目录
一、深度优先搜索
1.1 - 深度优先搜索遍历的过程
1.2 - 深度优先搜索遍历的算法实现
二、广度优先搜索
2.1 - 广度优先搜索遍历的过程
2.2 - 广度优先搜索遍历的算法实现
和树的遍历类似,图的遍历也是从图中某一顶点出发,按照某种方法对图中所有顶点访问且仅访问一次。图的遍历算法是求解图的连通性问题、拓扑排序和关键路径等算法的基础。
然而,图的遍历要比树的遍历复杂得多,因为图的任一顶点都可能和其余的顶点相连接,所以在访问了某个顶点之后,可能沿着某条搜索路径之后,又回到该顶点上。例如,图一 (b) 中所示的无向图 G2,由于图中存在回路,因此在访问了 v1、v2、v3、v4 之后,沿着边 (v4, v1) 又可访问到 v1。为了避免同一顶点被访问多次,在遍历图的过程中,必须记下每个已被访问过的顶点,为此,设一个辅助数组 isVisited[n],其初始值为 false 或 0,一旦访问了顶点 vi,便置 isVisited[vi] 为 true 或 1。
根据搜索路径的方向,通常有两条遍历图的路径:深度优先搜索和广度优先搜索。它们对无向图和有向图都适用。
一、深度优先搜索
1.1 - 深度优先搜索遍历的过程
深度优先搜索(Depth First Search,DFS)遍历类似于树的先序遍历,是树的先序遍历的推广。
对于一个连通图,深度优先搜索遍历的过程如下:
-
从图中某个顶点 v 出发,访问 v。
-
找出刚刚访问过的顶点的第一个未被访问的邻接点,访问该顶点。以该顶点为新顶点,重复此步骤,直至刚访问过的顶点没有未被访问的邻接点为止。
-
返回前一个访问过的且仍有未被访问的邻接点的顶点,找出该顶点的下一个未被访问的邻接点,访问该结点。
-
重复步骤 2 和 3,直至图中所有顶点都被访问过,搜索结束。
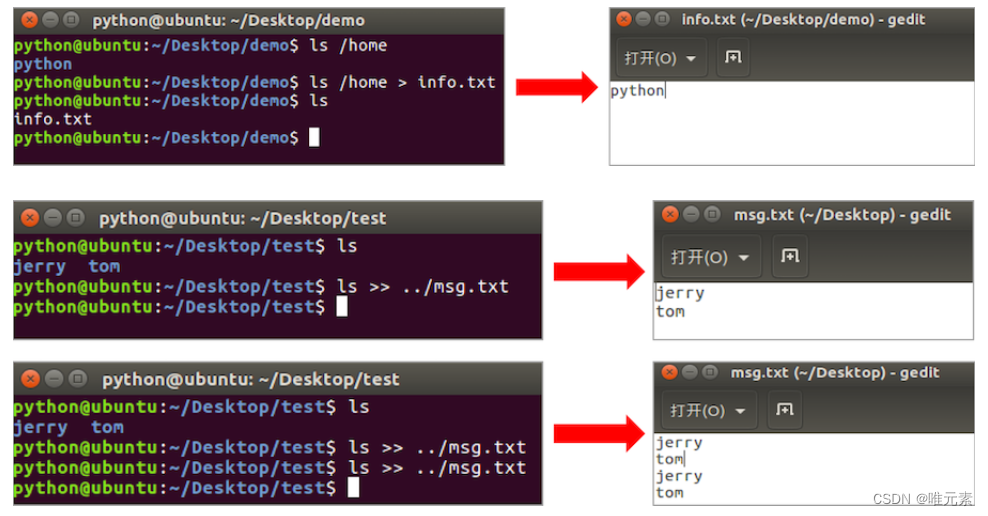
以下图 (a) 中所示的无向图 G4 为例,深度优先搜索遍历图的过程如下图 (b) 所示。
图中以带箭头的粗实线表示遍历时的访问路径,以带箭头的虚线表示回溯路径。小圆圈表示已访问的邻接点,大圆圈表示访问的邻接点。
具体过程如下:
-
从顶点 v1 出发,访问 v1。
-
在访问了 v1 之后,选择第一个未被访问的邻接点 v2,访问 v2。以 v2 为新顶点,重复此步,访问 v4、v8、v5。在访问了 v5 之后,由于 v5 的邻接点都已被访问,此步结束。
-
搜索从 v5 回到 v8,由于同样的理由,搜索继续回到 v4、v2 直至 v1,此时由于 v1 的另一个邻接点未被访问,则搜索又从 v1 到 v3,再继续进行下去。由此,得到的顶点访问序列为:v1-->v2-->v4-->v8-->v5-->v3-->v6-->v7。
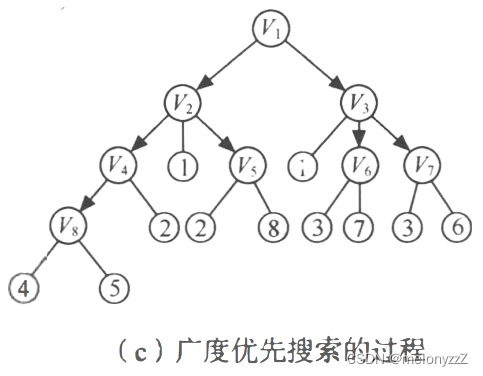
上图 (b) 中所示的所有顶点加上标有实箭头的边,构成一棵以 v1 为根的树,称为深度优先生成树,如下图所示。

1.2 - 深度优先搜索遍历的算法实现
显然,深度优先搜索遍历连通图是一个递归过程。为了在遍历过程中便于区分顶点是否已被访问,需附设访问标志数组 isVisited[n],其初值为 false,一旦某个顶点被访问,则其相应的分量置为 true。
void _DFS(Graph* pg, VertexType v, bool* isVisited)
{printf("%c-->", v);int pos = GetVertexPos(pg, v);isVisited[pos] = true;
int adjVexPos = GetFirstAdjVexPos(pg, v);while (adjVexPos != -1){VertexType w = GetVertexVal(pg, adjVexPos);if (isVisited[adjVexPos] == false)_DFS(pg, w, isVisited);
adjVexPos = GetNextAdjVexPos(pg, v, w);}
}
void DFS(Graph* pg, VertexType v)
{assert(pg);bool* isVisited = (bool*)malloc(sizeof(bool) * pg->vSize);assert(isVisited);for (int i = 0; i < pg->vSize; ++i){isVisited[i] = false;}_DFS(pg, v, isVisited);printf("NULL\n");free(isVisited);isVisited = NULL;
}若是非连通图,上述遍历过程执行之后,图中一定还有顶点未被访问,需要从图中另选一个未被访问的顶点作为起始点,重复上述深度优先搜索过程,直到图中所有顶点均被访问为止。
void DFSTraverse(Graph* pg)
{assert(pg);bool* isVisited = (bool*)malloc(sizeof(bool) * pg->vSize);assert(isVisited);for (int i = 0; i < pg->vSize; ++i){isVisited[i] = false;}for (int i = 0; i < pg->vSize; ++i){if (isVisited[i] == false){_DFS(pg, GetVertexVal(pg, i), isVisited);printf("NULL\n");}}free(isVisited);isVisited = NULL;
}调用一次
_DFS函数将遍历一个连通分量,有多少次调用,就说明图中有多少个连通分量。
二、广度优先搜索
2.1 - 广度优先搜索遍历的过程
广度优先搜索(Breadth First Search,BFS)遍历类似于树的层次遍历的过程。
广度优先搜索遍历的过程如下:
-
从图中某个顶点 v 出发,访问 v。
-
依次访问 v 的各个未曾访问过的邻接点。
-
分别从这些邻接点出发依次访问它们的邻接点,并使 "先被访问的顶点的邻接点" 先于 "后被访问的顶点的邻接点" 被访问。重复步骤 3,直至图中所有已被访问的邻接点都被访问到。
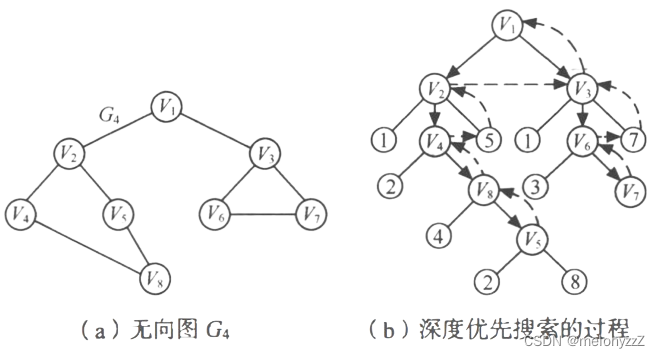
例如,对上图 (a) 中的无向图 G4 进行广度优先搜索遍历的过程如下图 (c) 所示。
具体过程如下:
-
从顶点 v1 出发,访问 v1。
-
依次访问 v1 的各个未曾访问过的邻接点 v2 和 v3。
-
依次访问 v2 的邻接点 v4 和 v5,以及 v3 的邻接点 v6 和 v7,最后访问 v4 的邻接点 v8。由于这些顶点的邻接点均已被访问,并且图中所有顶点都被访问,由此完成了图的遍历。得到的顶点访问序列为:v1-->v2-->v3-->v4-->v5-->v6-->v7-->v8。
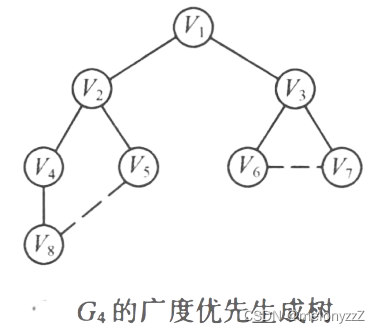
上图 (c) 中所示的所有顶点加上标有实箭头的边,构成一棵以 v1 为根的树,称为广度优先生成树,如下图所示。
2.2 - 广度优先搜索遍历的算法实现
可以看出,广度优先搜索遍历的特点是:尽可能先对横向进行搜索。假设 x 和 y 是两个相继被访问过的顶点,若当前是以 x 为出发点进行搜索,则在访问 x 的所有未曾被访问过的邻接点之后,紧接着是以 y 为出发点进行横向搜索,并对搜索到的 y 的邻接点中尚未被访问的顶点进行访问。也就是说,先访问的顶点其邻接点亦先被访问。为此,算法实现时需引入队列保存已被访问的顶点。
和深度优先搜索类似,广度优先搜索在遍历的过程中也需要一个访问标志数组。
广度优先搜索遍历连通图:
void _BFS(Graph* pg, VertexType v, bool* isVisited)
{printf("%c-->", v);int pos = GetVertexPos(pg, v);isVisited[pos] = true;
Queue q;QueueInit(&q);QueuePush(&q, pos);while (!QueueEmpty(&q)){pos = QueueFront(&q);QueuePop(&q);v = GetVertexVal(pg, pos);
int adjVexPos = GetFirstAdjVexPos(pg, v);while (adjVexPos != -1){VertexType w = GetVertexVal(pg, adjVexPos);if (isVisited[adjVexPos] == false){printf("%c-->", w);isVisited[adjVexPos] = true;QueuePush(&q, adjVexPos);}adjVexPos = GetNextAdjVexPos(pg, v, w);}}QueueDestroy(&q);
}
void BFS(Graph* pg, VertexType v)
{assert(pg);bool* isVisited = (bool*)malloc(sizeof(bool) * pg->vSize);assert(isVisited);for (int i = 0; i < pg->vSize; ++i){isVisited[i] = false;}_BFS(pg, v, isVisited);printf("NULL\n");free(isVisited);isVisited = NULL;
}广度优先搜索遍历非连通图算法的实现类似于深度优先搜索遍历非连通图,只需要将 _DFS 函数调用改为 _BFS 函数调用。