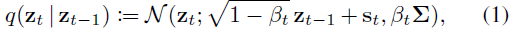摸索若依框架是如何实现权限过滤的
这篇文章,我也是作为一个优秀开源框架的学习者,在这里摸索这套框架是如何实现权限过滤的,这个封装对于入行Java半年之余的我来说,理解起来有些困难,所以,文章只是作为一个学习记录,如果有前辈指正,请不要多加指责,敬请提出宝贵意见,学生一定虚心学习请教,感谢!!!手下留情,不要大家难堪!

首先,简单的看一下若依明显的几个地方,首先就是service层留下了一个自定义注解
@Override@DataScope(deptAlias = "d", userAlias = "u")public List<SysUser> selectUserList(SysUser user){return userMapper.selectUserList(user);}@DataScope(deptAlias = "d", userAlias = "u") 是一个 Java 注解的用法,用于标注在方法上。这个注解属于自定义注解,它是根据 DataScope 类的定义创建的。
/*** 数据权限过滤注解* * @author ruoyi*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DataScope
{/*** 部门表的别名*/public String deptAlias() default "";/*** 用户表的别名*/public String userAlias() default "";/*** 权限字符(用于多个角色匹配符合要求的权限)默认根据权限注解@ss获取,多个权限用逗号分隔开来*/public String permission() default "";
}在这里,通过提供属性值为 deptAlias 和 userAlias 的方式对 DataScope 进行了配置。
具体来说:
@DataScope是一个自定义注解,它定义了一些属性,包括deptAlias和userAlias。deptAlias和userAlias是@DataScope注解的属性,它们有默认值,但在这里可以通过具体的值进行了配置。
这样的注解的目的通常是为了在标注了这个注解的方法中,通过 AOP 切面提供的机制来处理特定的逻辑。在代码中,DataScopeAspect 切面会根据这个注解的配置对数据进行范围过滤,确保用户只能访问其具有权限查看的数据。同时呢,我们留意一下 deptAlias 和 userAlias,这个两个字段分部对应的就是sys_dept 这个表和sys_user。我们慢慢往后看——
然后呢,我们进入mapper,看一下SQL是什么样子
<select id="selectUserList" parameterType="SysUser" resultMap="SysUserResult">select u.user_id, u.dept_id, u.nick_name, u.user_name, u.email, u.avatar, u.phonenumber, u.sex, u.status, u.del_flag, u.login_ip, u.login_date, u.create_by, u.create_time, u.remark, d.dept_name, d.leader from sys_user uleft join sys_dept d on u.dept_id = d.dept_idwhere u.del_flag = '0'<if test="userId != null and userId != 0">AND u.user_id = #{userId}</if><if test="userName != null and userName != ''">AND u.user_name like concat('%', #{userName}, '%')</if><if test="status != null and status != ''">AND u.status = #{status}</if><if test="phonenumber != null and phonenumber != ''">AND u.phonenumber like concat('%', #{phonenumber}, '%')</if><if test="params.beginTime != null and params.beginTime != ''"><!-- 开始时间检索 -->AND date_format(u.create_time,'%y%m%d') >= date_format(#{params.beginTime},'%y%m%d')</if><if test="params.endTime != null and params.endTime != ''"><!-- 结束时间检索 -->AND date_format(u.create_time,'%y%m%d') <= date_format(#{params.endTime},'%y%m%d')</if><if test="deptId != null and deptId != 0">AND (u.dept_id = #{deptId} OR u.dept_id IN ( SELECT t.dept_id FROM sys_dept t WHERE find_in_set(#{deptId}, ancestors) ))</if><!-- 数据范围过滤 -->${params.dataScope}</select>
这里,我们可以看到,${params.dataScope}
在MyBatis XML映射文件中,${params.dataScope} 是一个动态 SQL 片段,它会被实际的数据范围过滤逻辑替换。这个 SQL 片段是在运行时动态生成的,它会被注入到你的 SQL 查询中。
DataScopeAspect 切面类中的 dataScopeFilter 方法会设置 DATA_SCOPE 参数,这个参数会被添加到 BaseEntity 的参数集合中。在这个场景中,params 就是 BaseEntity,dataScope 参数将被放置在 params 的参数集合中。
在你的 SQL 查询中,${params.dataScope} 将被实际的数据范围过滤条件替换。这个过滤条件是根据用户的角色和权限动态生成的,确保只返回用户有权限访问的数据。
与 @DataScope(deptAlias = "d", userAlias = "u") 注解相关的内容在 DataScopeAspect 切面中,这个切面负责根据用户的数据权限进行过滤。所以,${params.dataScope} 的具体内容将由 DataScopeAspect 动态生成,确保只返回用户有权限访问的数据。
现在,我们逐渐提高了更多的东西,首先就是DataScopeAspect 这个切面类,然后还有一个参数集合 BaseEntity
我们先不深入,我们先看看 BaseEntity ,其实这个倒是无所谓,主要就是params会被填入参数,所以就大概看一眼
/*** Entity基类* * @author ruoyi*/
public class BaseEntity implements Serializable
{private static final long serialVersionUID = 1L;/** 搜索值 */@JsonIgnoreprivate String searchValue;/** 创建者 */private String createBy;/** 创建时间 */@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")private Date createTime;/** 更新者 */private String updateBy;/** 更新时间 */@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")private Date updateTime;/** 备注 */private String remark;/** 请求参数 */@JsonInclude(JsonInclude.Include.NON_EMPTY)private Map<String, Object> params;......此处省去get/set方法
}可以看到,大概如此罢了,然而这里有一个params会涉及到SQL安全问题,有可能造成SQL注入,所以在后面代码过程中,我们可以看到若依对于SQL注入的处理方法。
下来,就是这个切面类,这里的学问比较多,也是核心,我们需要静下心慢慢看
package com.ruoyi.framework.aspectj;import java.util.ArrayList;
import java.util.List;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
import com.ruoyi.common.annotation.DataScope;
import com.ruoyi.common.core.domain.BaseEntity;
import com.ruoyi.common.core.domain.entity.SysRole;
import com.ruoyi.common.core.domain.entity.SysUser;
import com.ruoyi.common.core.domain.model.LoginUser;
import com.ruoyi.common.core.text.Convert;
import com.ruoyi.common.utils.SecurityUtils;
import com.ruoyi.common.utils.StringUtils;
import com.ruoyi.framework.security.context.PermissionContextHolder;/*** 数据过滤处理** @author ruoyi*/
@Aspect
@Component
public class DataScopeAspect
{/*** 全部数据权限*/public static final String DATA_SCOPE_ALL = "1";/*** 自定数据权限*/public static final String DATA_SCOPE_CUSTOM = "2";/*** 部门数据权限*/public static final String DATA_SCOPE_DEPT = "3";/*** 部门及以下数据权限*/public static final String DATA_SCOPE_DEPT_AND_CHILD = "4";/*** 仅本人数据权限*/public static final String DATA_SCOPE_SELF = "5";/*** 数据权限过滤关键字*/public static final String DATA_SCOPE = "dataScope";@Before("@annotation(controllerDataScope)")public void doBefore(JoinPoint point, DataScope controllerDataScope) throws Throwable{clearDataScope(point);handleDataScope(point, controllerDataScope);}protected void handleDataScope(final JoinPoint joinPoint, DataScope controllerDataScope){// 获取当前的用户LoginUser loginUser = SecurityUtils.getLoginUser();if (StringUtils.isNotNull(loginUser)){SysUser currentUser = loginUser.getUser();// 如果是超级管理员,则不过滤数据if (StringUtils.isNotNull(currentUser) && !currentUser.isAdmin()){String permission = StringUtils.defaultIfEmpty(controllerDataScope.permission(), PermissionContextHolder.getContext());dataScopeFilter(joinPoint, currentUser, controllerDataScope.deptAlias(),controllerDataScope.userAlias(), permission);}}}/*** 数据范围过滤** @param joinPoint 切点* @param user 用户* @param deptAlias 部门别名* @param userAlias 用户别名* @param permission 权限字符*/public static void dataScopeFilter(JoinPoint joinPoint, SysUser user, String deptAlias, String userAlias, String permission){StringBuilder sqlString = new StringBuilder();List<String> conditions = new ArrayList<String>();for (SysRole role : user.getRoles()){String dataScope = role.getDataScope();if (!DATA_SCOPE_CUSTOM.equals(dataScope) && conditions.contains(dataScope)){continue;}if (StringUtils.isNotEmpty(permission) && StringUtils.isNotEmpty(role.getPermissions())&& !StringUtils.containsAny(role.getPermissions(), Convert.toStrArray(permission))){continue;}if (DATA_SCOPE_ALL.equals(dataScope)){sqlString = new StringBuilder();conditions.add(dataScope);break;}else if (DATA_SCOPE_CUSTOM.equals(dataScope)){sqlString.append(StringUtils.format(" OR {}.dept_id IN ( SELECT dept_id FROM sys_role_dept WHERE role_id = {} ) ", deptAlias,role.getRoleId()));}else if (DATA_SCOPE_DEPT.equals(dataScope)){sqlString.append(StringUtils.format(" OR {}.dept_id = {} ", deptAlias, user.getDeptId()));}else if (DATA_SCOPE_DEPT_AND_CHILD.equals(dataScope)){sqlString.append(StringUtils.format(" OR {}.dept_id IN ( SELECT dept_id FROM sys_dept WHERE dept_id = {} or find_in_set( {} , ancestors ) )",deptAlias, user.getDeptId(), user.getDeptId()));}else if (DATA_SCOPE_SELF.equals(dataScope)){if (StringUtils.isNotBlank(userAlias)){sqlString.append(StringUtils.format(" OR {}.user_id = {} ", userAlias, user.getUserId()));}else{// 数据权限为仅本人且没有userAlias别名不查询任何数据sqlString.append(StringUtils.format(" OR {}.dept_id = 0 ", deptAlias));}}conditions.add(dataScope);}// 多角色情况下,所有角色都不包含传递过来的权限字符,这个时候sqlString也会为空,所以要限制一下,不查询任何数据if (StringUtils.isEmpty(conditions)){sqlString.append(StringUtils.format(" OR {}.dept_id = 0 ", deptAlias));}if (StringUtils.isNotBlank(sqlString.toString())){Object params = joinPoint.getArgs()[0];if (StringUtils.isNotNull(params) && params instanceof BaseEntity){BaseEntity baseEntity = (BaseEntity) params;baseEntity.getParams().put(DATA_SCOPE, " AND (" + sqlString.substring(4) + ")");}}}/*** 拼接权限sql前先清空params.dataScope参数防止注入*/private void clearDataScope(final JoinPoint joinPoint){Object params = joinPoint.getArgs()[0];if (StringUtils.isNotNull(params) && params instanceof BaseEntity){BaseEntity baseEntity = (BaseEntity) params;baseEntity.getParams().put(DATA_SCOPE, "");}}
}为了便于理解参考,这里我就不去掉import的引入的类了,代码中可见,大概分为如下几个方法:
doBefore:这个方法是一个前置通知,即在目标方法执行前执行。它被用来清空数据范围过滤参数,然后调用handleDataScope方法处理数据范围过滤。
handleDataScope:该方法负责根据用户的角色和数据范围配置过滤数据。如果用户是超级管理员,则不进行数据过滤。否则,根据用户角色和权限配置调用dataScopeFilter方法进行数据范围过滤。
dataScopeFilter: 这是实际执行数据范围过滤的核心方法。根据用户的角色、权限和数据范围配置,动态构建 SQL 过滤条件,确保只返回用户有权限查看的数据。
clearDataScope:该方法用于在拼接权限 SQL 前先清空params.dataScope参数,以防止注入攻击。
这是四个方法的大概介绍,下面我们再整体梳理一下实现数据权限过滤的整体流程:
数据过滤的流程主要分为以下几个步骤:
-
切面拦截:
- 使用 Spring AOP(Aspect-Oriented Programming)框架,通过切面(
DataScopeAspect)拦截带有@DataScope注解的方法。
- 使用 Spring AOP(Aspect-Oriented Programming)框架,通过切面(
-
前置通知(
doBefore方法):- 在目标方法执行前执行前置通知,清空数据范围过滤参数(
DATA_SCOPE)并调用handleDataScope方法。
- 在目标方法执行前执行前置通知,清空数据范围过滤参数(
-
处理数据范围(
handleDataScope方法):- 获取当前登录用户(
LoginUser)以及用户的角色和权限信息。 - 如果用户是超级管理员(
isAdmin()),则不进行数据过滤。 - 否则,根据用户角色的数据范围配置,调用
dataScopeFilter方法生成数据范围的 SQL 过滤条件。
- 获取当前登录用户(
-
数据范围过滤(
dataScopeFilter方法):- 遍历用户的角色信息,根据每个角色的数据范围配置生成相应的 SQL 过滤条件。
- 数据范围配置包括:
DATA_SCOPE_ALL:全部数据权限DATA_SCOPE_CUSTOM:自定义数据权限DATA_SCOPE_DEPT:部门数据权限DATA_SCOPE_DEPT_AND_CHILD:部门及以下数据权限DATA_SCOPE_SELF:仅本人数据权限
- 根据用户的权限字符(
permission)进行过滤。 - 将生成的 SQL 过滤条件放入
params.dataScope参数中,该参数会在 MyBatis 查询中使用。就是我们在mapper映射中见到的${params.dataScope}
-
清空数据范围参数(
clearDataScope方法):- 为防止注入攻击,再次在拼接权限 SQL 前先清空
params.dataScope参数。之前我们提过一嘴,说是BaseEntity中的params可能造成SQL注入,这里就是进行了处理
- 为防止注入攻击,再次在拼接权限 SQL 前先清空
总体来说,该流程保证了在用户执行查询操作时,根据用户的角色、权限和数据范围配置,动态生成相应的 SQL 过滤条件,以确保用户只能查询到其具有权限查看的数据。这种机制对于多租户系统或需要数据隔离的系统非常有用,可以有效地提高系统的安全性和数据隐私保护能力。
这样,我们就大概清楚了整个数据权限过滤的流程,但是我的基础不扎实,我对于JoinPoint一直耿耿于怀,不知道为什么这个对象里面会有接口的入参,我想还是有必要解释一下:
JoinPoint 是 Spring AOP 中的一个核心概念,它代表正在被拦截的连接点(Join Point)。在 Spring AOP 中,连接点是应用程序中可以被拦截的点,通常是方法的执行。JoinPoint 提供了许多有关连接点的信息,如方法名、目标对象、方法参数等。
在你提供的代码中,JoinPoint 作为参数出现在 doBefore 方法中,这个方法使用 @Before 注解标记,表示在目标方法执行之前执行。具体来说,doBefore 方法会在带有 @DataScope 注解的方法执行之前被调用。
在 AOP 中,切面(Aspect)是一种模块化的方式,用于横切关注点(cross-cutting concerns),例如日志、事务管理、权限控制等。JoinPoint 提供了切面方法中访问连接点信息的途径,使得你可以在目标方法执行前或执行后执行一些逻辑。
总之,JoinPoint 是 Spring AOP 中的一个对象,它允许你获取连接点的信息,从而在切面中执行相应的逻辑。
至此,我们就大概完成了代码分析,至于更加深层次的问题,我还需要不断学习补充能量,我们后会有期!希望这次阅读让您有所收获,如果否然,我们下次一定,抱歉!