©PaperWeekly 原创 · 作者 | 郭必扬
单位 | 上海财经大学信息管理与工程学院AI Lab

论文标题:
GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation
论文作者:
Biyang Guo, Yeyun Gong, Yelong Shen, Songqiao Han, Hailiang Huang, Nan Duan, Weizhu Chen
作者单位:
上海财经大学信息管理与工程学院 AI Lab;微软亚洲研究院;微软 Azure AI
论文链接:
https://arxiv.org/abs/2211.10330
Github链接:
https://github.com/beyondguo/genius(更多相关工作见:https://github.com/microsoft/SCGLab)

论文简介
本文提出了一种基于草稿进行文本生成(sketch-based text generation)的预训练模型 GENIUS。GENIUS 模型可以根据你给定的少量的关键词、短语、片段,进行文本补全,从而构成一个完整、连贯的段落。这类似于我们人类写作时先打草稿再进行创作的过程。GENIUS 使用了大量通用语料进行预训练,在预训练中使用了一种 extreme-and-selective masking 的策略,这些使得 GENIUS 有强大的生成能力。下面是一些例子:

基于GENIUS的生成能力,本文还提出了一种新颖的数据增强方法——GeniusAug。GeniusAug 先从训练样本中抽取一个目标相关的 sketch,然后输入进 GENIUS 模型中进行新样本的生成。
相比于传统的数据增强方法,GeniusAug 既能够保存原样本的核心语义,还能够带来很大的多样性,从而使得模型在 in-distribution(ID)和 out-of-distribution(OOD)的情况都能得到显著的性能提升。实验验证 GeniusAug 可以通用于情感分类、主题分类、实体识别、机器阅读理解等多种 NLP 任务的数据增强。
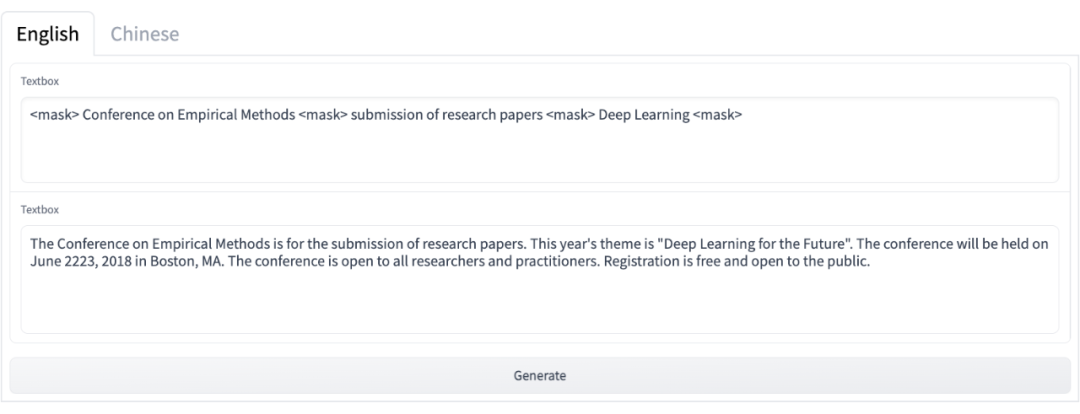
论文的代码和模型都已经开源,作者已经搭建了一个在线 demo,方便大家测试:
https://huggingface.co/spaces/beyond/genius

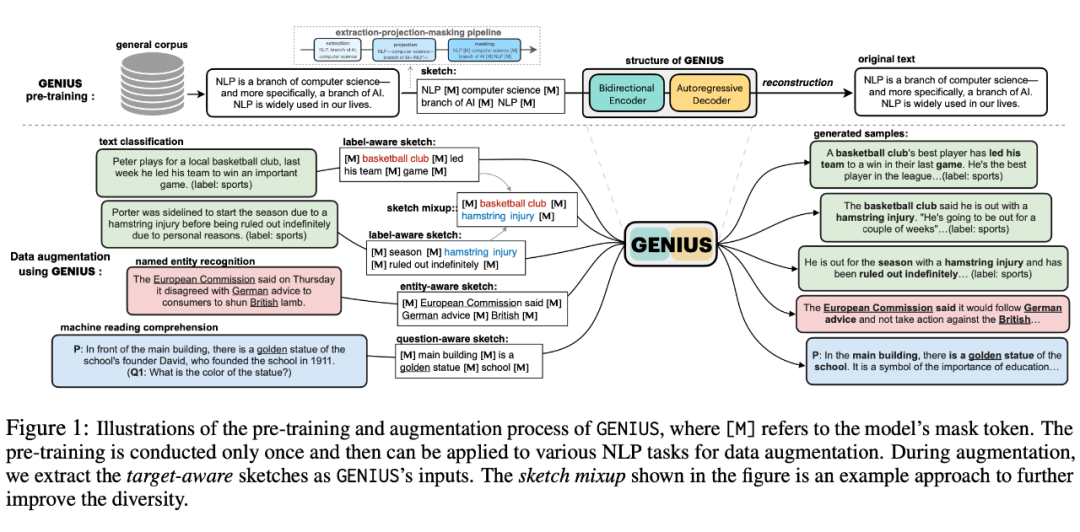
GENIUS的预训练
GENIUS 采用了一种 reconstruction from sketch 的预训练方式。先从完整文本中抽取一个 sketch,然后让模型根据 sketch 去重构这个文本。GENIUS 使用 BART [1] 模型进行初始化,在 C4 语料库上进行大规模预训练。
这里面的关键就是如何构造这样的 sketch,作者使用了一个 extraction-projection-masking 的 pipeline 来进行 sketch 构造:
1. extraction 使用无监督关键词抽取工具 YAKE [2],抽取最大为 3-gram 的关键词/短语,占比约为原文的 20%。这里抽取 3-gram 是为了抽取更大粒度的信息,从而降低重构难度。
2. projection 把抽取出来的关键信息,按照原文的位置、出现次数进行映射,且允许不同词语的重叠。
3. masking 把剩下的部分,使用单个的 MASK token 进行替换。
通过这样的三步,sketch 中就会保留原文的不同粒度的关键信息。经过作者统计,被 MASK 掉的内容平均占全文的 73%。
这个 sketch 的抽取步骤看似很简单,但是其中几个设计很关键:
1. 以往的文本重构预训练模型,都是采用 random masking 的策略,比如 BERT、BART、T5 等等,而且都只能采用比较小的 MASK 比例,本文认为 random 的策略,可能导致 MASK 的比例无法过大,而这又会限制模型的生成能力。
2. 抽取的出来的关键词,如何排列,以往的根据 keywords 生成文本的模型中,会直接按照抽取出来的顺序进行拼接,然后让模型去重构;本文认为这样也会增加重构的难度,使得预训练效果不佳;
3. 对抽取出来的关键信息,是直接拼接,还是使用 MASK token 进行拼接。作者也设计了实验来进行对比,发现使用 MASK token 来拼接可以有更好的效果。
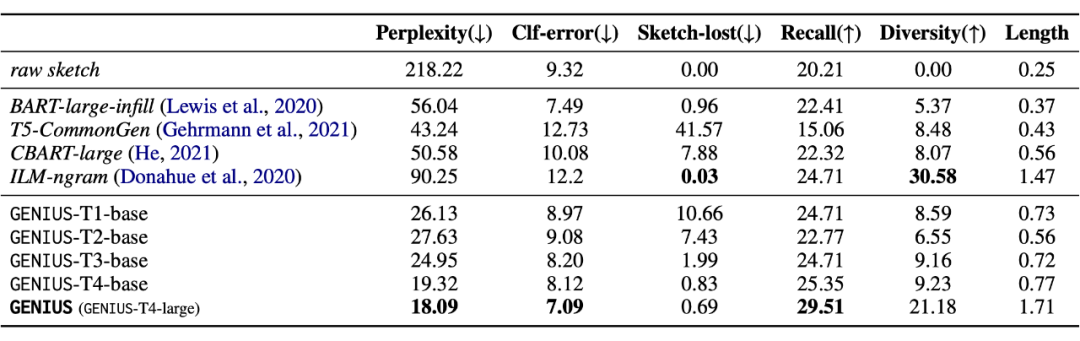
下图是作者对不同的 sketch 的构造方法进行的预训练效果的对比:
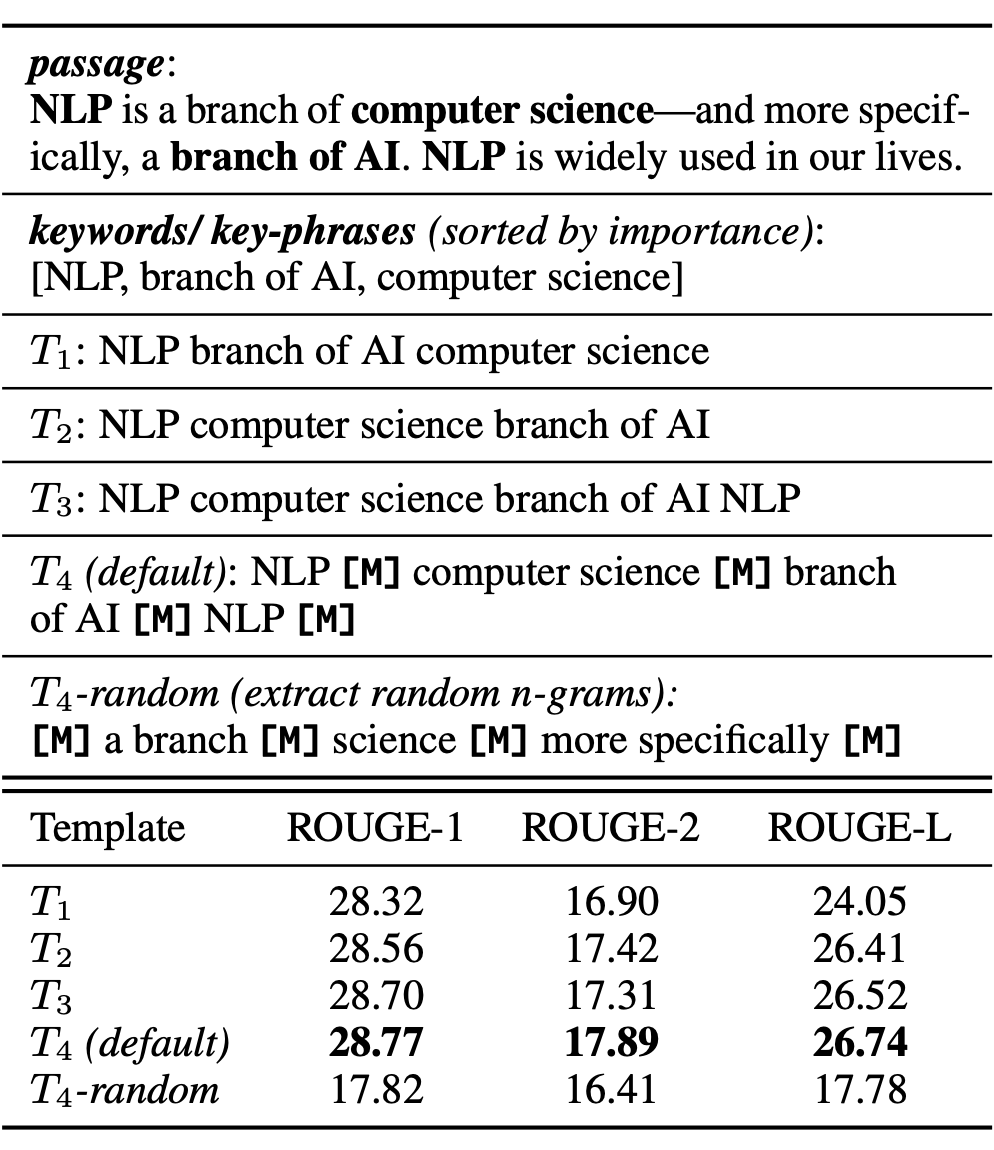
上图中,T4 是作者默认使用的sketch模板,其他的模板是作为对比,来验证模型模板的有效性。T1 就是抽取了关键词之后直接拼接作为 sketch,T2 则是按照原文的顺序进行关键词排列,T3 进一步允许了一个词出现多次,T4 在 T3 的基础上使用 MASK token 进行填补,T4-random 则是随机抽取词语来作为 sketch。
从结果发现,T4-random 的预训练效果最差,这验证了在这种机端 MASK 的情况下,随机选择一部分词来作为 sketch 是无法进行良好重构训练的。T2 效果优于 T1,说明了关键信息的按照原始顺序排列的重要性;T3 优于 T2,说明了允许这些信息出现多次、允许互相重叠是有益处的;T4(也就是默认模板)优于 T3,说明了使用 MASK token 作为连接是更有效的。
这些设计,降低了文本重构的难度,有利于训练,同时,T4 模板的设计,也更加贴近于 GENIUS 的 backbone——BART 的 text infilling 预训练目标,所以在继续预训练时,可以缓解灾难性遗忘的问题,使得在大规模继续预训练后能有良好的效果。
总的来说,GENIUS 的预训练,跟以往的基于文本重构的 denoising 预训练有着两点显著区别:
extreme masking:GENIUS 的 mask 比例可以高达 80%,而 BERT 系列、BART、T5 都只能 mask 很小一部分;
selective masking:GENIUS 是针对不那么重要的部分进行 mask,而之前的方法,基本都是 random mask 的方式。
2.1 实验
作者从新闻语料中抽取了 1000 条样本,抽取 sketch 进行 sketch-based text generation 任务,并对比了一系列相关模型,包括使用 text-infilling 目标进行训练的 BART [1]、根据词汇进行文本生成的 CBART [3],使用 CommonGen 训练的 keywords2text 模型以及 ILM(infilling language model)[4],GENIUS 在文本流畅性、多样性、保真度上都有优势:

根据这些例子可以看出,GENIUS 相比于其他 baseline,可以生成更长、更完整、更流畅的文本。

基于GENIUS的文本数据增强新方法–GeniusAug
数据增强是文本生成模型的重要应用之一,也是检验文本生成效果的重要手段。如果生成的文本可用于下游 NLP 任务的训练并带来性能提升,则可以说明文本生成的质量良好。
文本展示了 GENIUS 可作为一种通用的数据增强工具,应用于文本分类、实体识别、阅读理解等任务上。
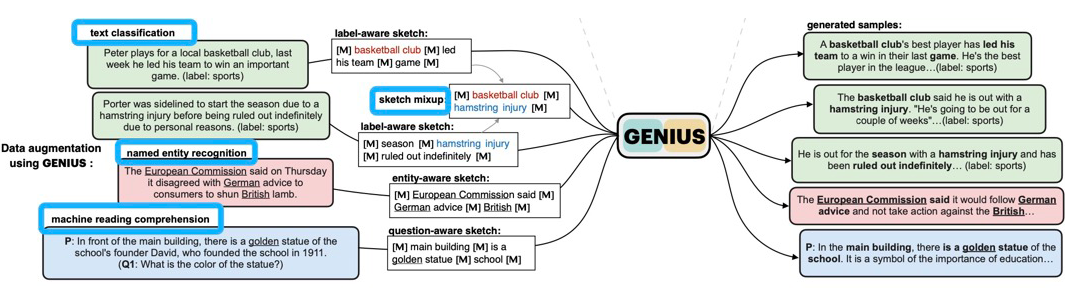
作者分析了传统的文本数据增强主要有两个问题:
有的方法太过于保守:例如基于文本编辑的 EDA [5],利用 MLM 模型进行词汇替换 [6] 等方法,只对原始文本进行极少量的改动,相当于给数据增加一些噪音。当改动过大时,这些方法甚至会损害模型的性能;其他基于 paraphrasing 的方法,例如 back-translation [7],也只是对原文的表达进行了一定的风格改变,整体结构、语义依然保持基本不变。这些特点,使得增强的样本缺乏多样性。
有的方法太过于激进:例如基于 GPT-2 模型在下游数据集上进一步微调,从而能够给定一个标签生成全新的训练样本 [8,9]。这些方法能产生多样化的样本,但是也同时有很大的风险产生不合理的样本,因此往往需要进一步筛选才能使用。
根据 GENIUS 的 sketch-based text generation 的思想,作者提出了 GeniusAug 方法,在进行多样化样本增强的情况下,还能够尽可能保留任务相关的语义,从而达到了保守和激进中间的一个平衡。
3.1 方法
具体方法分为两步:
1. target-aware sketch extraction
在 GENIUS 的预训练中,我们是通过无监督抽取工具进行抽取关键信息的。在数据增强的场景下,我们采用另一种方法——target-aware sketch extraction,抽取跟任务相关的部分作为关键信息。
假设原始样本为 , 其任务相关信息(target-related information,TRI)为 ,文本中的 n-gram 分为为,我们首先使用一个 encoder 来对这些信息进行编码,得到 , 和 ,然后我们通过下面公式来计算每个 n-gram 的得分:
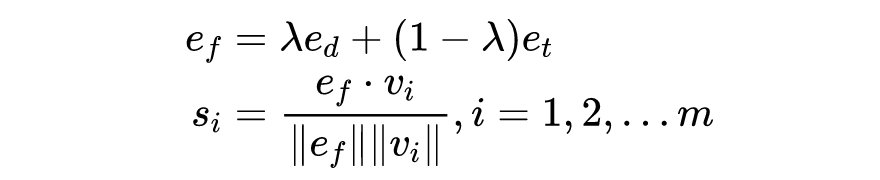
其中, 是一个 fusing embedding,综合了原始文本和 TRI 的语义,然后再通过余弦相似度来对 n-gram 进行排序,选择得分最高的 N 个作为 target-aware 的关键信息。
这里的 TRI,对于不同的任务我们有不同的选取,对于文本分类任务,TRI 就是文本的标签,或者标签的描述;对于 NER 任务,TRI 就是实体;对于阅读理解任务,TRI 就是给定的 question。我们可以认为这里抽取出来的信息,就是对具体任务最有帮助的信息,然后 GENIUS 模型根据这样的 sketch 进行生成,对这些关键信息构造新的上下文,从而构成新的样本。
2. GENIUS generation
得到 target-aware sketch 之后,就可以直接使用 GENIUS 进行文本生成了。但是,作者进一步提出了两种方式,一种可以进一步提升样本的质量,一种可以进一步提升样本的多样性:
attribute controlling:作者发现 GENIUS 除了根据 sketch 进行生成外,还具有“属性控制”的能力,我们可以在 sketch 的前面,增加一个 prompt,来使得生成的样本,更加贴近我们设置的某个属性。这个特点,对于数据增强尤其有用,比如对于文本分类任务,我们可以把属性设置为样本的标签,这样在文本生成的时候,就可以让生成的样本更加贴近某个类别。下面是一些属性控制的例子:

可以看到,同样的 sketch,在给定不同的 attribute 之后,可以生成不同主题的内容。
sketch-mixup:除了从某个样本中抽取 sketch 然后生成外,作者还提出了一种极大增加多样性的方式,借助了 Mixup 的思想,我们可以把来自不同样本的 sketch 进行混合,得到一个新的 sketch,作者在后面的实验中,也验证了这种 mixup 的方式在一些任务下可以继续提升性能。
由于 GENIUS 模型已经在大量通用语料上进行了预训练,所以在数据增强场景下是“取之即用”的,不需要在下游数据集上进行微调。相比之下,C-BERT [6], LAMBADA [8] 等方法则需要再下游数据集上进行微调之后才能使用。但是,微调一般都是有增益的,所以作者在实验中也对比了微调的版本 GeniusAug-f。
3.2 实验
3.2.1 文本分类
作者在数据增强部分是主要实验是在文本分类上进行的。作者采用了 6 个文本分类数据集:Huffpost 新闻、BBC 新闻、20NG、Yahoo 问答、IMDB 和 SST2 情感分类,测试了在仅仅提供 n={50,100,200,500,1000} 条标注训练样本的情况下,不同的数据增强方法能带来多大的性能提升。
除此之外,作者还设计了 4 组 OOD 泛化实验,Huffpost 和 BBC 新闻拥有 5 个相同的新闻类别,而 IMDB 和 SST2 都是电影评价二分类,因此它们彼此之间可以互相进行测试,验证模型在样本分布发生较大改变之后是否能够保持较好的泛化能力。
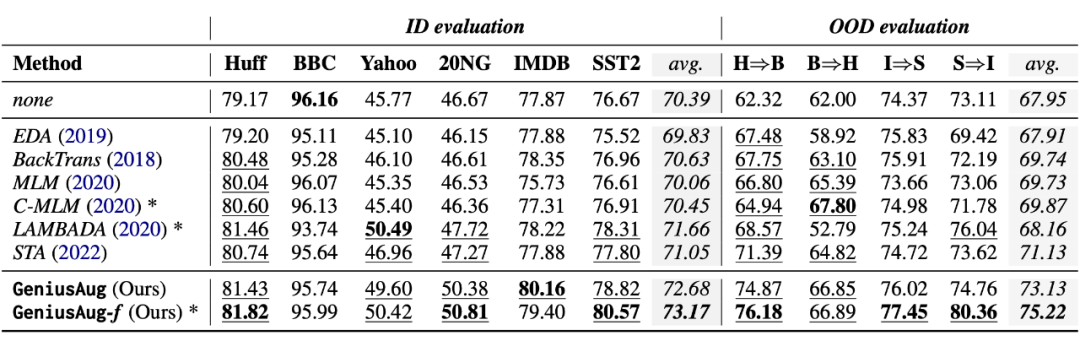
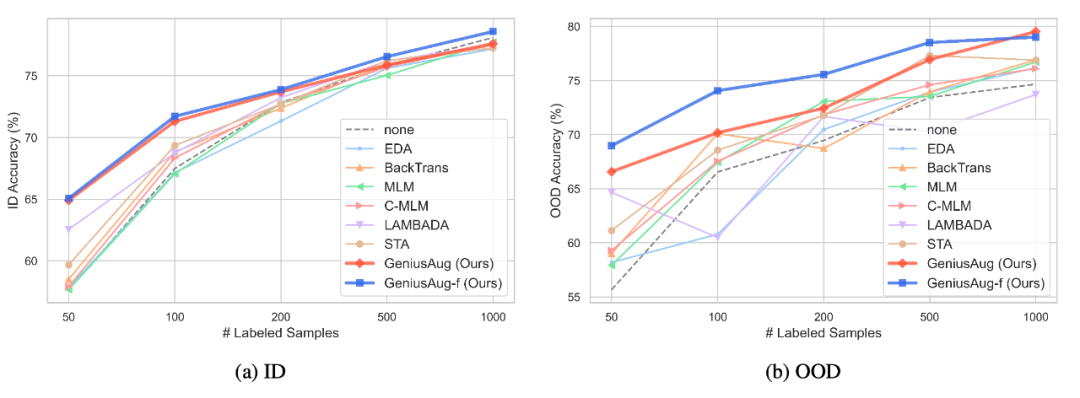
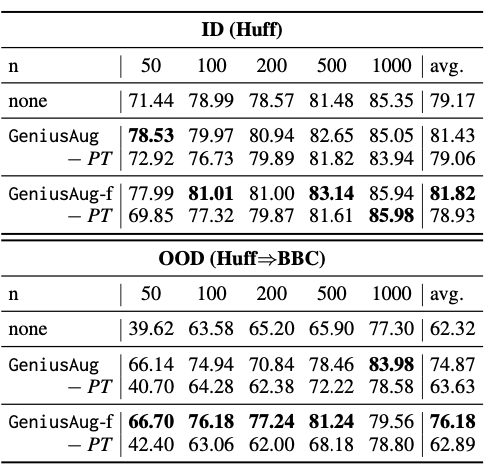
根据实验结果,GeniusAug 和 GeniusAug-f 在 ID 和 OOD 设置下,都取得了比其他 augmentation 方法更好的效果,尤其在 OOD 场景下。通过 target-aware sketch 抽取,使得模型可以保留任务的核心信息,通过 GENIUS 模型的生成,训练样本的多样性大大提高。这两方面,均对 OOD 泛化性能有很大帮助。
值得一提的是其中的另一个 baseline——STA [10],STA 是一种针对性文本数据增强方法,也涉及到任务相关信息的抽取,然后在增强的过程中根据词汇的不同角色进行针对性地文本编辑,因此 STA 对比其他 baseline 也可以取得比较好的效果。
然而,由于 STA 是一种基于规则的方法,产生的新样本可能不通顺,不借助语言模型,使得其多样性也收到限制,GeniusAug 则弥补了这方面的缺陷,在文本质量、多样性方面超越 STA,从而在下游任务上取得更好的效果。
接着,作者探究了在使用不同水平的分类模型时各个数据增强方法的效果(n=50):
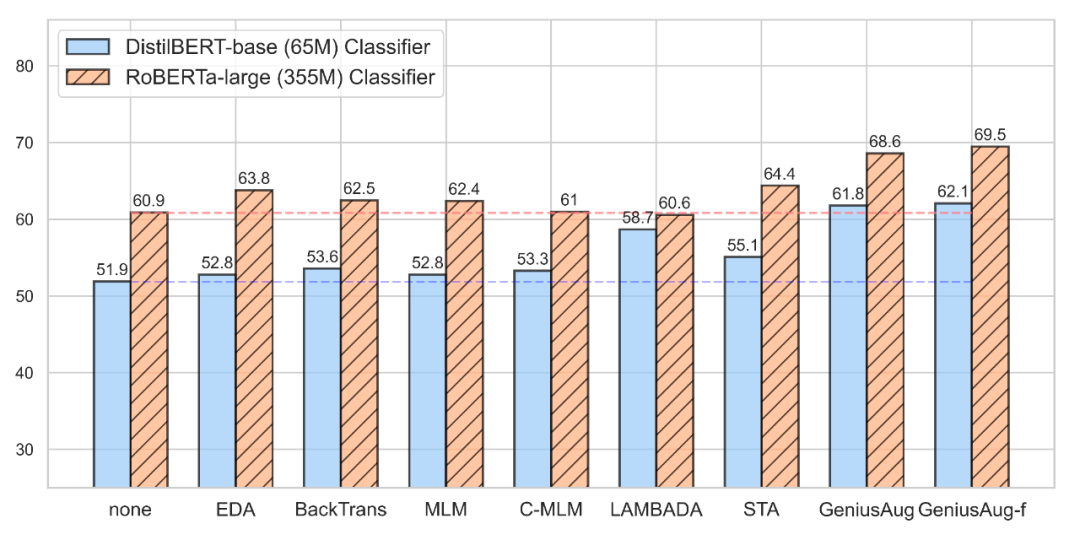
即使基线模型已经十分强大,GeniusAug 依然可以带来显著的性能提升。相比之下,其他方法带来的提升就微弱许多。有意思的事,当不使用数据增强时,RoBERTa-large 的性能是 60.9,distilBERT 的性能则为 51.9,而在 GeniusAug 的加持下,distilBERT 的性能可以跃升到 61.8,超越了 size 要大 5~6 倍的 RoBERTa-large 的性能。
前文中提到了使用 sketch-mixup 来进一步提高样本的多样性,作者也对此做了实验对比:
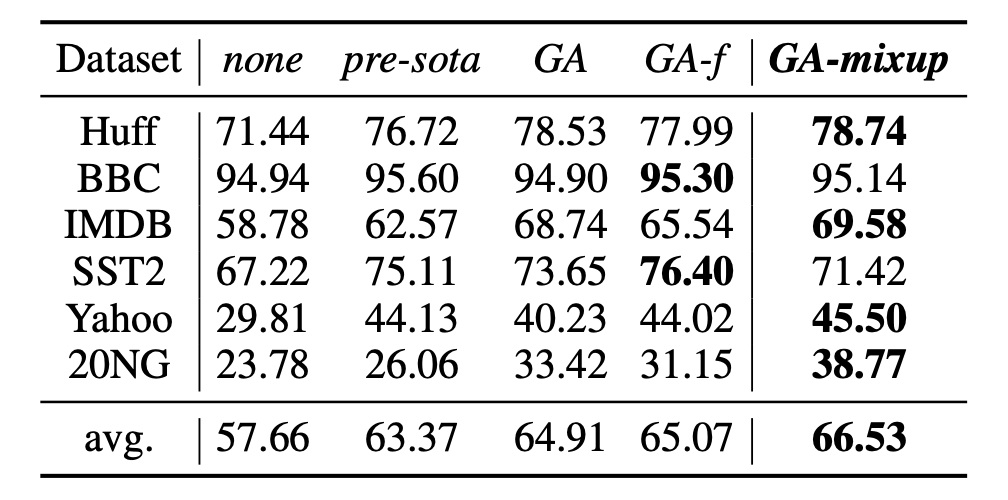
图中 GA 即为 GeniusAug 的简写,实验在低资源设置下(n=50)进行,GeniusAug-mixup 在所有数据集上都超越了 GeniusAug,甚至在 4/6 个数据集上超越了进一步微调的 GeniusAug-f。这个实验说明,sketch 的设计可能是一个很值得研究的问题,从而更加充分地利用 GENIUS 模型的能力。
3.2.2 NER和MRC任务
作者还在 NER 和 SQuAD 任务上做了相关实验,验证 GeniusAug 在其他 NLP 任务上的有效性。
对于 NER 任务,GeniusAug 通过抽取实体所在的片段来构成 sketch,然后通过 GENIUS 生成新的上下文。对于 MRC 任务,GeniusAug 则是先找出 answer 所在的句子,然后从该句子的上下文中抽取跟 question 相关的 sketch,然后交给 GENIUS 来生成新的上下文。
文章对比了几种常见的 baseline,实验结果如下:
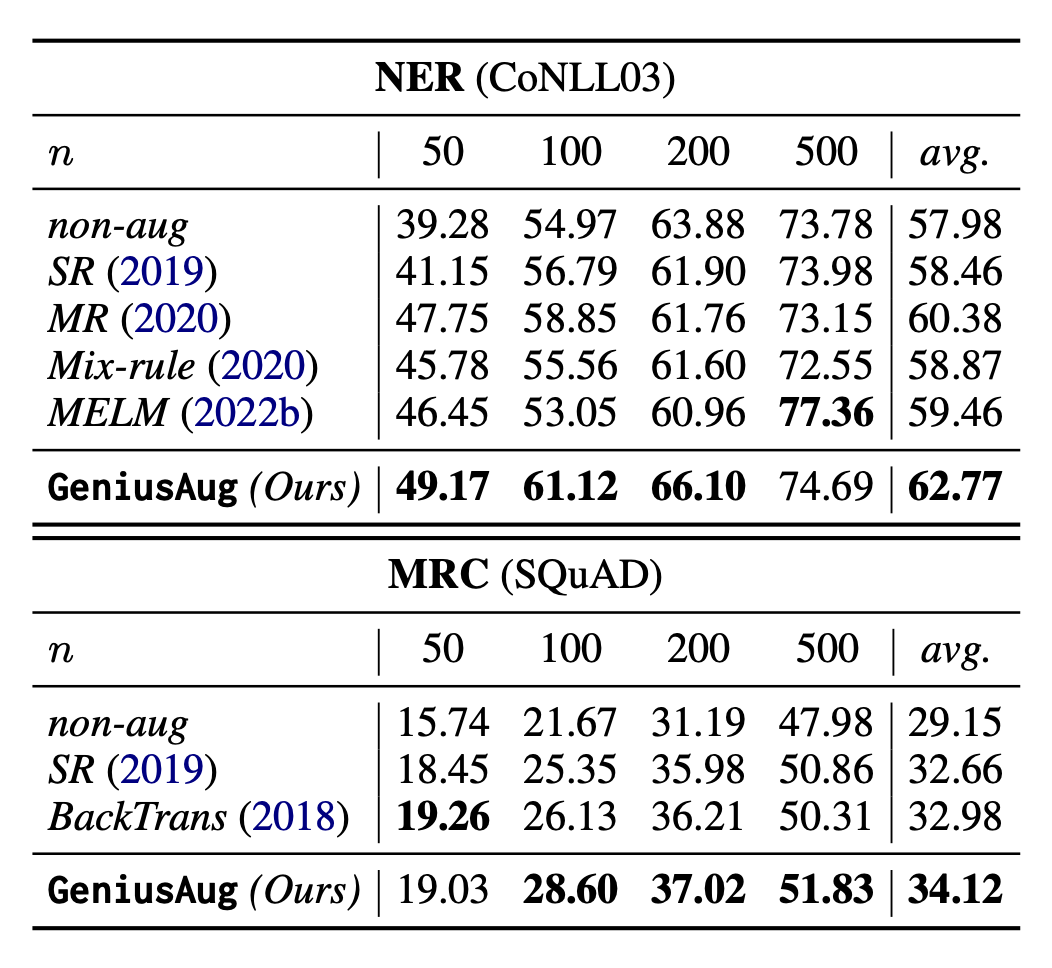
实验表明 GeniusAug 对其他 NLP 任务依然是强大的数据增强工具,而且无需在下游任务上进行微调。更多的 NLP 任务,作者团队还在继续探索中。
3.2.3 消融实验
最后作者做了两组消融实验,主要是为了探究两个问题:
1. GENIUS 的预训练,对于这种 sketch-based augmentation 方式是否真的有效。如果我们单纯的使用 BART 的 text-infilling,然后套用这里的 sketch-based augmentation,效果如何?
作者在 Huff 数据集上进行了实验,结果显示没有了 pre-training 之后,效果出现了显著的降低,尤其在低资源的场景下。但可以注意到,在 ID 的 setting 下,当训练样本达到 1000 时,没有预训练,但是使用 GENIUS 的方式微调,效果也可以很好,这也说明了这种 sketch-based augmentation 方式的有效性。然而,在 OOD setting 下,就算微调,效果依然不及有预训练的版本。
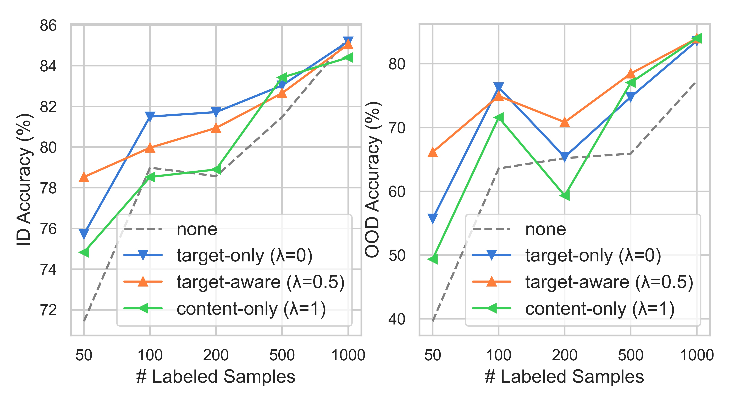
2. Target-aware sketch extraction 的策略是否比其他抽取 sketch 然后进行 augmentation 要更好。于是作者设计了两种其他方式:① 在抽取时,只考虑原文的语义,称为 content-only;② 在抽取时,仅考虑 target 的语义,称为 target-only。
然后在 Huff 上进行对比,见下图。实验发现,只使用 content 来抽取关键信息的话,效果是最差的。因为每个文本个性化的内容可能很多,不考虑标签,可能 sketch 并不是跟任务很相关,从而影响效果;而只考虑 target 的话,有时候表现还是挺不错的,但效果不太稳定;总体上看,同时考虑 content 和 target 的 target-aware 方法,是效果最好最稳定的。

总结&未来改进
GENIUS 模型是一种利用 extreme and selective masking 策略进行预训练的条件文本生成模型,这种预训练使得 GENIUS 模型可以给予几个极度残缺的文本进行补全和扩写,补充丰富的细节。GeniusAug 在 GENIUS 模型的基础上,探索了一种文本数据增强的新范式——基于草稿的数据增强,平衡了多样性和样本质量的两难问题,在众多 NLP 任务上表现出出色的效果。
当然,GENIUS 也存在着一些缺陷,作者在论文中专门设置了一章讨论 GENIUS 工作未来改进的方向。比如,目前使用的预训练数据量(两千万样本)依然没有足够大,使得模型可能在一些特殊场景下可能效果不好;对于一个 mask 部分,GENIUS 无法控制具体生成文本的长度,所以在一些需要精确控制的场景可能性能受限。
此外,基于 GENIUS 模型的数据增强方法 GeniusAug 也并不适用于所有 NLP 任务,比如 NLI 这种涉及到逻辑推理的问题,这是由于单纯的抽取 sketch 很难涵盖原文的逻辑关系,这使得生成的样本并不一定适用于下游任务。
更多模型的细节请参考论文,大家可以亲自上手测试一下模型 demo 来获得更直观地体验:
https://huggingface.co/spaces/beyond/genius


参考文献
[1] Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. 2020. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
[2] Yake! keyword extraction from single documents using multiple local features. 2020. Information Sciences.
[3] Parallel refinements for lexically constrained text generation with bart. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
[4] Enabling language models to fill in the blanks. 2020. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
[5] EDA: Easy data augmentation techniques for boosting performance on text classification tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing
[6] Conditional bert contextual augmentation. 2019. In International Conference on Computational Science
[7] Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv preprint arXiv:1804.09541.
[8] Do not have enough data? deep learning to the rescue! 2020. In Pro- ceedings of the AAAI Conference on Artificial Intelligence
[9] Data augmentation using pre-trained transformer models. 2020. In Proceedings of the 2nd Workshop on Life-long Learning for Spoken Language Systems
[10] Selective text augmentation with word roles for low-resource text classification. arXiv preprint arXiv:2209.01560.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·