目录
Kafka 下载
(1)将 kafka_2.11-2.4.1.tgz 上传至 /opt/software/
(2)解压安装包至 /opt/module/
[huwei@hadoop101 ~]$ cd /opt/software/
[huwei@hadoop101 software]$ tar -zxvf kafka_2.11-2.4.1.tgz -C ../module/(3)配置环境变量
[huwei@hadoop101 software]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
# KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin
使得环境变量生效
[huwei@hadoop101 software]$ source /etc/profile
(4)在 kafka 目录下创建 datas 文件夹
[huwei@hadoop101 software]$ cd ../module/kafka_2.11-2.4.1/
[huwei@hadoop101 kafka_2.11-2.4.1]$ mkdir datas
(5)修改配置文件
[huwei@hadoop101 software]$ cd /opt/module/kafka_2.11-2.4.1/config/
[huwei@hadoop101 config]$ vim server.properties
这里 broker id 就使用默认的 0,不修改

修改 kafka 数据的存放位置(默认存储7天)
kafka 本身的运行日志会存放在kafka目录下的 logs 文件夹下
log.dirs=/opt/module/kafka_2.11-2.4.1/datas

配置连接Zookeeper集群地址
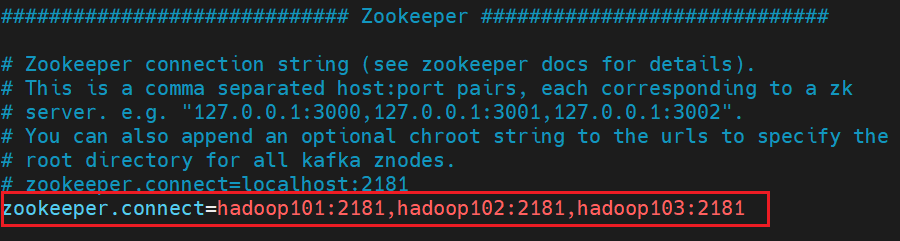
(6)向其他机器分发 kafka
这里我使用的是我前面 大数据技术学习笔记(三)—— Hadoop 的运行模式中写过的集群分发脚本
xsync
[huwei@hadoop101 module]$ xsync kafka_2.11-2.4.1/
(7)修改其他机器中的 broker id
分别在 hadoop102 和 hadoop103 上修改配置文件 /opt/module/kafka/config/server.properties 中的broker.id=1、broker.id=2
注:
broker.id不得重复
(8)分发系统环境变量
[huwei@hadoop101 module]$ sudo xsync /etc/profile.d/my_env.sh
然后分别使得其他机器上的环境变量生效
[huwei@hadoop102 ~]$ source /etc/profile
[huwei@hadoop103 ~]$ source /etc/profile
(9)启动 Kafka 集群
先启动 Zookeeper 集群
[huwei@hadoop101 module]$ [huwei@hadoop101 module]$ zk_cluster.sh start
这里使用的是我在 Zookeeper 安装与部署 中编写的群起Zookeeper 集群的脚本
依次在 hadoop101、hadoop102、hadoop103 节点上启动 kafka
[huwei@hadoop101 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
[huwei@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
[huwei@hadoop103 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
(10)停止集群
[huwei@hadoop101 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
[huwei@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
[huwei@hadoop103 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
(11)群起集群脚本
新建脚本 kafka_cluster.sh
[huwei@hadoop101 ~]$ cd bin
[huwei@hadoop101 bin]$ vim kafka_cluster.sh
编写如下内容
#!/bin/bash
if [ $# -lt 1 ]
then echo "Input Args Error....."exit
fi
for i in hadoop101 hadoop102 hadoop103
docase $1 in
start)echo "==================START $i KAFKA==================="ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties
;;
stop)echo "==================STOP $i KAFKA==================="ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-stop.sh stop
;;*)echo "Input Args Error....."exit
;;
esac
done
保存退出
给该脚本赋予执行权限
[huwei@hadoop101 bin]$ chmod u+x kafka_cluster.sh
群起集群
[huwei@hadoop101 bin]$ kafka_cluster.sh start
群停集群
[huwei@hadoop101 bin]$ kafka_cluster.sh stop
注意,停止集群的时候,也要先停止kafka,再停止zookeeper








![详解—C++ [异常]](https://img-blog.csdnimg.cn/direct/a6c938f57af54fe8a52422eb0fb9f79f.png)