文章目录
- 1 前言
- 1.1 项目介绍
- 2 情感分类介绍
- 3 数据集
- 4 实现
- 4.1 数据预处理
- 4.2 构建网络
- 4.3 训练模型
- 4.4 模型评估
- 4.5 模型预测
- 5 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于GRU的 电影评论情感分析
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1.1 项目介绍
其实,很明显这个项目和微博谣言检测是一样的,也是个二分类的问题,因此,我们可以用到学长之前提到的各种方法,即:
朴素贝叶斯或者逻辑回归以及支持向量机都可以解决这个问题。
另外在深度学习中,我们可以用CNN-Text或者RNN以及LSTM等模型最好。
当然在构建网络中也相对简单,相对而言,LSTM就比较复杂了,为了让不同层次的同学们可以接受,学长就用了相对简单的GRU模型。
如果大家想了解LSTM。以后,学长会给大家详细介绍。
2 情感分类介绍
其实情感分析在自然语言处理中,情感分析一般指判断一段文本所表达的情绪状态,属于文本分类问题。一般而言:情绪类别:正面/负面。当然,这就是为什么本人在前面提到情感分析实际上也是二分类问题的原因。
3 数据集
学长本次使用的是非常典型的IMDB数据集。
该数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价。该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
查看其数据集的文件夹:这是train和test文件夹。
接下来就是以train文件夹介绍里面的内容
然后就是以neg文件夹介绍里面的内容,里面会有若干的text文件:
4 实现
4.1 数据预处理
#导入必要的包import zipfileimport osimport ioimport randomimport jsonimport matplotlib.pyplot as pltimport numpy as npimport paddleimport paddle.fluid as fluidfrom paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear, Embeddingfrom paddle.fluid.dygraph.base import to_variablefrom paddle.fluid.dygraph import GRUUnitimport paddle.dataset.imdb as imdb#加载字典def load_vocab():vocab = imdb.word_dict()return vocab#定义数据生成器class SentaProcessor(object):def __init__(self):self.vocab = load_vocab()def data_generator(self, batch_size, phase='train'):if phase == "train":return paddle.batch(paddle.reader.shuffle(imdb.train(self.vocab),25000), batch_size, drop_last=True)elif phase == "eval":return paddle.batch(imdb.test(self.vocab), batch_size,drop_last=True)else:raise ValueError("Unknown phase, which should be in ['train', 'eval']")步骤
-
首先导入必要的第三方库
-
接下来就是数据预处理,需要注意的是:数据是以数据标签的方式表示一个句子,因此,每个句子都是以一串整数来表示的,每个数字都是对应一个单词。当然,数据集就会有一个数据集字典,这个字典是训练数据中出现单词对应的数字标签。
4.2 构建网络
这次的GRU模型分为以下的几个步骤
- 定义网络
- 定义损失函数
- 定义优化算法
具体实现如下
#定义动态GRU
class DynamicGRU(fluid.dygraph.Layer):
def init(self,
size,
param_attr=None,
bias_attr=None,
is_reverse=False,
gate_activation=‘sigmoid’,
candidate_activation=‘relu’,
h_0=None,
origin_mode=False,
):
super(DynamicGRU, self).init()
self.gru_unit = GRUUnit(
size * 3,
param_attr=param_attr,
bias_attr=bias_attr,
activation=candidate_activation,
gate_activation=gate_activation,
origin_mode=origin_mode)
self.size = size
self.h_0 = h_0
self.is_reverse = is_reverse
def forward(self, inputs):
hidden = self.h_0
res = []
for i in range(inputs.shape[1]):
if self.is_reverse:
i = inputs.shape[1] - 1 - i
input_ = inputs[ :, i:i+1, :]
input_ = fluid.layers.reshape(input_, [-1, input_.shape[2]], inplace=False)
hidden, reset, gate = self.gru_unit(input_, hidden)
hidden_ = fluid.layers.reshape(hidden, [-1, 1, hidden.shape[1]], inplace=False)
res.append(hidden_)
if self.is_reverse:
res = res[::-1]
res = fluid.layers.concat(res, axis=1)
return res
class GRU(fluid.dygraph.Layer):def __init__(self):super(GRU, self).__init__()self.dict_dim = train_parameters["vocab_size"]self.emb_dim = 128self.hid_dim = 128self.fc_hid_dim = 96self.class_dim = 2self.batch_size = train_parameters["batch_size"]self.seq_len = train_parameters["padding_size"]self.embedding = Embedding(size=[self.dict_dim + 1, self.emb_dim],dtype='float32',param_attr=fluid.ParamAttr(learning_rate=30),is_sparse=False)h_0 = np.zeros((self.batch_size, self.hid_dim), dtype="float32")h_0 = to_variable(h_0)self._fc1 = Linear(input_dim=self.hid_dim, output_dim=self.hid_dim*3)self._fc2 = Linear(input_dim=self.hid_dim, output_dim=self.fc_hid_dim, act="relu")self._fc_prediction = Linear(input_dim=self.fc_hid_dim,output_dim=self.class_dim,act="softmax")self._gru = DynamicGRU(size=self.hid_dim, h_0=h_0)def forward(self, inputs, label=None):emb = self.embedding(inputs)o_np_mask =to_variable(inputs.numpy().reshape(-1,1) != self.dict_dim).astype('float32')mask_emb = fluid.layers.expand(to_variable(o_np_mask), [1, self.hid_dim])emb = emb * mask_embemb = fluid.layers.reshape(emb, shape=[self.batch_size, -1, self.hid_dim])fc_1 = self._fc1(emb)gru_hidden = self._gru(fc_1)gru_hidden = fluid.layers.reduce_max(gru_hidden, dim=1)tanh_1 = fluid.layers.tanh(gru_hidden)fc_2 = self._fc2(tanh_1)prediction = self._fc_prediction(fc_2)if label is not None:acc = fluid.layers.accuracy(prediction, label=label)return prediction, accelse:return prediction
4.3 训练模型
def train():
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)): # # 因为要进行很大规模的训练,因此我们用的是GPU,如果没有安装GPU的可以使用下面一句,把这句代码注释掉即可
# with fluid.dygraph.guard(place = fluid.CPUPlace()):
processor = SentaProcessor()train_data_generator = processor.data_generator(batch_size=train_parameters["batch_size"], phase='train')model = GRU()sgd_optimizer = fluid.optimizer.Adagrad(learning_rate=train_parameters["lr"],parameter_list=model.parameters())steps = 0Iters, total_loss, total_acc = [], [], []for eop in range(train_parameters["epoch"]):for batch_id, data in enumerate(train_data_generator()):steps += 1doc = to_variable(np.array([np.pad(x[0][0:train_parameters["padding_size"]], (0, train_parameters["padding_size"] - len(x[0][0:train_parameters["padding_size"]])),'constant',constant_values=(train_parameters["vocab_size"]))for x in data]).astype('int64').reshape(-1))label = to_variable(np.array([x[1] for x in data]).astype('int64').reshape(train_parameters["batch_size"], 1))model.train()prediction, acc = model(doc, label)loss = fluid.layers.cross_entropy(prediction, label)avg_loss = fluid.layers.mean(loss)avg_loss.backward()sgd_optimizer.minimize(avg_loss)model.clear_gradients()if steps % train_parameters["skip_steps"] == 0:Iters.append(steps)total_loss.append(avg_loss.numpy()[0])total_acc.append(acc.numpy()[0])print("step: %d, ave loss: %f, ave acc: %f" %(steps,avg_loss.numpy(),acc.numpy()))if steps % train_parameters["save_steps"] == 0:save_path = train_parameters["checkpoints"]+"/"+"save_dir_" + str(steps)print('save model to: ' + save_path)fluid.dygraph.save_dygraph(model.state_dict(),save_path)draw_train_process(Iters, total_loss, total_acc)

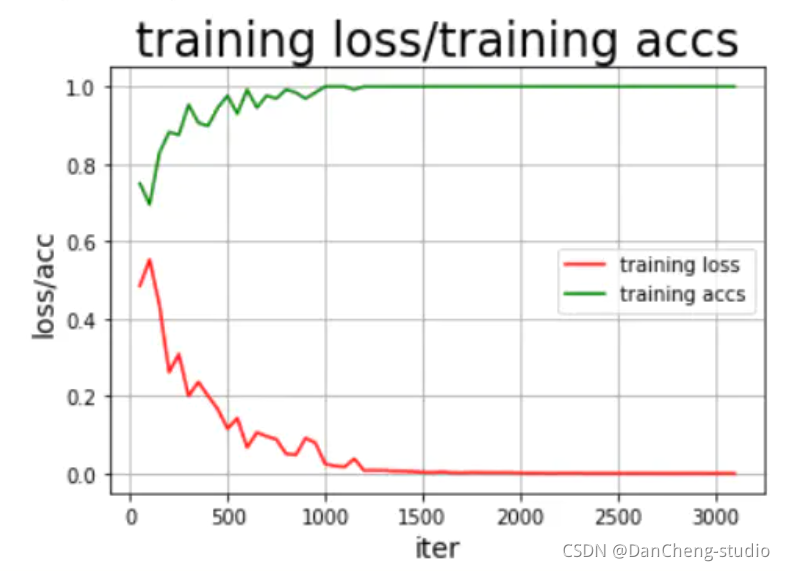
4.4 模型评估

结果还可以,这里说明的是,刚开始的模型训练评估不可能这么好,很明显是过拟合的问题,这就需要我们调整我们的epoch、batchsize、激活函数的选择以及优化器、学习率等各种参数,通过不断的调试、训练最好可以得到不错的结果,但是,如果还要更好的模型效果,其实可以将GRU模型换为更为合适的RNN中的LSTM以及bi-
LSTM模型会好很多。
4.5 模型预测
train_parameters[“batch_size”] = 1
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):sentences = 'this is a great movie'data = load_data(sentences)print(sentences)print(data)data_np = np.array(data)data_np = np.array(np.pad(data_np,(0,150-len(data_np)),"constant",constant_values =train_parameters["vocab_size"])).astype('int64').reshape(-1)infer_np_doc = to_variable(data_np)model_infer = GRU()model, _ = fluid.load_dygraph("data/save_dir_750.pdparams")model_infer.load_dict(model)model_infer.eval()result = model_infer(infer_np_doc)print('预测结果为:正面概率为:%0.5f,负面概率为:%0.5f' % (result.numpy()[0][0],result.numpy()[0][1]))

训练的结果还是挺满意的,到此为止,我们的本次项目实验到此结束。
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate