什么是布隆过滤器?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
布隆过滤器实现原理
布隆过滤器是一个bit向量或者说是一个bit数组(下面的数字为索引)。如下所示:

- 其最小单位为bit,初始化时全部置为0添加元素;
- 更新元素,利用K个Hash函数,将元素传入这K个Hash函数得到k个数字对应bit向量数组的K个下标,然后将这K个下标对应位置的值置为1。
- 查询元素:利用K个Hash函数,将元素传入这K个Hash函数得到k个数字对应bit向量数组的K个下标,如果这些下标对应的位置中有任何一个值为0,则被检测的元素一定不存在;如果这些位置的值都为1,则被检测的元素很可能(因为布隆过滤器存在误差)存在,但是不一定百分百存在。
- 删除元素:布隆过滤器不支持删除元素。如果我们因为某一个元素而将其对应的bit位的值变为0,那么如果这些bit位也是其他元素正在使用的,那么其他元素在查询时就会返回0,从而认为元素不存在而造成误判
举个例子
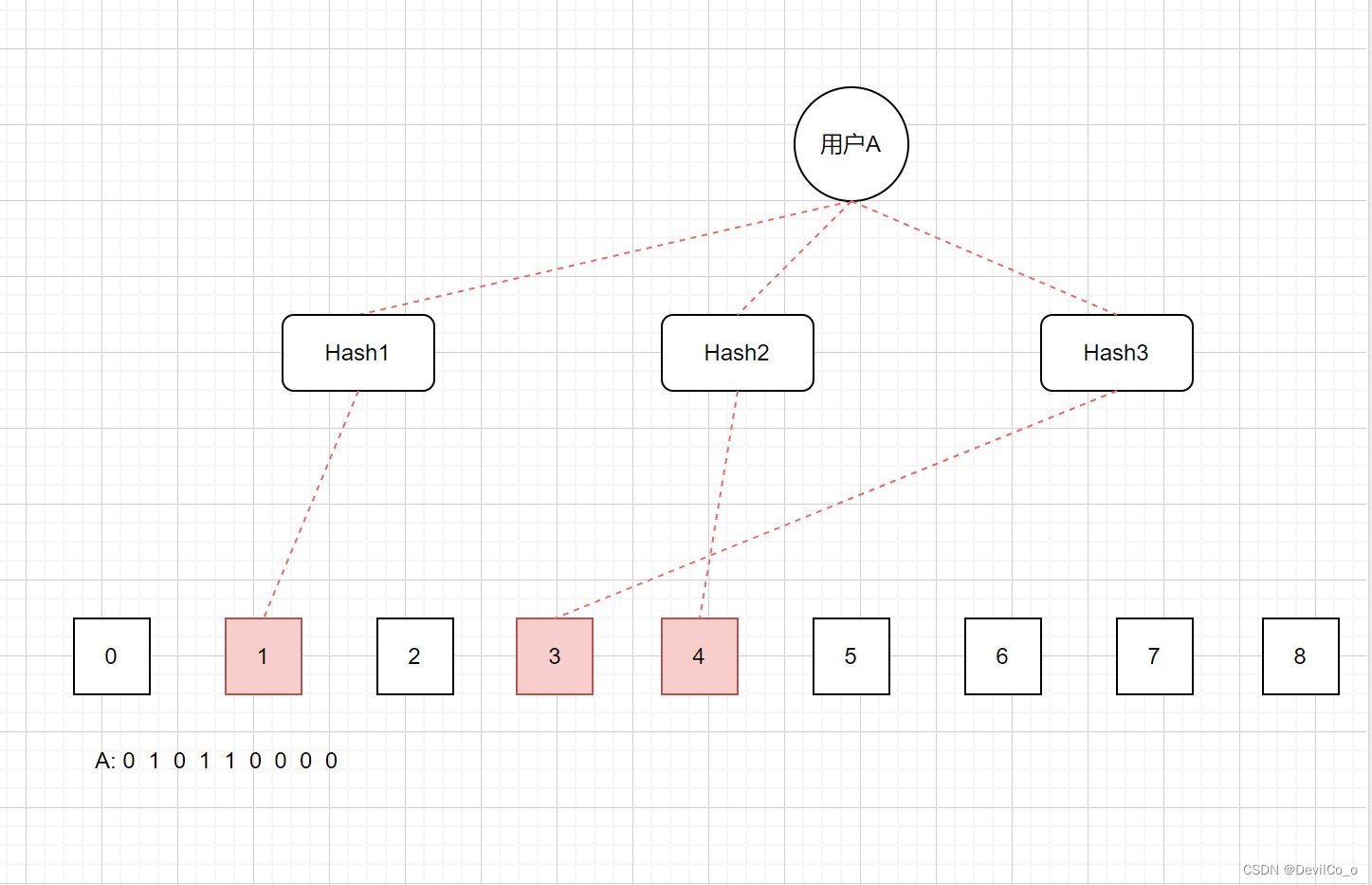
如何降低误判率?
使用多个Hash函数。
hash函数越多,误判的概率就越小。
但是,同时占用的空间也会越大,查询和插入操作的耗时也会更长,一般hash函数为3-5个。
常见的应用比较广的hash函数有MD5, SHA1, SHA256等。
布隆过滤器用在哪里?
优点
- 布隆过滤器可以高效地进行查询,用来告诉你“某样东西一定不存在或者可能存在”。
- 相比于传统的List、Set、Map等数据结构,它占用空间更少;3.
- 更新时更高效,布隆过滤器是位操作,而集合类型结构是操作对象。
缺点
- 其返回的结果判断存在的时候是存在误差的,判断不存在才是准确的;
- 不能提供删除操作;