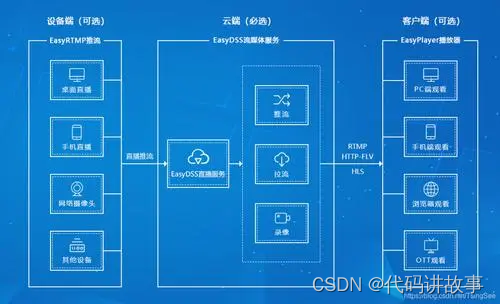
VOC数据图像和标签一起进行Resize
参加检测比赛的时候,很多时候工业原始数据尺度都比较大,如果对数据不提前进行处理,会导致数据在加载进内存时花费大量的时间,所以在执行训练程序之前需要将图像提前进行预处理。对于目标检测的数据,不只是将原始数据进行resize,边界框的坐标也要跟随一起进行resize。
如下,是今天测试需要用到的原始图像和他的标签。

<annotation><folder>VOC2012</folder><filename>2007_002266.jpg</filename><source><database>The VOC2007 Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image></source><size><width>500</width><height>373</height><depth>3</depth></size><segmented>1</segmented><object><name>aeroplane</name><pose>Rear</pose><truncated>1</truncated><difficult>0</difficult><bndbox><xmin>231</xmin><ymin>251</ymin><xmax>458</xmax><ymax>346</ymax></bndbox></object><object><name>aeroplane</name><pose>Left</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>5</xmin><ymin>118</ymin><xmax>499</xmax><ymax>258</ymax></bndbox></object>
</annotation>等比例缩放之后的结果如下。

单张图像resize
单张进行预处理的脚本如下。
# -*- coding: utf-8 -*-
# @File : PreProcessing.py
# @Author: 肆十二
# @Date : 2023/12/24
# @Desc : 同步缩放图片(等比例缩放无失真)和xml文件标注的anchor size
import glob
import xml.dom.minidom
import cv2img = cv2.imread("./demo.jpg")
height, width = img.shape[:2]# 定义缩放信息 以等比例缩放到416为例
scale=416/height
height=416
width=int(width*scale)dom = xml.dom.minidom.parse("./demo.xml")
root = dom.documentElement# 读取标注目标框
objects = root.getElementsByTagName("bndbox")for object in objects:xmin=object.getElementsByTagName("xmin")xmin_data=int(float(xmin[0].firstChild.data))# xmin[0].firstChild.data =str(int(xmin1 * x))ymin =object.getElementsByTagName("ymin")ymin_data = int(float(ymin[0].firstChild.data))xmax=object.getElementsByTagName("xmax")xmax_data = int(float(xmax[0].firstChild.data))ymax=object.getElementsByTagName("ymax")ymax_data = int(float(ymax[0].firstChild.data))# 更新xmlwidth_xml=root.getElementsByTagName("width")width_xml[0].firstChild.data=widthheight_xml = root.getElementsByTagName("height")height_xml[0].firstChild.data = heightxmin[0].firstChild.data = int(xmin_data*scale)ymin[0].firstChild.data = int(ymin_data*scale)xmax[0].firstChild.data = int(xmax_data*scale)ymax[0].firstChild.data = int(ymax_data*scale)# 另存更新后的文件with open('demo2.xml', 'w') as f:dom.writexml(f, addindent=' ', encoding='utf-8')# 测试缩放效果img = cv2.resize(img, (width, height))# xmin, ymin, xmax, ymax分别为xml读取的坐标信息left_top = (int(xmin_data*scale), int(ymin_data*scale))right_down= (int(xmax_data*scale), int(ymax_data*scale))cv2.rectangle(img, left_top, right_down, (255, 0, 0), 1)cv2.imwrite("result.jpg",img)批量resize
下面是批量对VOC格式数据集进行预处理的脚本,处理之后划分为37的比例就可以进行模型训练了。
import glob
import xml.dom.minidom
import cv2
from PIL import Image
import matplotlib.pyplot as plt
import os# 定义待批量裁剪图像的路径地址
IMAGE_INPUT_PATH = r'D:\code\data\JPEGImages'
XML_INPUT_PATH = r'D:\code\data\Annotations_new'
# 定义裁剪后的图像存放地址
IMAGE_OUTPUT_PATH = r'D:\code\data\JPEGImages_out'
XML_OUTPUT_PATH = r'D:\code\data\Annotations_out'
imglist = os.listdir(IMAGE_INPUT_PATH)
xmllist = os.listdir(XML_INPUT_PATH)for i in range(len(imglist)):# 每个图像全路径,这里有改进的空间image_input_fullname = IMAGE_INPUT_PATH + '/' + imglist[i]# xml_input_fullname = XML_INPUT_PATH + '/' + xmllist[i] xml_input_fullname = XML_INPUT_PATH + '/' + imglist[i].replace("jpg", "xml")image_output_fullname = IMAGE_OUTPUT_PATH + '/' + imglist[i]xml_output_fullname = XML_OUTPUT_PATH + '/' + xmllist[i]img = cv2.imread(image_input_fullname)height, width = img.shape[:2]# 定义缩放信息 以等比例缩放到416为例scale=400/heightheight=400width=int(width*scale)dom = xml.dom.minidom.parse(xml_input_fullname)root = dom.documentElement# 读取标注目标框objects = root.getElementsByTagName("bndbox")for object in objects:xmin=object.getElementsByTagName("xmin")xmin_data=int(float(xmin[0].firstChild.data))# xmin[0].firstChild.data =str(int(xmin1 * x))ymin =object.getElementsByTagName("ymin")ymin_data = int(float(ymin[0].firstChild.data))xmax=object.getElementsByTagName("xmax")xmax_data = int(float(xmax[0].firstChild.data))ymax=object.getElementsByTagName("ymax")ymax_data = int(float(ymax[0].firstChild.data))# 更新xmlwidth_xml=root.getElementsByTagName("width")width_xml[0].firstChild.data=widthheight_xml = root.getElementsByTagName("height")height_xml[0].firstChild.data = heightxmin[0].firstChild.data = int(xmin_data*scale)ymin[0].firstChild.data = int(ymin_data*scale)xmax[0].firstChild.data = int(xmax_data*scale)ymax[0].firstChild.data = int(ymax_data*scale)# 另存更新后的文件with open(xml_output_fullname, 'w') as f:dom.writexml(f, addindent=' ', encoding='utf-8')# 测试缩放效果img = cv2.resize(img, (width, height))'''# xmin, ymin, xmax, ymax分别为xml读取的坐标信息left_top = (int(xmin_data*scale), int(ymin_data*scale))right_down= (int(xmax_data*scale), int(ymax_data*scale))cv2.rectangle(img, left_top, right_down, (255, 0, 0), 1)'''cv2.imwrite(image_output_fullname,img)
总结
当前的目标检测框架中,模型方面基本都已经固定下来,YOLO或者RCNN,靠模型很难取得大规模的增点,所以这个时候从图像的角度进行入手显得非常重要,这里推荐大家使用一个专业的切图工具。
链接如下:GitHub - obss/sahi: Framework agnostic sliced/tiled inference + interactive ui + error analysis plots
碎碎念:数据预处理真的很关键啊,好的数据预处理真的可以节省大量的时间。