个点,则更有可能发现一个电子,而黑色区域则相反。
以上就是你需要了解的量子化学知识,也是暂时你需要了解的所有背景知识。下面,我们来谈一谈 ChatGPT。

ChatGPT 不了解任何真相,也没有任何观点
你可以想象,对于 ChatGPT 这样的模型,模型可能生成的每个可能文本块(从几个乱七八糟的单词到整篇连贯的文章)都是概率分布中的一个点,就像以上我们讨论的氢原子轨道中电子的分布位置。
当你在 ChatGPT 的输入框输入一组单词时,例如:“Tell me about the state of a cat in a box with a flask of poison and a bit of radioactive material”,你可以把点击“提交”按钮的动作想象成进行一次观察,这会引发波函数坍缩,并得出一个符号集合(只是许多可能的集合的一个)。
有些读者可能会意识到,文本到文本的大型语言模型,实际上是在概率空间中找到一个单词,并将它们串在一起形成句子。不过,在这个抽象层次上,“潜在空间指的是模型可能输出的所有单词的多维空间”与“潜在空间指的是可能输出的所有单词序列的多维空间”之间有一定的区别。为了方便读者理解,并最大程度地降低复杂性,此处我们采用后一个定义。
有时,文本提示输入会将你带到概率分布中的一个点,其对应的集合为 {The cat is alive},而有的时候,你会到达不同的点,比如对应于 {The cat is dead}。
请注意,上述输入符号也有可能会将你带到模型的潜在空间中的一个点,其对应的集合为 {ph'nglui mglw'nafh Cthulhu R'lyeh wgah'nagl fhtagn},尽管这种可能性几乎为零。这一切都取决于文本输入戳中的概率分布的形状,以及计算机的随机数生成器。
重点在于,在这个例子中,我们经常说语言模型“知道”猫的状态(生或者死),但其实这并不重要。模型内部是否对猫有一定的了解,以及对其环境有不同的掌握,这些其实也是次要的。
更好的方式是从这个角度理解:
在模型可能产生的所有符号集合的空间中(从胡言乱语的集合到莎士比亚的文集),模型概率分布中某些区域包含的符号集合,我们人类理解为 the cat is alive。在同一个概率空间中还有一些相邻区域包含的符号集合,我们人类理解为 The cat is dead。
以下是我们可能会在 ChatGPT 的潜在空间中遇到的一些与猫相关的符号集合,即可能的输出空间:
{The cat roused herself from slumber and blinked her eyes.}
{The soft breathing of the sleeping cat greeted Schrödinger as he opened the box.}
{Ja mon, de cat him dead.}
{“I’ve killed my favorite cat!” screamed Schrödinger as he pulled his pet’s lifeless corpse from the box.}
{Patches watched the scene from above, his astral cat form floating near the ceiling as his master lifted his lifeless body from the box and wept.}
当你用不同的输入集合戳模型时,遇到有些输出集合的概率可能更高,但理论上所有输出集合都有可能遇到。
因此,虽然你和我都围绕某个事实与 ChatGPT 进行交互时,例如,孟加拉虎是否濒临灭绝,我们不应该认为 ChatGPT 是拥有一些个人经历的实体,或者认为 ChatGPT 掌握了一些关于孟加拉虎的事实,即便它告诉你和我两个人的信息有一些矛盾,也不能认为它对其中一个人撒谎。
相反,我们应该认为,通过我的文本提示,我观察到了概率分布中的一个点,这个概率分布对应于关于孟加拉虎的一组事实和概念,而你也做了相同的事情。我们两个得到了不同的单词序列,而且这些单词序列似乎代表不同的事实,例如它告诉我这种老虎濒临灭绝,但告诉你这种老虎非常普通,这是因为我们两个戳中了概率分布中不同的波瓣,并在不同波瓣中找到了不同的点。
我戳中的概率分布中波瓣包含的单词序列,按照人类的理解,意思是孟加拉虎濒临灭绝。
你戳中的概率分布中波瓣包含的单词序列,按照人类的理解,意思是孟加拉虎数量过剩。
那么,我们应该如何解决这个问题呢?
考虑到实际情况是,孟加拉虎确实濒临灭绝,我们需要去掉概率分布中你戳中的那个波瓣(即孟加拉虎数量过剩),或者至少降低这个概率。

幻觉:特性还是错误?
当大型语言模型输出的单词序列不符合现实真相时,我们说该模型是产生了“幻觉”。
目前,我们有一套方法可以帮助我们塑造大型语言模型输出的概率分布,也就是说让一些区域变得更小或密度更低,而一些区域变得更大或更密集:
1.训练
2.微调
3.带有人类反馈的强化学习 (RLHF)
我们可以在高质量的数据上训练一个基础模型。所谓的高质量数据指的是符号集合,我们作为人类观察者认为这些数据有意义,而且是符合世界真相的符号集合。通过这种方式,经过训练的模型就像一个原子,其轨道的形状也符合我们的认知。
接下来,我们尝试一下这个模型,找出我们不希望在观察过程中在输出空间中遇到的区域,然后我们使用更有针对性、精心设计的训练数据对模型进行微调。这种微调会缩小一部分波瓣,并扩大一部分波瓣,同时我们希望在多次微调波瓣的形状之后,这个波函数一次又一次的缩小能够得到更加令我们满意的输出。
最后,我们利用带有人类反馈的强化学习,引入一些人为因素来帮助我们调整模型概率空间的形状,使其尽可能紧密地覆盖所有可能输出空间中对应于世界“真相”的点,同时不覆盖“虚假”事物相对应的点。正确完成这一步的工作后,模型概率空间的所有观察对我们来说都是“真相”点。
关于本节中的内容,我个人主要有两个问题:
1. 我们一直提到的这个“观察者”是谁,是负责解释模型的输出并判断对错的人?他们是聪明还是愚蠢?他们真的对真相感兴趣,还是说他们只是想塑造这个模型的概率分布来达到自己的目的?
2. 如果我有幸成为决定模型输出是否真实的观察者,我真的只想要真相吗?如果我想让模型讲一个关于独角兽的睡前故事,我会希望它模仿某位著名的主持人给我讲故事吗?一般来说模型的创造能力是一个特性,而不是非黑即白,不是吗?
这些问题是“幻觉”问题的核心,但这些不是技术问题,而是语言、解释学、政治的哲学,最重要的是:这是一个权力的问题。

ChatGPT 完全不了解你
与 ChatGPT 的交互体验非常强大,但实际上它只是一个 UI,就像计算器应用程序看起来像一个小型物理计算器一样。
虽然你以为模型在设法了解你,就像你了解它一样,随着对话的发展,你俩都在不断加深对彼此的了解。但实际情况并非如此。
你需要彻底摆脱自己正在与 ChatGPT 交谈的想法,为此你需要掌握的最后一个概念:令牌窗口。
ChatGPT 之前的语言模型
对于本文介绍的普通语言模型,你为模型提供一组输入,它执行概率操作,然后提供输出。输入会进入模型的令牌窗口。
这里的“令牌”指的就是本文一直在谈论的“符号”。我想尽量避免使用专业术语,所以才说“符号”,但实际上模型接收和输出的都是令牌。
“窗口”是模型可以接收并转化为一系列输出的令牌数量。
因此,当我使用 ChatGPT 之前的大型语言模型时,我将令牌放入令牌窗口,然后模型返回潜在空间中的一个点,而该点位于我放入的令牌附近。
关键在于,概率空间不会因我放入窗口的令牌而改变形状。当与我交互的窗口从一个变成另一个时,模型的权重保持不变,即模型不记得前一个窗口的内容。
你可以这样认为:每次我将令牌放入模型的窗口并点击“提交”时,就好像我在大街上撞见了模型,并第一次与它交谈,它不会记录任何有关与我交互的历史或信息。
还有一个不太完美的类比:每次我将特定提示和种子输入 Stable Diffusion,都会得到相同的图片。每个提示和种子的组合都会将我带到特定图像所在潜在空间中的一个点,如果我继续给它相同的输入,那么最后仍将获得相同的输出。我没有与模型建立任何共享的历史记录,而 Stable Diffusion 也没有“学习”任何关于我的信息。
最终结果是,模型经过训练后,唯一可获得的信息仅限于我放入令牌窗口的内容。如果我在令牌窗口中输入一个包含我婚姻状况的单词序列,那么模型会获取这些序列,并返回潜在空间中与输入序列相邻的一个点,而这个点代表与我在令牌窗口中给它的事实相关的信息。

伪造个性是 ChatGPT 一个很酷的技能
ChatGPT 是一个具有很大的令牌窗口的大型语言模型,它的使用体验更具交互性,让用户感觉就像真正的对话一样。
下面,我们来实际试试看 ChatGPT 的 UI,假设我打开了浏览器,启动了一个 ChatGPT 会话,如下所示:
Me: What’s up, man.(你好,最近怎么样?)
ChatGPT: Not much. What’s up with you?(还那样。你怎么样?)
Me: Eh, my cat just died in a lab accident.(唉,我的猫刚死于一次实验室事故。)
ChatGPT: I’m very sorry to hear that.(听到这个消息我感到非常遗憾。)
Me: Yeah, it sucks. I’ve already picked out a dog at the shelter, though. I pick him up this afternoon. (是的,我感觉很糟糕。不过,我已经从收养所挑选了一只狗。今天下午我就去接他。)
ChatGPT: That’s exciting! I’m sure your new dog will be a as good a companion for you as your now deceased cat.(太好啦!我相信你的狗会像已故的猫一样成为你的好伴侣。)
我们将这个此会话分解为多个令牌窗口,然后输入到模型中:
令牌窗口 1:
{What's up, man.}(你好,最近怎么样?)
输出1:
{Not much. What’s up with you?}(还那样。你怎么样?)
令牌窗口 2:
{Me: What’s up, man. (你好,最近怎么样?)
ChatGPT: Not much. What’s up with you?(还那样。你怎么样?)
Me: Eh, my cat just died in a lab accident.} (唉,我的猫刚死于一次实验室事故。)
输出2:
{I'm very sorry to hear that.} (听到这个消息我感到非常遗憾。)
令牌窗口 3:
{Me: What’s up, man. (你好,最近怎么样?)
ChatGPT: Not much. What’s up with you? (还那样。你怎么样?)
Me: Eh, my cat just died in a lab accident. (唉,我的猫刚死于一次实验室事故。)
ChatGPT: I’m very sorry to hear that. (听到这个消息我感到非常遗憾。)
Me: Yeah, it sucks. I’ve already picked out a dog at the shelter, though.} (是的,我感觉很糟糕。不过,我已经挑选了收养所的一只狗。今天下午我就去接他。)
输出3:
{That’s exciting! I’m sure your new dog will be a as good a companion for you as your now deceased cat.} (太好啦!我相信你的狗会像已故的猫一样成为你的好伴侣。)
看到了吗?OpenAI 不断将每次谈话的输出附加到现有输出,这样令牌窗口的内容就会随着谈话的进行而不断增加。
每次我点击“发送”时,OpenAI 不仅将我的最新输入提交给模型,还会将会话中所有之前的谈话内容都添加到令牌窗口,这样模型就可以获取整个“聊天记录”,并将我引向其概率空间中正确的波瓣。
换句话说,随着我与 ChatGPT 会话的进行,我为这个模型提供的“文本提示”越来越长,信息也越来越丰富。因此,在第三次交流中,ChatGPT “知道”我的猫已经死了,并且能够做出恰当的回应,正是因为 OpenAI 一直在秘密地将我们的整个“聊天”历史记录放入每个新的令牌窗口中。
但除了我们的聊天记录之外,这个模型不可能“知道”关于我的任何事情。所以说,令牌窗口是一种共享的、可变的状态,模型和我一起不断修改它,其中的内容是模型为了回复我而用于查找相关单词序列的一切。
总结一下:
模型的权重在正常使用期间不可变,这个权重决定了上述概率分布,并代表了模型“知道”的关于这个世界的一切。
我可以向模型输入新的“事实”,也就是我输入到令牌窗口的信息,模型据此生产新的输出。
如果你掌握了以上所有内容,就会明白即将推出的 OpenAI 模型版本中的 32K-token 窗口非常重要。这个令牌窗口足以让模型加载新的事实,例如客服历史记录、书籍章节或脚本、动作序列以及许多其他内容。
随着令牌窗口越来越大,预训练模型可以即时“学习”更多东西,因此也能解锁更多全新的 AI 功能。

☞香港科技大学:期中报告使用 ChatGPT 可加分;爆谷歌、微软已在韩国开始裁员;美国最大加密货币银行宣布关闭|极客头条
☞烧数亿美元、耗上万颗英伟达 GPU,微软揭秘构建 ChatGPT 背后超级计算机往事 !
☞各家的“ChatGPT”什么时候能取代程序员?CSDN AI编程榜发布