一、树介绍
1、定义
树形结构是一种层级式的数据结构,由顶点(节点)和连接它们的边组成。 树类似于图,但区分树和图的重要特征是树中不存在环路。树有以下特点:
(1)每个节点有零个或多个子节点;
(2)没有父节点的节点称为根节点;
(3)每一个非根结点有且只有一个父节点;
(4)除了根结点外,每个子节点可以分为多个不相交的子树;
2、优缺点及使用场景
优点:清晰的层级关系,快速查找,动态添加、删除和修改节点。
缺点:存在冗余存储,插入和删除的复杂性,高度不平衡等。
适用场景:层次关系、分类和搜索、表达关系和数据可视化等。
3、遍历方法
(1)深度遍历--先序(根-左-右)
(2)深度遍历--中序(左-根-右)
(3)深度遍历--后序(左-右-根)
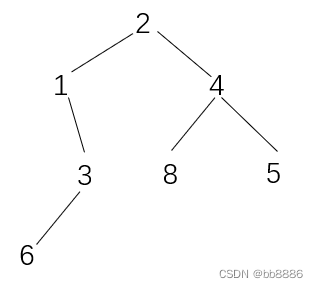
先序:【2, 1, 3, 6, 4, 8, 5】
中序:【1, 6, 3, 2, 8, 4, 5】
后序:【6, 3, 1, 8 ,5, 4, 2】
层序:【2, 1 ,4, 3, 8, 5, 6】
(4)层序遍历--自上而下,自左而右
4、主要类型
(1)二叉树
(a)概念:节点度不超过2的树。
(b)特点
(a)每个结点最多有两颗子结点。
(b)左子树和右子树是有顺序的,次序不能颠倒。
(c)即使某结点只有一个子树,也要区分左右子树。
(c)二叉树类型
① 满二叉树:在满二叉树中,除了叶节点外,每个节点都有两个子节点,且所有叶节点都在同一层级上
② 完全二叉树:完全二叉树是指除了最后一层外,其他层都是满的,并且最后一层的节点从左到右连续存在。
③ 二叉搜索树:二叉搜索树是一种有序的二叉树,对于每个节点,其左子树的值都小于节点的值,右子树的值都大于节点的值。这种有序性质使得二叉搜索树在查找、插入和删除等操作上有很高的效率。
④ 平衡二叉树:平衡二叉树是指任意节点的左子树和右子树的高度差不超过1的二叉树。平衡二叉树可以提高插入、删除和查找等操作的效率,常见的平衡二叉树有AVL树和红黑树。
(2)AVL树
(a)介绍:AVL树是一种自平衡的二叉搜索树,它的名称来自于它的发明者Adelson-Velsky和
Landis。AVL树通过在插入和删除节点时进行旋转操作来保持树的平衡。
(b)平衡调整:在AVL树中,每个节点都带有一个平衡因子(balance factor),它表示节点的左
子树高度与右子树高度之差。平衡因子可以是-1、0或1,如果平衡因子的绝对值大于1,就表示树
失去了平衡,需要进行平衡调整。AVL树的平衡调整通过四种旋转操作来完成。
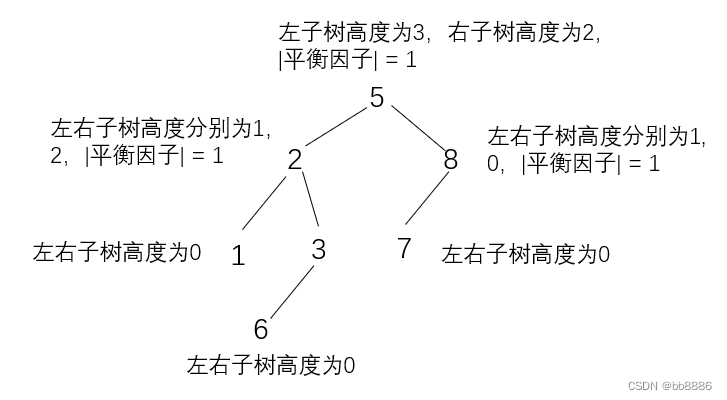
(c)AVL树的特点:
① 平衡性:在AVL树中,任意节点的左子树和右子树的高度差不超过1。
② 严格的排序性:AVL树是一种二叉搜索树,它保持了节点的严格排序性。对于每个节点,左子树中的所有节点都小于该节点,右子树中的所有节点都大于该节点。
(3)红黑树
(a)介绍:红黑树(Red-Black Tree)是一种自平衡的二叉搜索树,它通过对节点进行颜色标记
和旋转操作来保持树的平衡。

(b)红黑树的特点
① 节点颜色:每个节点被标记为红色或黑色。这是红黑树的核心特征之一。
② 平衡性:红黑树通过一些规则来维持平衡性。具体规则如下:
- 根节点是黑色。
- 所有叶节点(NIL节点或空节点)是黑色。
- 如果一个节点是红色,那么它的两个子节点都是黑色。
- 从任意节点到其每个叶子节点的路径上,包含相同数量的黑色节点。
③ 排序性:红黑树是一种二叉搜索树,它保持了节点的严格排序性。对于每个节点,左子树中的所有节点都小于该节点,右子树中的所有节点都大于该节点。
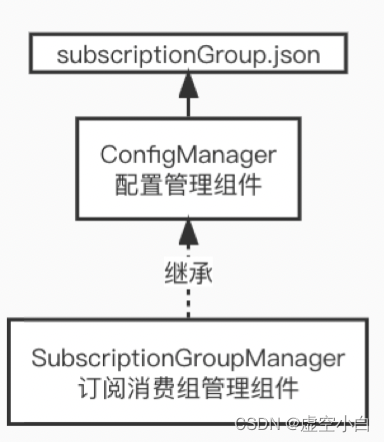
二、面试关于树结构常考算法
1、求二叉树的高度
题目:给定一颗二叉树,求该数的高度,例如,如下二叉树的高度是4。

思路:有两种方法来求解二叉树的高度,一是递归二是迭代。
递归方法通过递归调用求解左子树和右子树的高度,并取较大值加1得到二叉树的高度。
迭代方法使用层序遍历,每遍历完一层,高度加1,直到遍历完所有节点。
#include<iostream>
#include <algorithm>
#include<queue>
using namespace std;
struct BinaryTreeNode
{struct BinaryTreeNode* left;struct BinaryTreeNode* right;int data; BinaryTreeNode(int x): data(x), left(NULL),right(NULL) {}
};// 迭代方法
int FindHeightofTree(BinaryTreeNode* root){if (root == nullptr) {return 0; // 空树高度为0}int count = 0;while(root != NULL){if(root->left || root->right){count += 1;if(root->left){root = root->left;continue;} if(root->right){root = root->right;continue;} } root = NULL;}return count + 1;
}// 递归方法
int getHeight(BinaryTreeNode* root){if (root == nullptr) {return 0; // 空树高度为0}int leftHeight = getHeight(root->left);int rightHeight = getHeight(root->right);return 1 + std::max(leftHeight, rightHeight);
}int main(){BinaryTreeNode* root = new BinaryTreeNode(2);root->left = new BinaryTreeNode(1);root->right = new BinaryTreeNode(4);root->left->right = new BinaryTreeNode(3);root->right->left = new BinaryTreeNode(8);root->left->right->left = new BinaryTreeNode(5);// 递归法int res = FindHeightofTree(root);// 迭代法int res1 = getHeight(root);cout<< res1;cout<< res;// 释放内存,防止内存泄漏delete root->left->right->left;delete root->right->left;delete root->left->right;delete root->left;delete root->right;delete root;
}

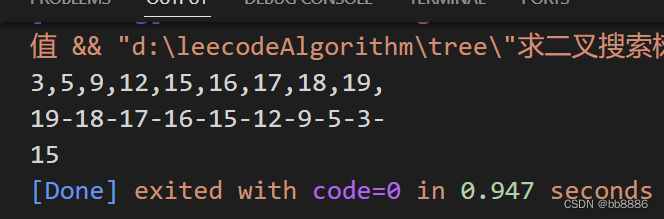
2、在二叉搜索树中查找第K个最大值
题目:如下二叉搜索树,给定k = 5,[19, 18, 17, 16, 15, 12, 9, 5, 3],则下列二叉搜索树中第5个最大值为15。

思路:二叉搜索树(BST)的后序遍历实际是对树节点的升序排列。所以同第一题,有递归法和迭代法实现BST的中序遍历,遍历后再逆序,返回第k个最大值。
迭代法实现中序遍历:使用一个栈来实现迭代法的中序遍历。先遍历树的左子树,如果当前节点存在左子树,则将当前节点压入栈,直到没有左子树,则记录栈顶元素(temp),并弹出。在遍历当前节点(temp)的右子树。
#include<iostream>
#include<vector>
#include<stack>
#include<algorithm>
using namespace std;struct BinaryTreeNode{BinaryTreeNode* left;BinaryTreeNode* right;int val;BinaryTreeNode(int x): val(x), left(NULL), right(NULL){}
};
int getNthMaxFromTree2(BinaryTreeNode* root, int k){vector<int> res;stack<BinaryTreeNode*> s;BinaryTreeNode* temp;//非递归中序遍历while(root != NULL || !s.empty()){if(root){s.push(root);root = root->left;}else{temp = s.top();s.pop();cout << temp->val<<",";res.push_back(temp->val);root = temp->right; }}// 降序sort(res.rbegin(),res.rend());cout << endl;for(auto c: res){cout<< c << "-";}return res[k-1]; }int main(){BinaryTreeNode* root = new BinaryTreeNode(12);root->left = new BinaryTreeNode(5);root->right = new BinaryTreeNode(18);root->left->left = new BinaryTreeNode(3);root->left->right = new BinaryTreeNode(9);root->right->left = new BinaryTreeNode(15);root->right->right = new BinaryTreeNode(19);root->right->left->right = new BinaryTreeNode(17);root->right->left->right->left = new BinaryTreeNode(16);int val = getNthMaxFromTree2(root, 5);cout << endl <<val;// 释放内存,防止内存泄漏delete root->right->left->right->left;delete root->right->left->right;delete root->right->right;delete root->right->left;delete root->left->right;delete root->left->left;delete root->right;delete root->left;delete root;
} 
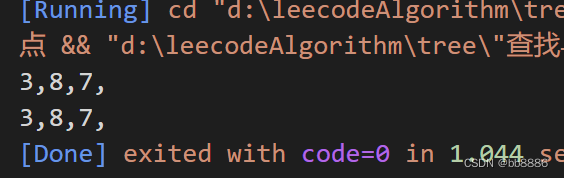
3、查找与根节点距离K的节点
题目:如下二叉树,给定k = 2, 输出与根节点距离2的节点[3, 8, 5]。
思路: 可以使用深度优先搜索(DFS)或广度优先搜索(BFS)来遍历二叉树,并记录每个节点的距离。当找到距离为K的节点时,将其存储起来。
广度优先搜索(BFS)+队列:我们可以在遍历每一层节点时,将该节点的子节点加入队列(size--控制循环),并记录它们的距离。当距离等于K时,将该节点的值存储起来。
深度优先搜索(DFS)+栈:使用一个栈来存储当前节点和距离的信息。在每次循环中,取出栈顶元素,检查当前距离是否等于K,如果是,则将该节点的值存储到结果数组中。然后,将当前节点的子节点按照右子节点先入栈,左子节点后入栈,并将距离加1。这样,我们可以确保在深度优先搜索中,离根节点更远的节点会在栈中先被访问。
#include<iostream>
#include<stack>
#include<queue>
#include<map>using namespace std;
typedef int BTDataType;
struct BinaryTreeNode
{struct BinaryTreeNode* _pLeft;struct BinaryTreeNode* _pRight;BTDataType _data;BinaryTreeNode(int x): _data(x), _pLeft(NULL), _pRight(NULL){}};// 二叉树的广度优先遍历+队列实现(非递归)
vector<int> LevelOrder(BinaryTreeNode* root, int k){queue<BinaryTreeNode*> que; //使用一个队列来存储当前层的节点BinaryTreeNode* temp;int distance;vector<int> res;if(root) que.push(root);while(!que.empty()){// 记录队列中的节点个数int size = que.size();if(distance == k){while(!que.empty()){res.push_back(que.front()->_data);que.pop();}break;}// 用size--控制循环处理当前层的节点(当前层所有节点出队,下层节点入队)while(size--){temp = que.front();que.pop();// cout << temp->_data << ",";if(temp->_pLeft) que.push(temp->_pLeft);if(temp->_pRight) que.push(temp->_pRight);}distance++;
}return res;
}// 二叉树的深度优先遍历(先序)+栈实现(非递归)
vector<int> getKdistanceInOrder(BinaryTreeNode* root, int k){vector<int> res;stack<pair<BinaryTreeNode*, int>> s; //栈用来存储节点和当前距离if(root) s.push({root, 0});while(!s.empty()){BinaryTreeNode* p = s.top().first;int distance = s.top().second;s.pop();if(distance == k) res.push_back(p->_data); //当距离等于K时,将该节点的值存储起来。if(p->_pRight) s.push({p->_pRight, distance + 1});if(p->_pLeft) s.push({p->_pLeft, distance + 1});}return res;
}int main(){BinaryTreeNode* root = new BinaryTreeNode(2);root->_pLeft = new BinaryTreeNode(1);root->_pRight = new BinaryTreeNode(4);root->_pLeft->_pRight = new BinaryTreeNode(3);root->_pRight->_pLeft = new BinaryTreeNode(8);root->_pRight->_pRight = new BinaryTreeNode(7);root->_pLeft->_pRight->_pLeft = new BinaryTreeNode(5);vector<int> res = LevelOrder(root, 2);for(auto c: res){cout << c << ",";}cout << endl;vector<int> res2 = getKdistanceInOrder(root, 2);for(auto b: res2){cout << b << ",";}// 释放内存delete root->_pLeft->_pRight->_pLeft;delete root->_pRight->_pRight;delete root->_pRight->_pLeft;delete root->_pLeft->_pRight;delete root->_pRight;delete root->_pLeft; }
4、在二叉树中查找给定节点的祖先节点
祖先节点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点。
题目:如下二叉树,给定节点值6,打印节点6的祖先节点 [3, 1, 2]。
思路: 使用递归方法,检查当前节点是否为空,为空就返回false。如果当前节点不为空,检查是否为目标节点,如果是返回true。接下来,递归地在左子树和右子树中查找目标节点,如果在左子树或右子树中找到了目标节点,则将当前节点的值添加到结果数组中,并返回true。如果左子树和右子树都没有找到目标节点,则返回false。
#include<iostream>
#include<vector>
#include<stack>
#include<algorithm>
using namespace std;struct BinaryTreeNode{BinaryTreeNode* left;BinaryTreeNode* right;int val;BinaryTreeNode(int x): val(x), left(NULL), right(NULL){}
};bool findAncestorsDFS(BinaryTreeNode* root, int target, vector<int>& ancestors) {if (root == nullptr) {return false;}if (root->val == target) {return true;}if (findAncestorsDFS(root->left, target, ancestors) || findAncestorsDFS(root->right, target, ancestors)) {ancestors.push_back(root->val);return true;}return false;
}int main(){BinaryTreeNode* root = new BinaryTreeNode(2);root->left = new BinaryTreeNode(1);root->right = new BinaryTreeNode(4);root->left->right = new BinaryTreeNode(3);root->right->left = new BinaryTreeNode(8);root->right->right = new BinaryTreeNode(5);root->left->right->left = new BinaryTreeNode(6);int target = 6;vector<int> ancestors;bool res = findAncestorsDFS(root, target, ancestors);cout << "节点 " << target << " 的祖先节点值为:";for (int val : ancestors) {std::cout << val << " ";}std::cout << std::endl;
}