为 Flink 量身定制的序列化框架
大家都知道现在大数据生态非常火,大多数技术组件都是运行在JVM上的,Flink也是运行在JVM上,基于JVM的数据分析引擎都需要将大量的数据存储在内存中,这就不得不面临JVM的一些问题,比如Java对象存储密度较低等。针对这些问题,最常用的方法就是实现一个显式的内存管理,也就是说用自定义的内存池来进行内存的分配回收,接着将序列化后的对象存储到内存块中。
现在Java生态圈中已经有许多序列化框架,比如说Java serialization, Kryo,Apache Avro等等。但是Flink依然是选择了自己定制的序列化框架,那么到底有什么意义呢?若Flink选择自己定制的序列化框架,对类型信息了解越多,可以在早期完成类型检查,更好的选取序列化方式,进行数据布局,节省数据的存储空间,直接操作二进制数据。

Flink在其内部构建了一套自己的类型系统,Flink现阶段支持的类型分类如图所示,从图中可以看到Flink类型可以分为基础类型Basic、数组Arrays、复合类型Composite、辅助类型Auxiliary、泛型和其它类型Generic。Flink支持任意的Java或是Scala类型。不需要像Hadoop一样去实现一个特定的接口org.apache.hadoop.io.Writable,Flink能够自动识别数据类型。
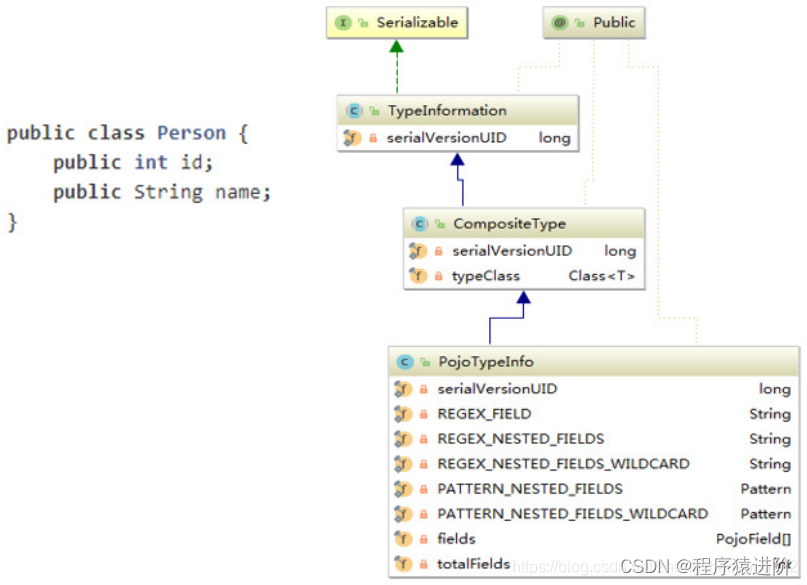
TypeInformation的思维导图如图所示,从图中可以看出,在Flink中每一个具体的类型都对应了一个具体的TypeInformation实现类,例如BasicTypeInformation中的IntegerTypeInformation和FractionalTypeInformation都具体的对应了一个TypeInformation。然后还有BasicArrayTypeInformation、CompositeType以及一些其它类型,也都具体对应了一个TypeInformation。
TypeInformation是Flink类型系统的核心类。对于用户自定义的Function来说,Flink需要一个类型信息来作为该函数的输入输出类型,即TypeInfomation。该类型信息类作为一个工具来生成对应类型的序列化器TypeSerializer,并用于执行语义检查,比如当一些字段在作为join或grouping的键时,检查这些字段是否在该类型中存在。
Flink 的序列化过程
在Flink序列化过程中,进行序列化操作必须要有序列化器,那么序列化器从何而来?
每一个具体的数据类型都对应一个TypeInformation的具体实现,每一个TypeInformation都会为对应的具体数据类型提供一个专属的序列化器。通过 Flink的序列化过程图可以看到TypeInformation会提供一个createSerialize()方法,通过这个方法就可以得到该类型进行数据序列化操作与反序化操作的对象TypeSerializer。
 对于大多数数据类型
对于大多数数据类型 Flink可以自动生成对应的序列化器,能非常高效地对数据集进行序列化和反序列化,比如,BasicTypeInfo、WritableTypeInfo等,但针对GenericTypeInfo类型,Flink会使用Kyro进行序列化和反序列化。其中,Tuple、Pojo和CaseClass类型是复合类型,它们可能嵌套一个或者多个数据类型。在这种情况下,它们的序列化器同样是复合的。它们会将内嵌类型的序列化委托给对应类型的序列化器。
简单的介绍下Pojo的类型规则,即在满足一些条件的情况下,才会选用Pojo的序列化进行相应的序列化与反序列化的一个操作。即类必须是Public的,且类有一个public的无参数构造函数,该类(以及所有超类)中的所有非静态no-static、非瞬态no-transient字段都是public的(和非最终的final)或者具有公共getter和setter方法,该方法遵循getter和setter的Java bean命名约定。当用户定义的数据类型无法识别为POJO类型时,必须将其作为GenericType处理并使用Kryo进行序列化。
Flink自带了很多TypeSerializer子类,大多数情况下各种自定义类型都是常用类型的排列组合,因而可以直接复用,如果内建的数据类型和序列化方式不能满足你的需求,Flink的类型信息系统也支持用户拓展。若用户有一些特殊的需求,只需要实现 TypeInformation、TypeSerializer和TypeComparator即可定制自己类型的序列化和比较大小方式,来提升数据类型在序列化和比较时的性能。
序列化就是将数据结构或者对象转换成一个二进制串的过程,在Java里面可以简单地理解成一个byte数组。而反序列化恰恰相反,就是将序列化过程中所生成的二进制串转换成数据结构或者对象的过程。下面就以内嵌型的Tuple3这个对象为例,简述一下它的序列化过程。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/8653144452544475bed9e725c06e6311.png)
Tuple3包含三个层面,一是int类型,一是double类型,还有一个是Person。Person包含两个字段,一是int型的ID,另一个是 String 类型的name,它在序列化操作时,会委托相应具体序列化的序列化器进行相应的序列化操作。从图中可以看到Tuple3 会把 int类型通过IntSerializer进行序列化操作,此时int只需要占用四个字节就可以了。根据int占用四个字节,这个能够体现出Flink可序列化过程中的一个优势,即在知道数据类型的前提下,可以更好的进行相应的序列化与反序列化操作。相反,如果采用Java的序列化,虽然能够存储更多的属性信息,但一次占据的存储空间会受到一定的损耗。Person类会被当成一个Pojo对象来进行处理,PojoSerializer序列化器会把一些属性信息使用一个字节存储起来。同样,其字段则采取相对应的序列化器进行相应序列化,在序列化完的结果中,可以看到所有的数据都是由MemorySegment去支持。
MemorySegment具有什么作用呢? MemorySegment在Flink中会将对象序列化到预分配的内存块上,它代表1个固定长度的内存,默认大小为32 kb。MemorySegment代表Flink中的一个最小的内存分配单元,相当于是Java的一个byte数组。 每条记录都会以序列化的形式存储在一个或多个MemorySegment中。
Flink 序列化的最佳实践
Flink常见的应用场景有四种,即注册子类型、注册自定义序列化器、添加类型提示、手动创建TypeInformation,具体如下:
【1】注册子类型: 如果函数签名只描述了超类型,但是它们实际上在执行期间使用了超类型的子类型,那么让Flink了解这些子类型会大大提高性能。可以在StreamExecutionEnvironment或ExecutionEnvironment中调用.registertype (clazz) 注册子类型信息。
【2】注册自定义序列化器: 对于不适用于自己的序列化框架的数据类型,Flink会使用Kryo来进行序列化,并不是所有的类型都与Kryo无缝连接,具体注册方法在下文介绍。
【3】添加类型提示: 有时,当Flink用尽各种手段都无法推测出泛型信息时,用户需要传入一个类型提示TypeHint,这个通常只在Java API中需要。
【4】手动创建TypeInformation: 在某些API调用中,这可能是必需的,因为Java的泛型类型擦除导致Flink无法推断数据类型。
其实在大多数情况下,用户不必担心序列化框架和注册类型,因为Flink已经提供了大量的序列化操作,不需要去定义自己的一些序列化器,但是在一些特殊场景下,需要去做一些相应的处理。
实践 - 类型声明: 类型声明去创建一个类型信息的对象是通过哪种方式?通常是用TypeInformation.of()方法来创建一个类型信息的对象,具体说明如下:
【1】对于非泛型类,直接传入class对象即可
PojoTypeInfo<Person> typeInfo = (PojoTypeInfo<Person>) TypeInformation.of(Person.class);
【2】对于泛型类,需要通过TypeHint来保存泛型类型信息
final TypeInfomation<Tuple2<Integer,Integer>> resultType = TypeInformation.of(new TypeHint<Tuple2<Integer,Integer>>(){});
【3】预定义常量: 如BasicTypeInfo,这个类定义了一系列常用类型的快捷方式,对于String、Boolean、Byte、Short、Integer、Long、Float、Double、Char等基本类型的类型声明,可以直接使用。而且Flink还提供了完全等价的Types类org.apache.flink.api.common.typeinfo.Types。特别需要注意的是,flink-table模块也有一个Types类org.apache.flink.table.api.Types,用于table模块内部的类型定义信息,用法稍有不同。使用IDE 的自动import时一定要小心。
【4】自定义TypeInfo和TypeInfoFactory: 通过自定义TypeInfo为任意类提供Flink原生内存管理(而非Kryo),使存
储更紧凑,运行时也更高效。需要注意在自定义类上使用@TypeInfo注解,随后创建相应的TypeInfoFactory并覆盖createTypeInfo()方法。
@TypeInfo(MyTupleTypeInfoFactory.class)
public class MyTuple<T0,T1>{public T0 myfield0;public T1 myfield1;
}public class MyTupleTypeInfoFactory extends TypeInfoFactory<MyTuple>{@Overridepublic TypeInformation<MyTuple> createTypeInfo(Type t, Map<String, TypeInfomation<?>> genericParameters){return new MyTupleTypeInfo(genericParameters.get("T0").genericParameters.get("T1"));}
}
实践 - 注册子类型
Flink认识父类,但不一定认识子类的一些独特特性,因此需要单独注册子类型。StreamExecutionEnvironment和 ExecutionEnvironment提供registerType()方法用来向Flink注册子类信息。
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.registerType(typeClass);
在registerType()方法内部,会使用TypeExtractor来提取类型信息,如上所示,获取到的类型信息属于PojoTypeInfo及其子类,那么需要将其注册到一起,否则统一交给Kryo去处理,Flink并不过问 ( 这种情况下性能会变差 )。
实践 - Kryo 序列化
对于Flink无法序列化的类型(例如用户自定义类型,没有registerType,也没有自定义TypeInfo和TypeInfoFactory),默认会交给 Kryo处理,如果Kryo仍然无法处理(例如Guava、Thrift、Protobuf等第三方库的一些类),有两种解决方案:
【1】强制使用Avro来代替Kryo
env.getConfig().enableForceAvro();
【2】为Kryo增加自定义的Serializer以增强Kryo的功能
env.getConfig().addDefaultKryoSerializer(clazz, serializer);
注:如果希望完全禁用Kryo(100%使用Flink的序列化机制),可以通过Kryoenv.getConfig().disableGenericTypes()的方式完成,但注意一切无法处理的类都将导致异常,这种对于调试非常有效。
Flink 通信层的序列化
Flink 的Task之间如果需要跨网络传输数据记录, 那么就需要将数据序列化之后写入NetworkBufferPool,然后下层的Task读出之后再进行反序列化操作,最后进行逻辑处理。为了使得记录以及事件能够被写入 Buffer,随后在消费时再从Buffer中读出,
Flink提供了数据记录序列化器RecordSerializer与反序列化器RecordDeserializer以及事件序列化器EventSerializer。
Function发送的数据被封装成SerializationDelegate,它将任意元素公开为IOReadableWritable以进行序列化,通过setInstance()来传入要序列化的数据。在Flink通信层的序列化中,有几个问题值得关注,具体如下:
【1】何时确定Function的输入输出类型?
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/369c0ff8c03c465ab7238c26d6cec965.png)
在构建StreamTransformation的时候通过TypeExtractor工具确定Function的输入输出类型。TypeExtractor类可以根据方法签名、子类信息等蛛丝马迹自动提取或恢复类型信息。
【2】何时确定Function的序列化 / 反序列化器?
构造StreamGraph时, 通过TypeInfomation的createSerializer()方法获取对应类型的序列化器TypeSerializer,并在addOperator()的过程中执行setSerializers() 操作,设置StreamConfig的TYPESERIALIZERIN1、TYPESERIALIZERIN2、 TYPESERIALIZEROUT_1属性。
【3】何时进行真正的序列化 / 反序列化操作? 这个过程与TypeSerializer又是怎么联系在一起的呢?
构造StreamGraph时, 通过TypeInfomation的createSerializer()方法获取对应类型的序列化器TypeSerializer,并在addOperator()的过程中执行setSerializers()操作,设置StreamConfig的TYPESERIALIZERIN1 、 TYPESERIALIZERIN2、 TYPESERIALIZEROUT_1属性。
【4】何时进行真正的序列化 / 反序列化操作? 这个过程与TypeSerializer又是怎么联系在一起的呢?
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/fbd072f386504d12911a5c3a80a3190f.png)
大家都应该清楚Task和StreamTask两个概念,Task是直接受TaskManager管理和调度的,而Task又会调用StreamTask,而StreamTask中真正封装了算子的处理逻辑。在run()方法中,首先将反序列化后的数据封装成StreamRecord交给算子处理;然后将处理结果通过Collector发送给下游 ( 在构建Collector时已经确定了SerializtionDelegate),并通过RecordWriter写入器将序列化后的结果写入DataOutput;最后序列化的操作交给SerializerDelegate处理,实际还是通过TypeSerializer的serialize()方法完成。