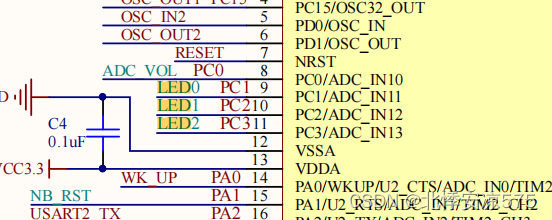
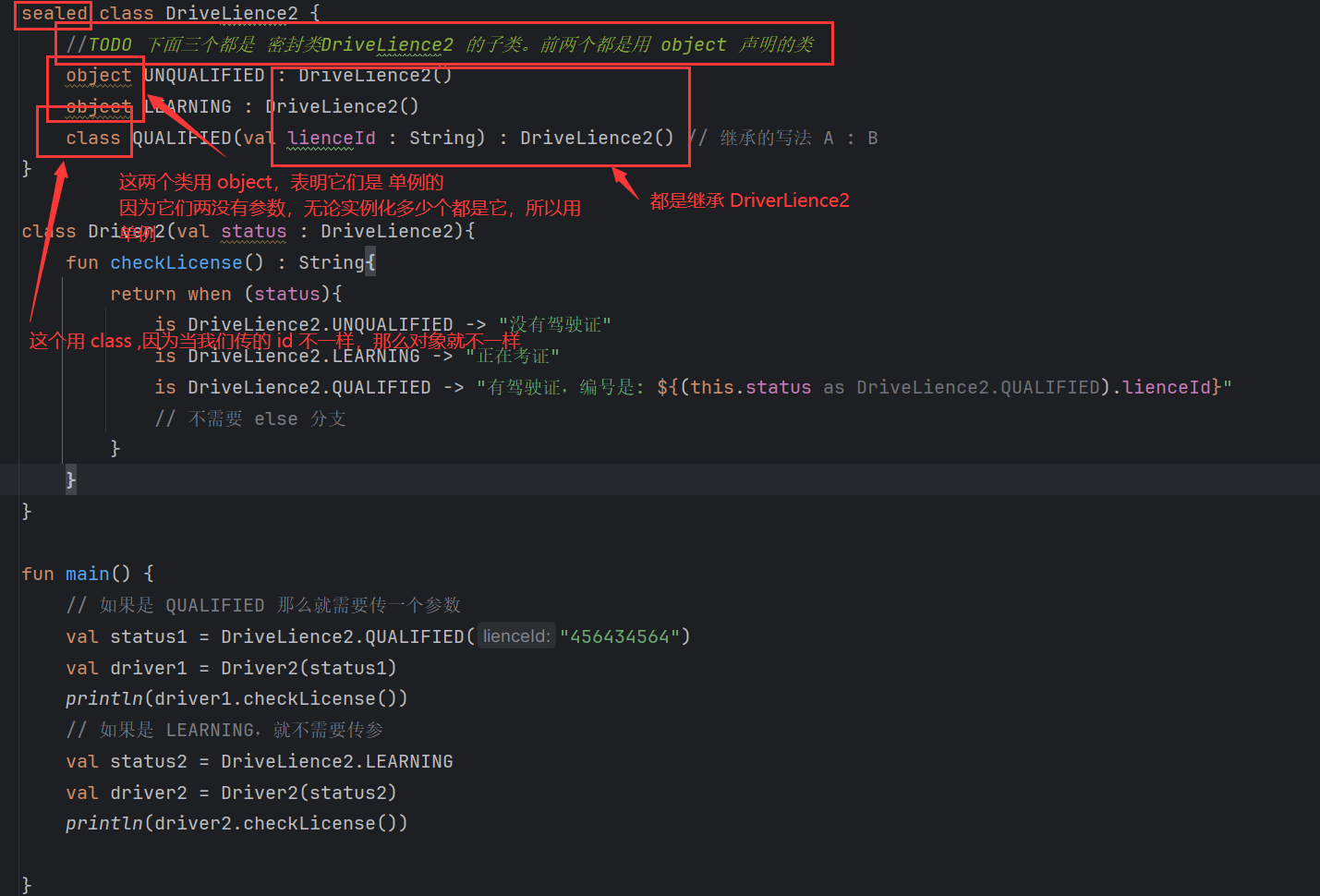
聚合模型的特点
将表中的列分为Key和Value。
Key是数据的维度列,比如时间,地区等等。key相同时会发生聚合。
Value是数据的指标列,比如点击量,花费等等。
每个指标列还会有自己的聚合函数,如:sum,min,max,bitmap_union等。数据会根据维度列进行分组,并对指标列进行聚合。
在3中机制下会发生聚合:
- 导入数据(insert, load等)
- BE内部Compaction时
- 查询数据
预聚合
导入数据时,发生的聚合,会丢失原始数据
表如下:
CREATE TABLE if not exists test_db.example_site_visit
(`user` id LARGEINT NOT NULL COMMENT "用户id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT"用户性别",`last_visit_date` DATETIME REPLACE default "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间",
)
AGGREGATE KEY(`user_id`, `date` ,`city` ,`age` ,`sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10;
REPLACE: key相同时,value替换成新插入的值
SUM:key相同时,value更新成求和结果
MAX:key相同时,value更新成保留最大值
MIN:key相同时,value更新成保留最小值
插入数据
前面6行数据时没有key相同的,所以插入后会有6条记录


当再次插入第七行数据时,第七行的key与第一行的key相同,因此发生聚合。
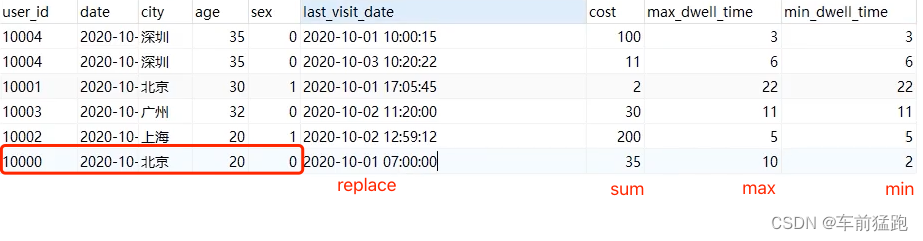
阻止预聚合
在表中增加插入记录时间字段insert_time,并且将该insert_time增加到key里,即可保证每条数据的key都不相同。

![使用教程之【SkyWant.[2304]】路由器操作系统,破解移动【Netkeeper】校园网【小白篇】](https://img-blog.csdnimg.cn/direct/01663f3794ff4cea9462ccd0000b3c0e.png)



![[内功修炼]函数栈帧的创建与销毁](https://img-blog.csdnimg.cn/direct/ae7043f7a9c04de4ad46dec9298a6e33.png)