Python作为一门流行的编程语言,拥有着庞大的生态系统和丰富的工具库,为开发者们提供了无限可能。在这篇文章中,我们将介绍21个开发者必备的Python工具,涵盖了开发、调试、测试、性能优化和部署等多个方面。
Python开发工具

Jupyter Notebook
Jupyter Notebook是一种交互式的开发环境,它可以在网页浏览器中编写和运行代码,展示结果,并添加文本说明、图像和其他元素,支持多种编程语言,包括Python、R和Julia等,但最为常见的用途是作为Python编程的工具。Jupyter Notebook可广泛应用于数据分析、数据可视化、机器学习和教育领域。
Pip
Pip是Python的包管理工具,用于安装和管理Python包。它允许用户轻松地安装、卸载、更新和管理Python包和其依赖关系。Pip可以从Python包索引(PyPI)中下载并安装成千上万的第三方包,这些包包括用于各种用途的库、工具和框架。通过Pip,开发人员可以快速方便地将所需的包集成到项目中,从而提高开发效率并且降低重复造轮子的成本。Pip通常随着Python一起安装,因此几乎所有的Python开发环境都可以直接使用它。
pip install <package_name>
VSCode
Visual Studio Code(VSCode)是由微软开发的免费开源的轻量级代码编辑器,它支持多种编程语言,包括Python。VSCode具有丰富的扩展生态系统,用户可以根据自己的需求安装各种插件,以扩展其功能。对于Python开发者来说,VSCode提供了丰富的功能,包括代码补全、调试支持、集成的终端、Git集成等等。它还支持Jupyter Notebook,使得数据科学家和机器学习工程师可以在同一个环境中进行代码编写和实验。由于其灵活性和丰富的功能,VSCode已成为许多开发者的首选编辑器之一。
Python网络爬虫工具

Requests
Requests是一个简单而优雅的Python HTTP库,允许发送HTTP请求并与Web服务进行交互。它提供了一个高级接口,用于发出请求、处理响应以及管理cookie和会话。Requests在诸如网络抓取、API交互和从Web服务中检索数据等任务中被广泛使用。

Beautiful Soup
Beautiful Soup是一个用于解析HTML和XML文档的Python库,它提供了从网页中提取数据的功能。Beautiful Soup 可以帮助开发者快速解析网页内容,提取所需的信息,并以简单直观的方式进行操作。由于其易用性和灵活性,Beautiful Soup 在网络抓取和数据挖掘领域得到了广泛的应用。
Scrapy
Scrapy 是一个基于 Python 的专业网络爬虫框架,用于快速、高效地构建和扩展网络爬虫系统。它提供了强大的功能,包括异步处理、管道处理和数据存储。Scrapy 还具有灵活的架构,可以轻松处理网页解析、数据提取和爬取规则的定义。由于其功能强大且易于扩展的特点,Scrapy 成为许多开发者在进行复杂网络爬取任务时的首选框架。

Python Web开发工具
Python的Web开发框架是一系列工具和库的集合,它们帮助开发人员构建Web应用程序和网站。这些框架提供了许多功能,如路由处理、模板渲染、数据库集成、表单处理等,使得开发人员能够以更高效的方式构建功能强大的Web应用。

Flask
Flask 是一个轻量级的 Python Web 开发框架,具有简单而灵活的设计。它提供了基本的工具和库,使得开发者能够快速构建 Web 应用程序。Flask 不会强加太多约束,因此开发者可以根据自己的需求选择适合的扩展来构建应用。Flask被广泛应用于构建小型至中型的 Web 应用,以及构建 RESTful API。

Streamlit
Streamlit是一个用于数据应用快速开发的Python库,它可以让用户使用简单的Python脚本来创建交互式的Web应用。通过Streamlit,用户可以轻松地将数据科学和机器学习模型转化为具有用户界面的应用程序,无需深入了解前端开发知识。

FastAPI
FastAPI 是一个现代的、高性能的 Python Web 框架,专门用于构建 API。它基于 Python 3.7+ 的标准类型提示,支持自动化的交互式文档生成,以及对数据验证和输入/输出的自动化处理。FastAPI 提供了快速、高效的性能,并且易于使用。它是构建 Web API 的首选框架之一,特别适用于构建高性能的后端服务。

Python数据分析工具

pandas
pandas 是一个开源的数据分析工具,提供了快速、强大、灵活和易于使用的数据结构,使得数据处理和分析变得更加简单和直观。它主要提供了两种数据结构:Series和 DataFrame,并且支持各种数据操作和处理,如数据清洗、转换、合并、切片、索引等,是Python数据分析领域中不可或缺的工具之一。

Numpy
NumPy是Python中用于科学计算的一个重要库,它提供了多维数组对象以及用于数组操作的大量函数,还提供了广播功能、整合 C/C++/Fortran 代码的工具,以及线性代数、随机数生成等功能,广泛应用于数据分析、机器学习和科学计算等领域。

SQLAlchemy
SQLAlchemy是一个用于Python的SQL工具和对象关系映射(ORM)库,它提供了灵活且强大的数据库访问功能,支持多种数据库后端,并允许开发者使用 Python 语言来执行各种数据库操作,包括创建、读取、更新和删除(CRUD)等。同时,SQLAlchemy 还提供了高级的 ORM 功能,可以将数据库表映射为 Python 对象,使得数据操作更加直观和灵活,是Python数据库访问和数据持久化的重要工具。

Dask
Dask 是一个用于并行计算的灵活的并行计算库,它与 Python 的 NumPy 和 Pandas 库兼容,可以用于处理大规模数据集,通过并行化和分布式计算来加速数据处理和分析。它提供了类似于 NumPy 和 Pandas 的数据结构和 API,并且可以在多核 CPU 或分布式计算框架上运行。Dask 的设计使得它可以轻松地扩展到大规模计算集群,适用于需要处理大量数据的数据科学和机器学习任务。

Python数据可视化工具

Matplotlib
Matplotlib 是一个用于创建数据可视化的 Python 库,它提供了丰富的绘图工具和功能,可用于生成各种类型的图表、图形和可视化。Matplotlib 可以创建线图、散点图、柱状图、饼图等多种图表,同时支持自定义图表样式、标签、图例等。作为Python中最流行的数据可视化工具之一,Matplotlib被广泛应用于科学计算、数据分析和报告生成等领域。

Seaborn
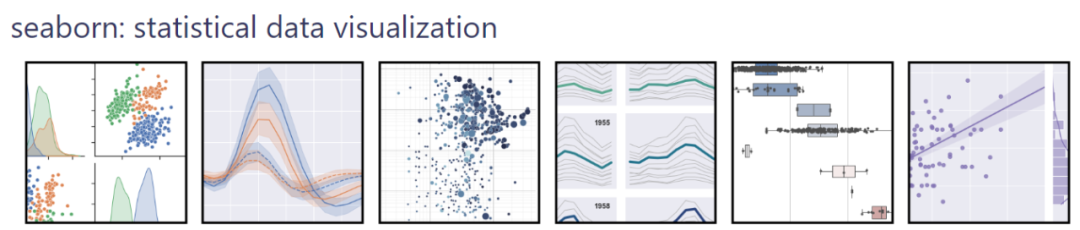
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,旨在创建具有吸引力和信息丰富的统计图形。它简化了创建统计图形的过程,提供了一些高级接口,使得绘图更加简单且美观,同时支持绘制各种统计图形,包括线图、条形图、散点图、箱线图、热力图等,可用于数据探索、分析和可视化。Seaborn还提供了对数据集进行可视化分析的功能,使得用户能够快速地了解数据的特征和分布。
Plotly
Plotly是一个用于创建交互式可视化的 Python 图表库,它提供了丰富的图表类型和交互功能,适用于创建各种复杂的图表和数据可视化。通过 Plotly,用户可以创建交互式图表、热图、3D图形、地理地图可视化等,并可以在 Web 应用程序中进行嵌入和展示。Plotly 还允许用户创建动态和实时更新的图表,使得数据的交互式探索变得更加直观和有趣,在数据科学、数据分析和报告展示等领域得到了广泛的应用。

Pandas-profiling
Pandas-Profiling 是一个用于生成数据报告的 Python 库,它能够自动生成关于数据集的详尽统计信息和可视化摘要。通过 Pandas-Profiling,用户可以轻松地了解数据的基本特征、分布、相关性和缺失值等情况,同时生成各种图表和摘要信息,如直方图、散点图、相关矩阵等。这使得数据分析人员能够更快速地对数据集进行初步的探索和理解。Pandas-Profiling 能够帮助用户快速发现数据集的特点和潜在问题,为进一步的数据分析和处理提供了有价值的参考依据。
Python机器学习工具

Scikit-learn
Scikit-learn 是一个用于机器学习和数据挖掘的 Python 库,它提供了简单而高效的工具用于数据挖掘和数据分析。Scikit-learn 包含了多种机器学习算法,包括分类、回归、聚类、降维和模型选择等。此外,它还提供了丰富的功能,如特征提取、特征选择、模型评估和模型优化等。Scikit-learn是数据科学和机器学习领域中不可或缺的工具之一,被广泛应用于实际的数据分析和预测建模中。
Keras
Keras 是一个用于构建人工神经网络的高级神经网络 API,它能够在 TensorFlow、CNTK 或 Theano 等后端上运行。Keras 具有简单、直观的接口,使得用户能够快速构建和实验各种神经网络模型。Keras 支持快速的原型设计和模块化构建,同时提供了丰富的神经网络层和模型组件,使得用户能够轻松地搭建复杂的深度学习模型。
PyTorch
PyTorch 是一个开源的深度学习框架,具有灵活的设计和易用的接口,适用于构建各种深度学习模型。作为一个功能强大且灵活的工具,PyTorch 提供了张量计算和自动微分的功能,可用于构建神经网络模型、进行模型训练和推断。PyTorch 还支持 GPU 加速计算,能够处理大规模的数据和复杂的模型。

Opencv
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,它提供了丰富的图像处理和计算机视觉功能,包括图像处理、特征检测、对象识别、摄像头标定、运动跟踪等。OpenCV 支持多种编程语言,包括 Python、C++ 和 Java 等,因此在不同的平台和系统上都得到了广泛的应用。作为一个功能强大而灵活的计算机视觉库,OpenCV 在图像处理、模式识别、机器学习和深度学习等领域中发挥着重要作用。