Ubuntu上安装MySQL以及hive
- 一、安装MySQL
- 1、更新软件源
- 2、安装 MySQL
- 3、启动 MySQL,并登录 MySQL
- 4、关闭 MySQL 指令:
- 5、修改登录密码
- 6、关闭 mysql,然后重新进入
- 二、安装hive
- 1、创建 hive 的数据库
- 2、下载压缩包
- 3、修改环境配置文件并激活
- 4、编辑 hive/conf/ 路径下的 hive-site.xml 文件
- 5、编辑 Hadoop 里面 etc/hadoop/路径下 core-site.xml 文件
- 6、初始化元数据库
- 7、启动 hadoop 集群和 MySQL 服务
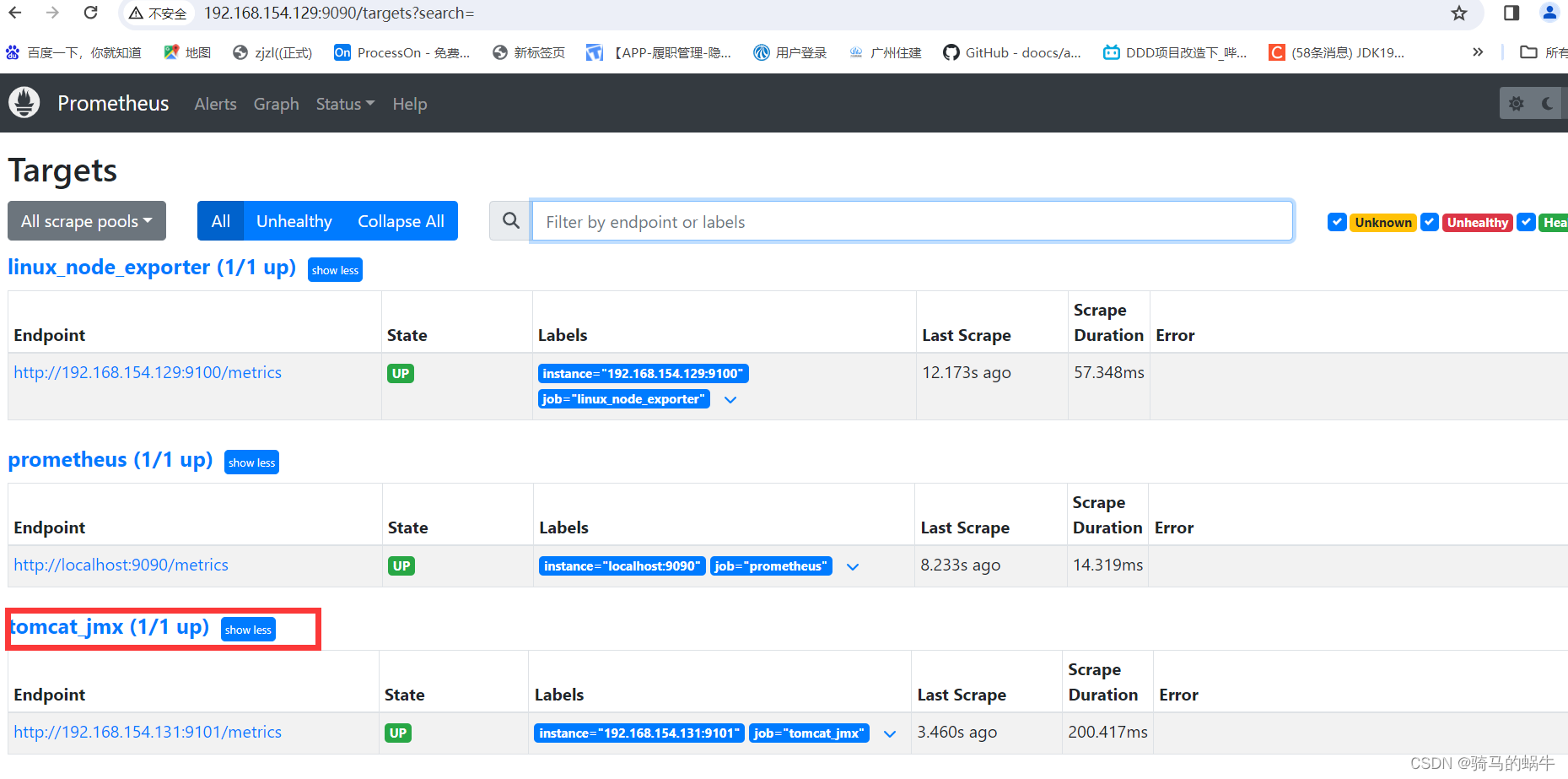
- 8、启动 hive 并检测
- 9、使用hive
- 10、关闭
一、安装MySQL
1、更新软件源
更新系统中可用软件包的信息。
sudo apt-get update # 更新软件源

2、安装 MySQL
sudo apt-get install mysql-server # 安装 mysql

输入密码


下载完成

3、启动 MySQL,并登录 MySQL
service mysql start # 启动sudo mysql -u root -p # 登录(eg.密码是 root)
注意:成功启动是无任何提示的

4、关闭 MySQL 指令:
service mysql stop
注意:成功关闭也是无任何提示的
5、修改登录密码
【注意:不要随便修改密码,这个密码跟所需配置文件内容是相关的,动了需要自己改 hive 的配置文件】
修改登录密码为 123456
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456'; -- 修改密码
FLUSH PRIVILEGES; -- 刷新权限
(小坑:一定要先修改密码后刷新权限)

6、关闭 mysql,然后重新进入
测试免密登录,一定要测,否则后面如果要使用hive会连不上sql
service mysql stop
mysql -u root -p
如果 mysql -u root -p报错说:Access denied for user 'root'@'localhost' ,那证明不能免密登录,要更改验证方式:
再次进入:sudo mysql -u root -p
更 改 验 证 方 式 : ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
刷新权限:FLUSH PRIVILEGES;
退出:exit;
再次执行:mysql -u root -p
确认是否启动成功,mysql节点处于LISTEN状态表示启动成功:
$ sudo netstat -tap | grep mysql

至此,ubuntu系统上顺利完成安装mysql数据库。
二、安装hive
1、创建 hive 的数据库
create database hive; -- 【创建 database 无 s】show databases; -- 【show database 有 s】exit; -- 退出:

2、下载压缩包
hive压缩包下载:https://pan.baidu.com/s/1t262sOy5I729yiMvm3ty9w
解压命令:unzip 文件名.zip -d /usr/local/hive
这里注意,一定要是三级目录!!!也就是指明,你要 hive 压缩包的内容全部解压到 hive 这个文件夹下!如果/usr/local 下没有 hive 会自动和已有合并的,可能整个 hadoop 都出问题。不要解压到/usr/local下,不小心搞错了你就从头再来。
这里的从头是指重新创建一个虚拟机,重新配置Hadoop。
3、修改环境配置文件并激活
文件地址:/usr/local/hive/bin
sudo vim ~/.bashrc
一共多了 5 行内容:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HADOOP_HOME/sbin:$HIVE_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOPA_HOME/sbin
export HADOOP_HOME_SBIN=/usr/local/hadoop/sbin

激活配置
source ~/.bashrc
4、编辑 hive/conf/ 路径下的 hive-site.xml 文件
编辑 hive/conf/ 路径下的 hive-site.xml 文件(改了密码的,就要修改这个文件)

(没有文件就自己创建)
hive-site.xml文件
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExsit=true;characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>这里加上自己的密码</value></property><property><name>datanucleus.readOnlyDatastore</name><value>false</value></property><property><name>datanucleus.fixedDatastore</name><value>false</value></property><property><name>datanucleus.autoCreateSchema</name><value>true</value></property><property><name>datanucleus.autoCreateTables</name><value>true</value></property><property><name>datanucleus.autoCreateColumns</name><value>true</value></property>
</configuration>5、编辑 Hadoop 里面 etc/hadoop/路径下 core-site.xml 文件
编辑 Hadoop 里面 etc/hadoop/路径下 core-site.xml 文件(/usr/local/hadoop/etc/hadoop/),加入如下
具体步骤可看:大数据实战平台环境搭建
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>

6、初始化元数据库
schematool -dbType mysql -initSchema
【这一步在/usr/local/hive/bin 下执行】
【出现 schematool completed才是初始化成功,
如果出现schematool fail表示失败,看一下报错,驱动问题找驱动
连接问题返回mysql最后一点】
7、启动 hadoop 集群和 MySQL 服务
输入./sbin/start-dfs.sh启动hdfs。

输入jps确定Hadoop处于启动状态。

8、启动 hive 并检测
最好在/usr/local/hive/bin路径下启动
hive

9、使用hive
show databases;
9.1. 创建一个数据库
create database db_test1;
9.2. 创建一个表
create table emp
(empno int,
ename string,
job string,
mgr int,
hiredate string,
sal int,
comm int,
deptno int)
row format delimited fields terminated by ',';
9.3. 测试数据,自己创建txt文件
7369,SMITH,CLERK,7902,1980/12/17,800,0,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,0,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,0,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,0,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,0,20
7839,KING,PRESIDENT,-1,1981/11/17,5000,0,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,0,20
7900,JAMES,CLERK,7698,1981/12/3,950,0,30
7902,FORD,ANALYST,7566,1981/12/3,3000,0,20
7934,MILLER,CLERK,7782,1982/1/23,1300,0,10
9.4. 导入数据
加载本地的数据到Hive的表
load data local inpath '/root/temp/emp.txt into table emp;
加载HDFS的数据到Hive的表
load data inpath '/scott/emp.txt into table emp;
9.5. 查询数据
select * from emp;
运行截图:


10、关闭