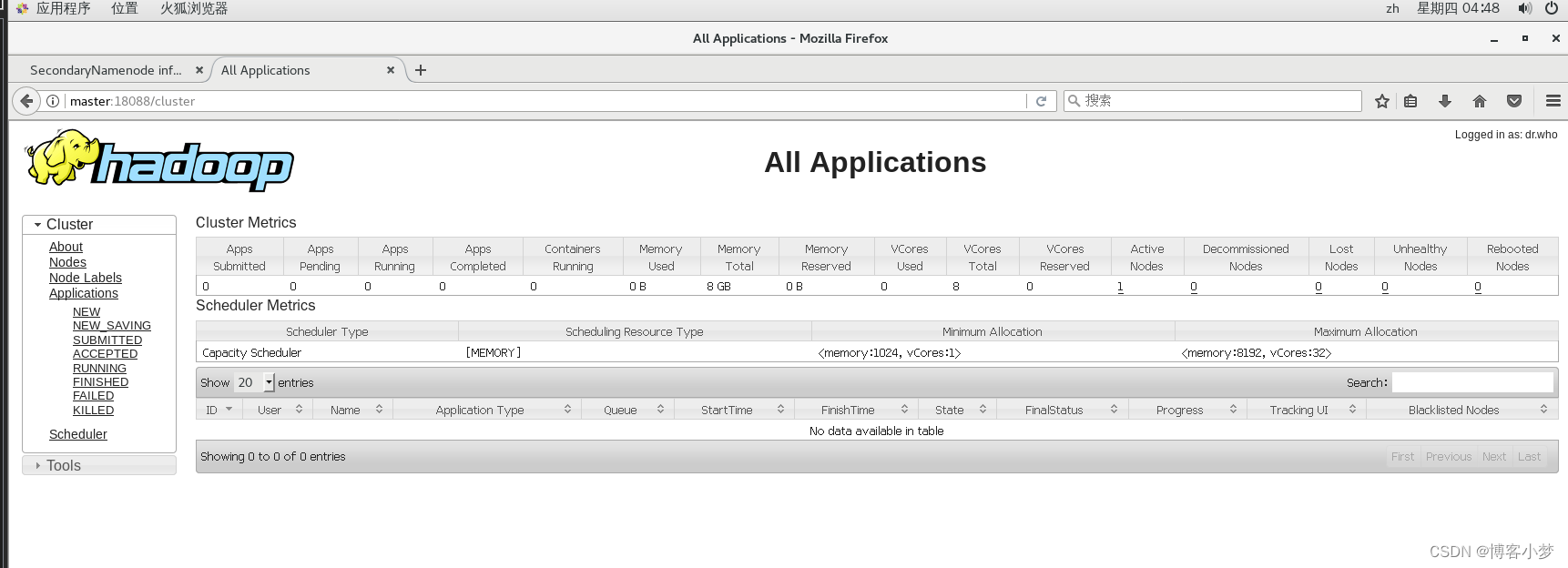
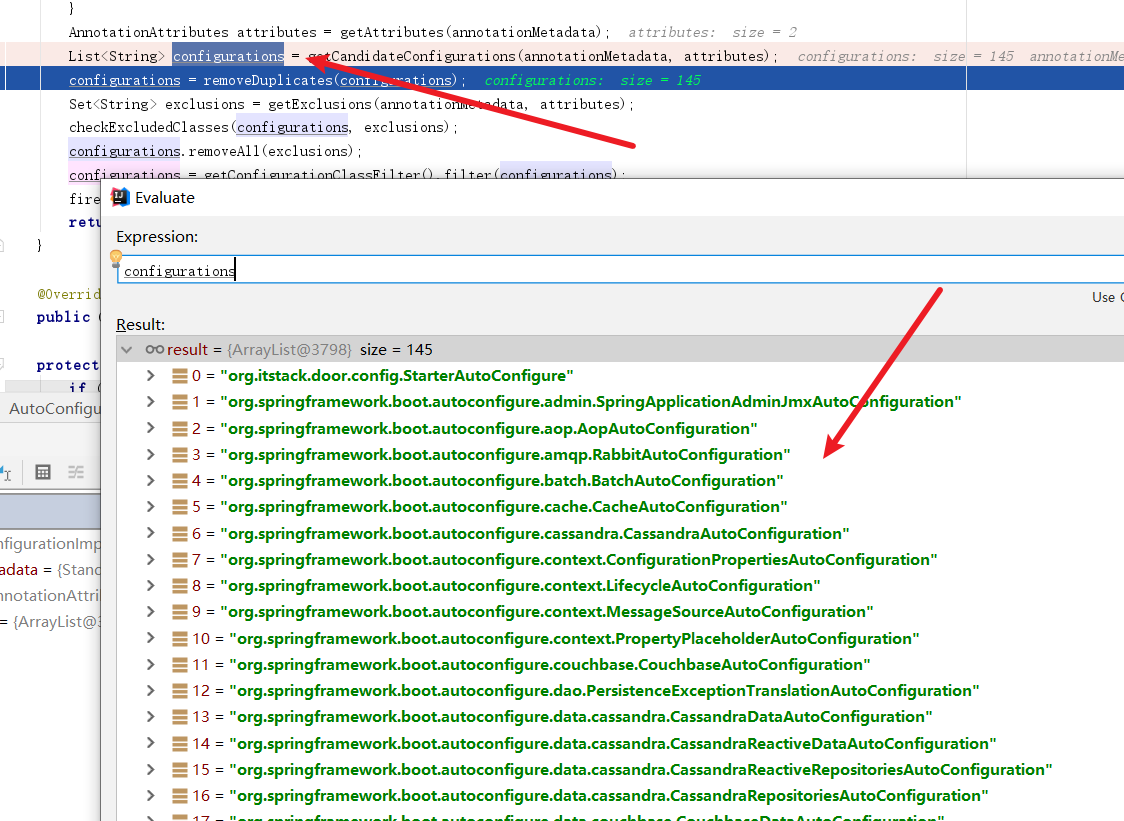
考虑如下的人员数据,其中加下划线的是主码,数据库模式由四个关系组成:
employee (empname, street, city)
works (empname, compname, salary)
company(id, compname, city)
managers (empname, mgrname)
其中关系 employee 给出人员的基本信息,包括人员姓名(empname),居住的城市(city)
和街道 (street):works 存人员工作的公司名称(compname) 及年薪 (salary),单位为万元;
company包括一个自增类型的 id、公司名称(compname)和公司所在城市(city);
managers存储人员及直属经理的信息。按要求完成下列数据库操作:
1.找出工作城市在“北京”且年薪高于 20 万的人员信息:(关系代数表达式 1分+SQL1分)
2.找出所有不在“美华”公司工作的人员信息:(关系代数表达式 2 分 + SQL2 分)
3.查询全体人员年薪情况,要求包含无业人员:(关系代数表达式3 分 +SQL3 分)
4.假设一个公司可以在多个城市开设。找出在“北华”公司所在城市均设厂的公司:(关系
代数表达式4分 +SQL8 分)
5.查询员工人数最多的公司名称及人数;(SQL8 分)
6.找出数据库中年薪超过“北华”公司的每名员工的人员信息:(SQL5 分)
7.找出数据库中所有居住街道和城市与其经理相同的人员信息:(SQL6分)
8.修改数据库,使为“北华”公司工作的所有年薪不超过 100 万的经理增长 10%;(SQL5分)
9.创建一个视图 COMINFO(compname,avgsalary),其中 avgsalary 表示该公司员工平均薪
水: (SQL5 分)
10.SQL 语句完成将 works 关系的查询与插入权限赋予 userl。(SQL2 分)
构造测试数据
-- 创建 employee 表并插入数据
CREATE TABLE employee (empname VARCHAR(50),street VARCHAR(50),city VARCHAR(50),primary key(empname)
);INSERT INTO employee (empname, street, city) VALUES
('张三', '街道1', '北京'),
('李四', '街道2', '上海'),
('王五', '街道3', '广州'),
('赵六', '街道1', '北京'),
('钱七', '街道5', '上海'),
('孙八', '街道6', '北京'),
('周九', '街道3', '广州'),
('吴十', '街道8', '上海'),
('郑十一', '街道9', '北京'),
('王十二', '街道10', '广州');-- 创建 works 表并插入数据
CREATE TABLE works (empname VARCHAR(50),compname VARCHAR(50),salary FLOAT,primary key(empname)
);INSERT INTO works (empname, compname, salary) VALUES
('张三', 'ABC', 25),
('李四', '美华', 110),
('王五', 'XYZ', 18),
('赵六', 'ABC', 22),
('钱七', '北华', 105),
('孙八', '北华', 45),
('周九', 'XYZ', 40),
('郑十一', '北华', 26),
('王十二', 'ABC', 23);-- 创建 company 表并插入数据
CREATE TABLE company (id INT,compname VARCHAR(50),city VARCHAR(50),primary key(id)
);INSERT INTO company (id, compname, city) VALUES
(1, 'ABC', '北京'),
(2, '美华', '上海'),
(3, 'XYZ', '北京'),
(4, '北华', '广州'),
(5, 'DEF', '上海'),
(6, 'GHI', '北京'),
(7, 'JKL', '广州'),
(8, 'MNO', '上海'),
(9, 'PQR', '北京'),
(10, 'PQR', '上海'),
(11, 'PQR', '广州'),
(12, '北华', '北京'),
(13, 'STU', '广州'),
(14, 'STU', '北京');-- 创建 managers 表并插入数据
CREATE TABLE managers (empname VARCHAR(50),mgrname VARCHAR(50),primary key(empname)
);INSERT INTO managers (empname, mgrname) VALUES
('张三', '赵六'),
('郑十一', '孙八'),
('孙八', '钱七'),
('王五', '周九'),
('王十二', '张三');
1.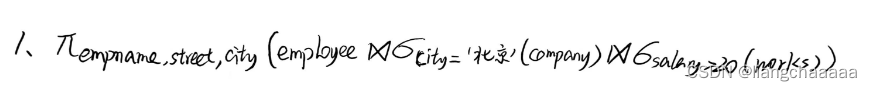
select distinct employee.empname,street,employee.city
from works
left join employee on works.empname = employee.empname
left join company on company.compname = works.compname
where employee.city='北京' and works.salary > 20;2.
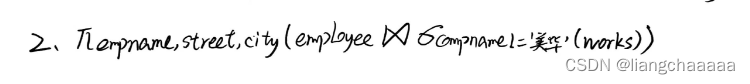
select distinct employee.empname,street,employee.city
from employee
left join works on works.empname = employee.empname
where works.compname!='美华'3.

select distinct works.salary
from employee
left join works on works.empname = employee.empname
4.
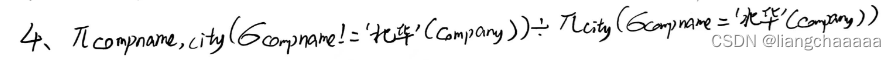
select distinct compname
from company as x
where not exists(select *from company as ywhere y.compname = '北华' and not exists(select *from company as zwhere z.compname = x.compname and z.city = y.city)
) and compname!='北华';5.
select compname,count(*)
from works
group by compname
having count(*)>=all(select count(*)from works group by compnamehaving count(*)
)6.
select distinct employee.empname,street,employee.city
from employee
left join works on works.empname = employee.empname
where salary > all(select salaryfrom workswhere compname = '北华'
)7.
select distinct subtable.empname,subtable.street,subtable.city
from(select managers.empname,street,city,mgrnamefrom employeejoin managerswhere employee.empname = managers.empname
)as subtable
left join employee on employee.empname = subtable.mgrname
where employee.street = subtable.street and employee.city = subtable.city 8.
update works
set salary =salary * 1.1
where salary < 100 and compname = '北华' and empname in(select mgrnamefrom managers
)
9.
create view COMINFO(compname,avgsalary )
as
select compname,AVG(salary) as avgsalary
from works
group by compname10.
grant insert,select
on works
to 'userl'