[paper | proj]
- 给定FLAME,基于每个三角面片中心初始化一个3D Gaussian(3DGS);当FLAME mesh被驱动时,3DGS根据它的父亲三角面片,做平移、旋转和缩放变化;
- 3DGS可以视作mesh上的辐射场;
- 为实现高保真的avatar,本文提出一种蒙皮(binding)继承策略,在优化过程中,保持蒙皮对3DGS的控制;
- 本文贡献如下:
- 提出GaussianAvatars,通过将3DGS绑定至FLAME模型,实现可驱动的head avatars;
- 设计了一种蒙皮继承策略,使得在保持蒙皮控制的情况下,3DGS的新增和移除。
近期工作
静态场景表征
- NeRF用神经网络,以辐射场的形式存储场景;
- 后续工作将场景表征为voxel grids、使用voxel hashing、或使用tensor decomposition,加速渲染;
- PointNeRF使用点云表征场景;
- 3D Gaussian Splatting使用各向异性3D Gaussian,实现实时渲染和优异的视觉效果;
- Mixture of Volumetric Primitives使用surface-aligned volumes实现高视觉保真度的快速渲染;
动态场景表征
- Basic Design:基于NeRF的方法,输入4D坐标(x, y, z, t),输出密度和颜色。例如:K-Plane、4K4D等。这类方法虽然效果不错,但是无法显式控制内容;
- Deformation MLP:学习静态标定空间,通过MLP将其他时间下的空间映射回标准空间;
- Proxy geometry:
- Liu等人 [25] 基于SMPL移动后的最近三角面片,将观察空间中的点warp回标定空间;
- Peng等人 [34] 基于SMPL的骨架和神经蒙皮系数(neural blending weights)变形点;
- 前向变形(forward deformation)[13, 18, 20, 23, 48] 和cage-based deformation [54];
- 不同于上述方法,本文将3DGS附着在三角面片上,并显式地移动他们,避免使用标定空间,并可使用mesh finetuning。
头像重建与驱动
- Thies等人 [41] 实现了数字人的实时人脸跟踪和面部重现(face reenactment);
- Gafni等人 [8] 从单目视频中以表情系数作为控制信号,学习NeRF;
- Grassal等人 [10] 向FLAME中添加偏移量,增强几何,通过基于表情控制的纹理域,实现动态纹理;
- IMavatar [51] 基于神经隐式方程学习3D可形变数字人,通过iterative root-finding实现标定空间到观察空间的映射;
- HeadNeRF [11] 学习一个基于NeRF的参数化头模;
- INSTA [55] 通过寻找FLAME上最近三角面片,将查询点映射回标定空间;
- Zheng [52] 探索了基于点的表征和可导的点渲染方法,在标定空间中定义点集,学习受FLAME表情系数控制的形变场,以驱动数字人;
- AvatarMAV [46] 定义了标定辐射场和运动场;
- 不同于INSTA,本文在3DGS和三角面片间建立一致性关联。
方法
- 根据给定的多视角图片和相机参数,估计每帧图片中的FLAME参数;
- 建立三角面片和3DGS的关系;
- 可导渲染得到图片与GT图片算损失,用于训练模型;
- 在训练过程中,通过蒙皮继承策略(binding inheritance strategy)控制3DGS增删后与三角面片的对应关系。
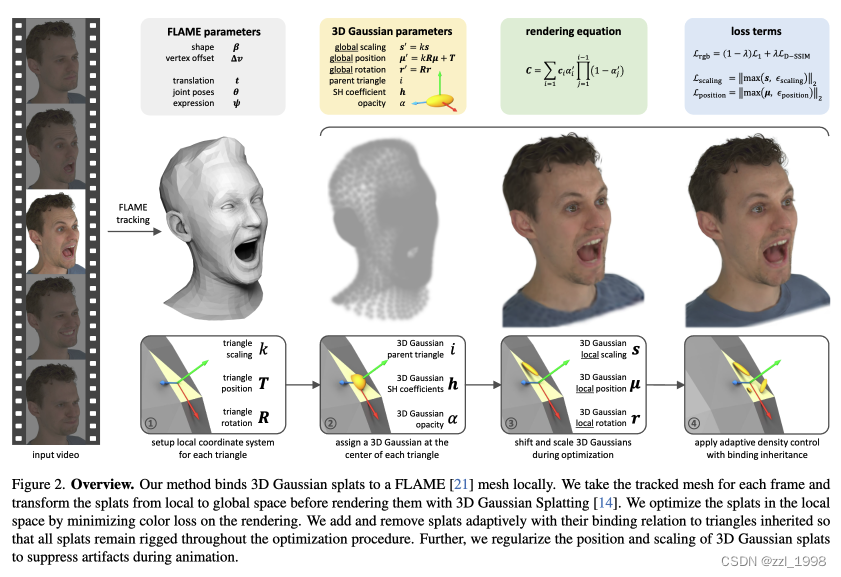
绑定3DGS与三角面片
给定三角面片,本文计算:
- 均值位置
:给定三角面片的三条边,计算对应的均值位置;
- 构造旋转矩阵
:1)三角面片的某条边;2)三角面片的法向向量;3)与前两者垂直的第三边;
- 放缩变量
:通过三角形中一条边及其垂线的平均长度来计算标量
对于对应的3DGS,在局部空间定义其位置,旋转矩阵
,各向异性缩放系数
。
- 初始化时,
为局部零点位置,
为单位旋转矩阵,
为单位矢量。
- 渲染时,将其从局部空间转换为全局空间:

本文将三角面片的缩放系数,嵌入到公式5和6中,使得3DGS的局部位置和缩放与三角面片的缩放相关。这使得全局定义的学习率可以适用于局部。
蒙皮继承策略
- 稠密:对于具有较大view-space positional gradient的3DGS,如果该点较大则拆分为两个,如果较小则复制一个新的;确保新3DGS和旧的足够近,这样可以将新点绑定至旧点对应的三角面片;
- 剪枝:在3DGS原有剪枝的技术上,确保每个三角面片具有至少一个3DGS。有些脸部区域(眼球)常被遮挡,很有可能由于剪枝,导致眼球部分的3DGS被去掉。
优化和正则
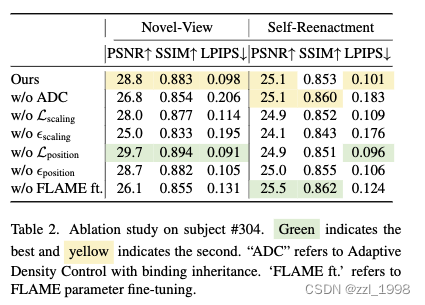
- 渲染图像损失如下,可以保证对已有场景有不错效果,但是对新表情和位置效果不佳(存在spike和blob伪影)
![]()
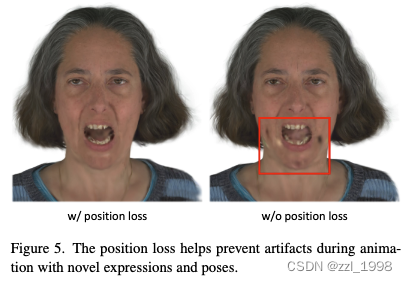
具有阈值的位置损失(Position loss with threshold)
在蒙皮继承策略中,本文通过拆分和复制增加新的3DGS。理想情况下,新增的3DGS应该与面片相邻。但是经过优化后,无法保证他们相邻。为解决该问题,本文引入了位置正则项:
![]()
,确保3DGS和它的父亲三角面片足够近。
具有阈值的放缩损失(Scaling loss with threshold)
如果某个3DGS相较于它的父亲三角面片更大,三角面片的小角度旋转,会在3DGS上被放大,导致伪影。为解决该问题,本文引入了放缩正则项:
![]()
,确保3DGS不会太大。
最终损失
![]()
其中,和
。这两项确保常被遮挡的区域(眼球、牙齿)可以被保留。
实现细节
- Adam,位置学习率为5e-3,放缩学习率为1.7e-2;
- 除了3DGS,FLAME的translation、joint rotation和表情系数也会fine-tune,学习率分别为:1e-6,1e-5和1e-3。
- 训练600k iters,从10k iters之后,每2k iters执行3DGS的更新和蒙皮继承策略,每60k iters,重新设置3DGS的不透明度。
实验
- 数据集:NeRSemble数据集上的9个目标,每个目标包含10种表情和16个视角。
- 测试:1)新视角生成(novel-view synthesis);2)自重演(self-reenactment);3)跨ID重演(cross-identity reenactment)。
数字人重建



消融实验