ShaderJoy —— 如何判别直线是否和二次贝塞尔曲线相交【GLSL】

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/2164.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

第十二章:算法与程序设计
文章目录:
一:基本概念
1.算法与程序
1.1 算法
1.2 程序
2.编译预处理
3.面向对象技术
4.程序设计方法
5.SOP标志作业流程
6.工具
6.1 自然语言
6.2 流程图
6.3 N/S图
6.4 伪代码
6.5 计算机语言
二:程序设计 基础
1.常数
…

【BLE】CC2541之ADC
本文最后修改时间:2022年04月12日 23:00 一、本节简介
本文介绍如何通过P05口采集电压值。 二、实验平台
1)CC2541平台
①协议栈版本:BLE-CC254x-1.4.0
②编译软件:IAR 10.20.1
③硬件平台:香瓜CC2541开发板、USB…

SpeingMVC框架(三)
目录
五、响应数据与结果视图
1、返回值分类
2、springmvc的请求转发和重定向 六、异常处理
1、处理思路
2、自定义异常处理器 七、springmvc中的拦截器
1、拦截器概述
2、自定义拦截器步骤 五、响应数据与结果视图
1、返回值分类
返回String:Controller方…
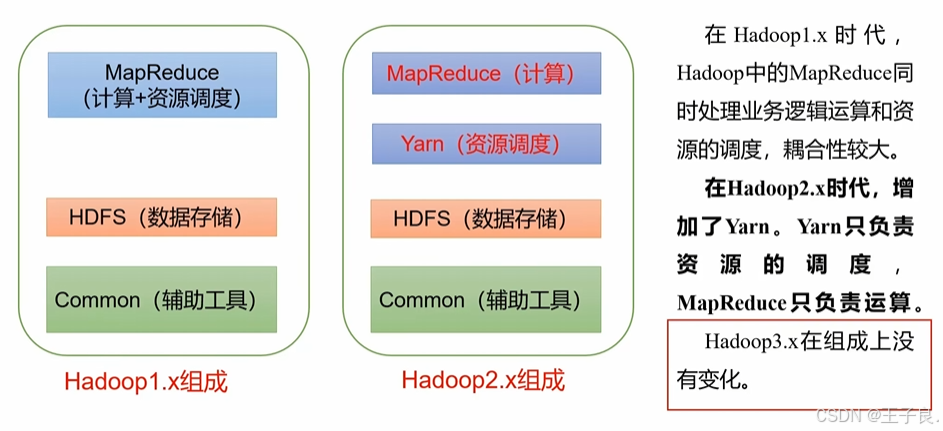
Hadoop3.x 万字解析,从入门到剖析源码
💖 欢迎来到我的博客! 非常高兴能在这里与您相遇。在这里,您不仅能获得有趣的技术分享,还能感受到轻松愉快的氛围。无论您是编程新手,还是资深开发者,都能在这里找到属于您的知识宝藏,学习和成长…

【Vue】分享一个快速入门的前端框架以及如何搭建
先上效果图: 登录
菜单: 下载地址: 链接:https://pan.baidu.com/s/1m-ZlBARWU6_2n8jZil_RAQ 提取码:ui20 …
主要是可以自定义设置token,更改后端请求地址较为方便。
应用设置: 登录与token设置: 在这里设置不用登录,可以请求的接口: request.js i…

汽车免拆诊断案例 | 2007 款法拉利 599 GTB 车发动机故障灯异常点亮
故障现象
一辆2007款法拉利599 GTB车,搭载6.0 L V12自然吸气发动机(图1),累计行驶里程约为6万km。该车因发动机故障灯异常点亮进厂检修。 图1 发动机的布置 故障诊断
接车后试车,发动机怠速轻微抖动,…

Emacs 折腾日记(九)——elisp 数组与序列
elisp 中序列是数组和列表的统称,序列的共性是内部数据有一个先后的顺序,它与C/C 中有序列表类似。
elisp 中的数组包括向量、字符串、char-table 和布尔向量,它们的关系如下:
在之前一章中已经介绍了序列中的一种类型——列表,…

Mac玩Steam游戏秘籍!
Mac玩Steam游戏秘籍! 大家好!最近有不少朋友在用MacBook玩Steam游戏时遇到不支持mac的问题。别担心,我来教你如何用第三方工具Crossover来畅玩这些不支持的游戏,简单又实用! 第一步:下载Crossover 首先&…

初识算法和数据结构P1:保姆级图文详解
文章目录 前言1、算法例子1.1、查字典(二分查找算法)1.2、整理扑克(插入排序算法)1.3、货币找零(贪心算法) 2、算法与数据结构2.1、算法定义2.2、数据结构定义2.3、数据结构与算法的关系2.4、独立于编程语言…

Oracle 使用dbms_stats.gather_table_stats来进行表analyse,收集表统计信息
目录 一. 介绍二. 参数说明三. 简易封装四. 效果 一. 介绍
DBMS_STATS.GATHER_TABLE_STATS 用于收集 表 级别的统计信息。这些统计信息有助于查询优化器优化查询计划,影响与表本身相关的查询性能。 Oracle 查询优化器会根据表的统计信息来选择最优的执行计划。当运…

apache-skywalking-apm-10.1.0使用
apache-skywalking-apm-10.1.0使用
本文主要介绍如何使用apache-skywalking-apm-10.1.0,同时配合elasticsearch-8.17.0-windows-x86_64来作为存储 es持久化数据使用。
步骤如下:
一、下载elasticsearch-8.17.0-windows-x86_64
1、下载ES(elasticsear…

Flink系统知识讲解之:容错与State状态管理
Flink系统知识之:容错与State状态管理
状态在Flink中叫作State,用来保存中间计算结果或者缓存数据。根据是否需要保存中间结果,分为无状态计算和有状态计算。对于流计算而言,事件持续不断地产生,如果每次计算都是相互…

Python线性混合效应回归LMER分析大鼠幼崽体重数据、假设检验可视化|数据分享...
全文链接:https://tecdat.cn/?p38816 在数据分析领域,当数据呈现出层次结构时,传统的一般线性模型(GLM)可能无法充分捕捉数据的特征。混合效应回归作为GLM的扩展,能够有效处理这类具有层次结构的数据&…


【WEB】网络传输中的信息安全 - 加密、签名、数字证书与HTTPS
文章目录 1. 概述2. 网络传输安全2.1.什么是中间人攻击2.2. 加密和签名2.2.1.加密算法2.2.2.摘要2.2.3.签名 2.3.数字证书2.3.1.证书的使用2.3.2.根证书2.3.3.证书链 2.4.HTTPS 1. 概述
本篇主要是讲解讲一些安全相关的基本知识(如加密、签名、证书等)&…


uni-app编写微信小程序使用uni-popup搭配uni-popup-dialog组件在ios自动弹出键盘。
uni-popup-dialog 对话框
将 uni-popup 的type属性改为 dialog,并引入对应组件即可使用对话框 ,该组件不支持单独使用
示例
<button click"open">打开弹窗</button>
<uni-popup ref"popup" type"dialog"…

UML系列之Rational Rose笔记九:组件图
一、新建组件图 二、组件图成品展示 三、工作台介绍
最主要的还是这个component组件;
然后还有这几个,正常是用不到的;基本的使用第四部分介绍一下:
四、基本使用示例 这些,主要是运用package还有package specifica…

数据结构《MapSet哈希表》
文章目录 一、搜索树1.1 定义1.2 模拟实现搜索 二、Map2.1 定义2.2 Map.Entry2.3 TreeMap的使用2.4 Map的常用方法 三、Set3.1 定义3.2 TreeSet的使用3.3 Set的常用方法 四、哈希表4.1 哈希表的概念4.2 冲突4.2.1 冲突的概念4.2.2 冲突的避免1. 选择合适的哈希函数2. 负载因子调…

赛灵思(Xilinx)公司Artix-7系列FPGA
苦难从不值得歌颂,在苦难中萃取的坚韧才值得珍视;
痛苦同样不必美化,从痛苦中开掘出希望才是壮举。
没有人是绝对意义的主角,
但每个人又都是自己生活剧本里的英雄。滑雪,是姿态优雅的“贴地飞行”,也有着成…
推荐文章
- Python 3.11 69 个内置函数(完整版)
- #渗透测试#批量漏洞挖掘#CyberPanel面板远程命令执行漏洞(CVE-2024-51567)
- (1)SpringBoot入门+彩蛋
- (十七) Nginx解析:架构设计、负载均衡实战与常见面试问题
- .NET周刊【1月第4期 2025-01-26】
- [250217] x-cmd 发布 v0.5.3:新增 DeepSeek AI 模型支持及飞书/钉钉群机器人 Webhook 管理
- [Collection与数据结构] B树与B+树
- [Echarts]图例换行时icon对齐标题
- [HelloCTF]PHPinclude-labs超详细WP-Level 6Level 7Level 8Level 9-php://协议
- [Java基础-线程篇]7_线程设计模式与总结
- [答疑]这个消息名是写发送数据还是接收数据
- [今年毕业设计]最新最全最有创意的基于云计算的计算机专业毕设选题精选推荐汇总建议收藏!!