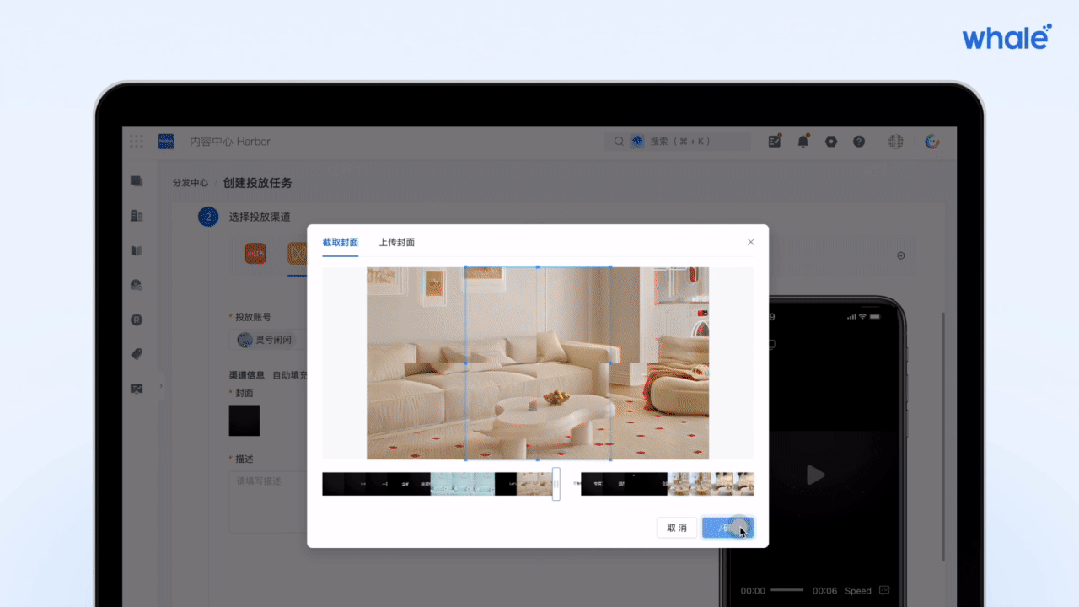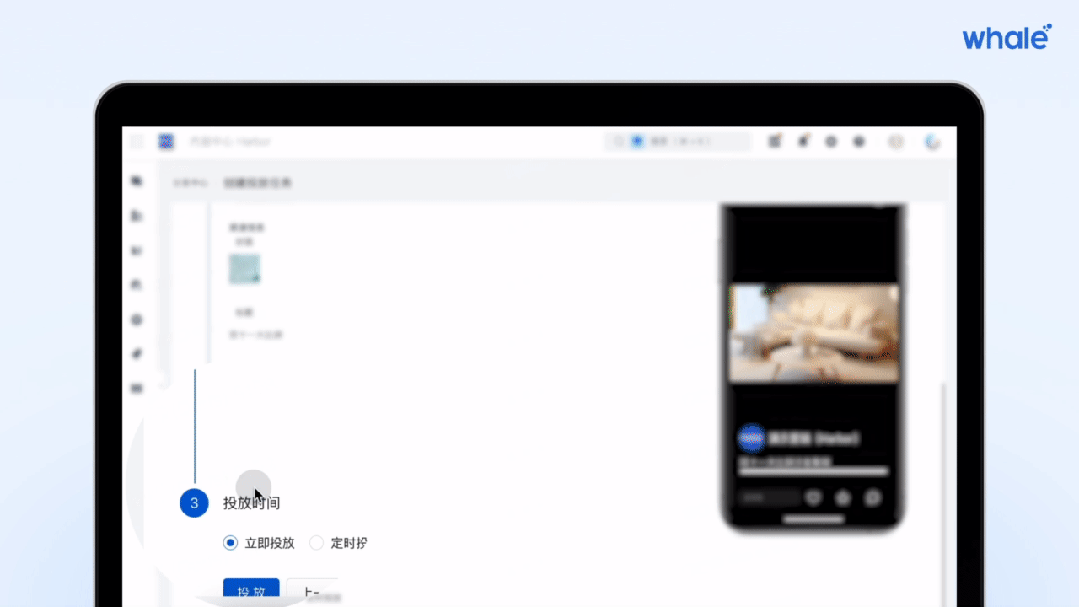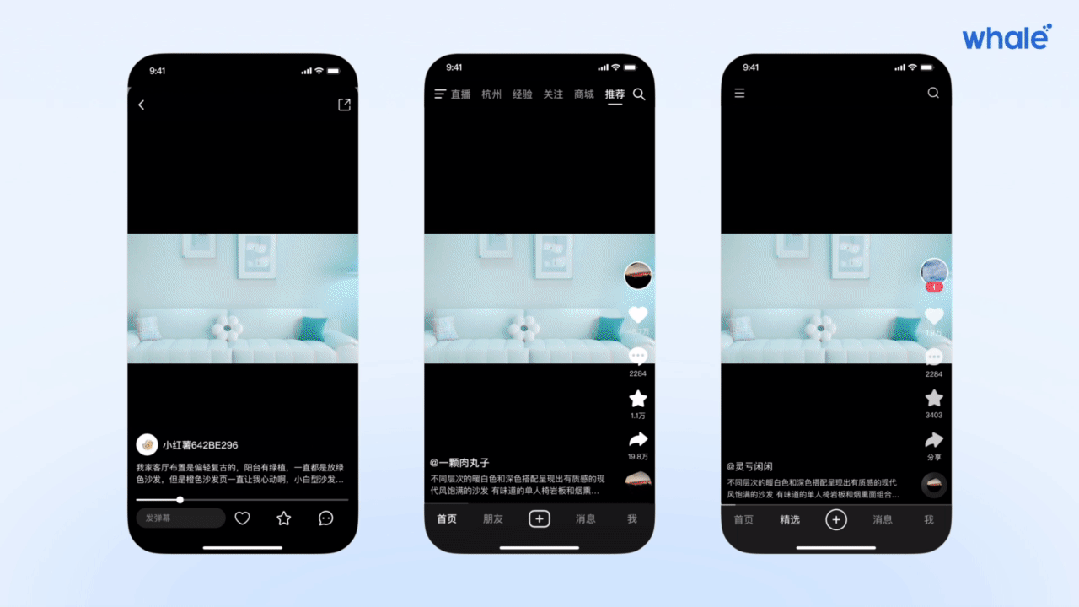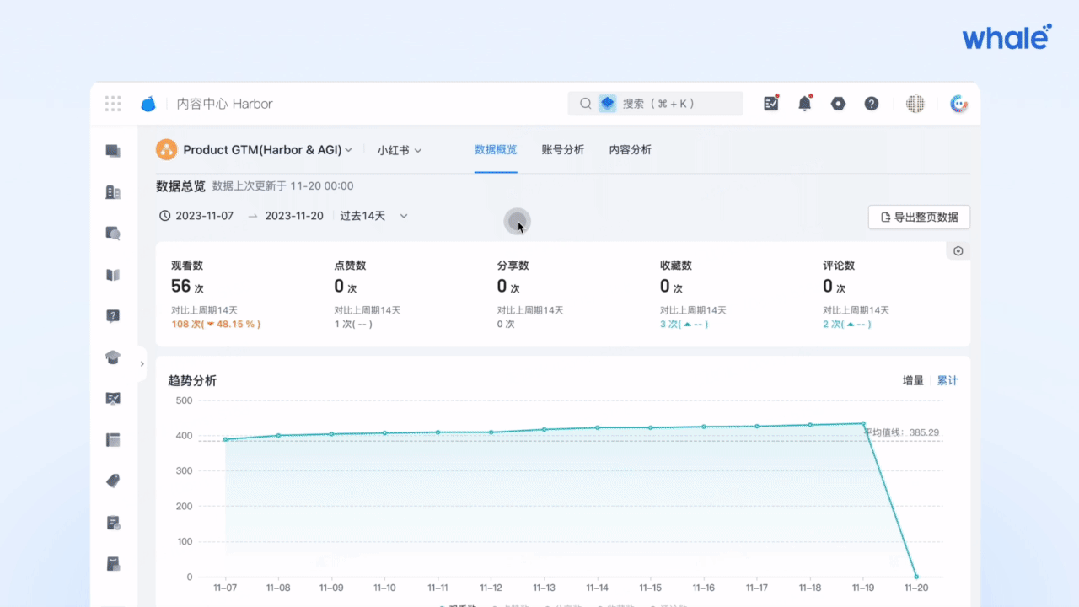
词嵌入模型
- 将单词映射到实向量的技术称为词嵌入。
为什么独热向量不能表达词之间的相似性?

自监督的word2vec。
word2vec将每个词映射到一个固定长度的向量,这些向量能更好的表达不同词之间的相似性和类比关系。
word2vec分为两类,两类模型都是自监督模型。
- 跳元模型(SKip-Gram)。
- 连续词袋(CBOW)模型。
小结
- 词向量是用于表示单词意义的向量,也可以看作词的特征向量。将词映射到实向量的技术称为词嵌入。
- word2vec工具包含跳元模型和连续词袋模型。
- 跳元模型假设一个单词可用于在文本序列中,生成其周围的单词;而连续词袋模型假设基于上下文词来生成中心单词。

跳元模型和连续词袋模型的损失函数?


近似训练
使用负采样和分层Softmax来优化损失函数的计算:
- 负采样通过考虑相互独立的事件来构造损失函数,这些事件同时涉及正例和负例。训练的计算量与每一步的噪声词数成线性关系。
- 分层softmax使用二叉树中从根节点到叶节点的路径构造损失函数。训练的计算成本取决于词表大小的对数。


用于预训练词嵌入的数据集
- 高频词在训练中可能不是那么有用。我们可以对他们进行下采样,以便在训练中加快速度。
- 为了提高计算效率,我们以小批量方式加载样本。我们可以定义其他变量来区分填充标记和非填充标记,以及正例和负例。
预训练word2vec
-
我们可以使用嵌入层和二元交叉熵损失来训练带负采样的跳元模型。




-
词嵌入的应用包括基于词向量的余弦相似度为给定词找到语义相似的词。
全局向量的词嵌入
- 诸如词-词共现计数的全局语料库统计可以来解释跳元模型。
- 交叉熵损失可能不是衡量两种概率分布差异的好选择,特别是对于大型语料库。GloVe使用平方损失来拟合预先计算的全局语料库统计数据。
- 对于GloVe中的任意词,中心词向量和上下文词向量在数学上是等价的。
- GloVe可以从词-词共现概率的比率来解释。
子词嵌入
- fastText模型提出了一种子词嵌入方法:基于word2vec中的跳元模型,它将中心词表示为其子词向量之和。
- 字节对编码执行训练数据集的统计分析,以发现词内的公共符号。作为一种贪心方法,字节对编码迭代地合并最频繁的连续符号对。
- 子词嵌入可以提高稀有词和词典外词的表示质量。
FastText模型的主要结构组件:



FastText模型的主要特点是什么?



词的相似性和类比任务
- 在实践中,在大型语料库上预先练的词向量可以应用于下游的自然语言处理任务。
- 预训练的词向量可以应用于词的相似性和类比任务。
自然语言处理中的预训练是在训练什么?



来自Transformer的双向编码器表示
由于语言模型的自回归特性,GPT只能向前看(从左到右)。在“i went to the bank to deposit cash”(我去银行存现金)和“i went to the bank to sit down”(我去河岸边坐下)的上下文中,由于“bank”对其左边的上下文敏感,GPT将返回“bank”的相同表示,尽管它有不同的含义。
小结
- word2vec和GloVe等词嵌入模型与上下文无关。它们将相同的预训练向量赋给同一个词,而不考虑词的上下文(如果有的话)。它们很难处理好自然语言中的一词多义或复杂语义。
- 对于上下文敏感的词表示,如ELMo和GPT,词的表示依赖于它们的上下文。
- ELMo对上下文进行双向编码,但使用特定于任务的架构(然而,为每个自然语言处理任务设计一个特定的体系架构实际上并不容易);而GPT是任务无关的,但是从左到右编码上下文。
- BERT结合了这两个方面的优点:它对上下文进行双向编码,并且需要对大量自然语言处理任务进行最小的架构更改。
- BERT输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和。
- 预训练包括两个任务:掩蔽语言模型和下一句预测。前者能够编码双向上下文来表示单词,而后者则显式地建模文本对之间的逻辑关系。
word2vec,Glove,EIMo,GPT,BERT等模型的特点,优点和缺点:



总结:
每种模型都有其独特的优势和局限性。Word2Vec和GloVe在词嵌入方面表现出色,但不涉及上下文信息;ELMo、GPT和BERT则在捕捉复杂的上下文关系方面更为先进,但也伴随着更高的资源需求。选择哪种模型通常取决于特定任务的需求、可用资源和性能目标。
用于预训练BERT的数据集
- 与PTB数据集相比,WikiText-2数据集保留了原来的标点符号、大小写和数字,并且比PTB数据集大了两倍多。
- 我们可以任意访问从WikiText-2语料库中的一对句子生成的预训练(遮蔽语言模型和下一句预测)样本。
预训练BERT
BERT的预训练机制:


小结
- 原始的BERT有两个版本,其中基本模型有1.1亿个参数,大模型有3.4亿个参数。
- 在预训练BERT之后,我们可以用它来表示单个文本、文本对或其中的任何词元。
- 在实验中,同一个词元在不同的上下文中具有不同的BERT表示。这支持BERT表示是上下文敏感的。
遮蔽语言模型损失和下一句预测损失分别表示什么?


MLM损失和NSP损失共同构成了BERT模型的预训练损失,它们分别针对模型的两个核心任务:理解词的上下文相关含义和理解句子间的关系。通过最小化这两个损失,BERT能够学习到丰富且有效的语言表示,为各种下游NLP任务奠定基础。