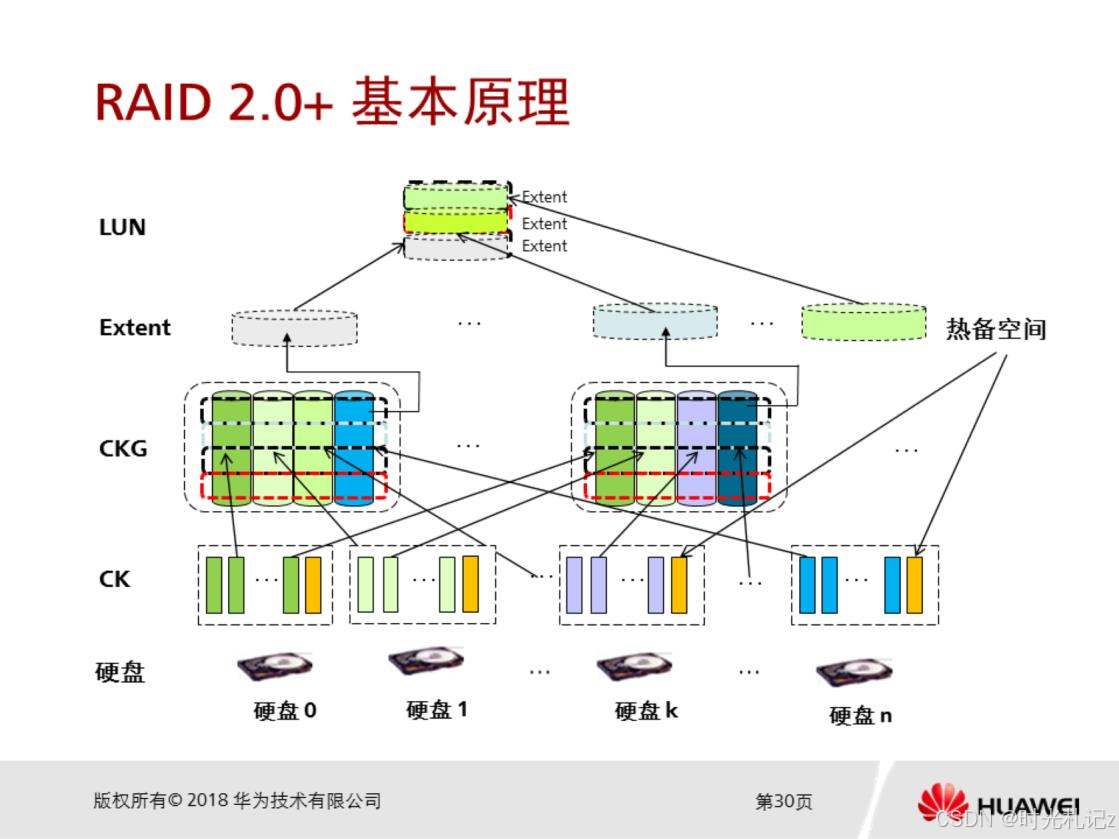
RustDesk服务端
- 下面的截图是我本地的一个服务器做为演示用,你自行的搭建服务需要该服务器有
固定的ip地址 -
1、通过宝塔面板快速安装

-
2、点击【安装】后会有一个配置信息,
默认即可
-
3、点击【确认】后会自动安装等待安装完成

-
4、安装完成后点击【打开日志】图标

-
5、查看生成的
Key
-
6、如果你云服务器有访问规则,可能还需要开放相应的端口

Rustdesk应用端
https://github.com/rustdesk/rustdesk/releases
-
2、Rustdesk 受控端和被控端都需要以下安装步骤


-
3、这里
ID服务器和中继服务器,填你宝塔服务器的ip地址,下面的Key就填上面Docker安装成功后生成的Key,