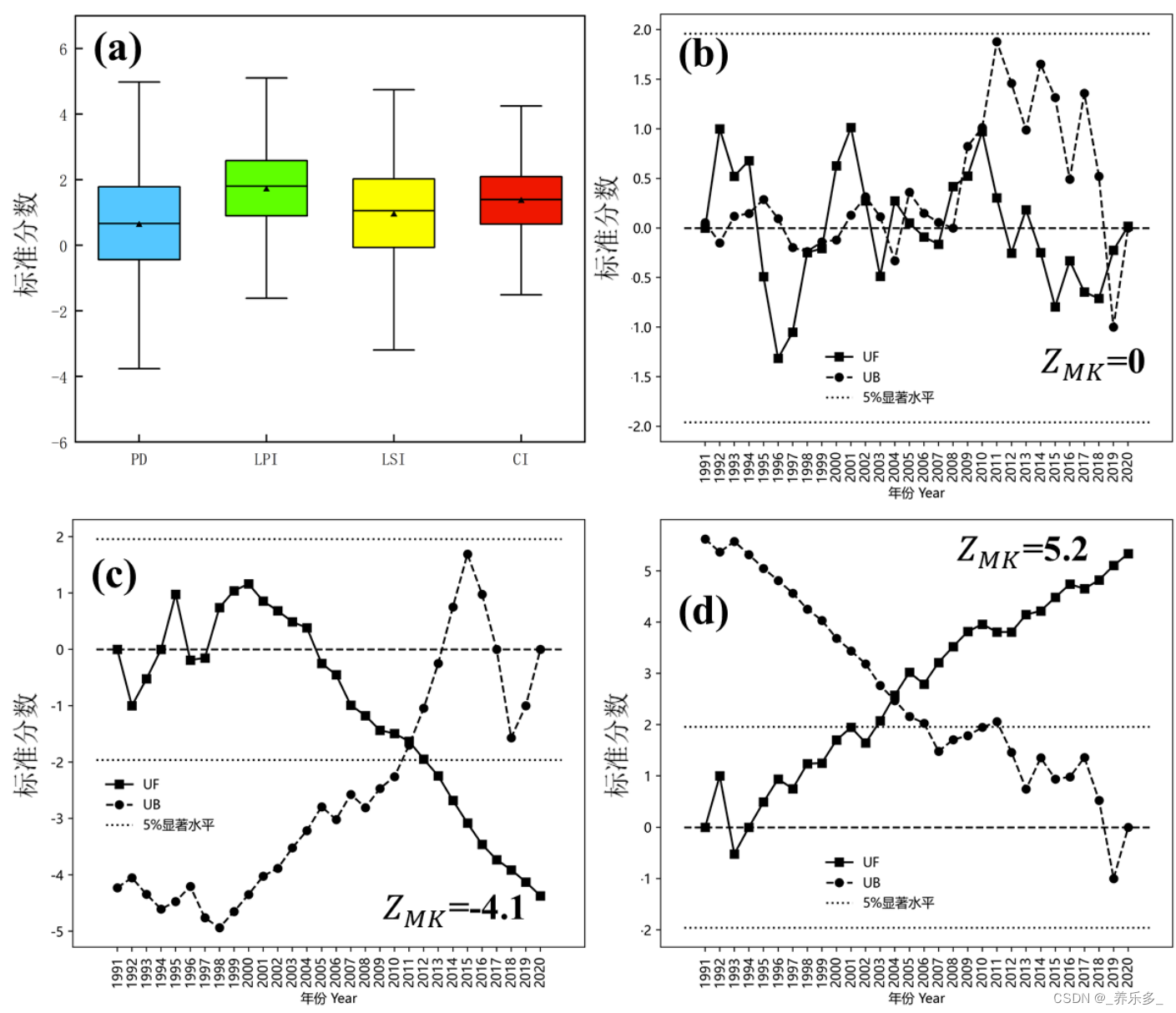
日志文件
kafka在server.properties配置文件中通过log.dir属性指定了Kafka的日志存储路径
核心文件

1. log文件
实际存储消息的日志文件, 大小固定1G(参数log.segment.bytes可配置), 写满后就会新增一个新的文件, 文件名是第一条消息的偏移量
2. index文件
以偏移量为索引来记录对应的.log日志文件中的消息偏移量
3. timeindex文件
以时间戳为索引, 用来进行一些跟时间相关的消息处理。比如文件清理。
文件查看
kafka提供了工具查看这些二进制文件
./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.loglog文件追加消息
Kafka都以追加的方式写入新的消息日志。position就是消息记录的起点,size就是消息序列化后的长度。Kafka中的消息日志,只允许追加,不支持删除和修改。所以,当前文件名最大的一个log文件是当前写入消息的日志文件,其他文件都是不可修改的历史日志。
每个Log文件都保持固定的大小。如果当前文件记录不下,会重新创建一个log文件,并以这个log文件写入的第一条消息的偏移量命名。这种设计是为了更方便进行文件映射,加快读消息的效率。
index和timeindex索引

- index和timeindex存的offset都是相对偏移量, 可以节省空间, 绝对偏移量 = 日志文件名+相对偏移量
- 两个索引不会每写入一条消息就建立索引, 而是Broker每写入40KB的数据,就建立一条索引。由参数log.index.interval.bytes配置
- index文件类似于数据结构的跳表, 可以加速查询log文件效率, timeindex可以做跟时间相关的处理, 例如文件清理. 这也是kafka消费者能够从某个offset或者某个时间点读消息的原因
文件清理机制
Kafka为了防止日志过多, 给服务器带来压力, 可以设置一些定期删除策略
判断过期
- log.retention.check.interval.ms:定时检测文件是否过期。默认 300000毫秒,也就是五分钟
- log.retention.hours , log.retention.minutes, log.retention.ms 。 表示文件保留多长时间。默认生效的是log.retention.hours,默认值168小时,也就是7天。如果设置了更高的时间精度,以时间精度最高的配置为准。
在检查文件是否过期时,遍历.timeindex文件最大的那一条记录。
过期处理
log.cleanup.policy: 日志清理策略
有两个选项,delete表示删除日志文件。 compact表示压缩日志文件。
当log.cleanup.policy选择delete时,还有一个参数可以设置,
log.retention.bytes:表示所有日志文件的大小。
当总日志文件大小超过这个阈值后,会删除最早的日志文件。默认是-1,表示不删除。
注意: 压缩文件可能造成文件丢失, 对相同key文件进行压缩, 只会保留最后一条
高效读写机制
1. 文件结构
同一个Topic下的多个Partition单独记录日志文件,并行读取,加快Topic下的数据读取速度。然后index的稀疏索引结构,可以加快log日志检索的速度。
2. 顺序写
kafka把每个log文件大小固定1g, 在写文件前, 提前占据一块磁盘空间. kafka的log文件只能追加方式结尾写入(顺序写), 就可以直接往提前申请的磁盘空间写入, 不用再去其他磁盘位置找空闲空间
kafka官网测试, 顺序写速度能达到600M/s,基本与内存写速度相当。而随机写的速度就只有100K/s
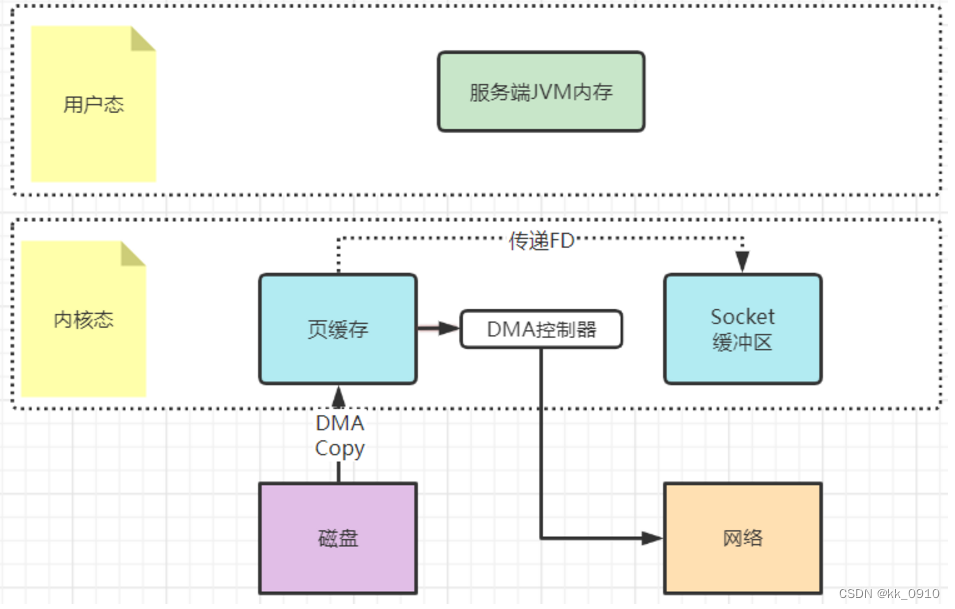
3. 零拷贝
零拷贝是Linux操作系统提供的一种IO优化机制,而Kafka大量运用零拷贝机制来加速文件读写。
1、mmap文件映射机制
这种方式是在用户态不再缓存整个IO的内容,改为只持有文件的一些映射信息。通过这些映射,"遥控"内核态的文件读写。这样就减少了内核态与用户态之间的拷贝数据大小,提升了IO效率。

2、sendfile文件传输机制
这种机制可以理解为用户态,也就是应用程序不再关注数据的内容,只是向内核态发一个sendfile指令,要他去复制文件就行了。这样数据就完全不用复制到用户态,从而实现了零拷贝。
刷盘机制
如果page缓存中的数据没有及时写入到磁盘, 当服务断电, 数据可能丢失. 最安全的方式是写一条数据. 刷一次盘, 也被叫做同步刷盘. 刷盘是linux系统对应了一次fsync的系统调用
刷盘参数配置:
- flush.ms : 多少毫秒进行一次强制刷盘
- log.flush.interval.messages:表示当同一个Partiton的消息条数积累到这个数量时,就会申请一次刷盘操作。默认是Long.MAX。
- log.flush.interval.ms:当一个消息在内存中保留的时间,达到这个数量时,就会申请一次刷盘操作。他的默认值是空。如果这个参数配置为空,则生效的是下一个参数。
- log.flush.scheduler.interval.ms:检查是否有日志文件需要进行刷盘的频率。默认也是Long.MAX。
这里可以看出, Kafka并不支持同步刷盘操作。但是在RocketMQ中却支持了这种同步刷盘机制。但是如果真的每来一个消息就调用一次刷盘操作,这是任何服务都无法承受的