1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
近年来,随着智能制造产业的不断发展,基于人工智能与机器视觉的自动化产品缺陷检测技术在各行各业中得到了广泛应用。磁瓦作为永磁电机的主要组成部分,其质量的好坏直接影响着永磁电机的使用寿命和工作性能。目前在大多数磁瓦生产过程中,对磁瓦质量的检测仍以人工目视检测为主,这种检测方式存在检测效率低、检测标准不统一、人工成本高等问题。此外,由于磁瓦表面缺陷种类较多,表面纹理复杂且对比度较低,传统的视觉检测与图像处理技术很难对磁瓦表面缺陷进行准确检测与分类,因此研究一种适合磁瓦的自动化缺陷检测及分类方法对于磁瓦的生产具有十分重要的意义。 机器视觉与图像处理作为人工智能领域的重要研究内容,主要通过卷积神经网络对图像数据的特征进行提取与学习,获取图像所含信息,进一步对图像进行处理。目前,将机器视觉与图像处理技术应用于磁瓦缺陷检测问题的研究,已取得了一定成果。本文针对目前磁瓦缺陷检测方法中存在的不足展开研究
2.图片演示



3.视频演示
【改进YOLOv8】磁瓦缺陷分类系统:改进LSKNet骨干网络的YOLOv8_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集CWDatasets。
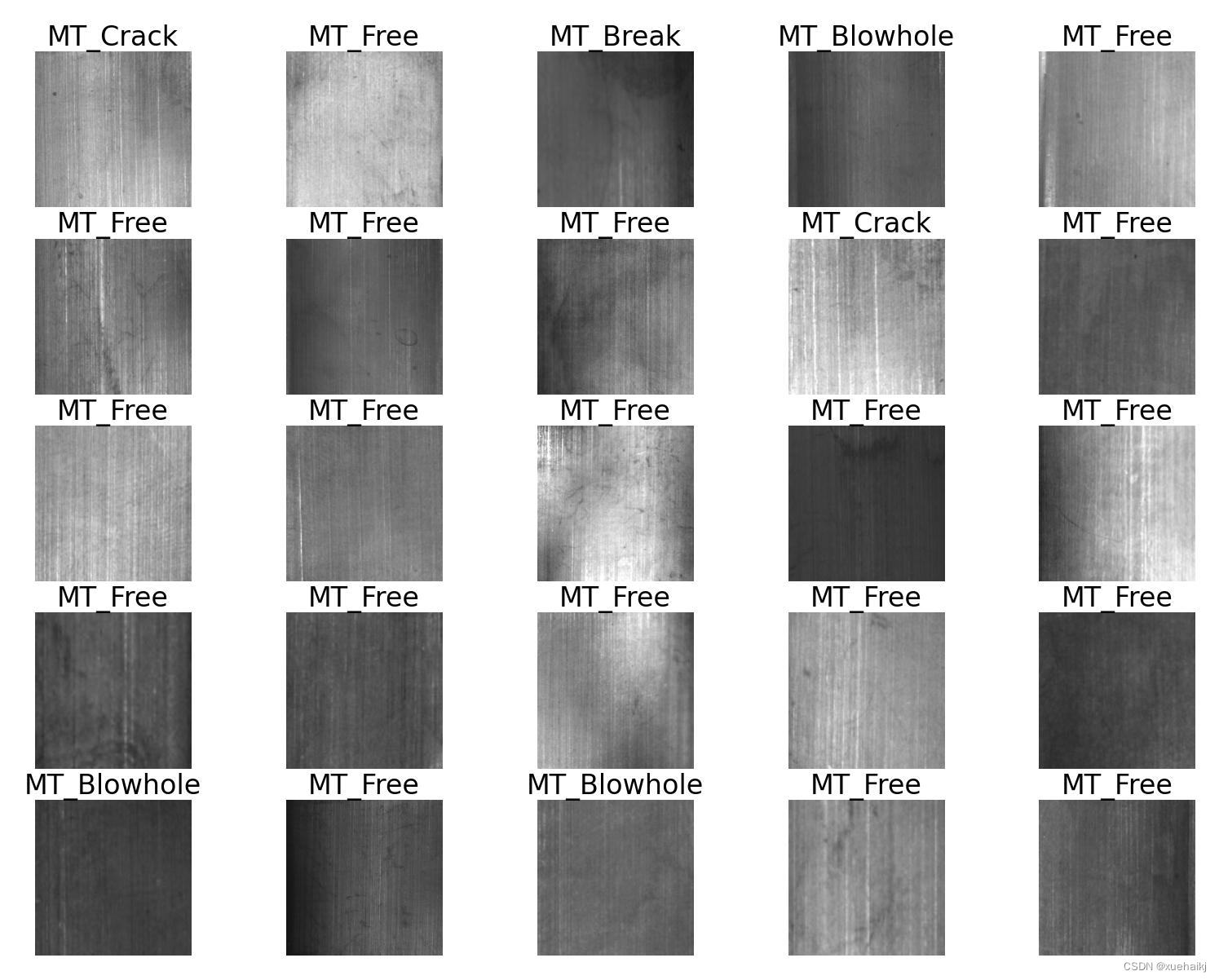
下面是一个简单的方法是使用Python脚本,该脚本读取分类图片文件,然后将其转换为所需的格式。
import os
import shutil
import random# 指定输入和输出文件夹的路径
input_dir = 'train'
output_dir = 'output'# 确保输出文件夹存在
if not os.path.exists(output_dir):os.makedirs(output_dir)# 遍历输入文件夹中的所有子文件夹
for subdir in os.listdir(input_dir):input_subdir_path = os.path.join(input_dir, subdir)# 确保它是一个子文件夹if os.path.isdir(input_subdir_path):output_subdir_path = os.path.join(output_dir, subdir)# 在输出文件夹中创建同名的子文件夹if not os.path.exists(output_subdir_path):os.makedirs(output_subdir_path)# 获取所有文件的列表files = [f for f in os.listdir(input_subdir_path) if os.path.isfile(os.path.join(input_subdir_path, f))]# 随机选择四分之一的文件files_to_move = random.sample(files, len(files) // 4)# 移动文件for file_to_move in files_to_move:src_path = os.path.join(input_subdir_path, file_to_move)dest_path = os.path.join(output_subdir_path, file_to_move)shutil.move(src_path, dest_path)print("任务完成!")整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----dataset-----dataset|-----train| |-----class1| |-----class2| |-----.......||-----valid| |-----class1| |-----class2| |-----.......||-----test| |-----class1| |-----class2| |-----.......模型训练
Epoch gpu_mem box obj cls labels img_size1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]all 3395 17314 0.994 0.957 0.0957 0.0843Epoch gpu_mem box obj cls labels img_size2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]all 3395 17314 0.996 0.956 0.0957 0.0845Epoch gpu_mem box obj cls labels img_size3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_firstclass DetectionTrainer(BaseTrainer):def build_dataset(self, img_path, mode='train', batch=None):gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):assert mode in ['train', 'val']with torch_distributed_zero_first(rank):dataset = self.build_dataset(dataset_path, mode, batch_size)shuffle = mode == 'train'if getattr(dataset, 'rect', False) and shuffle:LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")shuffle = Falseworkers = 0return build_dataloader(dataset, batch_size, workers, shuffle, rank)def preprocess_batch(self, batch):batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255return batchdef set_model_attributes(self):self.model.nc = self.data['nc']self.model.names = self.data['names']self.model.args = self.argsdef get_model(self, cfg=None, weights=None, verbose=True):model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)if weights:model.load(weights)return modeldef get_validator(self):self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))def label_loss_items(self, loss_items=None, prefix='train'):keys = [f'{prefix}/{x}' for x in self.loss_names]if loss_items is not None:loss_items = [round(float(x), 5) for x in loss_items]return dict(zip(keys, loss_items))else:return keysdef progress_string(self):return ('\n' + '%11s' *(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')def plot_training_samples(self, batch, ni):plot_images(images=batch['img'],batch_idx=batch['batch_idx'],cls=batch['cls'].squeeze(-1),bboxes=batch['bboxes'],paths=batch['im_file'],fname=self.save_dir / f'train_batch{ni}.jpg',on_plot=self.on_plot)def plot_metrics(self):plot_results(file=self.csv, on_plot=self.on_plot)def plot_training_labels(self):boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)if __name__ == '__main__':args = dict(model='./yolov8-ContextGuidedDown.yaml', data='coco8.yaml', epochs=100)trainer = DetectionTrainer(overrides=args)trainer.train()
该程序文件是一个用于训练基于检测模型的程序。它使用Ultralytics YOLO库进行训练。
该文件定义了一个名为DetectionTrainer的类,它是BaseTrainer类的子类。DetectionTrainer类用于构建和训练YOLO检测模型。
该文件还定义了一些辅助函数,用于构建数据集、构建数据加载器、预处理批次数据等。
在main函数中,首先定义了一些参数,然后创建了一个DetectionTrainer对象,并调用其train方法开始训练。
5.2 backbone\revcol.py
import torch
import torch.nn as nnclass RevCol(nn.Module):def __init__(self, kernel='C2f', channels=[32, 64, 96, 128], layers=[2, 3, 6, 3], num_subnet=5, save_memory=True) -> None:super().__init__()self.num_subnet = num_subnetself.channels = channelsself.layers = layersself.stem = Conv(3, channels[0], k=4, s=4, p=0)for i in range(num_subnet):first_col = True if i == 0 else Falseself.add_module(f'subnet{str(i)}', SubNet(channels, layers, kernel, first_col, save_memory=save_memory))self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward(self, x):c0, c1, c2, c3 = 0, 0, 0, 0x = self.stem(x) for i in range(self.num_subnet):c0, c1, c2, c3 = getattr(self, f'subnet{str(i)}')(x, c0, c1, c2, c3) return [c0, c1, c2, c3]
该程序文件名为backbone\revcol.py,是一个用于深度学习的神经网络模型的实现。该文件包含了多个模块和函数,用于定义和操作神经网络的各个组件。
该文件中定义了以下模块和函数:
RevCol类:该类是整个神经网络模型的主要部分,包含了多个子网络(SubNet)和一个初始卷积层(stem)。该类的前向传播方法定义了整个神经网络的前向传播过程。SubNet类:该类是神经网络的子网络,包含了多个级别(Level)和一个反向传播函数(_forward_reverse)。该类的前向传播方法定义了子网络的前向传播过程。Level类:该类是神经网络的级别,包含了一个融合层(fusion)和多个卷积层(blocks)。该类的前向传播方法定义了级别的前向传播过程。Fusion类:该类是级别的融合层,根据级别的不同选择不同的融合方式。该类的前向传播方法定义了融合层的前向传播过程。ReverseFunction类:该类是一个自定义的反向传播函数,用于实现反向传播过程中的特殊操作。该类的前向传播方法定义了反向传播函数的前向传播过程,后向传播方法定义了反向传播函数的反向传播过程。- 其他辅助函数和工具函数:包括获取GPU状态、设置设备状态、分离和梯度等。
总体来说,该程序文件实现了一个具有多个级别和子网络的神经网络模型,用于进行深度学习任务。
5.3 backbone\SwinTransformer.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from timm.models.layers import DropPath, to_2tuple, trunc_normal_class Mlp(nn.Module):""" Multilayer perceptron."""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xdef window_partition(x, window_size):"""Args:x: (B, H, W, C)window_size (int): window sizeReturns:windows: (num_windows*B, window_size, window_size, C)"""B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size, H, W):"""Args:windows: (num_windows*B, window_size, window_size, C)window_size (int): Window sizeH (int): Height of imageW (int): Width of imageReturns:x: (B, H, W, C)"""B = int(windows.shape[0] / (H * W / window_size / window_size))x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass WindowAttention(nn.Module):""" Window based multi-head self attention (W-MSA) module with relative position bias.It supports both of shifted and non-shifted window.Args:dim (int): Number of input channels.window_size (tuple[int]): The height and width of the window.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if setattn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0proj_drop (float, optional): Dropout ratio of output. Default: 0.0"""def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk
该程序文件是一个用于实现Swin Transformer模型的Python文件。Swin Transformer是一种基于窗口注意力机制的Transformer模型,用于图像分类任务。
该文件定义了以下几个类:
- Mlp:多层感知机模块,用于特征的线性变换和非线性激活。
- window_partition:将输入特征划分为窗口。
- window_reverse:将划分的窗口恢复为原始特征。
- WindowAttention:基于窗口的多头自注意力模块,支持相对位置偏置。
- SwinTransformerBlock:Swin Transformer的基本模块,包括窗口注意力和多层感知机。
- PatchMerging:用于将特征图像素合并的模块。
- BasicLayer:Swin Transformer的一个阶段,包含多个Swin Transformer模块和特征图像素合并。
这些类的实现组成了Swin Transformer模型的基本组件,可以通过组合这些组件来构建完整的Swin Transformer模型。
5.4 backbone\VanillaNet.py
import torch
import torch.nn as nn
from timm.layers import weight_initclass activation(nn.ReLU):def __init__(self, dim, act_num=3, deploy=False):super(activation, self).__init__()self.deploy = deployself.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num*2 + 1, act_num*2 + 1))self.bias = Noneself.bn = nn.BatchNorm2d(dim, eps=1e-6)self.dim = dimself.act_num = act_numweight_init.trunc_normal_(self.weight, std=.02)def forward(self, x):if self.deploy:return torch.nn.functional.conv2d(super(activation, self).forward(x), self.weight, self.bias, padding=(self.act_num*2 + 1)//2, groups=self.dim)else:return self.bn(torch.nn.functional.conv2d(super(activation, self).forward(x),self.weight, padding=self.act_num
该程序文件名为backbone\VanillaNet.py,是一个用于构建VanillaNet模型的Python代码文件。
该文件定义了以下类和函数:
- activation类:继承自nn.ReLU类,用于定义激活函数。
- Block类:继承自nn.Module类,用于定义模型的基本块。
- VanillaNet类:继承自nn.Module类,用于定义整个VanillaNet模型。
- update_weight函数:用于更新模型的权重。
- vanillanet_5函数:用于构建VanillaNet-5模型。
- vanillanet_6函数:用于构建VanillaNet-6模型。
- vanillanet_7函数:用于构建VanillaNet-7模型。
- vanillanet_8函数:用于构建VanillaNet-8模型。
- vanillanet_9函数:用于构建Vanilla
6.系统整体结构
下表总结了每个文件的功能:
| 文件名 | 功能 |
|---|---|
| train.py | 训练分类模型的主要脚本,包括模型定义、数据加载、训练循环等 |
| backbone/lsknet.py | 实现LSKNet骨干网络的模型定义 |
| backbone/repvit.py | 实现RepVIT骨干网络的模型定义 |
| backbone/revcol.py | 实现RevCol骨干网络的模型定义 |
| backbone/SwinTransformer.py | 实现Swin Transformer骨干网络的模型定义 |
| backbone/VanillaNet.py | 实现VanillaNet骨干网络的模型定义 |
| classify/predict.py | 实现分类模型的推理脚本,包括加载模型、预处理数据、进行推理和后处理等 |
| classify/train.py | 实现分类模型的训练脚本,包括模型定义、数据加载、训练循环等 |
| classify/val.py | 实现分类模型的验证脚本,用于评估模型在验证集上的性能 |
| extra_modules/head.py | 实现模型的头部部分,用于分类任务的输出 |
| extra_modules/kernel_warehouse.py | 存储模型的卷积核参数 |
| extra_modules/orepa.py | 实现OREPA模块,用于增强模型的表达能力 |
| extra_modules/rep_block.py | 实现REP Block模块,用于增强模型的表达能力 |
| extra_modules/RFAConv.py | 实现RFAConv模块,用于增强模型的感受野 |
| models/common.py | 包含一些通用的模型操作函数 |
| models/experimental.py | 包含一些实验性的模型定义 |
| models/tf.py | 包含一些与TensorFlow相关的模型操作函数 |
| models/yolo.py | 包含YOLO模型的定义和相关操作函数 |
| ultralytics/* | 包含Ultralytics库的各个模块和功能 |
| utils/* | 包含一些通用的工具函数和辅助函数 |
| utils/aws/* | 包含与AWS相关的工具函数 |
| utils/flask_rest_api/* | 包含使用Flask构建REST API的相关工具函数 |
| utils/loggers/* | 包含不同日志记录器的实现,如ClearML、Comet、WandB等 |
| utils/segment/* | 包含用于图像分割任务的工具函数 |
| utils/activations.py | 包含一些激活函数的实现 |
| utils/augmentations.py | 包含一些数据增强的实现 |
| utils/autoanchor.py | 包含自动锚框生成的实现 |
| utils/callbacks.py | 包含一些回调函数的实现 |
| utils/dataloaders.py | 包含数据加载器的实现 |
| utils/downloads.py | 包含一些下载数据集和模型的实现 |
| utils/loss.py | 包含一些损失函数的实现 |
| utils/metrics.py | 包含一些评估指标的实现 |
| utils/plots.py | 包含一些绘图函数的实现 |
| utils/torch_utils.py | 包含一些与PyTorch相关的工具函数 |
| utils/triton.py | 包含与Triton Inference Server相关的工具函数 |
这些文件组成了一个完整的缺陷分类系统,包括模型定义、训练、推理和评估等功能。
7.YOLOv8简介
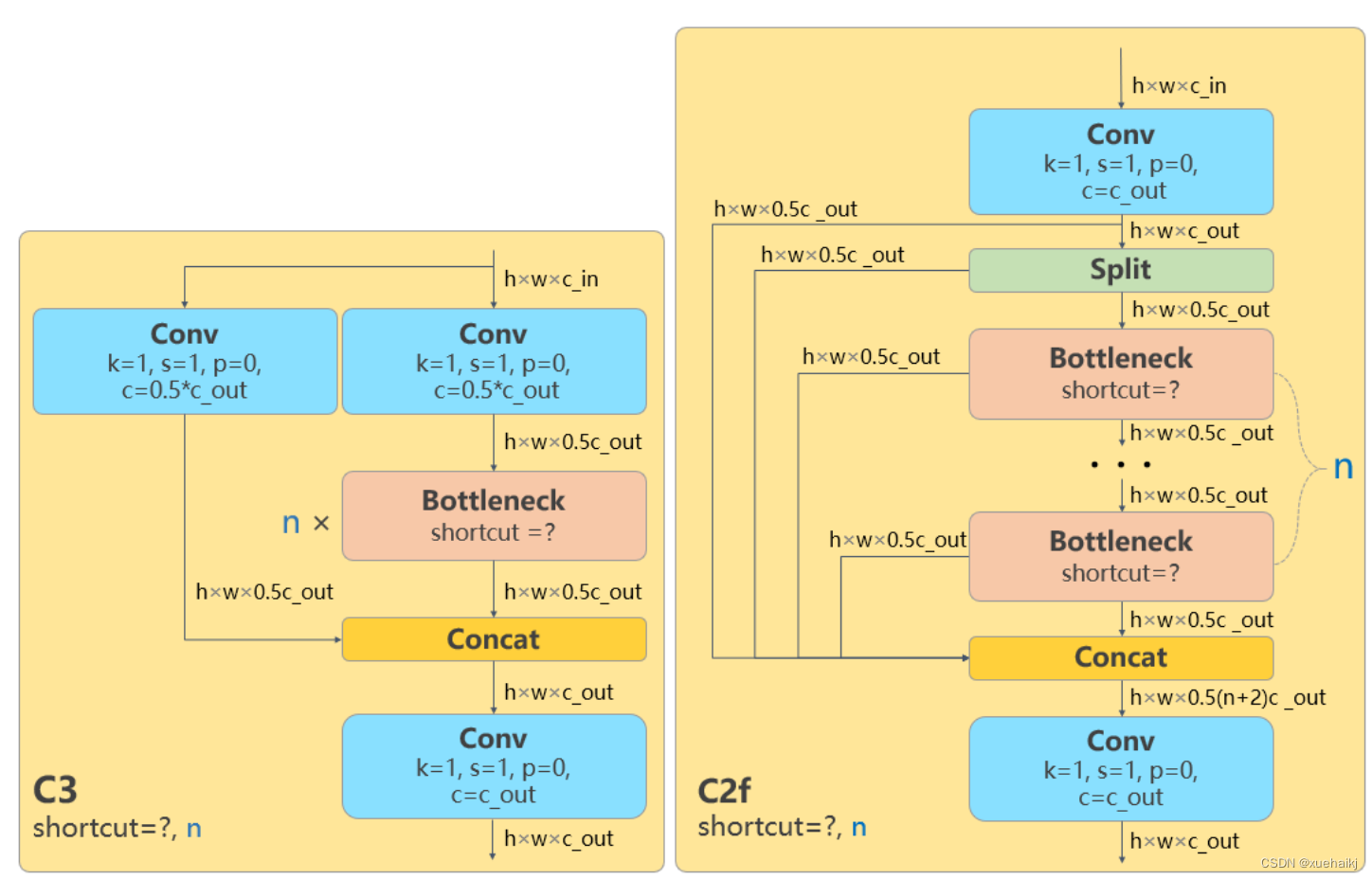
由上图可以看出,C2中每个BottlNeck的输入Tensor的通道数channel都只是上一级的0.5倍,因此计算量明显降低。从另一方面讲,梯度流的增加,t也能够明显提升收敛速度和收敛效果。
C2i模块首先以输入tensor(n.c.h.w)经过Conv1层进行split拆分,分成两部分(n,0.5c,h,w),一部分直接经过n个Bottlenck,另一部分经过每一操作层后都会以(n.0.5c,h,w)的尺寸进行Shortcut,最后通过Conv2层卷积输出。也就是对应n+2的Shortcut(第一层Conv1的分支tensor和split后的tensor为2+n个bottenlenneck)。
Neck
YOLOv8的Neck采用了PANet结构,如下图所示。
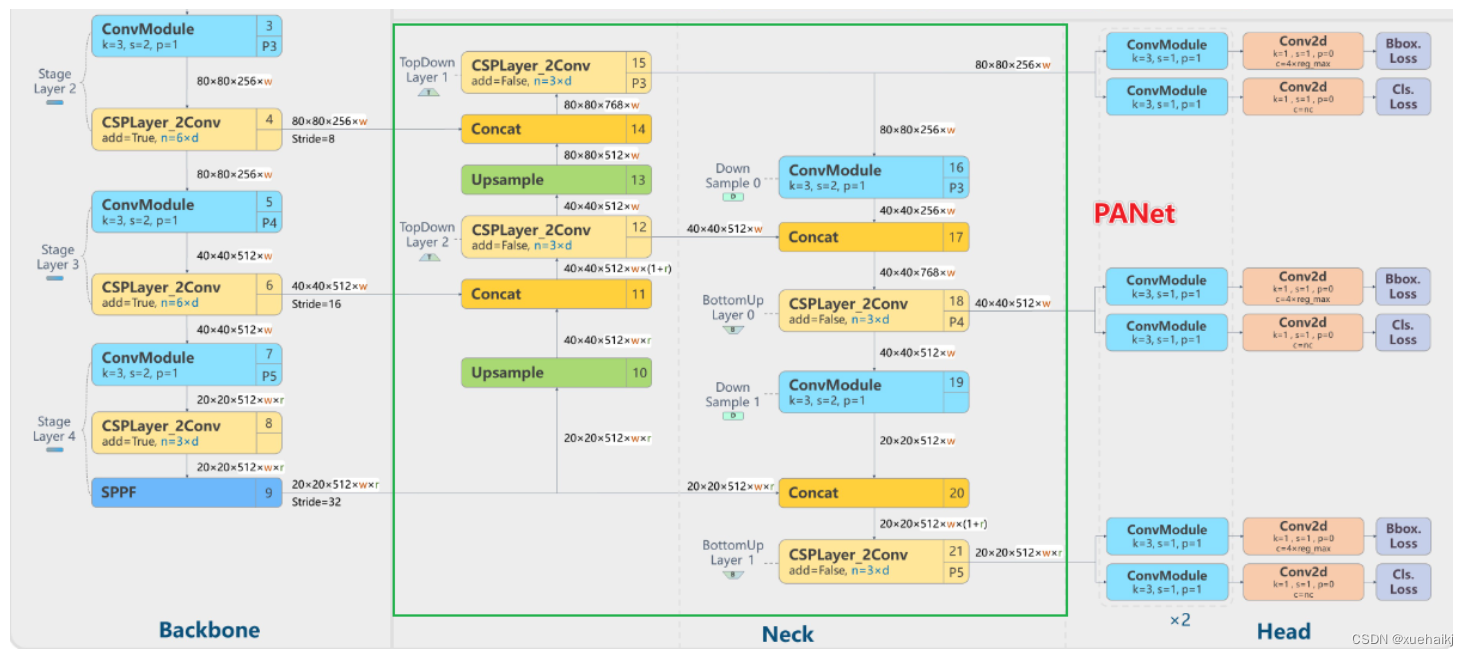
Backbone最后SPPF模块(Layer9)之后H、W经过32倍下采样,对应地Layer4经过8倍下采样,Layer6经过16倍下采样。输入图片分辨率为640640,得到Layer4、Layer6、Layer9的分辨率分别为8080、4040和2020。
Layer4、Layer6、Layer9作为PANet结构的输入,经过上采样,通道融合,最终将PANet的三个输出分支送入到Detect head中进行Loss的计算或结果解算。
与FPN(单向,自上而下)不同的是,PANet是一个双向通路网络,引入了自下向上的路径,使得底层信息更容易传递到顶层。
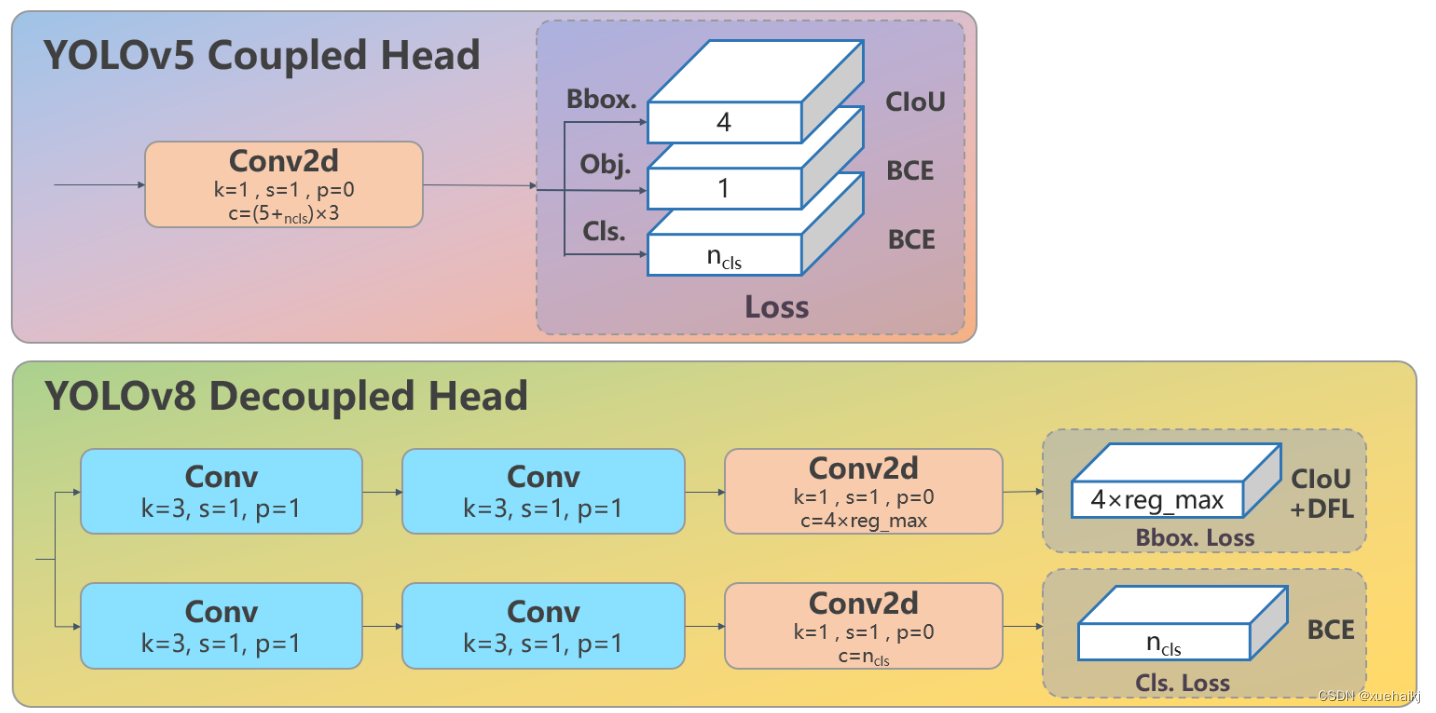
Head
Head部分相比Yolov5改动较大,直接将耦合头改为类似Yolo的解耦头结构(Decoupled-Head),将回归分支和预测分支分离,并针对回归分支使用了Distribution Focal Loss策略中提出的积分形式表示法。之前的目标检测网络将回归坐标作为一个确定性单值进行预测,DFL将坐标转变成一个分布。
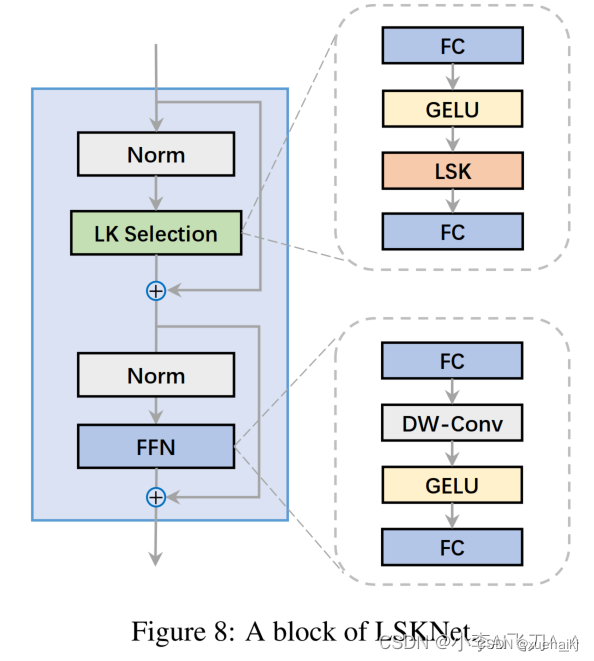
8.LSKNet的架构
该博客提出的结构层级依次为:
LSK module(大核卷积序列+空间选择机制) < LSK Block (LK Selection + FFN)<LSKNet(N个LSK Block)
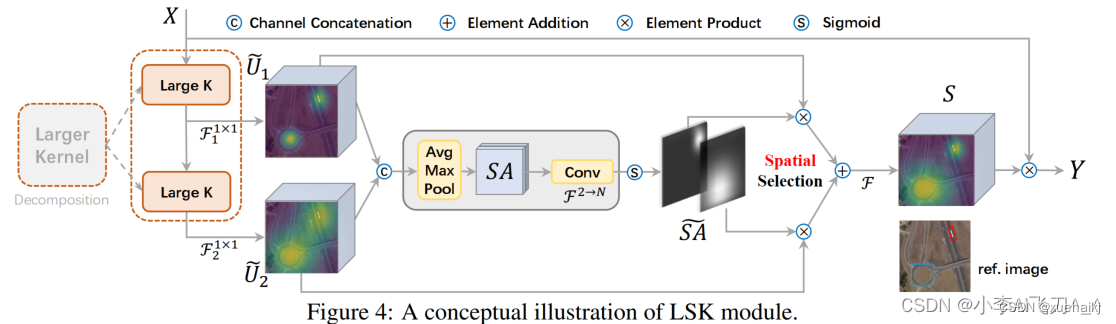
LSK 模块
LSK Block
LSKNet 是主干网络中的一个可重复堆叠的块(Block),每个LSK Block包括两个残差子块,即大核选择子块(Large Kernel Selection,LK Selection)和前馈网络子块(Feed-forward Network ,FFN),如图8。LK Selection子块根据需要动态地调整网络的感受野,FFN子块用于通道混合和特征细化,由一个全连接层、一个深度卷积、一个 GELU 激活和第二个全连接层组成。
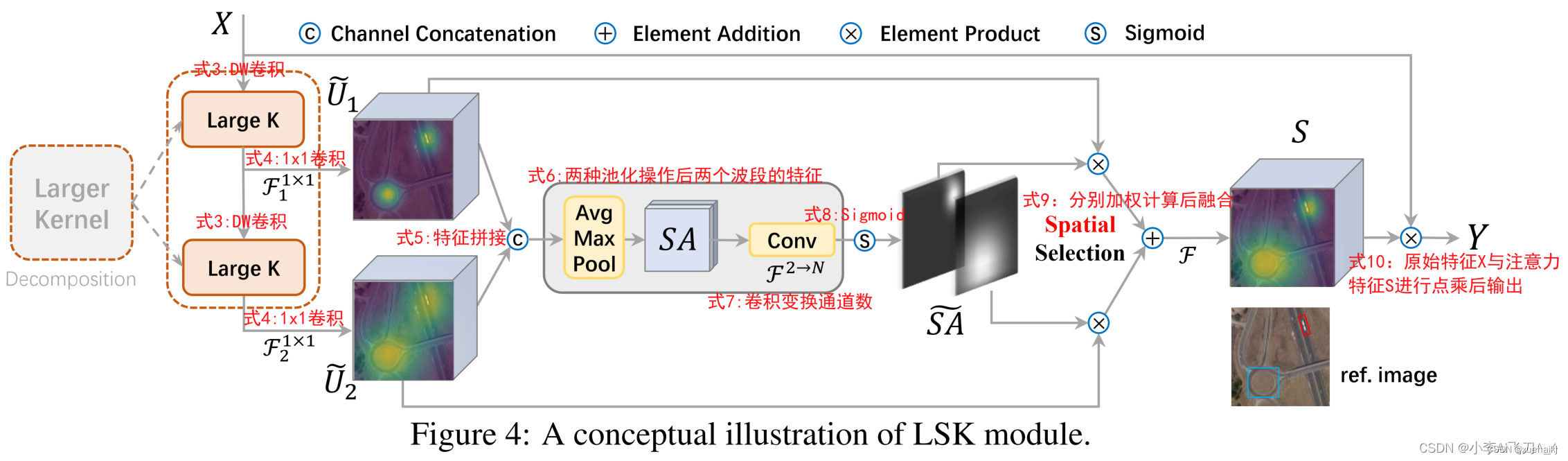
LSK module(LSK 模块,图4)由一个大核卷积序列(large kernel convolutions)和一个空间核选择机制(spatial kernel selection mechanism)组成,被嵌入到了LSK Block 的 LK Selection子块中。
Large Kernel Convolutions
因为不同类型的目标对背景信息的需求不同,这就需要模型能够自适应选择不同大小的背景范围。因此,作者通过解耦出一系列具有大卷积核、且不断扩张的Depth-wise 卷积,构建了一个更大感受野的网络。
具体地,假设序列中第i个Depth-wise 卷积核的大小为 ,扩张率为 d,感受野为 ,它们满足以下关系:
卷积核大小和扩张率的增加保证了感受野能够快速增大。此外,我们设置了扩张率的上限,以保证扩张卷积不会引入特征图之间的差距。
Table2的卷积核大小可根据公式(1)和(2)计算,详见下图:

这样设计的好处有两点。首先,能够产生具有多种不同大小感受野的特征,便于后续的核选择;第二,序列解耦比简单的使用一个大型卷积核效果更好。如上图表2所示,解耦操作相对于标准的大型卷积核,有效地将低了模型的参数量。
为了从输入数据 的不同区域获取丰富的背景信息特征,可采用一系列解耦的、不用感受野的Depth-wise 卷积核:
其中,是卷积核为 、扩张率为 的Depth-wise 卷积操作。假设有个解耦的卷积核,每个卷积操作后又要经过一个的卷积层进行空间特征向量的通道融合。
之后,针对不同的目标,可基于获取的多尺度特征,通过下文中的选择机制动态选择合适的卷积核大小。
这一段的意思可以简单理解为:
把一个大的卷积核拆成了几个小的卷积核,比如一个大小为5,扩张率为1的卷积核加上一个大小为7,扩张率为3的卷积核,感受野为23,与一个大小为23,扩张率为1的卷积核的感受野是一样的。因此可用两个小的卷积核替代一个大的卷积核,同理一个大小为29的卷积核也可以用三个小的卷积代替(Table 2),这样可以有效的减少参数,且更灵活。
将输入数据依次通过这些小的卷积核(公式3),并在每个小的卷积核后面接上一个1×1的卷积进行通道融合(公式4)。
Spatial Kernel Selection
为了使模型更关注目标在空间上的重点背景信息,作者使用空间选择机制从不同尺度的大卷积核中对特征图进行空间选择。
首先,将来自于不同感受野卷积核的特征进行concate拼接,然后,应用通道级的平均池化和最大池化提取空间关系,其中, 和 是平均池化和最大池化后的空间特征描述符。为了实现不同空间描述符的信息交互,作者利用卷积层将空间池化特征进行拼接,将2个通道的池化特征转换为N个空间注意力特征图,之后,将Sigmoid激活函数应用到每一个空间注意力特征图,可获得每个解耦的大卷积核所对应的独立的空间选择掩膜,又然后,将解耦后的大卷积核序列的特征与对应的空间选择掩膜进行加权处理,并通过卷积层进行融合获得注意力特征 ,最后LSK module的输出可通过输入特征 与注意力特征 的逐元素点成获得,公式对应于结构图上的操作如下:
9.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《【改进YOLOv8】磁瓦缺陷分类系统:改进LSKNet骨干网络的YOLOv8》
10.参考文献
[1]王凌云,杨剑,张赟宁,等.计及多智能体调度的冷热电联供型微网并网优化运行研究[J].可再生能源.2020,(1).DOI:10.3969/j.issn.1671-5292.2020.01.019 .
[2]程显毅,谢璐,朱建新,等.生成对抗网络GAN综述[J].计算机科学.2019,(3).DOI:10.11896/j.issn.1002-137X.2019.03.009 .
[3]刘畅,张剑,林建平.基于神经网络的磁瓦表面缺陷检测识别[J].表面技术.2019,(8).DOI:10.16490/j.cnki.issn.1001-3660.2019.08.044 .
[4]翟华伟,崔立成,张维石.一种改进灵敏度分析的在线自适应极限学习机算法[J].小型微型计算机系统.2019,(7).DOI:10.3969/j.issn.1000-1220.2019.07.005 .
[5]沈翠芝.采用生成对抗网络的金融文本情感分类方法[J].福州大学学报(自然科学版).2019,(6).DOI:10.7631/issn.1000-2243.19174 .
[6]宋春华,彭泫知.机器视觉研究与发展综述[J].装备制造技术.2019,(6).DOI:10.3969/j.issn.1672-545X.2019.06.062 .
[7]朱秀昌,唐贵进.生成对抗网络图像处理综述[J].南京邮电大学学报(自然科学版).2019,(3).DOI:10.14132/j.cnki.1673-5439.2019.03.001 .
[8]蔡增伟,张顺琦,蒋小乐,等.探索汽车制动钳支架的智能绿色制造之路[J].制造技术与机床.2019,(9).DOI:10.19287/j.cnki.1005-2402.2019.09.001 .
[9]赵树阳,李建武.基于生成对抗网络的低秩图像生成方法[J].自动化学报.2018,(5).DOI:10.16383/j.aas.2018.c170473 .
[10]崔建国,张善好,于明月,等.基于增量型极限学习机的飞机复合材料结构损伤识别[J].科学技术与工程.2018,(4).