一、本文介绍
本文带来的改进机制是YOLOv5模型与多元分支模块(Diverse Branch Block)的结合,Diverse Branch Block (DBB) 是一种用于增强卷积神经网络性能的结构重新参数化技术。这种技术的核心在于结合多样化的分支,这些分支具有不同的尺度和复杂度,从而丰富特征空间。我将其放在了YOLOv5的不同位置上均有一定的涨点幅度,同时这个DBB模块的参数量并不会上涨太多,我添加三个该机制到模型中,GFLOPs上涨了0.04。
推荐指数:⭐⭐⭐⭐
打星原因:为什么打四颗星是因为我觉得这个机制的计算量会上涨,这是扣分点,其次涨幅效果也比较一般但是有涨点,当然可能是数据集的原因毕竟不同的数据集效果不同
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
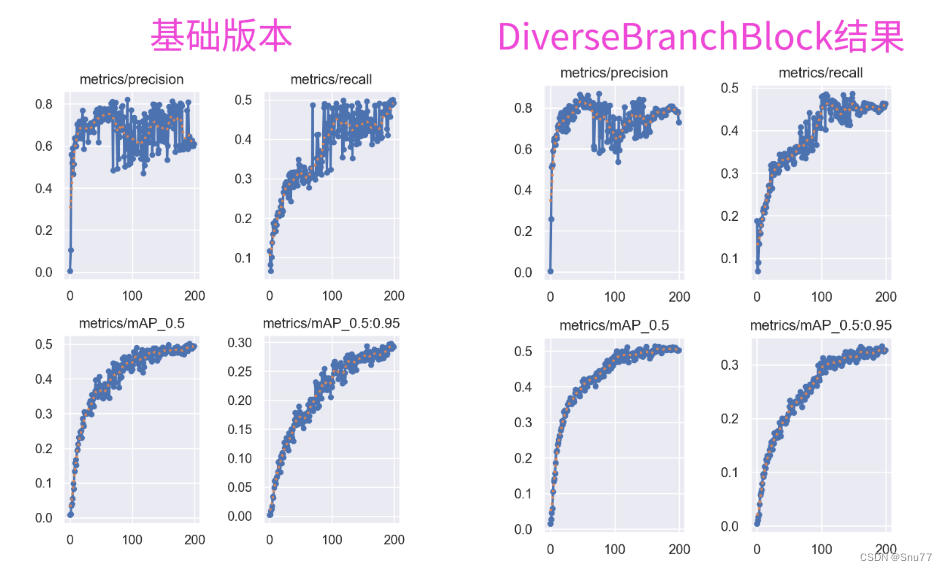
训练结果对比图->
目录
一、本文介绍
二、Diverse Branch Block原理
2.1 Diverse Branch Block的基本原理
2.2 多样化分支结构
2.3 训练与推理分离
2.4 宏观架构不变
三、Diverse Branch Block的完整代码
四、手把手教你添加Diverse Branch Block机制
4.1 细节修改教程
4.1.1 修改一
4.1.2 修改二
4.1.3 修改三
4.1.4 修改四
4.2 DBB的yaml文件(仔细看这个否则会报错)
4.2.1 DBB的yaml文件一
4.2.2 DBB的yaml文件二
4.2.3 DBB的yaml文件三
4.3 DBB运行成功截图
4.4 推荐Diverse Branch Block可添加的位置
五、本文总结
二、Diverse Branch Block原理

论文地址:论文官方地址
代码地址:官方代码地址

2.1 Diverse Branch Block的基本原理
Diverse Branch Block(DBB)的基本原理是在训练阶段增加卷积层的复杂性,通过引入不同尺寸和结构的卷积分支来丰富网络的特征表示能力。我们可以将基本原理可以概括为以下几点:
1. 多样化分支结构:DBB 结合了不同尺度和复杂度的分支,如不同大小的卷积核和平均池化,以增加单个卷积的特征表达能力。
2. 训练与推理分离:在训练阶段,DBB 采用复杂的分支结构,而在推理阶段,这些分支可以被等效地转换为单个卷积层,以保持高效推理。
3. 宏观架构不变:DBB 允许在不改变整体网络架构的情况下,作为常规卷积层的替代品插入到现有网络中。
下面我将为大家展示Diverse Branch Block(DBB)的设计示例:
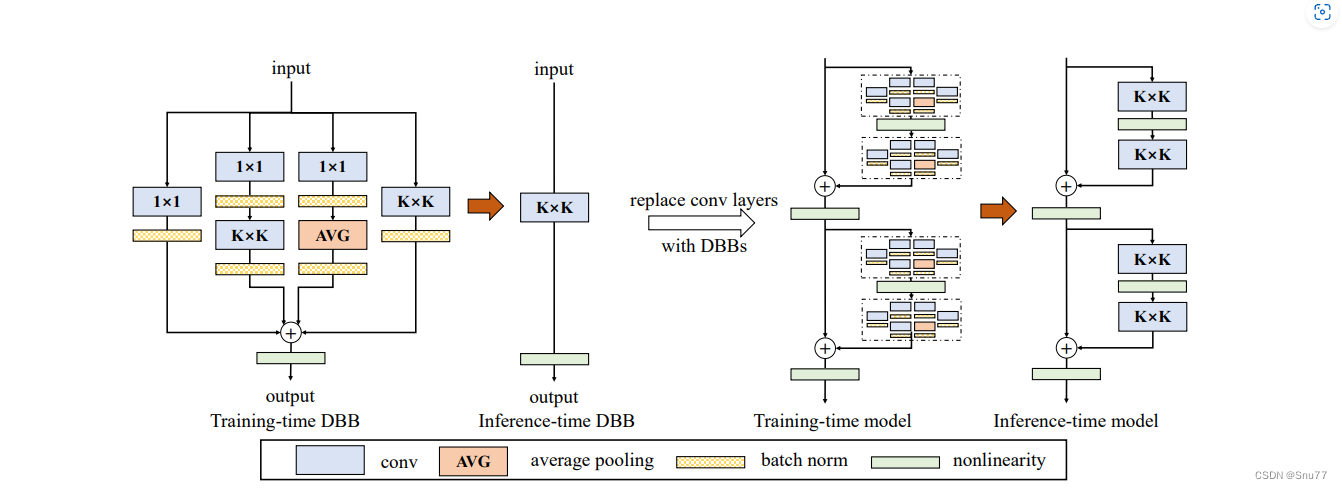
在训练时(左侧),DBB由不同大小的卷积层和平均池化层组成,这些层以一种复杂的方式并行排列,并最终合并输出。训练完成后,这些复杂的结构会转换成单个卷积层,用于模型的推理阶段(右侧),以此保持推理时的效率。这种转换允许DBB在保持宏观架构不变的同时,增加训练时的微观结构复杂性。
2.2 多样化分支结构
多样化分支结构是在卷积神经网络中引入的一种结构,旨在通过多样化的分支来增强模型的特征提取能力。这些分支包含不同尺寸的卷积层和池化层,以及其他潜在的操作,它们并行工作以捕获不同的特征表示。在训练完成后,这些复杂的结构可以合并并简化为单个的卷积层,以便在推理时不增加额外的计算负担。这种设计使得DBB可以作为现有卷积层的直接替换,增强了现有网络架构的性能,而不需要修改整体架构。
下面我详细展示了如何通过六种转换方法将训练时的Diverse Branch Block(DBB)转换为推理时的常规卷积层,每一种转换对应于一种特定的操作:

1. Transform I:将具有批量规范化(batch norm)的卷积层融合。
2. Transform II:合并具有相同配置的卷积层的输出。
3. Transform III:合并序列卷积层。
4. Transform IV:通过深度串联(concat)来合并卷积层。
5. Transform V:将平均池化(AVG)操作融入卷积操作中。
6. Transform VI:结合不同尺度的卷积层。
可以看到右侧的框显示了经过这些转换后,可以实现的推理时DBB,其中包含了常规卷积、平均池化和批量规范化操作。这些转换确保了在不增加推理时负担的同时,能够在训练时利用DBB的多样化特征提取能力。
2.3 训练与推理分离
训练与推理分离的概念是指在模型训练阶段使用复杂的DBB结构,而在模型推理阶段则转换为简化的卷积结构。这种设计允许模型在训练时利用DBB的多样性来增强特征提取和学习能力,而在实际应用中,即推理时,通过减少计算量来保持高效。这样,模型在保持高性能的同时,也保证了运行速度和资源效率。
上面我将展示在训练阶段如何通过不同的卷积组合(如图中的1x1和KxK卷积),以及在推理阶段如何将这些组合转换成一个简化的结构(如图中的转换IV所示的拼接操作):
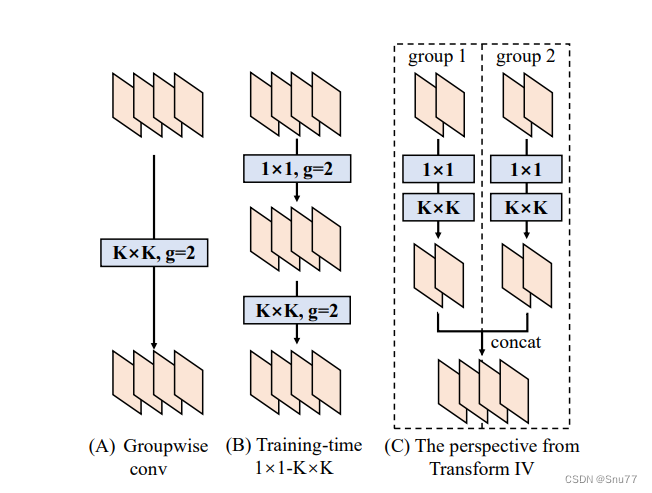
经过分析,我们可以发现它说明了三种不同的情况:
A)组卷积(Groupwise conv):将输入分成多个组,每个组使用不同的卷积核。
B)训练时的1x1-KxK结构:首先应用1x1的卷积(减少特征维度),然后是分组的KxK卷积。
C)从转换IV的角度看:这是将多个分组的卷积输出合并的视角。这里,组内卷积后的特征图先分别通过1x1卷积处理,然后再进行拼接(concat)。
2.4 宏观架构不变
宏观架构不变指的是DBB在设计时考虑到了与现有的网络架构兼容性,确保可以在不改变整体网络架构(如ResNet等流行架构)的前提下,将DBB作为一个模块嵌入。这意味着DBB增强了网络的特征提取能力,同时保持了原有网络结构的布局,确保了推理时的效率和性能。这样的设计允许研究者和开发者将DBB直接应用到现有的深度学习模型中,而无需进行大规模的架构调整。
三、Diverse Branch Block的完整代码
我们找到如下的目录'yolov5-master/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from ..common import Conv, autopaddef transI_fusebn(kernel, bn):gamma = bn.weightstd = (bn.running_var + bn.eps).sqrt()return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / stddef transII_addbranch(kernels, biases):return sum(kernels), sum(biases)def transIII_1x1_kxk(k1, b1, k2, b2, groups):if groups == 1:k = F.conv2d(k2, k1.permute(1, 0, 2, 3)) #b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3))else:k_slices = []b_slices = []k1_T = k1.permute(1, 0, 2, 3)k1_group_width = k1.size(0) // groupsk2_group_width = k2.size(0) // groupsfor g in range(groups):k1_T_slice = k1_T[:, g * k1_group_width:(g + 1) * k1_group_width, :, :]k2_slice = k2[g * k2_group_width:(g + 1) * k2_group_width, :, :, :]k_slices.append(F.conv2d(k2_slice, k1_T_slice))b_slices.append((k2_slice * b1[g * k1_group_width:(g + 1) * k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3)))k, b_hat = transIV_depthconcat(k_slices, b_slices)return k, b_hat + b2def transIV_depthconcat(kernels, biases):return torch.cat(kernels, dim=0), torch.cat(biases)def transV_avg(channels, kernel_size, groups):input_dim = channels // groupsk = torch.zeros((channels, input_dim, kernel_size, kernel_size))k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2return k# This has not been tested with non-square kernels (kernel.size(2) != kernel.size(3)) nor even-size kernels
def transVI_multiscale(kernel, target_kernel_size):H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2return F.pad(kernel, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad])def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,padding_mode='zeros'):conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups,bias=False, padding_mode=padding_mode)bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True)se = nn.Sequential()se.add_module('conv', conv_layer)se.add_module('bn', bn_layer)return seclass IdentityBasedConv1x1(nn.Conv2d):def __init__(self, channels, groups=1):super(IdentityBasedConv1x1, self).__init__(in_channels=channels, out_channels=channels, kernel_size=1, stride=1,padding=0, groups=groups, bias=False)assert channels % groups == 0input_dim = channels // groupsid_value = np.zeros((channels, input_dim, 1, 1))for i in range(channels):id_value[i, i % input_dim, 0, 0] = 1self.id_tensor = torch.from_numpy(id_value).type_as(self.weight)nn.init.zeros_(self.weight)def forward(self, input):kernel = self.weight + self.id_tensor.to(self.weight.device).type_as(self.weight)result = F.conv2d(input, kernel, None, stride=1, padding=0, dilation=self.dilation, groups=self.groups)return resultdef get_actual_kernel(self):return self.weight + self.id_tensor.to(self.weight.device)class BNAndPadLayer(nn.Module):def __init__(self,pad_pixels,num_features,eps=1e-5,momentum=0.1,affine=True,track_running_stats=True):super(BNAndPadLayer, self).__init__()self.bn = nn.BatchNorm2d(num_features, eps, momentum, affine, track_running_stats)self.pad_pixels = pad_pixelsdef forward(self, input):output = self.bn(input)if self.pad_pixels > 0:if self.bn.affine:pad_values = self.bn.bias.detach() - self.bn.running_mean * self.bn.weight.detach() / torch.sqrt(self.bn.running_var + self.bn.eps)else:pad_values = - self.bn.running_mean / torch.sqrt(self.bn.running_var + self.bn.eps)output = F.pad(output, [self.pad_pixels] * 4)pad_values = pad_values.view(1, -1, 1, 1)output[:, :, 0:self.pad_pixels, :] = pad_valuesoutput[:, :, -self.pad_pixels:, :] = pad_valuesoutput[:, :, :, 0:self.pad_pixels] = pad_valuesoutput[:, :, :, -self.pad_pixels:] = pad_valuesreturn output@propertydef weight(self):return self.bn.weight@propertydef bias(self):return self.bn.bias@propertydef running_mean(self):return self.bn.running_mean@propertydef running_var(self):return self.bn.running_var@propertydef eps(self):return self.bn.epsclass DiverseBranchBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size,stride=1, padding=None, dilation=1, groups=1,internal_channels_1x1_3x3=None,deploy=False, single_init=False):super(DiverseBranchBlock, self).__init__()self.deploy = deployself.nonlinear = Conv.default_actself.kernel_size = kernel_sizeself.out_channels = out_channelsself.groups = groupsif padding is None:padding = autopad(kernel_size, padding, dilation)assert padding == kernel_size // 2if deploy:self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True)else:self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups)self.dbb_avg = nn.Sequential()if groups < out_channels:self.dbb_avg.add_module('conv',nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,stride=1, padding=0, groups=groups, bias=False))self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=out_channels))self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,padding=0, groups=groups)else:self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding))self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))if internal_channels_1x1_3x3 is None:internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channelsself.dbb_1x1_kxk = nn.Sequential()if internal_channels_1x1_3x3 == in_channels:self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=groups))else:self.dbb_1x1_kxk.add_module('conv1',nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3,kernel_size=1, stride=1, padding=0, groups=groups, bias=False))self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=internal_channels_1x1_3x3,affine=True))self.dbb_1x1_kxk.add_module('conv2',nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels,kernel_size=kernel_size, stride=stride, padding=0, groups=groups,bias=False))self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))# The experiments reported in the paper used the default initialization of bn.weight (all as 1). But changing the initialization may be useful in some cases.if single_init:# Initialize the bn.weight of dbb_origin as 1 and others as 0. This is not the default setting.self.single_init()def get_equivalent_kernel_bias(self):k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)if hasattr(self, 'dbb_1x1'):k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)else:k_1x1, b_1x1 = 0, 0if hasattr(self.dbb_1x1_kxk, 'idconv1'):k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()else:k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weightk_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second,b_1x1_kxk_second, groups=self.groups)k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device),self.dbb_avg.avgbn)if hasattr(self.dbb_avg, 'conv'):k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight, self.dbb_avg.bn)k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second,b_1x1_avg_second, groups=self.groups)else:k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_secondreturn transII_addbranch((k_origin, k_1x1, k_1x1_kxk_merged, k_1x1_avg_merged),(b_origin, b_1x1, b_1x1_kxk_merged, b_1x1_avg_merged))def switch_to_deploy(self):if hasattr(self, 'dbb_reparam'):returnkernel, bias = self.get_equivalent_kernel_bias()self.dbb_reparam = nn.Conv2d(in_channels=self.dbb_origin.conv.in_channels,out_channels=self.dbb_origin.conv.out_channels,kernel_size=self.dbb_origin.conv.kernel_size, stride=self.dbb_origin.conv.stride,padding=self.dbb_origin.conv.padding, dilation=self.dbb_origin.conv.dilation,groups=self.dbb_origin.conv.groups, bias=True)self.dbb_reparam.weight.data = kernelself.dbb_reparam.bias.data = biasfor para in self.parameters():para.detach_()self.__delattr__('dbb_origin')self.__delattr__('dbb_avg')if hasattr(self, 'dbb_1x1'):self.__delattr__('dbb_1x1')self.__delattr__('dbb_1x1_kxk')def forward(self, inputs):if hasattr(self, 'dbb_reparam'):return self.nonlinear(self.dbb_reparam(inputs))out = self.dbb_origin(inputs)if hasattr(self, 'dbb_1x1'):out += self.dbb_1x1(inputs)out += self.dbb_avg(inputs)out += self.dbb_1x1_kxk(inputs)return self.nonlinear(out)def init_gamma(self, gamma_value):if hasattr(self, "dbb_origin"):torch.nn.init.constant_(self.dbb_origin.bn.weight, gamma_value)if hasattr(self, "dbb_1x1"):torch.nn.init.constant_(self.dbb_1x1.bn.weight, gamma_value)if hasattr(self, "dbb_avg"):torch.nn.init.constant_(self.dbb_avg.avgbn.weight, gamma_value)if hasattr(self, "dbb_1x1_kxk"):torch.nn.init.constant_(self.dbb_1x1_kxk.bn2.weight, gamma_value)def single_init(self):self.init_gamma(0.0)if hasattr(self, "dbb_origin"):torch.nn.init.constant_(self.dbb_origin.bn.weight, 1.0)class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = DiverseBranchBlock(c_, c2, 3, 1, groups=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3_DBB(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))四、手把手教你添加Diverse Branch Block机制
4.1 细节修改教程
4.1.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。

4.1.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。

4.1.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加。)

4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->

到此就修改完成了,复制下面的ymal文件即可运行。
4.2 DBB的yaml文件(仔细看这个否则会报错)
4.2.1 DBB的yaml文件一
下面的配置文件为我修改的DBB的位置,参数的位置里面什么都不用添加空着就行,大家复制粘贴我的就可以运行,同时我提供多个版本给大家,根据我的经验可能涨点的位置。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3_DBB, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3_DBB, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3_DBB, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
4.2.2 DBB的yaml文件二
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3_DBB, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3_DBB, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3_DBB, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3_DBB, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3_DBB, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3_DBB, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3_DBB, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
4.2.3 DBB的yaml文件三
注意此版本的我再大目标,小目标,中目标三个曾的后面添加了一个注意力机制,此版本需要显存较大,可以根据自己的需求增删,如果修改大家要注意修改Detect里面的检测层数。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, DiverseBranchBlock, []], # 18[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 21 (P4/16-medium)[-1, 1, DiverseBranchBlock, []], # 22[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 25 (P5/32-large)[-1, 1, DiverseBranchBlock, []], # 26[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]4.3 DBB运行成功截图
附上我的运行记录确保我的教程是可用的。

4.4 推荐Diverse Branch Block可添加的位置
Diverse Branch Block是一种即插即用的可替换卷积的模块,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入Diverse Branch Block(yaml文件一)。
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加修改后的C3_DBB可以帮助模型更有效地融合不同层次的特征(yaml文件二)。
检测头:可以再检测头前面添加(yaml文件三)
检测头中:可以再检测头的内部添加该机制(未提供因为需要修改检测头比较麻烦,后期专栏收费后大家购买专栏之后大家会得到一个包含上百个机制的v5文件里面包含所有的改进机制)
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新