文章目录
- 一、基础常见面试题
- 1、数组和链表区别
- 2、深拷贝和浅拷贝相关问题的区别
- 3、a++和++a区别
- 4、c++内存模型
- 5、四种强制转换和应用场景
- 二、指针相关
- 1、指针和引用的区别
- 2、函数指针和指针函数
- 3、传指针、引用和值
- 4、常量指针和指针常量
- 5、野指针
- 6、智能指针的用法
- 三、关键字作用
- 1、define、typdef、inline
- 2、overrride和overload
- 3、new和malloc
- 4、costexpr和const区别
- 5、const关键字和用法
- 6、static关键字和用法
- 7、extern:
- 四、类/结构体相关
- 1、构造函数和析构函数调用顺序
- 2、虚函数用法
- 3、虚析构作用
- 4、三大特性
- 5、抽象类
一、基础常见面试题
1、数组和链表区别
**(1)数组:**一组具有相同数据类型的变量的集合。
(2)链表:一种物理存储单元上非连续、非顺序的存储结构,逻辑顺序是通过链表中的指针链接次序实现的。
逻辑结构:
(1)数组在内存中连续;链表用动态内存分配的方式,内存中不连续。
(2)数组在使用前固定长度,不能改变数组长度;链表动态增删元素。
(3)数组元素减少时会造成内存浪费;链表使用malloc或new来申请内存,使用free或delete来释放内存。
内存结构: 数组从栈上分配内存,使用方便但自由度小;链表在堆上分配内存,自由度大但要注意造成内存泄漏。
访问效率: 数组在内存中顺序存储,下标访问效率高,插入删除效率低;链表需要从头遍历访问,访问效率低,插入删除效率高。
越界问题: 数组大小固定,存在访问越界的风险;链表只要能申请空间就无越界风险。
2、深拷贝和浅拷贝相关问题的区别
拷贝构造函数: 建立对象时可用同一类的另一个对象来初始化该对象的存储空间。这个拷贝过程只需要拷贝数据成员,而函数成员是共用的(只有一份拷贝)。没有自己定义拷贝构造函数时,会在拷贝对象时调用默认拷贝构造函数,进行的是浅拷贝。
用到拷贝构造的情况:
a.一个对象以值传递的方式传入函数体;
b.一个对象以值传递的方式从函数返回;
c. 一个对象需要通过另外一个对象进行初始化。
1.当函数的参数为对象时,实参传递给形参的实际上是实参的一个拷贝对象,系统自动通过拷贝构造函数实现;
2.当函数的返回值为一个对象时,该对象实际上是函数内对象的一个拷贝,用于返回函数调用处。
浅拷贝是让两个指针指向同一个位置,仅复制指针变量的地址,没有复制指向的对象。没有重新分配资源。假如B复制A,如果改变A,则B也被改变,就是浅拷贝
深拷贝是让另一个指针自己再开辟空间。一个类拥有资源,当这个类的对象发生复制过程的时候,会重新开辟内存空间。假如B复制A,A改变而B不变,就是深拷贝。
什么时候使用深拷贝? 在对含有指针成员的类对象进行拷贝时,须自定义拷贝构造函数进行深拷贝,避免内存泄漏。
浅拷贝带来问题:在于析构函数释放多次堆区内存,使用std::shared_ptr,可以解决这个问题。
调用一次构造函数,调用两次析构函数。在没有自己定义拷贝构造函数时,会在拷贝对象时调用默认拷贝构造函数,进行浅拷贝。对指针拷贝后会出现两个指针指向同一个内存空间。 指针被分配一次内存,但是程序结束时该内存却被释放了两次,会导致崩溃。
3、a++和++a区别
a++是先取值后自增;取a的地址,把它的值装入寄存器,然后增加内存中的a的值;++a是先自增后取值。取a的地址,增加它的内容,然后把值放在寄存器中。
如 a = 3,(a++)+(++a) = 8;
4、c++内存模型
栈区: 存放函数参数以及局部变量,在出作用域时,将自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但分配的内存容量有限。
堆区: new 分配的内存块,包括数组,类实例等,需 delete 手动释放。如果未释放,在整个程序结束后,操作系统会自动回收掉。
全局/静态区: 保存自动全局变量和static变量(包括static全局和局部变量)。静态区的内容在整个程序的生命周期内都存在,有编译器在编译的时候分配(数据段(存储全局数据和静态数据)和代码段(可执行的代码/只读常量))。
常量存储区: 常量存于此处,此存储区不可修改。
代码区: 存放函数体的二进制代码,由操作系统进行管理的。
5、四种强制转换和应用场景
(1) static_cast:
作用:
⽤于基本数据类型之间的转换,如把int转换成char。
把任何类型的表达式转换成void类型。
特点:
没有运⾏时类型检查来保证转换的安全性
进⾏上⾏转换(把派⽣类的指针或引⽤转换成基类表示)是安全的
进⾏下⾏转换(把基类的指针或引⽤转换为派⽣类表示),由于没有动态类型检查,所以是不安全的。
(2) dynamic_cast:
在进⾏下⾏转换时,dynamic_cast具有类型检查(信息在虚函数中)的功能,⽐static_cast更安全。
转换后必须是类的指针、引⽤或者void*,基类要有虚函数,可以交叉转换。
dynamic本身只能⽤于存在虚函数的⽗⼦关系的强制类型转换;对于指针,转换失败则返回nullptr,对于引⽤,转换失败会抛出异常。
(2) reinterpret_cast:
进行无关类型的转换,可以将整型转换为指针,也可以把指针转换为数组;可以在指针和引⽤⾥进⾏转换,平台移植性⽐价差。
int *p = new int(5);
int p = reinterpret_cast<int>(p);
(2) const_cast:
常量指针转换为⾮常量指针,并且仍然指向原来的对象。常量引⽤被转换为⾮常量引⽤,并且仍然指向原来的对象。去掉类型的const或volatile属性。
二、指针相关
1、指针和引用的区别
(1)定义性质:指针是变量,存储地址;引用是变量的别名,与原始变量是同一块内存;
(2)指针可以不初始化,引用必须初始化。指针可以改变指向地址和指向地址中存放数据的改变。引用不可变
(3)指针可以多级,引用只能一级。
(4)指针可以指向空值, 引用不可以指向空值。
(5)sizeof运算结果不同,自增运算意义不同。
2、函数指针和指针函数
(1) 函数指针:指向函数的入口的指针(函数名替换(*p))
声明返回int类型,形参为int, int:int (*p)(int, int);
(2) 指针函数:返回值是指针的函数。
声明形参为int, intm 返回值是int型指针的函数
int *p(int, int);
类似地:
(3)指针数组和数组指针
指针数组:一个数组,包含元素为指针: int* arr[10];
数组指针: 一个指针,指向一个数组:int(*arr_ptr)[10];
(4)函数模板和模板函数
函数模板:一个模板,用于生成函数。
template
void fun(T a) {}
模板函数:一个函数,由模板生成而来。
fun<Shape*>:fun(int)、fun(double)…
(5)类模板和模板类
类模板:一个模板,生产类的模板;
template
class vector {};
模板类:一个类,由模板生成的类。
vector<Shape*>:vector 、vector…
3、传指针、引用和值
值传递:
(1)形参和实参各占一个独立的存储空间。
(2)形参的存储空间是函数被调用时才分配的,调用开始,系统为形参开辟一个临时的存储区,然后将各实参传递给形参,这是形参就得到了实参的值。
形参是实参的拷贝,改变形参的值并不会影响外部实参的值。值传递是单向的(实参->形参)(形参的操作无法反作用到实参上),参数的值只能传入,不能传出。
当函数内部需要修改参数,并且不希望这个改变影响调用者时,采用值传递。
指针传递:
形参为指向实参地址的指针,当对形参的指向操作时,就相当于对实参本身进行的操作。
指针类型也可以作为函数参数的原型,视为把变量的地址传入函数,此时在函数中,对地址中的元素进行修改,则原先的数据就会确实地被修改。
引用传递:
形参相当于是实参的“别名”,对形参的操作其实就是对实参的操作,在引用传递过程中,被调函数的形式参数虽然也作为局部变量在栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。
被调函数对形参的任何操作都被处理成间接寻址,即通过栈中存放的地址访问主调函数中的实参变量。被调函数对形参做的任何操作都影响了主调函数中的实参变量。
引用和指针传递: 形参可以修饰实参
值传递不如地址传递高效,因为值传递先从实参的地址中取值,再赋值给形参代入函数计算。而指针则把形参的地址直接指向实参地址,使用时直接取出数据,效率提高。
*指针需要检查是否为空,引用不需要。
4、常量指针和指针常量
(1)常量指针:指针指向可以改,指针指向的值不可以改。
int a = 10;
int b = 10;
const int *p1 = &a;
p1 = &b // 正确
//*p1 = 100 // 错误
(2)指针常量:指针指向不可以变,值可以更改
int const p2 = &a
//p2 = &b //错误
*p2 = 100 //正确
5、野指针
野指针: 访问一个已销毁或者访问受限的内存区域的指针,野指针不能判断是否为NULL来避免指针,指向了一块随机的空间,不受程序控制。
空悬指针: 指针正常初始化,曾指向一个对象,该对象被销毁了,但是指针未制空,那么就成了悬空指针。
野指针产生的原因:
1.指针定义时未被初始化:指针在被定义的时候,如果程序不对其进行初始化的话,它会随机指向一个区域,因为任意指针变量(除了了static修饰的指针)它的默认值都是随机的
2.指针被释放时没有置空:我们在用malloc()开辟空间的时候,要检查返回值是否为空,如果为空,则开辟失败;如果不为空,则指针指向的是开辟的内存空间的首地址。指针指向的内存空间在用free()和delete释放后,如果程序员没有对其进行置空或者其他赋值操作的话,就会成为一个野指针。
3.指针操作超越变量作用域:不要返回指向栈内存的指针或者引用,因为栈内存在函数结束的时候会被释放。
野指针的危害:
指针指向的内容已经无效了,而指针没有被置空,解引用一个非空的无效指针是一个未被定义的行为,也就是说不一定导致错误,野指针被定位到是哪里出现问题,在哪里指针就失效了,不好查找错误的原因。
规避方法:
初始化指针的时候将其置为nullptr,之后对其操作。
释放指针的时候将其置为nullptr
6、智能指针的用法
优点:
(1)处理资源泄露问题;
(2)处理空悬指针的问题;
(3)处理比较由异常造成的资源泄露(new失败抛出异常,没delete)
三种智能指针:
auto_ptr已废弃,C++98中的Class auto_ptr在C++11中已不再建议使用。两个指针(同类型)不能指向同一个资源,复制或赋值都会改变资源的所有权。
unique_ptr:独占式/禁止拷贝,
独占式拥有(exclusive ownership)或严格拥有(strict ownership)概念,保证同一时间内只有一个智能指针可以指向该对象。可以避免资源泄露。
shared_ptr:引用计数/自动析构/死循环
实现共享式拥有(shared ownership),多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用(reference)被销毁”时候释放。多个智能指针共享一个控制块(constrol block),包含指向资源的 shared_ptr对象个数、指向资源的 weak_ptr 对象个数以及删除器(delete:用户自定义的用于释放资源的函数,可以默认没有)。
基于引用计数模型?
每次有 shared_ptr 对象指向资源,引用计数器就加1;
当有 shared_ptr 对象析构时,计数器减1;
当计数器值为0时,被指向的资源将会被释放掉。
且该类型的指针可复制和可赋值,即其可用于STL容器中。此外,shared_ptr 指针可与多态类型和不完全类型一起使用。
缺点: 无法检测出循环引用,如一颗树,其中既有指向孩子结点的指针又有指向父亲结点的指针,即孩子父亲相互引用。这会造成资源无法释放,从而导致内存泄露。
weak_ptr:弱引用解决shared_ptr死循环的问题。
指向有shared_ptr 指向的资源(即其需要shared_ptr的参与,其辅助 shared_ptr 之用),但是不会导致计数。一旦计数器为0,不管此时指向资源的 weak_ptr 指针有多少,资源都会被释放。
所有的这些 weak_ptr 指针会被标记为无效状态(即 weak_ptr作为观察shared_ptr 的角色存在着,shared_ptr 不会感受到 weak_ptr 的存在)。通过函数 expired() 来检查是是否 weak_ptr 处于无效状态。
weak_ptr 在访问所引用的对象前必须先转换为 shared_ptr。
作用: weak_ptr 是用来表达临时所有权的概念:当某个对象只有存在时才需要被访问,而且随时可以被他人删除时,可以使用 weak_ptr 来跟踪该对象。需要获得临时所有权时,则将其转换为 shared_ptr ,此时若原来的 shared_ptr 被销毁,则该对象的生命周期将延长至这个临时生成的 shared_ptr 同样被销毁为止。
三、关键字作用
1、define、typdef、inline
(1)define:
简单的字符串替换,没有类型检查
在预处理阶段起作⽤
防⽌头⽂件重复引⽤
不分配内存,给出的是⽴即数,有多少次使⽤就进⾏多少次替换。
(2)typedef
用于定义类型别名,有对应的数据类型,是要进⾏判断的
在编译、运⾏的时候起作⽤
在静态存储区中分配空间,在程序运⾏过程中内存中只有⼀个拷⻉
两者其他区别:
define没有作用域的限制,之前预定义过的宏,在以后的程序中都可以使用,而typedef有自己的作用域。
#define INTPTR1 int*
typedef int* INTPTR2;
INTPTR1 p1, p2; // 声明一个指针变量p1和一个整型变量p2
INTPTR2 p3, p4; //声明两个指针变量p3、p4
(3)inline:避免频繁调用的小函数大量消耗栈空间(栈内存)
将内联函数编译完成⽣成了函数体直接插⼊被调⽤地⽅,减少了压栈跳转和返回的操作。没有普通函数调⽤时的额外开销;
内联函数是⼀种特殊的函数,会进⾏类型检查;
对编译器的⼀种建议,编译器有可能拒绝这种请求;
inline编译限制:
- 不能存在任何形式的循环语句
- 不能存在过多的条件判断语句
- 函数体不能过于庞⼤
- 内联函数声明必须在调⽤语句之前,内联函数的定义放在头文件。
2、overrride和overload
(1)overrride: 用于子类继承父类,重写父类方法。
参数列表、返回值和抛出异常与被重写方法一致。
被重写方法不能为私有private
静态方法不能重写为非静态方法
重写的访问修饰符大于被重写方法的访问修饰符。
(2)overload: 一个方法的参数形式不同
不同的参数类型如不同的参数个数、参数顺序
3、new和malloc
(1)返回状态:new失败抛出异常。malloc失败返回NULL。
(2)内存大小: new无需指出内存块大小,malloc需要指出内存尺寸大小。C++提供了new[]与delete[]来专门处理数组类型,使用new[]分配的内存必须使用delete[]进行释放;
A *ptr1 = new A
A *ptr2 = (A*)malloc(sizeof (A))
//数组
A * ptr = new A[10];//分配10个A对象
delete [] ptr;
(3)重载: operator new/operator delete可以被重载,而malloc/free并不允许重载。
(4)构造函数和析构函数: new/delete会调用对象的构造函数和析构函数,malloc不会。(5)malloc与free是标准库函数,new/delete是c++运算符。
(6)内存位置: new是从自由存储区上为对象动态分配内存空间,而malloc函数是从堆上动态分配内存。
(7)返回类型安全: new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void* ,需要通过强制类型转换将void*指针转换成我们需要的类型。
4、costexpr和const区别
const 表示只读,constexpr 表示常量/常量表达式。
constexpr 只能定义编译期常量,在编译程序时可以将其结果计算出来,⽽ const 可以定义编译期和运⾏期常量。
如果标记为constexpr,则同样它是const的。但相反并不成立
5、const关键字和用法
6、static关键字和用法
(1)修饰局部变量:使得被修饰的变量成为静态变量,存储在静态区。作用范围为该函数体,不同于auto变量,该变量的内存只被分配一次,
因此其值在下次调用时仍维持上次的值。变量的值不会因为函数终止而丢失
(2)修饰全局变量:改变了作用域。被static修饰的全局变量只能被包含该定义的文件内所有函数访问。只对定义在同一文件中的函数可见。
(3)修饰函数:使得函数只能在包含该函数定义的文件中被调用。对于静态函数,声明和定义需要放在同一个文件夹中。
(4)修饰类的数据成员:使其成为类的全局变量,会被类的所有对象共享,包括派生类的对象,所有的对象都只维持同一个实例。
因此,static成员必须在类外进行初始化(初始化格式:int base::var=10;),而不能在构造函数内进行初始化,不过也可以用const修饰static数据成员在类内初始化。
(5)修饰成员函数:使这个类只存在这一份函数,所有对象共享该函数,不含this指针,因而只能访问类的static成员变量。静态成员是可以独立访问的,无须创建任何对象实例就可以访问。
例如可以封装某些算法,比如数学函数,如ln,sin,tan等等,这些函数本就没必要属于任何一个对象,所以从类上调用感觉更好,比如定义一个数学函数类Math,调用Math::sin(3.14); 还可以实现某些特殊的设计模式:如Singleton;
7、extern:
extern: 声明外部变量,在函数或者文件外部定义的全局变量。
修饰全局变量: 表明该变量定义于其他翻译单元。
修饰全局常量: 表明该全局常量拥有外部链接(可以被其他翻译单元发现),否则全局常量默认是只有内部链接,即不可被其他翻译单元发现。
//file1
extern const int a = 10; //定义拥有外部链接的全局常量J
//file2
extern const int a; //声明全局常量J来自于其他翻译单元
修饰局部变量: 表明该局部变量在其他翻译单元中被定义,需要在链接的时候去解析。
对于局部变量来说,extern可用于声明该局部变量来自其他翻译单元,但是不能使用extern定义一个拥有外部链接的局部单元
void Fun()
{extern int a; //表明a来自于其他翻译单元extern int b = 10; //错误,因为局部变量b的生命周期在退出函数的时结束,不允许其建立 外部链接
}
修饰一个字符串:** 形如extern “C” 之类的用法大家肯定见过了,表明后接的代码块(或者后接的声明)使用C语言调用惯例。
修饰一个模板: 表明该模板已经在其他翻译单元实例化,不需要在这里实例化。
四、类/结构体相关
1、构造函数和析构函数调用顺序
(1)构造函数顺序:基类构造函数、对象成员构造函数、派生类本身的构造函数 。
(2)派生类本身的析构函数、对象成员析构函数、基类析构函数(与构造顺序相反)
2、虚函数用法
**定义:**在基类中声明为 virtual 并在一个或多个派生类中被重新定义的成员函数,通过基类访问派生类定义的函数,实现多态性,必须是基类的非静态成员函数。
使用方法:
在基类用virtual声明成员函数为虚函数。在派生类中重新定义此函数,为它赋予新的功能。在类外定义虚函数时,不必在定义virtual。在派生类中重新定义此函数,要求函数名、函数类型、函数参数个数和类型全部与基类的虚函数相同,并根据派生类的需要重新定义函数体。
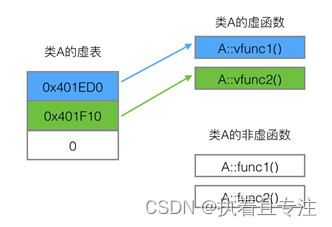
虚函数表:
每个包含了虚函数的类都包含一个虚表,虚表是一个指针数组,其元素是虚函数的指针,每个元素对应一个虚函数的函数指针。虚函数指针的赋值发生在编译器的编译阶段。
同一个类的所有对象都使用同一个虚表,对象内部包含一个虚表的指针,来指向自己所使用的虚表。为了让每个包含虚表的类的对象都拥有一个虚表指针,编译器在类中添加了一个指针,*__vptr,用来指向虚表。
3、虚析构作用
析构函数为什么是虚函数? 为了当用一个基类的指针删除一个派生类的对象时,派生类的析构函数会被调用。
虚函数的作用,就是用基类的指针操作对象时,能在运行时判断出对象的真正类型。 如(A为基类,B为派生类)
A * p= new B();
delete p;
如果A中的析构函数为虚函数,那么delete p的时候程序就会发现p指向的是一个B的对象,然后调用B的析构函数。
如果A中的析构函数不是虚函数,那么编译器就认为p指向的是一个A的对象,然后调用A的析构函数。B中定义的部分没有被析构,造成内存泄漏。
但并不是要把所有类的析构函数都写成虚函数。只有当一个类被用来作为基类的时候,才把析构函数写成虚函数。
4、三大特性
继承
封装
多态
5、抽象类
类中至少有一个函数被声明为纯虚函数,则这个类就是抽象类。纯虚函数是通过在声明中使用 “= 0” 来指定的,如下所示:
class Box
{
public:// 纯虚函数virtual double getVolume() = 0;private:double length; double width;
};
侵权联系删,持续更新中~
如果你对自动驾驶预测规划决策控制学习规划、科研方向、求职感兴趣,欢迎咸鱼搜索“技术咨询小店”。