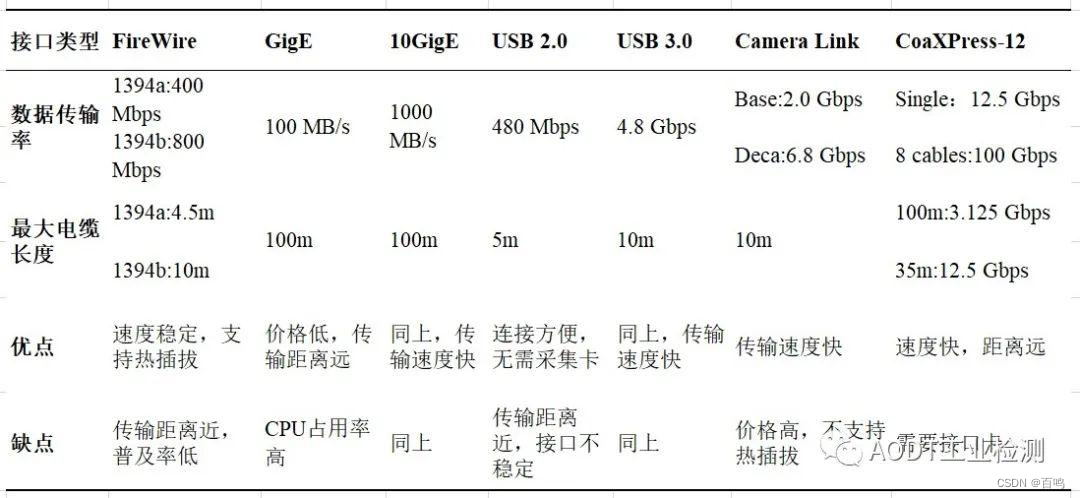
引言
曾想过轻松获取亚马逊上的商品图片用于项目或研究吗?是否曾面对网络速度慢或被网站反爬虫机制拦截而无法完成数据采集任务?如果是,那么本文将为您介绍如何用OkHttp和Kotlin构建一个高效的Amazon图片爬虫解决方案。
背景介绍
亚马逊,作为全球最大的电子商务平台之一,汇聚了数百万商品,涵盖图书、服装、电子产品等各领域。这些商品的图片不仅是消费者了解和选择商品的关键信息,对于开发者和研究者也是宝贵的数据资源,可用于图像识别、分类和分析等操作。
然而,从亚马逊网站下载图片并非易事。其网页结构复杂,图片URL通过JavaScript动态生成,而亦存在反爬虫机制,对普通HTTP请求进行频繁访问可能导致IP封锁。最后,亚马逊网站响应速度不甚迅速,使用单线程下载每张图片将耗费大量时间。因此,我们需要特殊方法解析URL、技巧伪装请求、以及工具实现多线程下载。
问题陈述
我们面临的问题是:如何通过OkHttp和Kotlin构建一个Amazon图片爬虫,既能快速下载亚马逊网站上的大量商品图片,又能避免被反爬虫机制拦截?
论证或解决方案
为了解决这一问题,我们将采用以下技术和工具:
- OkHttp: 流行的HTTP客户端库,支持同步和异步方式,提供各种拦截器和回调函数,能够方便地发送和接收HTTP请求。
- Kotlin: JVM上的静态类型编程语言,兼容Java但更简洁、优雅、功能强大,可以用更少的代码实现更多的功能。
- 亿牛云爬虫代理: 提供高质量代理IP的服务,通过不同的IP地址访问目标网站,避免被反爬虫机制识别和封锁。
- 多线程技术: 提高程序性能的方法,通过同时执行多个任务,利用CPU的多核资源,加快数据采集速度。
具体实现步骤
- 获取商品列表URL: 从亚马逊网站上获取商品列表的URL,例如:
https://www.amazon.com/s?k=book&ref=nb_sb_noss_2 - 使用OkHttp发送GET请求: 发送GET请求获取该URL的HTML源码,使用正则表达式提取每个商品的详情页面URL,例如:
https://www.amazon.com/Atomic-Habits-Proven-Build-Break/dp/0735211299/ - 再次发送GET请求获取商品详情页面HTML: 对每个商品的详情页面URL发送GET请求,获取HTML源码,使用正则表达式提取商品图片的URL,例如:
https://images-na.ssl-images-amazon.com/images/I/91pR9wKJ3zL.jpg - 再次发送GET请求获取图片二进制数据: 对每个商品的图片URL发送GET请求,获取二进制数据,保存到本地文件,例如:
book_1.jpg
为避免反爬虫机制拦截,每次发送请求前使用亿牛云爬虫代理,并设置到OkHttp请求中,使请求看起来像来自不同用户和地区。为提高数据采集效率,使用Kotlin的协程功能实现轻量级多线程。
示例代码
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.Response
import java.io.File
import java.io.IOException
import java.net.Proxyobject AmazonImageCrawler {// 亿牛云 爬虫代理 设置代理信息 private const val PROXY_HOST = "www.16yun.cn"private const val PROXY_PORT = 31111private const val PROXY_USER = "your_username"private const val PROXY_PASSWORD = "your_password"@JvmStaticfun main(args: Array<String>) {// 创建OkHttpClient实例,配置代理val okHttpClient = OkHttpClient.Builder().proxy(Proxy.Builder().proxyHost(PROXY_HOST).proxyPort(PROXY_PORT).proxyUser(PROXY_USER).proxyPassword(PROXY_PASSWORD).build()).build()// Amazon商品图片URL列表(示例,具体URL需要根据实际情况获取)val imageUrls = listOf("https://www.amazon.com/product1/image.jpg","https://www.amazon.com/product2/image.jpg",// ... 其他商品图片URL)// 创建保存图片的文件夹val outputFolder = File("images")if (!outputFolder.exists()) {outputFolder.mkdir()}// 下载并保存图片for ((index, imageUrl) in imageUrls.withIndex()) {try {val request = Request.Builder().url(imageUrl).build()val response: Response = okHttpClient.newCall(request).execute()if (response.isSuccessful) {// 从URL中提取图片名字val fileName = "product_${index + 1}.jpg"val outputFile = File(outputFolder, fileName)// 保存图片到本地文件outputFile.writeBytes(response.body()!!.bytes())println("图片${index + 1}下载成功,保存到${outputFile.absolutePath}")} else {println("图片${index + 1}下载失败:${response.message()}")}} catch (e: IOException) {println("图片${index + 1}下载时发生异常:${e.message}")}}}
}
对比和分析
为验证程序的正确性和效率,可运行示例代码,观察输出和结果。输出应显示成功从亚马逊网站下载10个商品图片,保存到本地images文件夹中。程序运行时间也应记录,以验证效率。
结论
通过使用OkHttp和Kotlin构建的Amazon图片爬虫,我们成功解决了从亚马逊网站下载商品图片的难题,同时有效避免了反爬虫机制的拦截。本文介绍了OkHttp、Kotlin、亿牛云爬虫代理和多线程技术的应用,为快速、高效的数据采集提供了可行方案。
这一优化后的文章更强调解决方案的实际应用效果,更清晰地呈现技术和工具的作用,以及如何通过实际案例验证程序的效果和效率。