介绍
OpenAI 在 2021 年提出了 CLIP(Contrastive Language–Image Pretraining)算法,这是一个先进的机器学习模型,旨在理解和解释图像和文本之间的关系。CLIP 的核心思想是通过大规模的图像和文本对进行训练,学习图像内容与自然语言描述之间的对应关系。这种方法使得模型能够在没有特定任务训练的情况下,对广泛的视觉概念进行理解和分类。
历史
OpenAI 的 CLIP(Contrastive Language–Image Pretraining)算法是在多模态学习领域的一个重要发展,而要理解其历史发展,首先需要明确“模态”的含义及其在人工智能中的应用。
模态的含义
在人工智能和计算机科学中,“模态”(Modality)通常指的是不同类型的数据或通信方式。常见的模态包括文本、图像、视频、音频等。每种模态具有独特的特性和处理方式。
多模态学习
多模态学习涉及同时使用和分析多种不同类型的数据(即多种模态)。例如,一个多模态系统可能会同时处理图像和文本信息,以更全面地理解和解释内容。
CLIP 的历史发展
-
早期背景:在 CLIP 之前,大多数人工智能系统主要关注单一模态的处理。例如,有些模型专注于图像识别,而其他模型则集中于文本分析。
-
多模态学习的兴起:随着技术的发展,研究人员开始探索如何结合不同模态的数据来提高人工智能系统的理解和分析能力。多模态学习开始成为研究的热点。
-
CLIP 的推出:2021 年,OpenAI 推出了 CLIP,这是一个突破性的多模态学习模型。CLIP 通过大规模的图像和文本数据训练,学习理解两者之间的关联。
-
CLIP 的创新:CLIP 的创新之处在于其能够使用对比学习方法同时处理和理解图像和文本信息。这意味着模型可以对图像进行分类或描述,而无需大量特定任务的训练。
-
影响和应用:CLIP 的成功展示了多模态学习在实际应用中的潜力,包括图像分类、内容创建、自动标注等领域。
-
后续发展:CLIP 的成功激发了更多关于多模态学习的研究和开发,推动了人工智能向更复杂、更全面的理解和处理不同类型数据的方向发展。
CLIP 解决方案
OpenAI CLIP 模型并不是最初为 GPT(Generative Pretrained Transformer)设计的。虽然 CLIP 和 GPT 都是 OpenAI 开发的模型,但它们是针对不同用途和应用场景设计的。
目的和用途
- GPT:主要关注于理解和生成文本。
- CLIP:旨在关联图像和文本,使模型能够理解视觉内容并有效地将其与语言描述相关联。
技术关联
-
预训练和大数据:CLIP 和 GPT 都使用了预训练的方法,在大规模数据集上进行学习。GPT 在文本数据上进行预训练,而 CLIP 在图像和文本对上进行预训练。
-
深度学习和神经网络:两者都基于深度学习的原理,使用神经网络架构来处理和生成数据。
-
多模态学习的概念:尽管 GPT 主要专注于文本,但在其最新的迭代中,例如 GPT-4,已开始涉足多模态学习,这是 CLIP 主要关注的领域。
技术差异
-
专注领域:CLIP 专注于图像和文本之间的关系,而 GPT 主要处理文本数据。
-
模型结构和目的:CLIP 使用对比学习方法来关联图像和文本,GPT 使用 Transformer 架构来生成连贯、有意义的文本。
-
应用范围:GPT 在文本生成、翻译、问答等任务中表现出色,而 CLIP 适用于图像识别、内容创建、文本到图像的任务等。
数据来源
OpenAI 的 CLIP(Contrastive Language–Image Pretraining)模型是在一个非常大的图像-文本对数据集上训练的。具体来说,据 OpenAI 的原始论文所述,CLIP 是在一个包含约4亿个图像-文本对的数据集上进行训练的。
这个数据集的规模是其显著特点之一,它使得模型能够学习并理解广泛的视觉概念和自然语言描述。大规模的数据集对于训练如 CLIP 这样的多模态模型来说至关重要,因为它们提供了足够的样本来捕捉和理解图像内容和相关文本之间复杂的关系。
随着技术发展,现在已经超过论文所述4亿对。
监督信号
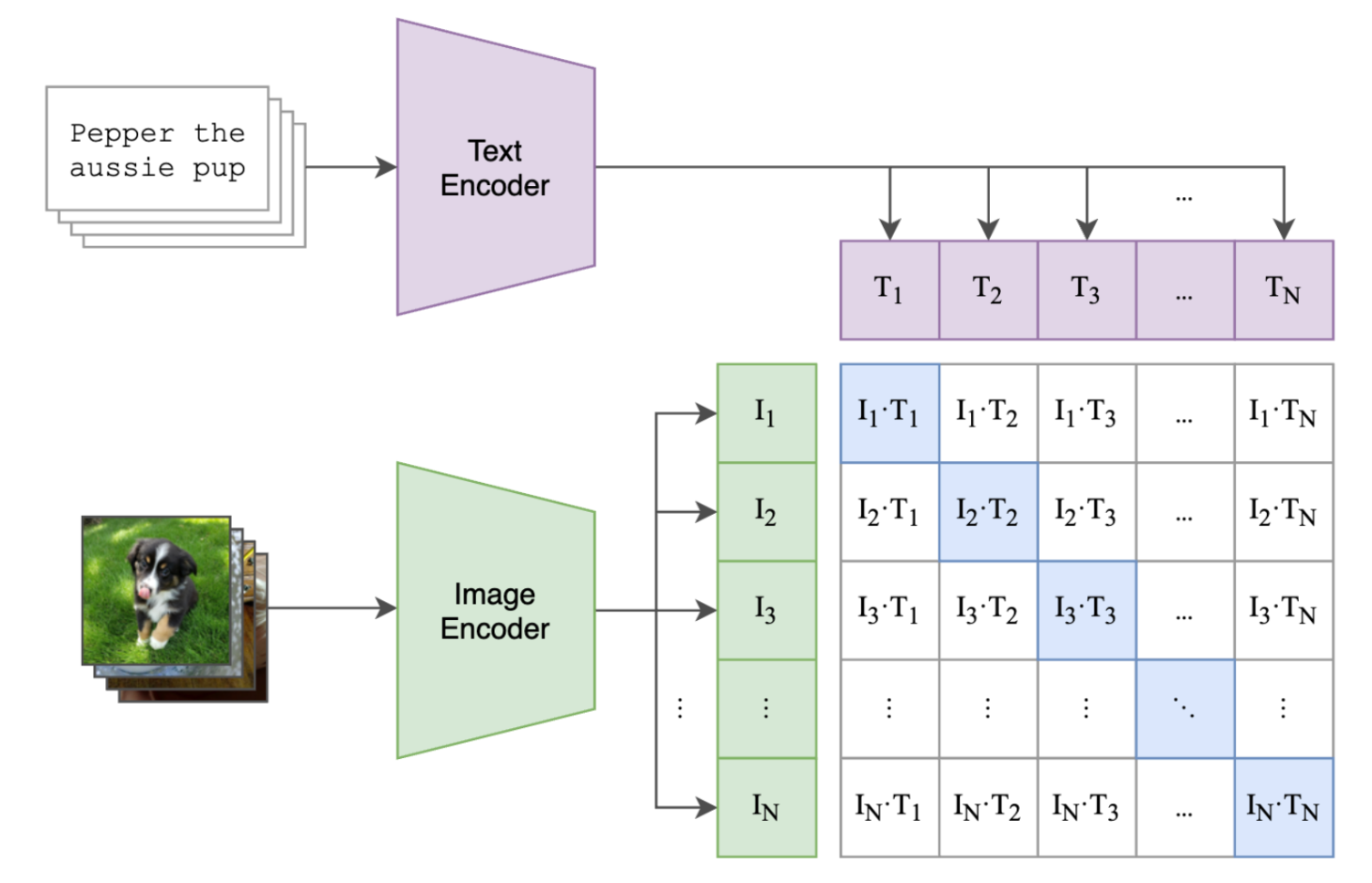
CLIP(Contrastive Language–Image Pretraining)模型实现监督信息的方式是通过对比学习。这是一种自监督学习方法,不需要传统的标注数据集。 CLIP 的基本工作原理:
-
图像和文本编码器:CLIP 由两个主要组成部分构成:一个图像编码器和一个文本编码器。图像编码器处理输入的图像,将其转换为向量表示(特征)。文本编码器则对应地处理文本数据,如标签或描述,并将其转换为向量表示。
-
生成特征向量:每张图像 ( I i ) ( I_i ) (Ii) 通过图像编码器生成一个向量,每个文本 ( T j ) ( T_j ) (Tj) 通过文本编码器生成一个向量。
-
对比损失函数:在训练过程中,CLIP 使用一个对比损失函数(如 InfoNCE),该损失函数鼓励模型将每个图像的向量表示靠近其对应文本的向量表示,同时将其远离不匹配文本的向量表示。具体来说,模型被训练以最大化图像和正确文本对之间的点积 ( I i ⋅ T i ) ( I_i \cdot T_i ) (Ii⋅Ti),同时最小化与错误配对的点积 ( I i ⋅ T j ≠ i ) ( I_i \cdot T_{j\neq i} ) (Ii⋅Tj=i)。
-
构建正负样本对:对于每个图像-文本对 ( I i , T i ) (I_i, T_i) (Ii,Ti),正确的配对被视为正样本,而该图像与数据集中其他所有文本 ( T j ≠ i ) ( T_{j\neq i} ) (Tj=i) 的配对被视为负样本。
通过这种方式,CLIP 可以在没有显式标注的情况下学习图像内容与文本描述之间的语义关系。训练完成后,CLIP 能够根据其文本描述识别图像,或者根据图像内容找到合适的文本标签。这种方法的优势在于其能够处理开放式任务,并对未见过的图像和文本描述具有较好的泛化能力。
代码实现
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.models import resnet50
from transformers import BertTokenizer, BertModel# 假设你已经有一个包含图像和文本对的 Dataset
class YourDataset(torch.utils.data.Dataset):# 初始化方法,加载数据等# 返回数据集大小# 获取单个样本的方法# 定义图像编码器
class ImageEncoder(nn.Module):def __init__(self):super(ImageEncoder, self).__init__()# 使用预训练的ResNet50作为图像编码器self.resnet = resnet50(pretrained=True)self.resnet.fc = nn.Linear(self.resnet.fc.in_features, 512) # 假设我们的特征空间大小为512def forward(self, images):return self.resnet(images)# 定义文本编码器
class TextEncoder(nn.Module):def __init__(self):super(TextEncoder, self).__init__()# 使用预训练的BERT作为文本编码器self.bert = BertModel.from_pretrained('bert-base-uncased')self.linear = nn.Linear(self.bert.config.hidden_size, 512) # 假设我们的特征空间大小为512def forward(self, input_ids, attention_mask):outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)pooled_output = outputs.pooler_outputreturn self.linear(pooled_output)# 对比损失函数
class ContrastiveLoss(nn.Module):def forward(self, image_features, text_features):# 计算图像和文本特征之间的相似度logits = image_features @ text_features.T# 使用温度缩放 softmaxtemperature = 0.07logits = logits / temperature# 对角线元素是正样本对的相似度labels = torch.arange(logits.size(0)).to(logits.device)loss = nn.CrossEntropyLoss()(logits, labels)return loss# 实例化模型和损失函数
image_encoder = ImageEncoder()
text_encoder = TextEncoder()
contrastive_loss = ContrastiveLoss()# 优化器
params = list(image_encoder.parameters()) + list(text_encoder.parameters())
optimizer = optim.Adam(params, lr=1e-4)# 数据加载器
dataset = YourDataset()
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)# 训练循环
for epoch in range(num_epochs):for images, texts in data_loader:# 对图像和文本进行编码image_features = image_encoder(images)input_ids, attention_mask = texts # 假设这些是经过BERT Tokenizer处理的文本text_features = text_encoder(input_ids, attention_mask)# 计算对比损失loss = contrastive_loss(image_features, text_features)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {epoch}: Loss {loss.item()}")注意:这个代码提供了一个高级概述,并没有涉及一些实际实现中的细节,比如数据预处理、设备管理(CPU/GPU)、模型保存和加载、评估逻辑等。
可以考虑使用 OpenAI 发布的官方代码库或者像 transformers 这样的第三方库,它们提供了预训练的 CLIP 模型和方便的接口。
衡量相似度
在构建多模态模型如 CLIP 时,可以使用多种方法来衡量图像表示和文本表示之间的相似度。两种常用的方法是点积(dot product)和余弦相似度(cosine similarity)。
点积(Dot Product)
点积直接计算两个向量的对应元素的乘积之和。如果两个向量在相同维度的数值都很大且符号相同(即都是正数或都是负数),它们的点积就会很大。
余弦相似度(Cosine Similarity)
余弦相似度是通过测量两个向量之间的夹角的余弦值来确定它们之间的相似度。计算公式为两个向量的点积除以它们各自范数(norm)的乘积。这样,余弦相似度主要关注向量的方向而不是其大小。
区别
- 规范化:余弦相似度在计算时对向量进行了规范化处理,它不受向量长度的影响,只反映方向上的相似性;而点积会受到向量长度的影响。
- 解释性:点积可以直接解释为向量元素间的相互作用强度,而余弦相似度表示方向一致性的度量。
- 范围:余弦相似度的取值范围为 [-1, 1],而点积的范围可以是任意实数。
扩散模型与CLIP

在结合 CLIP 架构时,可以采取以下步骤:
-
文本编码器:CLIP 的文本编码器可以用来处理文本输入,生成与文本描述相匹配的语义表示。
-
图像编码器:同样地,CLIP 的图像编码器可以处理图像输入,为现有的图像生成高层次的特征表示。
-
条件输入:在扩散模型中,可以将这些来自 CLIP 的语义表示作为条件输入,引导生成过程以确保最终产生的图像与给定的文本描述相匹配。
-
降噪 U-Net:在扩散模型中,降噪 U-Net 用于在每个扩散步骤中估计和移除噪声,从而逐步重建图像。在结合了 CLIP 后,U-Net 可以被调整以接受来自 CLIP 的条件表示作为额外的输入,通过交叉注意(cross-attention)机制来集成文本和图像信息。
-
交叉注意机制:这是一个关键的集成点,在 U-Net 的每个层次中,可以通过交叉注意模块将文本的条件表示与图像的特征结合起来。这样,生成过程在每一步都会考虑到文本描述的语义内容。
-
训练过程:在训练扩散模型时,需要确保文本条件信息被正确地用于指导图像的生成。这可能涉及调整损失函数,以奖励那些更好地与文本描述相匹配的图像。
CLIP 开源项目
OpenAI 只是开源了 CLIP 模型的权重,并没有开源对应的 4 亿图文对。后来的学者便开始复现 OpenAI 的工作。比较有代表性的工作包括 OpenCLIP、ChineseCLIP 和 EVA-CLIP。
-
OpenCLIP 是社区驱动的,目的是复现 OpenAI 的 CLIP 模型。这个项目已经在多个数据源和计算预算上训练了多个模型,从小规模实验到较大规模实验,包括在如 LAION-400M、LAION-2B 和 DataComp-1B 等数据集上训练的模型。 https://github.com/mlfoundations/open_clip
-
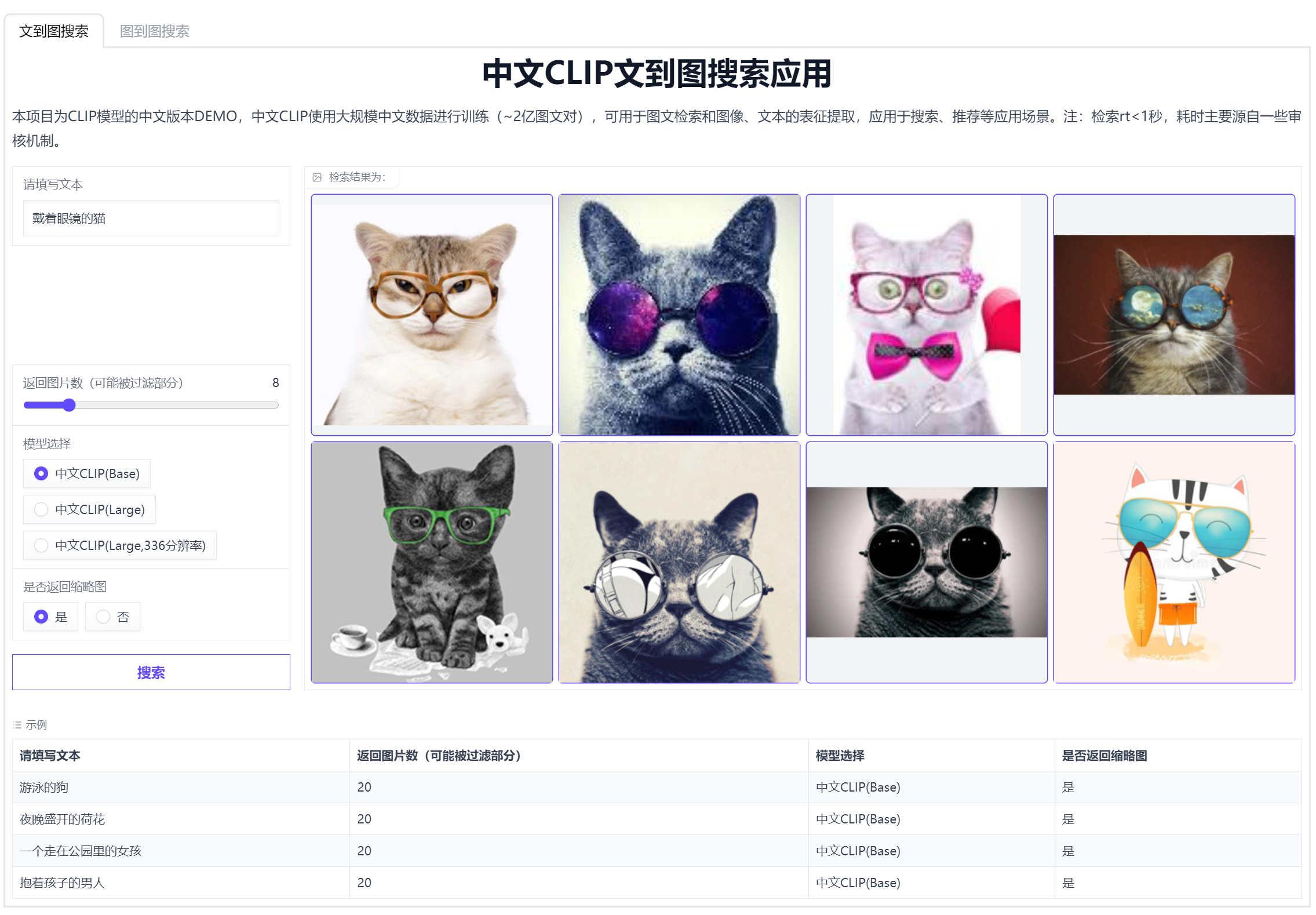
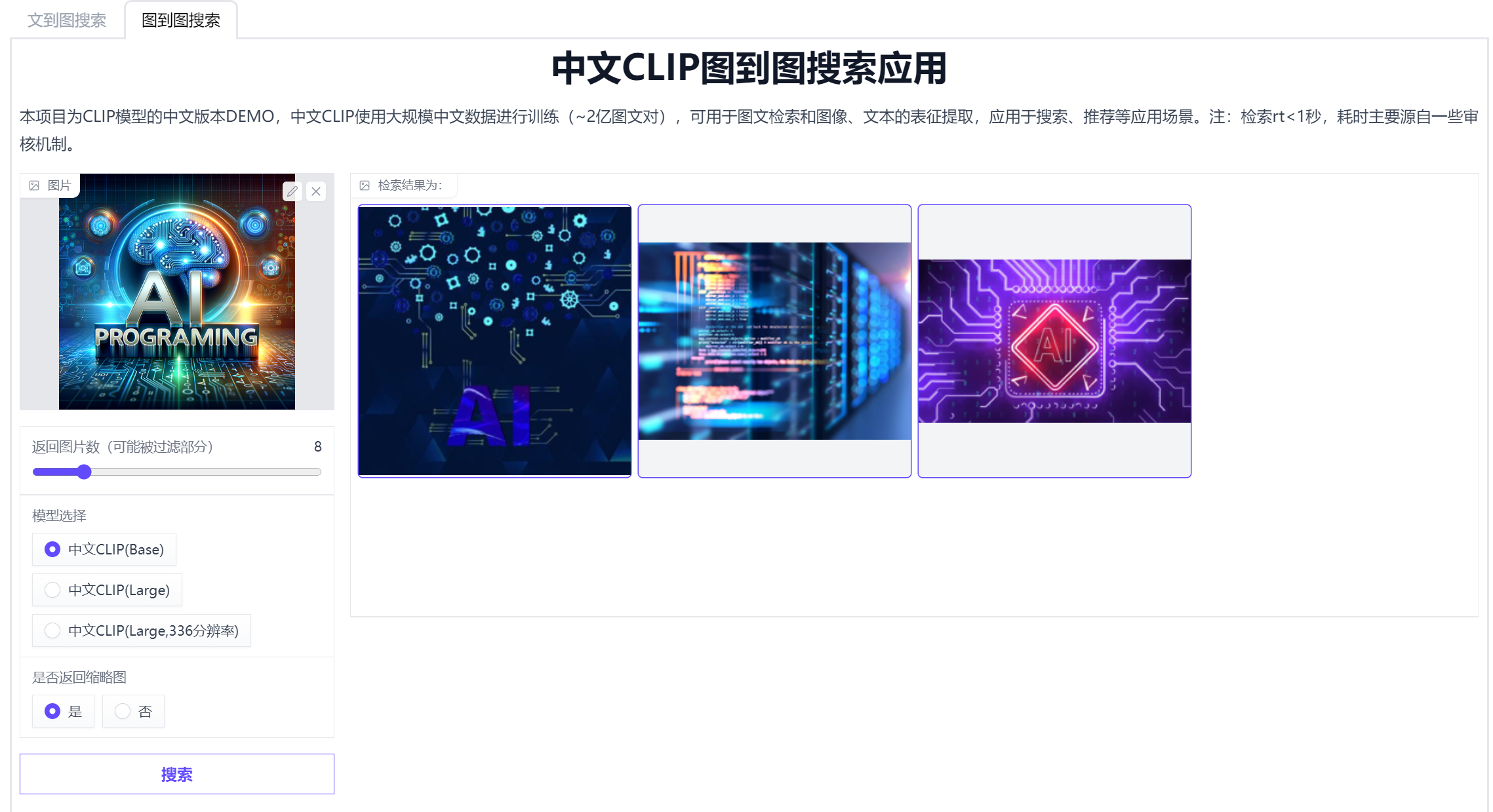
ChineseCLIP 是 OpenAI CLIP 模型的中文版本,它使用了大约2亿的中文图文对进行训练,以实现中文领域的图文特征计算、跨模态检索和零样本图片分类等任务。https://github.com/OFA-Sys/Chinese-CLIP
-
EVA-CLIP 使用了约910万的数据对进行预训练,采用CLIP的经典网络结构。它是目前效果最好的开源中文CLIP模型之一,为中文多模态任务提供了有价值的预训练权重。https://github.com/THUDM/EvaClip
测试环境
https://modelscope.cn/studios/damo/chinese_clip_applications/summary