Hystrix 的核心是提供服务容错保护,防止任何单一依赖耗尽整个容器的全部用户线程。使用舱壁隔离模式,对资源或失败单元进行隔离,避免一个服务的失效导致整个系统垮掉(雪崩效应)。
1 Hystrix监控
Hystrix 提供了对服务请求的仪表盘监控。在客户端加入以下依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>并在客户端的Application类加上@EnableHystrixDashboard注解。
访问地址:http://localhost:8080/hystrix
在输入框中输入监控地址:http://localhost:8080/hystrix.stream,然后点击“Monitor Stream”按钮。
图 Hystrix 监控初始界面

图 Hystrix 仪表盘主要参数及含义
2 服务隔离
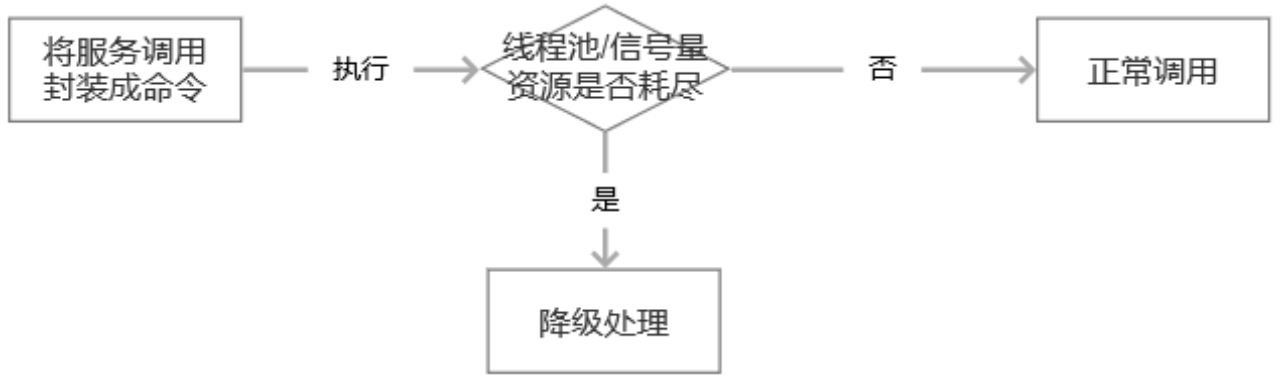
图 Hystrix 实现服务隔离的思路
2.1 隔离策略
Hystrix 提供了线程池隔离和信号量隔离两种隔离策略。
execution.isolation.strategy 属性配置隔离策略,默认为THREAD(线程池隔离),SEMAPHORE为信号量隔离。execution.isolation.thread.timeoutInMilliseconds属性配置请求超时时间,默认为1000ms。
2.1.1 线程池隔离
不同服务的执行使用不同的线程池,同时将用户请求的线程(如Tomcat)与具体业务执行的线程分开,业务执行的线程池可以控制在指定的大小范围内,从而使业务之间不受影响,达到隔离的效果。
| 优点 |
|
| 缺点 | 线程及线程池的创建及管理增加了计算开销。 |
表 线程池隔离的优缺点
关于线程池隔离的相关配置有如下参数:
coreSize:线程池核心线程数。即线程池中保持存活的最小线程数。默认为10。
maximumSize:线程池允许的最大线程数。当核心线程数已满且任务队列已满时,线程池会尝试创建新的线程,直到达到最大线程数。默认为10。
maxQueueSize:线程池任务队列的大小。默认为-1,表示任务将被直接交给工作线程处理,而不是放入队列中等待。
queueSizeRejectionThreshold:即便没达到maxQueueSize阈值,但达到该阈值时,请求也会被拒绝,默认值为5。
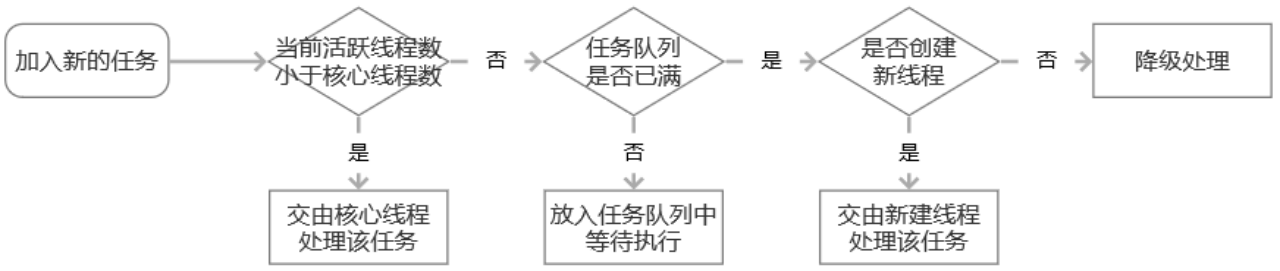
图 新的请求在线程池的处理过程
是否创建新线程,是指当前活跃线程已达到coreSize,但线程数小于maximumSize,Hystrix 会创建新的线程来处理该任务。(这一步还受到queueSizeRejectionThreshold及maxQueueSize参数的影响)。
2.1.2 信号量隔离
用户请求线程和业务执行线程是同一线程,通过设置信号量的大小限制用户请求对业务的并发访问量,从而达到限流的保护效果。
| 优点 | 1 开销小,避免了线程创建、销毁及上下文切换等开销。 2 配置简单,只需要设置信号量大小即可。 3 适合轻量级操作,如内存或缓存服务访问,这些操作不太可能导致长时间延迟,因此信号隔离可以保持系统的高效性。 |
| 缺点 | 限流能力有限,存在阻塞风险,如果依赖服务阻塞,因为其没有使用线程池来隔离请求,那么可能会影响整个请求链路,导致系统性能下降。 |
表 Hystrix 信号隔离的优缺点
execution.isolation.semaphore.maxConcurrentRequests 最大并发请求数(信号量大小)。默认为10。
2.2 服务隔离的颗粒度
@HystrixCommand 注解还有三个属性:commandKey(标识该命令全局唯一的名称,默认情况下,同一个服务名称共享一个线程池)、groupKey(组名,Hystrix 会让相同组名的命令使用同一个线程池)、threadPoolKey(线程池名称,多个服务可以设置同一个threadPoolKey,来共享同一个线程池,在信号量隔离策略中不起作用)。
3 请求缓存
在用户的同一个请求中,消费者可能会多次重复调用一个服务。Hystrix 提供的请求缓存可以在CommandKey/CommandGroup相同的情况下,直接共享第一次命令执行的结果,降低依赖调用次数。
@Service
public class UserService {private final RestTemplate restTemplate;public UserService(RestTemplate restTemplate) {this.restTemplate = restTemplate;}@CacheResult(cacheKeyMethod = "generateCacheKey")@HystrixCommand(commandKey = "info3",groupKey = "info3Group",commandProperties = {@HystrixProperty(name = "requestCache.enabled", value = "true")})public RequestResult<String> info3(String name) {System.out.println("发送请求:" + name);return RequestResult.success(restTemplate.getForObject("http://provider/user/info?name=" + name, String.class));}public String generateCacheKey(String name) {return name;}
}@RequestMapping("/home")
@RestController
public class HomeController {private final RestTemplate restTemplate;private final UserService userService;public HomeController(RestTemplate restTemplate, UserService userService) {this.restTemplate = restTemplate;this.userService = userService;}@GetMapping("/info3")public RequestResult<String> info3(String name) {HystrixRequestContext context = HystrixRequestContext.initializeContext();RequestResult<String> result = userService.info3(name);userService.info3(name);context.close();return result;}
}
4 请求合并
Hystrix针对高并发场景,支持将多个请求自动合并为一个请求,通过合并可以减少对依赖的请求,极大节省开销,提高系统效率。
请求合并主要是通过两部分实现:1)@HystrixCollapser 指定高并发请求的对应请求,其返回值为Futuer。2)@HystrixCommand 指定合并后的单个请求。其参数为第1部分请求参数的集合。
@Service
public class UserService {private final RestTemplate restTemplate;public UserService(RestTemplate restTemplate) {this.restTemplate = restTemplate;}@HystrixCollapser(collapserKey = "info",scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,batchMethod = "batchInfo",collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds", value = "1000"),@HystrixProperty(name = "maxRequestsInBatch", value = "3")})public Future<RequestResult<String>> batchInfo(String name) {// 不会被执行System.out.println("HystrixCollapser info");return null;}@HystrixCommandpublic List<RequestResult<String>> batchInfo(List<String> names) {System.out.println("批量发送:" + names);// 依赖也需要有一个支持批量的接口String res = restTemplate.getForObject("http://provider/user/info?name=" + names, String.class);List<RequestResult<String>> list = new ArrayList<>();int count = 0;for (String str : names) {list.add(RequestResult.success(res + "kk" + str + count++));}return list;}
}@RequestMapping("/home")
@RestController
public class HomeController {private final RestTemplate restTemplate;private final UserService userService;public HomeController(RestTemplate restTemplate, UserService userService) {this.restTemplate = restTemplate;this.userService = userService;}@GetMapping("/info2")public RequestResult<String> info2(String name) throws ExecutionException, InterruptedException {HystrixRequestContext context = HystrixRequestContext.initializeContext();Future<RequestResult<String>> future = userService.batchInfo(name);RequestResult<String> result = future.get();context.close();return result;}
}


















