六:bs4简介
基本概念:
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据官方解释如下:
'''
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,
所以不需要多少代码就可以写出一个完整的应用程序。
'''
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。BeautifulSoup会帮节省数小时甚至数天的工作时间。BeautifulSoup3目前已经停止开发,官网推荐在现在的项目中使用BeautifulSoup4。
bs4的安装
由于 Bautiful Soup 是第三方库,因此需要单独下载,下载方式非常简单,执行以下命令即可安装:
pip install bs4
由于BS4 解析页面时需要依赖 文档解析器,所以还需要安装 lxml 作为解析库 所以我们还需要安装lxml,安装方式如下:
pip install lxml
Python 也自带了一个文档解析库 html.parser, 但是其解析速度要稍慢于 lxml。除了上述解析器外,还可以使用 html5lib 解析器,安装方式如下:
pip install html5lib
注意:bs4是依赖lxml库的,只有先安装lxml库才可以安装bs4库
文档解析器优缺点
下表列出了主要的解析器,以及它们的优缺点:
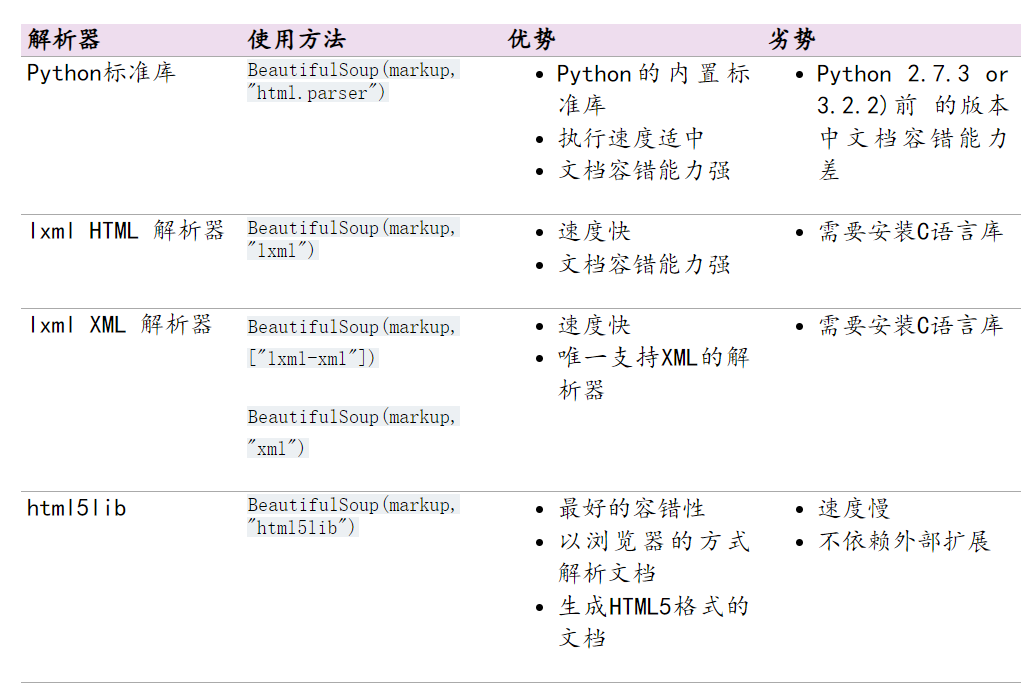
推荐使用lxml作为解析器,因为效率更高。在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定。
提示: 如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的。因此我们可以根据情况去选择对应的文档解析器。具体情况具体分析。
bs4的使用
快速开始
创建BS4解析对象是万事开头的第一步,这非常地简单,语法格式如下所示:
1、导入解析包
from bs4 import BeautifulSoup
2、创建beautifulsoup解析对象
soup = BeautifulSoup(html_doc, ‘html.parser’)
上述代码中,html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 ‘lxml’ 或者 ‘html5lib’
from bs4 import BeautifulSouphtml_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>
"""
# 创建一个soup对象
soup = BeautifulSoup(html_doc,'lxml')
print(soup,type(soup))
# 格式化文档输出
print(soup.prettify())
# 获取title标签内容 <title>The Dormouse's story</title>
print(soup.title)
# 获取title标签名称: title
print(soup.title.name)
# title标签里面的文本内容: The Dormouse's story
print(soup.title.string)
# 获取p段落
print(soup.p)
bs4的对象种类
- tag : html中的标签。
可以通过BeautifulSoup分析Tag的具体内容,具体格式为soup.name,其中name是html下的标签。
- NavigableString : 标签中的文本对象。
- BeautifulSoup : 整个html文本对象。
可以作为Tag对象。
- Comment : 特殊的NavigableString对象,如果html标签中有注释,则可过滤注释符号并保留注释文本。
from bs4 import BeautifulSouphtml_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>
"""'''
tag : 标签
NavigableString : 可导航的字符串
BeautifulSoup : bs对象
Comment : 注释
'''
soup = BeautifulSoup(html_doc, "html.parser")
# print(soup)
'''tag:标签'''
print(type(soup.title))
print(type(soup.p))
print(type(soup.a))'''NavigableString : 可导航的字符串'''
from bs4.element import NavigableString
print(type(soup.title.string))'''BeautifulSoup : bs对象'''
soup = BeautifulSoup(html_doc, "html.parser")
print(type(soup))'''Comment : 注释'''
html = "<b><!--同学们好呀加油学习--></b>"
soup2 = BeautifulSoup(html, "html.parser")
print(soup2.b.string, type(soup2.b.string))遍历文档树
遍历子节点
- contents 返回的是一个所有子节点的列表(了解)
- children 返回的是一个子节点的迭代器(了解)
- descendants 返回的是一个生成器遍历子子孙孙(了解)
- string 获取标签里面的内容(掌握)
- strings 返回是一个生成器对象用过来获取多个标签内容(掌握)
- stripped_strings 和strings 基本一致 但是它可以把多余的空格去掉(掌握)
遍历父节点(了解)
- parent 直接获得父节点
- parents 获取所有的父节点
遍历兄弟节点(了解)
- next_sibling 下一个兄弟结点
- previous_sibling 上一个兄弟结点
- next_siblings 下一个所有兄弟结点
- previous_siblings上一个所有兄弟结点
from bs4 import BeautifulSouphtml_doc = """
<html>
<head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
"""
'''
生成器 迭代器 可迭代对象 三者之间的关系
'''
# 获取单个标签中的内容
soup = BeautifulSoup(html_doc, "lxml")
r1 = soup.title.string # 获取标签里面的内容
print(r1)# 获取html中所有的标签内容
r2 = soup.html.strings # 返回是一个生成器对象用过来获取多个标签内容
print(r2)
for i in r2:print(i)r3 = soup.html.stripped_strings # 和strings基本一致 但是它可以把多余的空格去掉
print(r3) # 生成器对象 <generator object Tag._all_strings at 0x000001A73C538AC8>
for i in r3:print(i)
搜索文档树
find()
- find()方法返回搜索到的第一条数据
find_all()
- find_all()方法以列表形式返回所有的搜索到的标签数据
实例应用
html = """
<table class="tablelist" cellpadding="0" cellspacing="0"><tbody><tr class="h"><td class="l" width="374">职位名称</td><td>职位类别</td><td>人数</td><td>地点</td><td>发布时间</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-25</td></tr><tr class="odd"><td class="l square"><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td><td>技术类</td><td>2</td><td>深圳</td><td>2017-11-25</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td><td>技术类</td><td>2</td><td>深圳</td><td>2017-11-25</td></tr><tr class="odd"><td class="l square"><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-25</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr><tr class="odd"><td class="l square"><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td><td>技术类</td><td>4</td><td>深圳</td><td>2017-11-24</td></tr><tr class="odd"><td class="l square"><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr><tr class="odd"><td class="l square"><a id="test" class="test" target='_blank' href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr></tbody>
</table>
"""
- 获取所有的tr标签;
# 1 获取所有的tr标签
trs = soup.find_all("tr") # 这是个列表过滤器
for tr in trs:print(tr)print("*" * 150)
- 获取第二个tr标签;
# 2 获取第二个tr标签
tr = soup.find_all("tr")[1]
print(tr)
- 获取获取所有的class =even的tr标签
trs = soup.find_all("tr", class_="even") # 但这里如果直接用class不行 class是作为我们的关键字
# trs = soup.find_all("tr", attrs={"class": "even"}) 这两种方式都可
for tr in trs:print(tr)print("*" * 150)
- 获取所有a标签里面的href属性值;
# 5 获取所有的a标签的href属性
a_li = soup.find_all("a")
for a in a_li:href = a.get("href")print(href)
- 获取所有的岗位信息。
trs = soup.find_all("tr")[1:]
for tr in trs:tds = tr.find_all("td")# print(tds)job_name = tds[0].stringprint(job_name)
select()方法
我们也可以通过css选择器的方式来提取数据。但是需要注意的是这里面需要我们掌握css语法https://www.w3school.com.cn/cssref/css_selectors.asp
from bs4 import BeautifulSouphtml = """
<table class="tablelist" cellpadding="0" cellspacing="0"><tbody><tr class="h"><td class="l" width="374">职位名称</td><td>职位类别</td><td>人数</td><td>地点</td><td>发布时间</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-25</td></tr><tr class="odd"><td class="l square"><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td><td>技术类</td><td>2</td><td>深圳</td><td>2017-11-25</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td><td>技术类</td><td>2</td><td>深圳</td><td>2017-11-25</td></tr><tr class="odd"><td class="l square"><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-25</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr><tr class="odd"><td class="l square"><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td><td>技术类</td><td>4</td><td>深圳</td><td>2017-11-24</td></tr><tr class="odd"><td class="l square"><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr><tr class="even"><td class="l square"><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr><tr class="odd"><td class="l square"><a id="test" class="test" target='_blank' href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td><td>技术类</td><td>1</td><td>深圳</td><td>2017-11-24</td></tr></tbody>
</table>
"""
soup = BeautifulSoup(html, "lxml")# 获取所有的tr标签
# trs = soup.select("tr")
# for i in trs:
# print(i)# 获取第二个tr标签
# tr = soup.select("tr")[1]
# print(tr)# 获取所有class等于even的tr标签
# trs = soup.select(".even")# 获取所有的a标签的href属性
# a_tags = soup.select("a")
# print(a_tags)
# for a in a_tags:
# href = a.get("href")
# print(href)# 获取所有的职位信息
trs = soup.select("tr")[1:]
print(trs)
for tr in trs:print(tr)print(list(tr.strings))info = list(tr.stripped_strings)[0]print(info)
修改文档树
- 修改tag的名称和属性
- 修改string 属性赋值,就相当于用当前的内容替代了原来的内容
- append() 像tag中添加内容,就好像Python的列表的 .append() 方法
- decompose() 修改删除段落,对于一些没有必要的文章段落我们可以给他删除掉
from bs4 import BeautifulSouphtml_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, "html.parser")
"""
● 修改tag的名称和属性
● 修改string 属性赋值,就相当于用当前的内容替代了原来的内容
● append() 像tag中添加内容,就好像Python的列表的 .append() 方法
● decompose() 修改删除段落,对于一些没有必要的文章段落我们可以给他删除掉
"""
# 修改tag的名称和属性
tag_p = soup.p
print(tag_p)
tag_p.name = "w"
tag_p["class"] = "content"
print(tag_p)# 修改string 属性赋值,就相当于用当前的内容替代了原来的内容
tag_p = soup.p
print(tag_p.text)
tag_p.string = "you need python"
print(tag_p.text)# append() 像tag中添加内容,就好像Python的列表的 .append() 方法
tag_p = soup.p
print(tag_p)
tag_p.append("真的C!")
print(tag_p)# # decompose() 修改删除段落,对于一些没有必要的文章段落我们可以给他删除掉
r = soup.title
print(r)
r.decompose()
print(soup)
csv模块
什么是csv?
CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件。python自带了csv模块,专门用于处理csv文件的读取
csv模块的使用
写入csv文件
1 通过创建writer对象,主要用到2个方法。一个是writerow,写入一行。另一个是writerows写入多行
2 使用DictWriter 可以使用字典的方式把数据写入进去
读取csv文件
1 通过reader()读取到的每一条数据是一个列表。可以通过下标的方式获取具体某一个值
2 通过DictReader()读取到的数据是一个字典。可以通过Key值(列名)的方式获取数据
csv文件操作应用
"""csv写入文件"""
import csvpersons = [('岳岳', 20, 175), ('月月', 22, 178), ('张三', 20, 175)]
headers = ('name', 'age', 'heigth')
with open('persons.csv', mode='w', encoding='utf-8',newline="")as f:writer = csv.writer(f) # 创建writer对象writer.writerow(headers) # 将表头写入进去for i in persons:writer.writerow(i) # 将列表中的值写入进去# Dictwriter 写入字典数据格式
import csvpersons = [{'name': '岳岳', 'age': 18, 'gender': '男'},{'name': '岳岳2', 'age': 18, 'gender': '男'},{'name': '岳岳3', 'age': 18, 'gender': '男'}
]headers = ('name', 'age', 'gender')
with open('person2.csv', mode='w', encoding='utf-8',newline="")as f:writer = csv.DictWriter(f, headers)writer.writeheader() # 写入表头writer.writerows(persons)"""csv读取文件"""
# 方式一
import csv
with open('persons.csv',mode='r',encoding='utf-8',newline="")as f:reader = csv.reader(f)print(reader) # <_csv.reader object at 0x0000021D7424D5F8>for i in reader:print(i)# 方式二
import csv
with open('person2.csv', mode='r', encoding='utf-8',newline="")as f:reader = csv.DictReader(f)print(reader) # <_csv.reader object at 0x0000021D7424D5F8>for i in reader:# print(i)for j, k in i.items():print(j, k)
bs4实例应用
from bs4 import BeautifulSoup
import requests
import csv"""
目标url = "http://www.weather.com.cn/textFC/hb.shtml"
需求: 爬取全国所有城市的温度(最低气温) 并保存到csv文件中
保存格式:[{"city":"北京","temp":"5℃"},{"xxx":"xxx","xxx":"xxx"},.....]
涉及技术: request csv bs4思路与页面分析:
1 获取网页源码并创建soup对象
2 将拿到的数据进行解析拿到目标数据2.1 先找到整页的div class = 'conMidtab'标签2.2 接下来找到它下面的每一个省或者是直辖市的table标签2.3 对拿到的tables数据进行过滤 找到table标签下面所有的tr标签 需要注意,要把前2个tr标签过滤掉2.4 再找到tr标签里面所有的td标签(第0个就是城市 倒数第二个就是温度)
3 将获取的数据进行存储
"""# 定义一个函数用于获取网页源码并解析数据
def getscroce(every_url):# 目标url# url = "http://www.weather.com.cn/textFC/hb.shtml"# 请求头数据headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}response = requests.get(every_url, headers=headers)response.encoding = 'utf-8'# 获取到的网页源码html = response.text# 将获取的网页源代码进行解析# 1 创建一个soup对象soup = BeautifulSoup(html, 'html5lib')# print(soup)# 2 先找到整页的div class = 'conMidtab'标签conMidtab = soup.find('div', class_='conMidtab')# print(conMidtab)# 3接下来找到它下面的每一个省或者是直辖市的table标签tables = conMidtab.find_all('table')# print(tables)# 4对拿到的tables数据进行过滤 找到table标签下面所有的tr标签(需要注意,要把前2个tr标签过滤掉)# 定义一个列表 将字典数据进行存储 然后准备写入csvtemplist = []for table in tables:trs = table.find_all('tr')[2:]# print(trs)for index, tr in enumerate(trs):# print(index,tr)# 在找到tr标签里面所有的td标签(第0个就是城市 倒数第二个就是温度)tds = tr.find_all('td')# print(tds)# 获取城市存在的td标签city_td = tds[0]if index == 0:city_td = tds[1]# print(city_td)# 定义一个字典用于保存数据 城市和温度tempdict = {}# 获取城市文本数据city = list(city_td.stripped_strings)[0]# print(city)# 获取最低温度temp_td = tds[-2]temp = list(temp_td.stripped_strings)[0]# print(temp)tempdict['city'] = citytempdict['temp'] = temp# 将字典数据添加到列表中templist.append(tempdict)# print(templist) # 通过打印发现 {'city': '河北', 'temp': '20'} 这个根本不存在'''如果是直辖市你取第0个td标签没有问题,所有的数据也是正常的如果是省你不能取第0个td标签了(省的名字),取第一个td标签,但是所有的都取第一个td那么这样其它城市又不对了。因为其它的城市都是第0个td标签我们只需要做一个判断,什么时候取第0个td 什么时候取第一个td'''# 将获取的数据进行返回 用于下一步进行数据的存储return templist# 定义一个函数用于保存解析到的数据
def writeData(alltemplist):header = ('city', 'temp')with open('weather.csv', mode='w', encoding='utf-8', newline='')as f:# 创建写入对象writer = csv.DictWriter(f, header)# 写入表头writer.writeheader()# 写入数据writer.writerows(alltemplist)# 定义一个主函数 用来执行各个函数
def main():# 定义一个列表保存全国城市的温度alltemplist = []model_url = "http://www.weather.com.cn/textFC/{}.shtml"# 定义一个列表 用于保存八大地区的urlurlkey_list = ["hb", "db", "hd", "hz", "hn", "xb", "xn", "gat"]for i in urlkey_list:every_url = model_url.format(i)print(every_url)# templist = getscroce() # 舍去alltemplist += getscroce(every_url)# print(templist)# 将获取的数据进行传递 用于保存csvwriteData(alltemplist)# enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。# for i,j in enumerate(range(10)):# print(i,j)if __name__ == '__main__':main()




![[Kubernetes]3. k8s集群Service详解](https://img-blog.csdnimg.cn/direct/0f90740aef3c4283b109aa8ba52519fe.png)