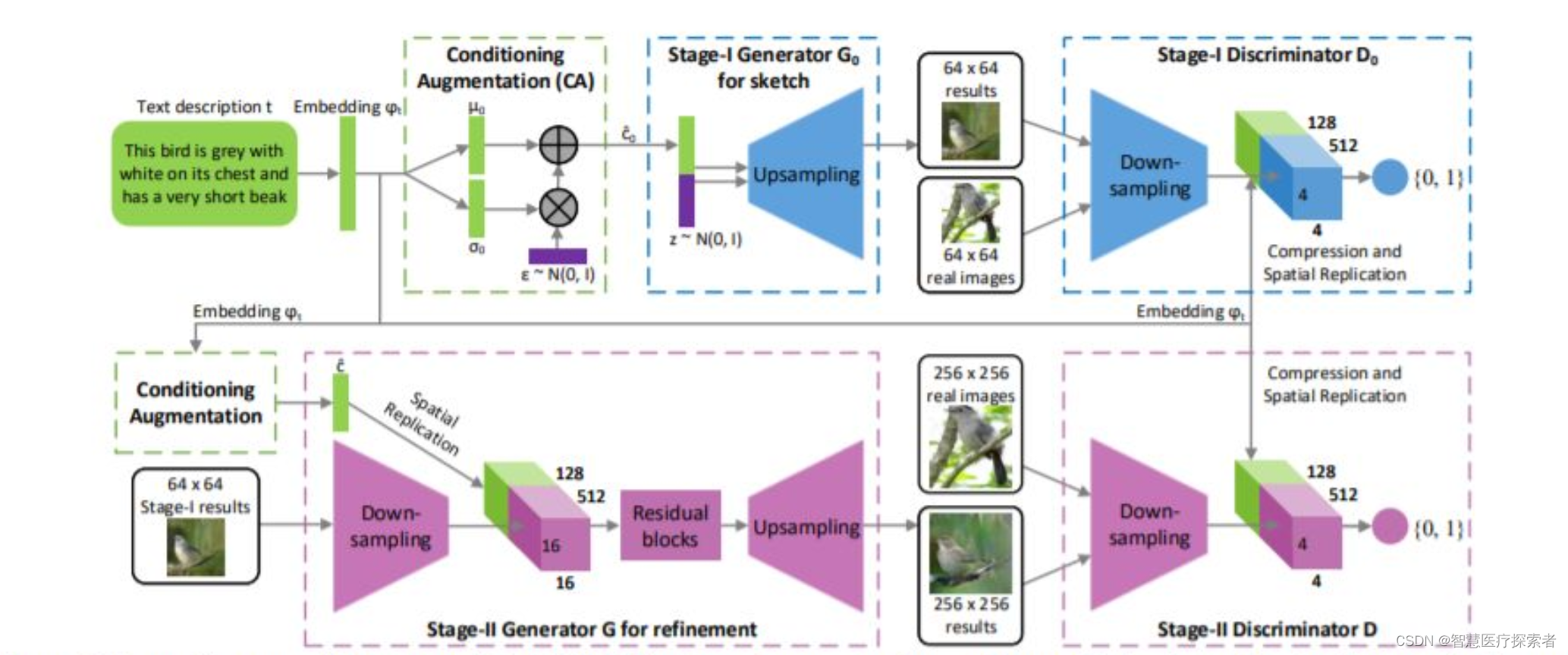
C4.5 信息增益比实现决策树
信息增益比
g R ( D , A ) = g ( D , A ) H ( D ) g_{R}(D, A)=\frac{g(D, A)}{H(D)} gR(D,A)=H(D)g(D,A)
其中, g ( D , A ) g(D,A) g(D,A)是信息增益, H ( D ) H(D) H(D)是数据集 D D D的熵
代码实现
import numpy as npdef calculate_entropy(labels):# 计算标签的熵_, counts = np.unique(labels, return_counts=True)probabilities = counts / len(labels)entropy = -np.sum(probabilities * np.log2(probabilities))return entropydef calculate_information_gain(data, labels, feature_index, threshold):# 根据给定的特征和阈值划分数据left_mask = data[:, feature_index] <= thresholdright_mask = data[:, feature_index] > thresholdleft_labels = labels[left_mask]right_labels = labels[right_mask]# 计算左右子集的熵left_entropy = calculate_entropy(left_labels)right_entropy = calculate_entropy(right_labels)# 计算信息增益total_entropy = calculate_entropy(labels)left_weight = len(left_labels) / len(labels)right_weight = len(right_labels) / len(labels)information_gain = total_entropy - (left_weight * left_entropy + right_weight * right_entropy)return information_gaindef find_best_split(data, labels):num_features = data.shape[1]best_info_gain = 0best_feature_index = -1best_threshold = Nonefor feature_index in range(num_features):feature_values = data[:, feature_index]unique_values = np.unique(feature_values)for threshold in unique_values:info_gain = calculate_information_gain(data, labels, feature_index, threshold)if info_gain > best_info_gain:best_info_gain = info_gainbest_feature_index = feature_indexbest_threshold = thresholdreturn best_feature_index, best_thresholddef create_decision_tree(data, labels):# 基本情况:如果所有标签都相同,则返回一个叶节点,其中包含该标签if len(np.unique(labels)) == 1:return {'label': labels[0]}# 找到最佳的划分特征best_feature_index, best_threshold = find_best_split(data, labels)# 创建一个新的内部节点,其中包含最佳特征和阈值node = {'feature_index': best_feature_index,'threshold': best_threshold,'left': None,'right': None}# 根据最佳特征和阈值划分数据left_mask = data[:, best_feature_index] <= best_thresholdright_mask = data[:, best_feature_index] > best_thresholdleft_data = data[left_mask]left_labels = labels[left_mask]right_data = data[right_mask]right_labels = labels[right_mask]# 递归创建左右子树node['left'] = create_decision_tree(left_data, left_labels)node['right'] = create_decision_tree(right_data, right_labels)return nodedef predict(node, sample):if 'label' in node:return node['label']feature_value = sample[node['feature_index']]if feature_value <= node['threshold']:return predict(node['left'], sample)else:return predict(node['right'], sample)# 示例数据集
data = np.array([[1, 2, 0],[1, 2, 1],[1, 3, 1],[2, 3, 1],[2, 3, 0],[2, 2, 0],[1, 1, 0],[1, 1, 1],[2, 1, 1],[1, 3, 0]
])labels = np.array([0, 1, 1, 1, 0, 0, 0, 1, 1, 1])# 创建决策树
decision_tree = create_decision_tree(data, labels)# 测试数据
test_data = np.array([[1, 2, 0],[2, 1, 1],[1, 3, 1],[2, 3, 0]
])# 预测结果
for sample in test_data:prediction = predict(decision_tree, sample)print(f"样本: {sample}, 预测标签: {prediction}")