㊙️小明博客主页:➡️ 敲键盘的小明 ㊙️
✅关注小明了解更多知识☝️
文章目录
- 前言
- 一、什么是数组?
- 二、一维数组的创建和初始化
- 2.1 一维数组的创建
- 2.2 一维数组的初始化
- 2.3 一维数组的使用
- 3.3 一维数组的存储
- 三、二维数组的创建和初始化
- 3.1 二维数组的创建
- 3.2 二维数组的初始化
- 3.3 二维数组的使用
- 3.4 二维数组的存储
- 四、数组的越界
- 五、数组作为函数的参数
- 🚫错误的冒泡排序
- 🔍数组名
- ✅正确的冒泡排序
- 完结
前言
提示:本篇文章为C语言函数的个人总结,内容如若有误,请及时联系我更正。
- 转载请注明原创,谢谢。

提示:以下是本篇文章正文内容:
一、什么是数组?
C语言的数组是一种数据结构,它用于存储相同类型的数据。
下面举几个生活中的例子来帮助理解C语言的数组:
例如 : : :
我们平时在买东西的时候,经常看到超市货架上的编号:超市的货架上通常会有多个相同的商品,例如一排排的牛奶。每个商品都有一个位置编号,例如第1排、第2排、第3排等。
数组中的元素就像这些商品,而数组的索引就像商品的位置编号。通过位置编号(即索引),我们可以快速找到并访问特定的商品(即数组元素)。
总之,数组是一种基本的数据结构,它可以帮助我们组织和管理数据。在实际编程中,数组经常被用于存储一系列相关的数据项。
在C语言中,数组的大小是预先定义好的,并且在程序运行时保持不变。通过索引访问数组元素时,需要注意不要越界访问 ,否则可能会导致程序崩溃或其他错误。
二、一维数组的创建和初始化
数组是一块连续的内存空间,用来存储相同类型元素的集合。数组还可以分为 一维数组 和 多维数组(一般常见的是二维数组)。
总之,数组是一组相同类型元素的集合。
2.1 一维数组的创建
让我们来看一下一维数组创建的格式:
数据类型 数组名 [ 常量表达式 ] ;
例子:
#include <stdio.h>
int main()
{int arr1[10];char arr2[3];double arr3[5];return 0;
}
- 数组的创建,在C99标准之前(99年发布的C语言标准), 数组只能是常量指定大小。但是在C99标准支持了变长数组的概念,数组的大小可以使用变量指定,但是数组不能初始化。但是在VS编译器中还是不支持变长数组的。
- 创建时可以指定类型、变量名、元素的个数。
- 一般来说,数组为type类型的数组我们就叫type数组,比如int类型数组我们可以称之为int数组或者整型数组。
2.2 一维数组的初始化
让我们来看一下一维数组初始化的格式:
数据类型 数组名 [ 数组个数 ] = { 数据内容 } ;
例子:
#include <stdio.h>
int main()
{//完全初始化int arr1[5] = { 1, 2, 3, 4, 5 };char str1[3] = { 'a','b','c'};//不完全初始化int arr2[10] = { 1, 2, 3, 4, 5 };char str2[10] = { 'a','b','c'};return 0;
}
当我们打开监视的时候可以查看到此时数组的赋值情况:
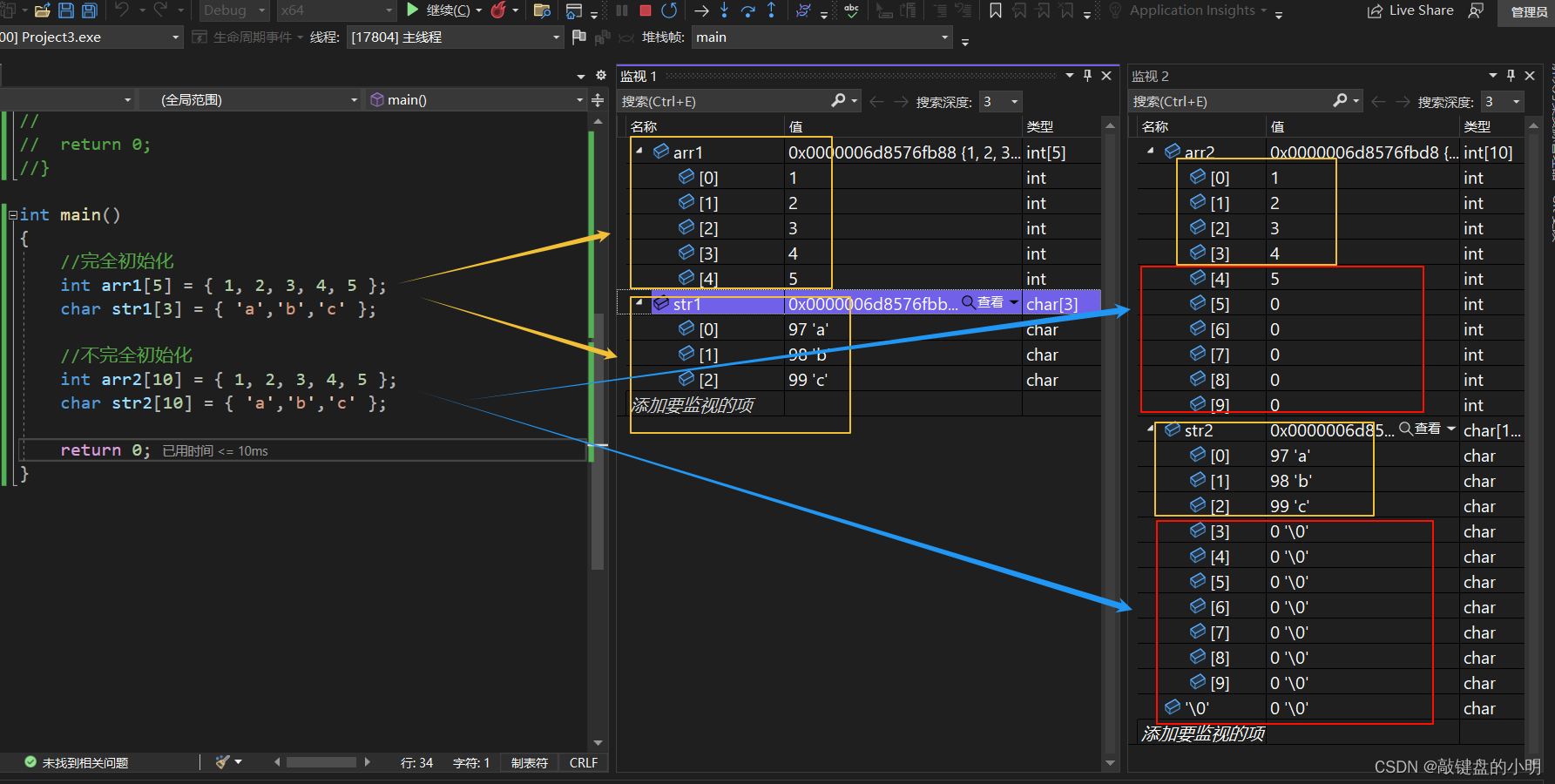
arr1 和 str1 是分别定义一个整形的数组和一个字符数组,数组的个数和内部元素的个数一致。
arr2 和 str2 也定义了一个整形的数组和一个字符数组,但是两个数组都是10个元素,而内部元素并没有 10 个,所以 剩余元素初始化为 0 。
2.3 一维数组的使用
细心的小伙伴在刚才应该已经发现了数组的使用方法:
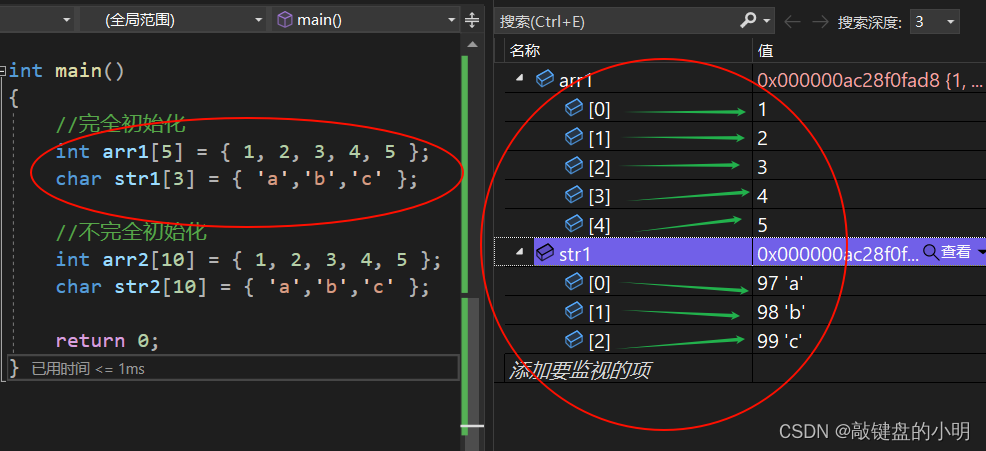
在之前初始C语言的文章中,对于数组的使用,小明介绍了一个操作符:[ ],下标引用操作符。它其实就是数组访问的操作符。
例子:
#include <stdio.h>
int main()
{int arr[] = { 1,2,3,4,5,6,7,8,9,10 };printf("%d\n", arr[1]);printf("%d\n", arr[6]);printf("%d\n", arr[8]);return 0;
}
执行结果:
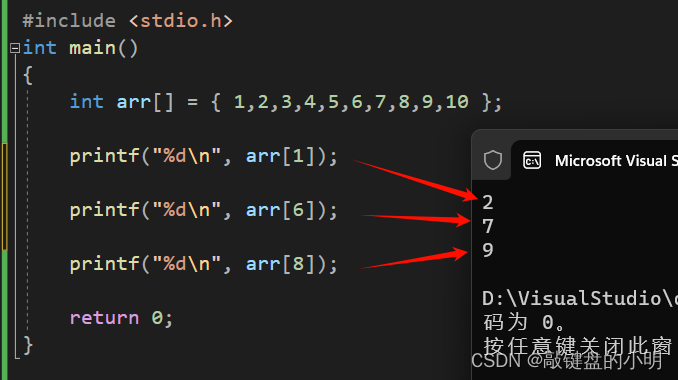
我们可以看到,当我们打印 a r r [ 1 ] arr[1] arr[1] 的时候,在屏幕上打印出了数字 2 2 2 ,同样的, a r r [ 6 ] arr[6] arr[6] 和 a r r [ 8 ] arr[8] arr[8] 在屏幕上分别打印出了数字 7 7 7 和 9 9 9 ,这就是因为数组中一个很重要的知识点: 下标 。
数组中的每个元素都有一个序号,这个序号是从0开始的,而不是从我们熟悉的1开始,称为下标 。使用数组元素时,用下标即可访问相对应的元素。
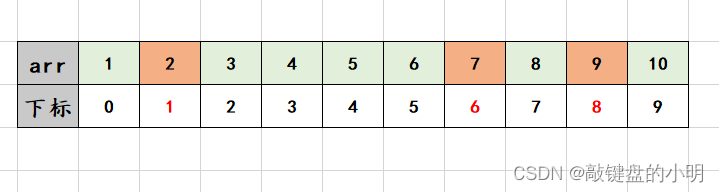
数组的每个元素都有一个下标,且 下标是从0开始的 。
3.3 一维数组的存储
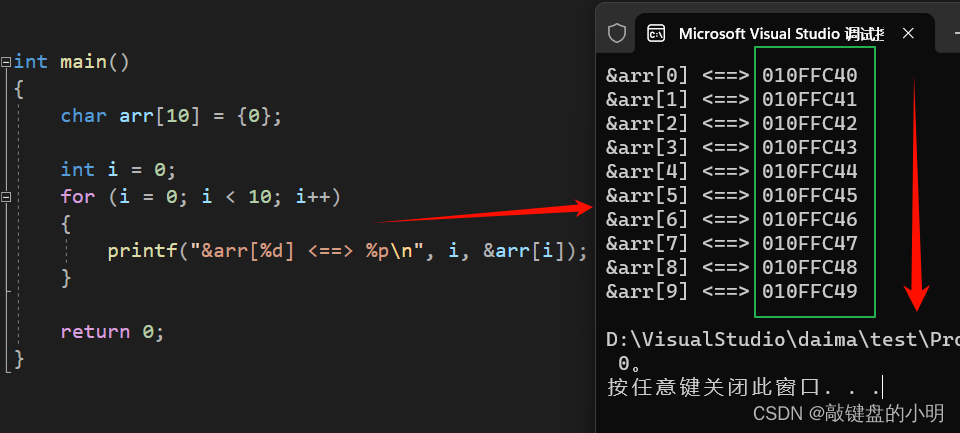
当我们观察输出的结果时,我们可以看到,随着数组下标的增长,元素的地址也在有规律的递增。
这也同样是数组的一个知识点:数组在内存中是连续存放的。
三、二维数组的创建和初始化
上面的数组可以看作是一行连续的数据,只有一个下标,称为一维数组。
在实际问题中还有很多数据是二维的或多维的,因此C语言允许构造多维数组 。多维数组元素有多个下标,以确定它在数组中的位置。小明在这里只给大家介绍二维数组,多维数组是可以由二维数组而推导出来的。
3.1 二维数组的创建
二维数组定义的一般形式是:
数据类型 数组名 [ 常量表达式 1 ] [ 常量表达式 2 ] ;
例子:
#include <stdio.h>
int main()
{int a[3][4]; // 3行4列char arry[10][10]; // 10行10列return 0;
}
- 我们可以将二维数组看做一个 Excel 表格,有行有列,表达式1 表示行数,表达式2 表示列数,要在二维数组中定位某个元素,必须同时指明行和列。
- 也可以将二维数组看成一个坐标系,有 x 轴和 y 轴,要想在一个平面中确定一个点,必须同时知道 x 轴和 y 轴。
3.2 二维数组的初始化
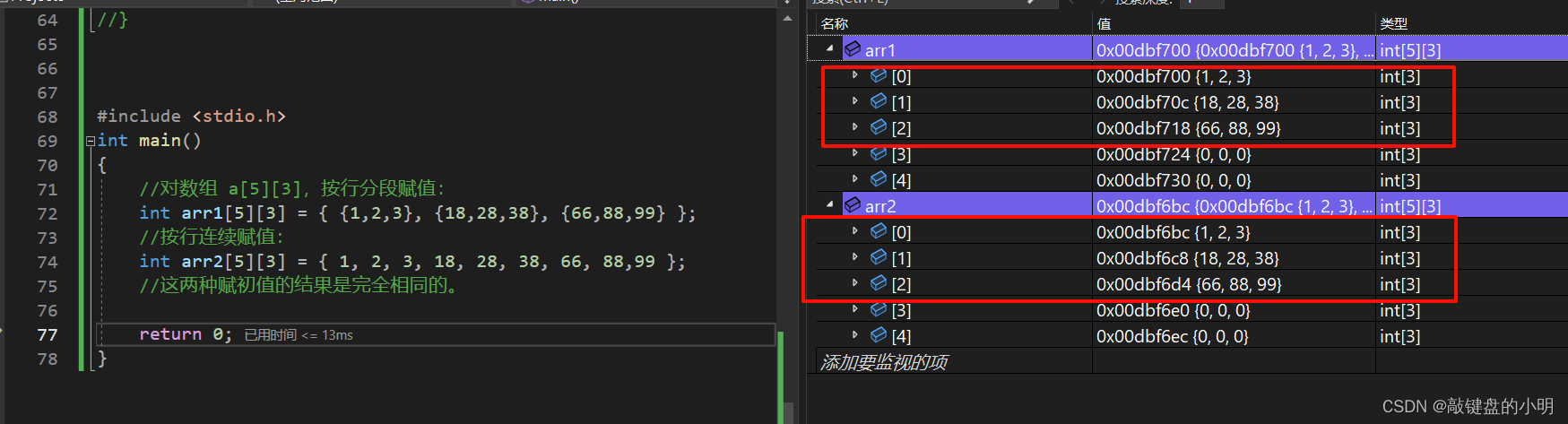
二维数组的初始化(赋值)可以按行分段赋值,也可按行连续赋值。
例:
#include <stdio.h>
int main()
{//对数组 a[5][3],按行分段赋值:int arr1[5][3]={ {1,2,3}, {18,28,38}, {66,88,99}};//按行连续赋值:int arr2[5][3]={1, 2, 3, 18, 28, 38, 66, 88,99};//这两种赋初值的结果是完全相同的。return 0;
}
注意:
二维数组如果有初始化,行可以省略,但是列不能省略。
3.3 二维数组的使用
二维数组在概念上是二维的,但在内存中是连续存放的;换句话说,二维数组的各个元素是相互挨着的,彼此之间没有缝隙。
例:
有一个学习小组有 4 个人,每个人有数学、英语、C语言, 3 门课程的考试成绩。

对于该情况的二维数组定义及初始化:
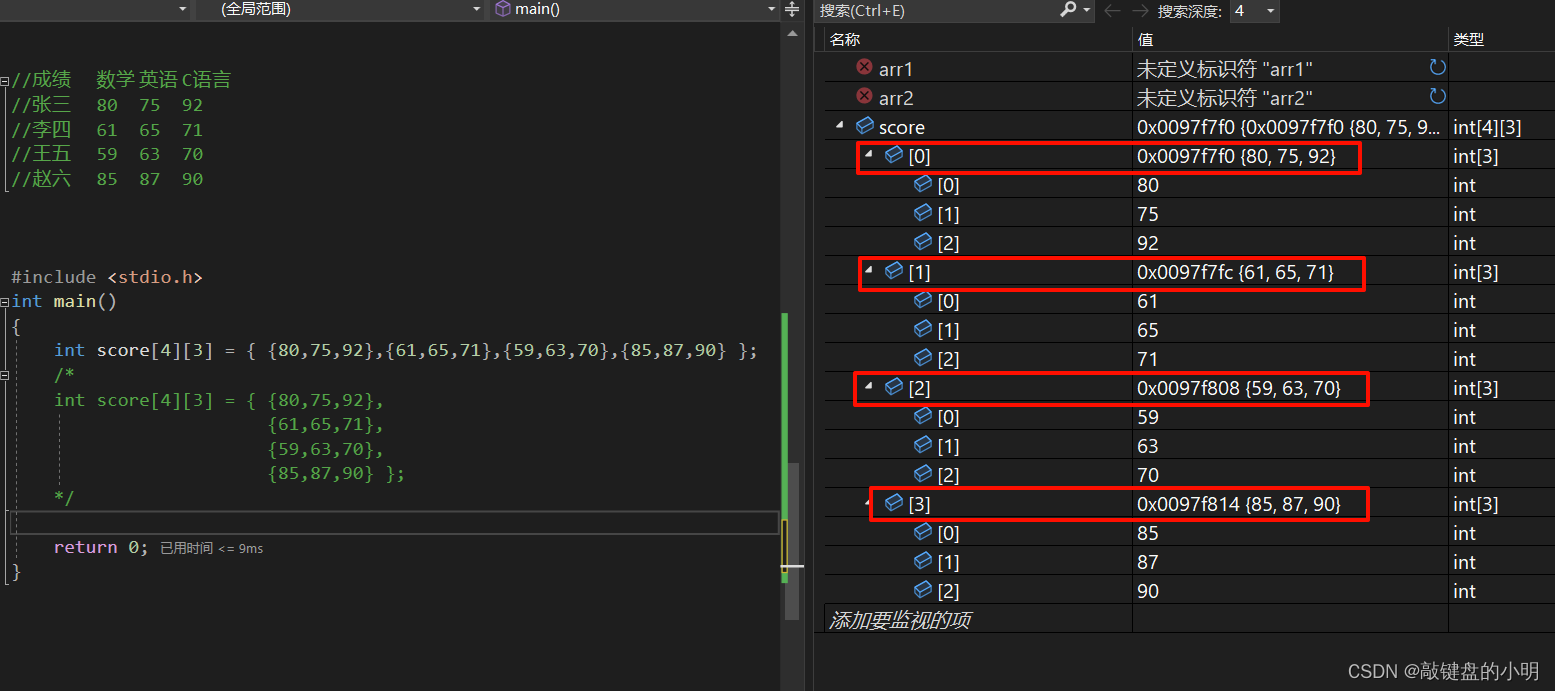
此时,我们又该想一个问题:我们的二维数组又该如何使用嘞?
其实,二维数组中的元素是通过使用下标(即数组的行索引和列索引)来访问的。
例如:
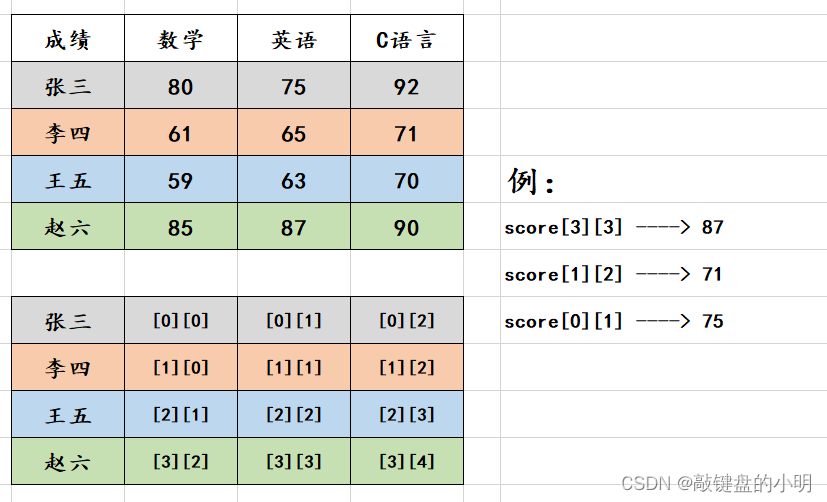
#include <stdio.h>
int main()
{int score[4][3] = { {80,75,92},{61,65,71},{59,63,70},{85,87,90} };printf("%d\n", score[3][2]);printf("%d\n", score[1][2]);printf("%d\n", score[0][1]);return 0;
}

当我们将上面的代码被编译和执行时,它会产生下列结果:
a[0][0] = 80
a[0][1] = 75
a[0][2] = 92
a[1][0] = 61
a[1][1] = 65
a[1][2] = 71
a[2][0] = 59
a[2][1] = 63
a[2][2] = 70
a[3][0] = 85
a[3][1] = 87
a[3][2] = 90
对于二维数组的初始化还要注意:
✅ 可以只对部分元素赋值,未赋值的元素自动取“ 零 ”值。
-
例如:
int a[3][3] = {{1}, {2}, {3}};是对每一行的第一列元素赋值,未赋值的元素的值为 0。赋值后各元素的值为:
1 0 0 2 0 0 3 0 0 -
再例如:
int a[3][3] = {{0,1}, {0,0,2}, {3}};是对每一行的第一列元素赋值,未赋值的元素的值为 0。
赋值后各元素的值为:0 1 0 0 0 2 3 0 0
3.4 二维数组的存储
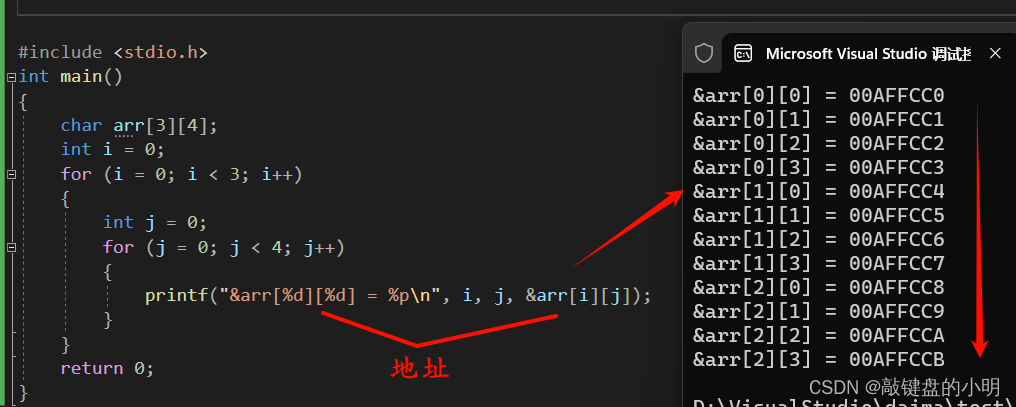
像一维数组一样,这里我们打印二维数组的每个元素,来看一下是如何存储的:
#include <stdio.h>
int main()
{char arr[3][4];int i = 0;for (i = 0; i < 3; i++){int j = 0;for (j = 0; j < 4; j++){printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);}}return 0;
}
运行结果:
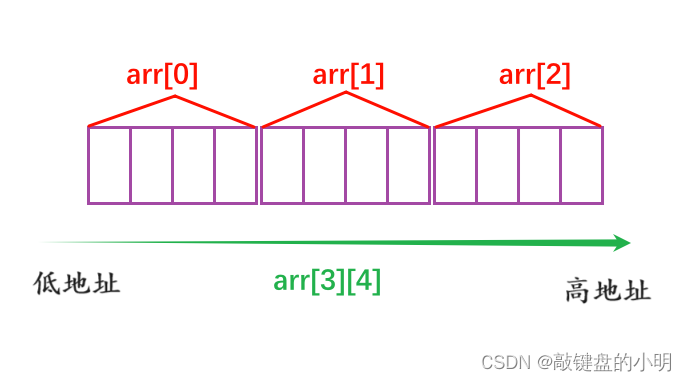
二维数组可以看作是由一维数组嵌套而成的;如果一个数组的每个元素又是一个数组,那么它就是二维数组。当然,前提是各个元素的类型必须相同。根据这样的分析,一个二维数组也可以分解为多个一维数组,C语言允许这种分解。
由此可见,其实二维数组在内存中也是连续存储的。
四、数组的越界
- 数组的下标是有范围限制的。
- 数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
- 所以数组的下标如果小于0,或者大于n-1,也就是我们所使用的索引超出了数组的范围,就会发生数组越界错误。
例如,假设我们有一个大小为5的整型数组int arr[5],它的有效索引范围是0到4。
#include <stdio.h>
int main()
{int arr[5] = {1, 2, 3, 4, 5};return 0;
}

如果我们尝试访问arr[5]或arr[6],就会导致数组越界错误。
#include <stdio.h>
int main()
{int arr[5] = {1, 2, 3, 4, 5};printf("%d\n", arr[3]);printf("%d\n", arr[5]);printf("%d\n", arr[6]);return 0;
}

但是呢,C语言本身不做下标越界检查的,这取决于编译器,有的编译器会报做错,有的则不会!但不报错不一定对,写的时候一定要注意❗️❗️❗️

为了解决这个问题,我们可以采取以下措施:
- 在使用数组之前,始终检查索引是否在有效范围内。
- 使用动态内存分配函数(如malloc)创建数组,并根据需要调整其大小。
- 在可能的情况下,使用其他数据结构(如链表、向量等),它们可以动态地调整大小以适应不同的需求。
总之,避免数组越界是非常重要的,因为它可能导致程序崩溃或产生不可预测的结果。
五、数组作为函数的参数
在实际开发中,有很多场景需要我们将数组元素按照从大到小(或者从小到大)的顺序排列,这样在查阅数据时会更加直观,例如:
- 一个保存了班级学号的数组,排序后更容易分区分数高的学生和分数低的学生。
- 一个保存了商品单价的数组,排序后更容易看出它们的性价比。
对于这种场景,往往我们在写代码的时候,会将数组作为参数传个函数,数组传参是相当重要的,数组传参涉及到一些函数知识点,后面会有详解函数的文章,接下来先我们来看看数组如何传参。
这里我们以从小到大冒泡排序为例子,讲一下数组传参思想:
冒泡排序思路讲解:
第一个元素开始,每次比较相邻的元素,符合条件则交换。

- 从数组头部开始,不断比较相邻的两个元素的大小,让较大的元素逐渐往后移动(交换两个元素的值),直到数组的末尾。经过第一轮的比较,就可以找到最大的元素,并将它移动到最后一个位置。
- 第一轮结束后,继续第二轮。仍然从数组头部开始比较,让较大的元素逐渐往后移动,直到数组的倒数第二个元素为止。经过第二轮的比较,就可以找到次大的元素,并将它放到倒数第二个位置。
- 以此类推,进行 n-1(n 为数组长度)轮“冒泡”后,就可以将所有的元素都排列好。
那么,按照上面的思路设计一下冒泡排序:
#include <stdio.h>
int main()
{int arr[] = { 11, 27 , 9, 32, 34, 16 ,7 };int i = 0;int sz = sizeof(arr) / sizeof(arr[0]);for (i = 0; i < sz - 1; i++){int j = 0;for (j = 0; j < sz - i - 1; j++){if (arr[j] > arr[j + 1]){int t = arr[j];arr[j] = arr[j + 1];arr[j + 1] = t;}}}for (i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");return 0;
}运行结果:
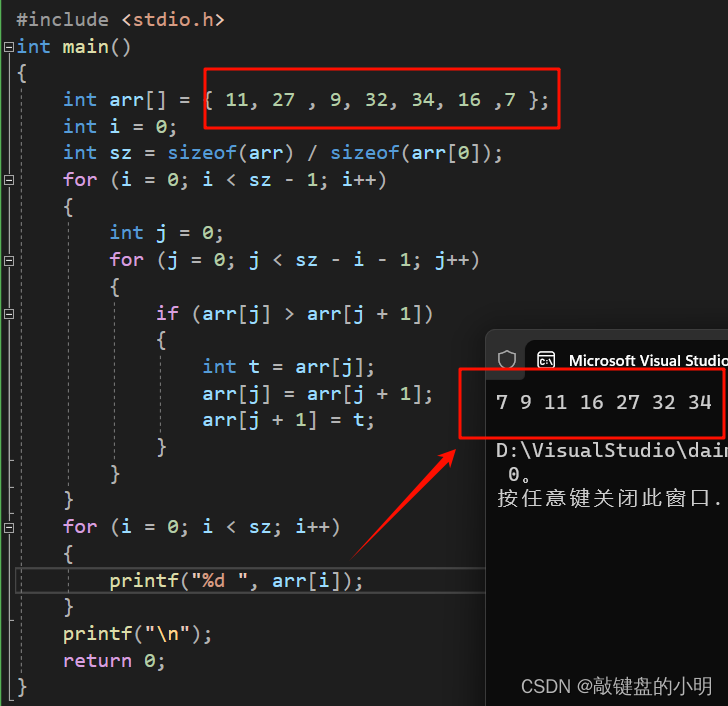
🚫错误的冒泡排序
既然,我们知晓了冒泡排序的写法,又会函数的写法,那要不要试一下自己写一个冒泡排序的函数?
说搞就搞,直接开整!🤪🤪🤪
void Bubble_sort(int arr[])
{int sz = sizeof(arr) / sizeof(arr[0]);int i = 0;for (i = 0; i < sz - 1; i++){int j = 0;for (j = 0; j < sz - 1 - i; j++){if (arr[j] > arr[j + 1]){int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}
}int main()
{int arr[] = { 11, 27 , 9, 32, 34, 16 ,7 };Bubble_sort(arr);int i = 0;for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){printf("%d ", arr[i]);}return 0;
}
运行结果:
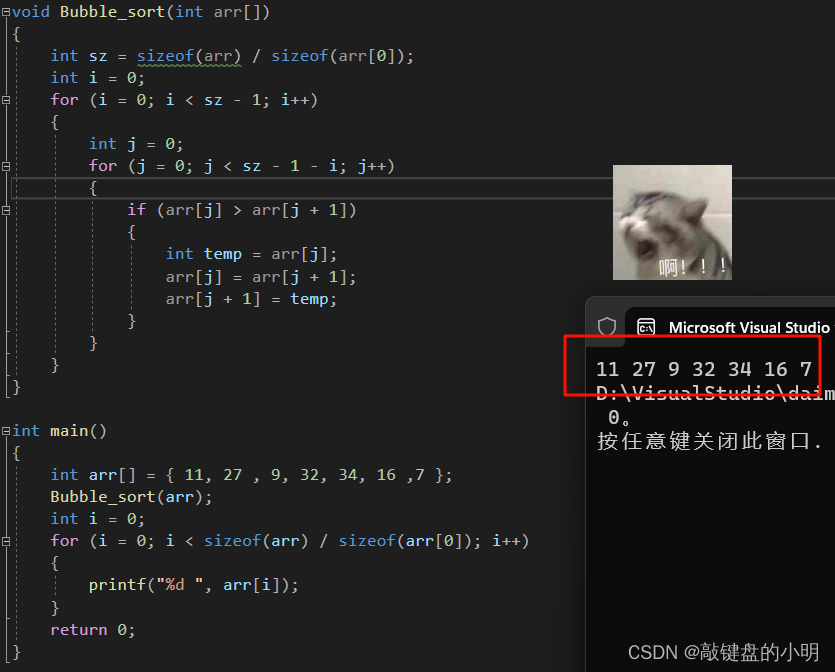
等等!!!为什么没有任何变化 ???
众爱卿莫慌,随朕开启调试观察一番
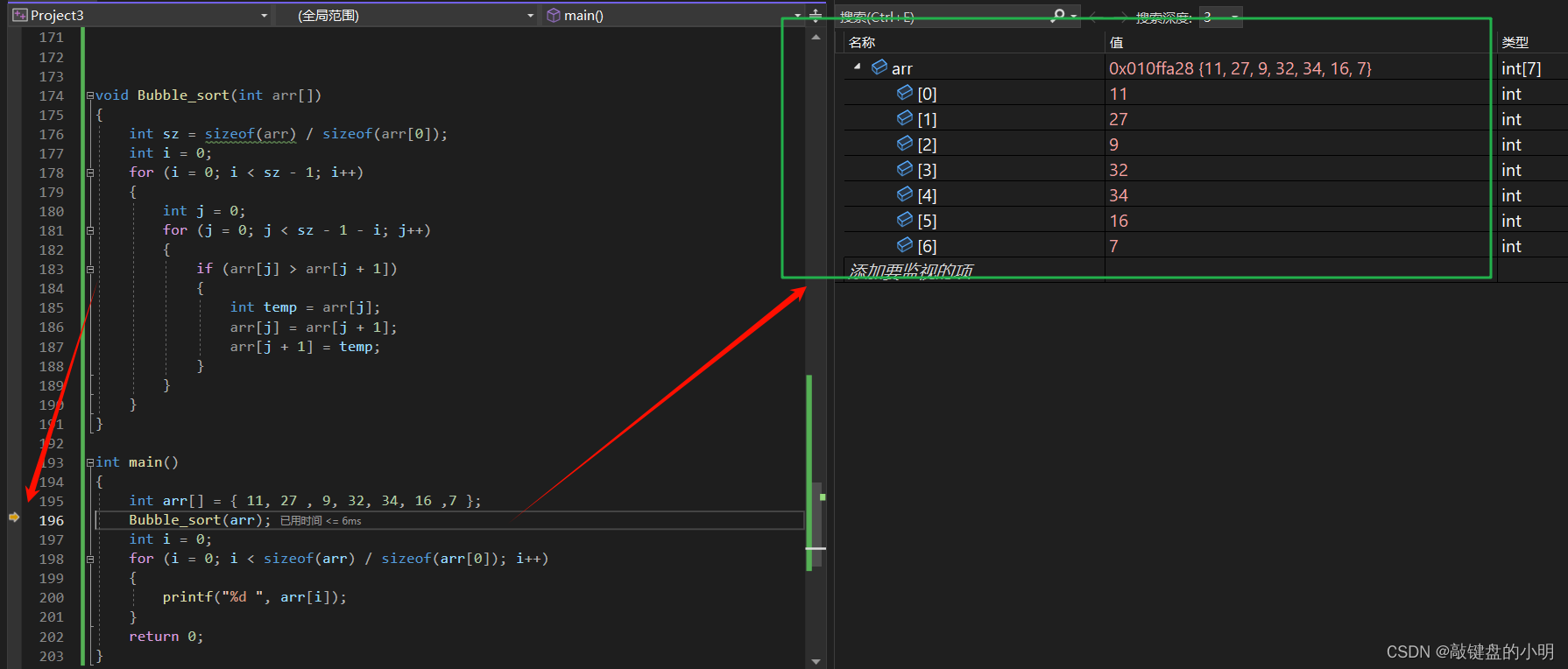
我们可以看到在代码执行到此处之时,我们的数组已然初始化,所以并不是这里的问题。让我们进入函数一探究竟:
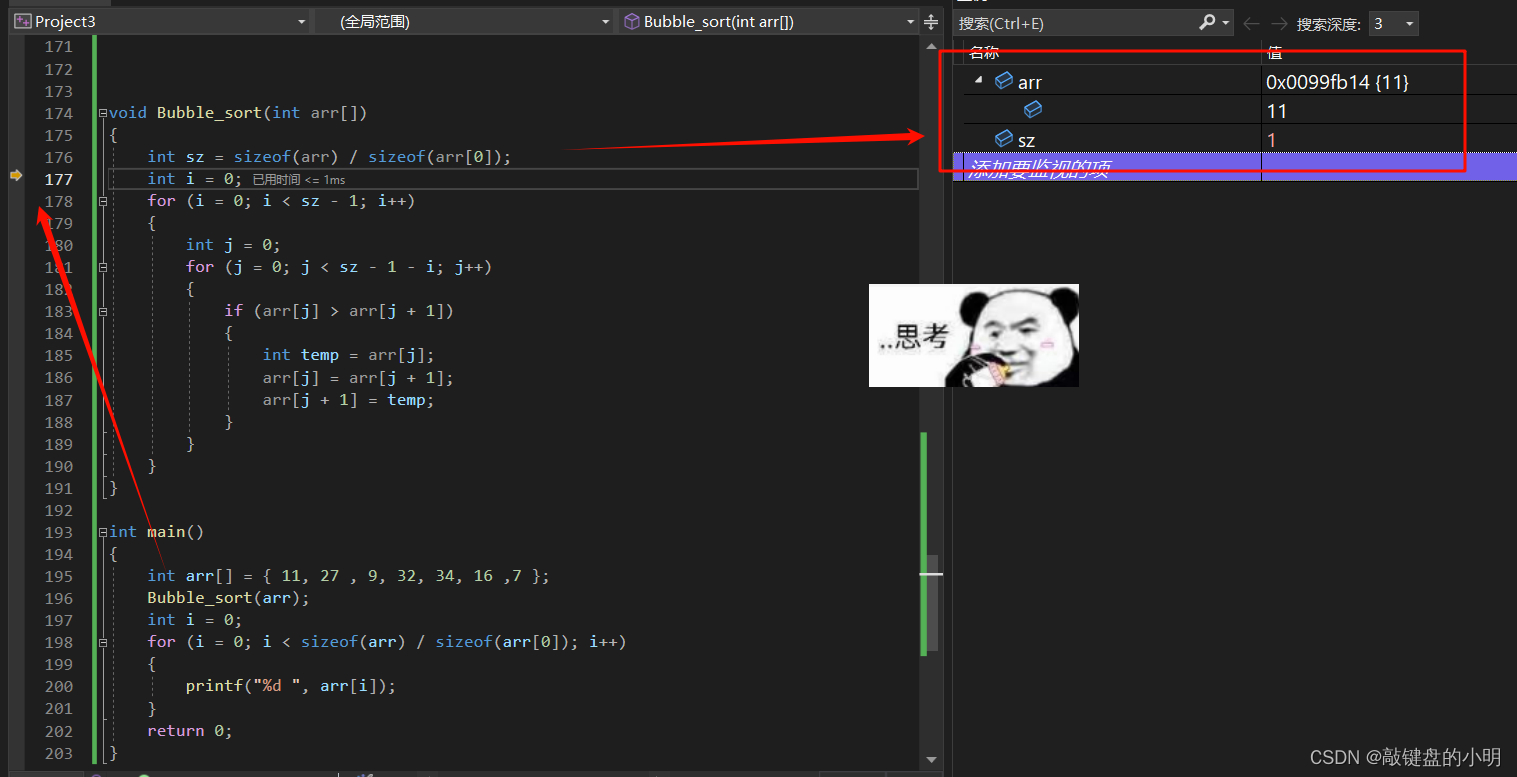
好好好,找到了!!!
我们发现在函数中,求数组元素个数sz方面出现了问题,此时我们恍然大悟,数组作为函数传参,不是把整个数组传递过去。那数组名究竟传参传递了什么东东?
这里,就又要引入一个新知识点,数组名。
🔍数组名
在刚才我们调试的时候可以发现arr中是11,而我们数组中的首元素也正好是11,那么,会不会arr在传参的时候传的是数组的首元素呢?

我们将首元素修改一下,再试一次:

现在,我们发现当我们改成888之后,arr传过去的也同样是888。
让我们再写一段代码试一试:
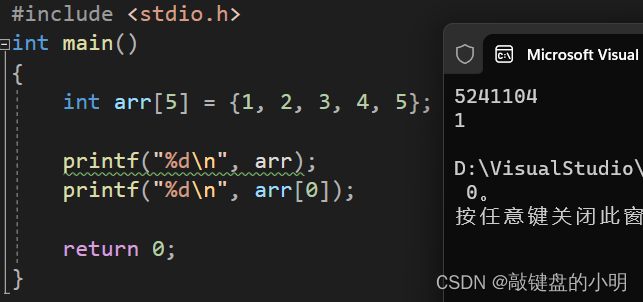
在这里我们就可以看到两次打印的数值并不一样。
让我们看一下警告:
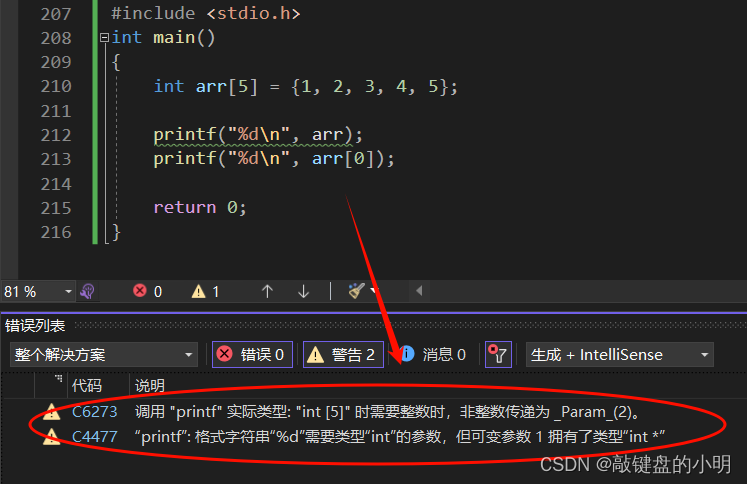
喔~
这里显示arr不是数组首元素,它是居然是一个指针!
此时我们回想一下曾经接触的知识,是不是有了些思路?我们知道,指针其实就是地址,那么,既然不是数组首元素,会不会有可能是数组首元素的 地址(指针)呢?
再搞一段代码浅试一手:
#include <stdio.h>
int main()
{int arr[5] = {1, 2, 3, 4, 5};printf("arr ----> %d\n", arr);printf("arr[0] -> %d\n", &arr[0]);return 0;
}
运行结果:
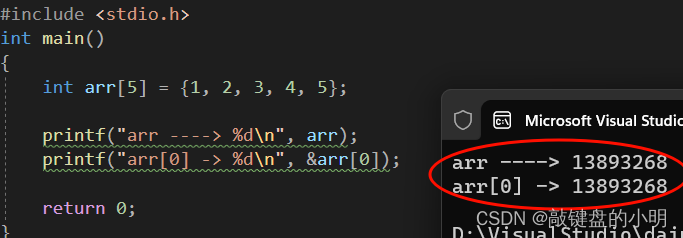
最终的最终,我们几乎可以确定,数组名代表数组首元素的地址,但是,是所有情况下,数组名都代表首元素地址嘛?
其实,有两个特例:
1️⃣ sizeof(数组名),这里的数组名就表示整个数组,计算的是整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数组,单位是字节。
2️⃣ &数组名,这里的数组名表示整个数组,取出的是数组的地址。&数组名,数组名代表的时整个数组!
除此之外,所有遇到的数组名都是数组的首地址。
✅正确的冒泡排序
当数组传参的时候,实际上只是把数组的首元素的地址传递过去了。
所以即使在函数参数部分写成数组的形式:
int arr[] 表示的依然是一个指针: int * arr
所以,我们直接在主函数内求出sz,然后在冒泡排序的函数内直接用即可:
void Bubble_sort(int *arr[],int sz)
{int i = 0;for (i = 0; i < sz - 1; i++){int j = 0;for (j = 0; j < sz - i - 1; j++){if (arr[j] > arr[j + 1]){int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}}
}int main()
{int arr[] = { 11, 27 , 9, 32, 34, 16 ,7 };int sz = sizeof(arr) / sizeof(arr[0]);Bubble_sort(arr,sz);int i = 0;for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){printf("%d ", arr[i]);}printf("\n");return 0;
}
运行结果:
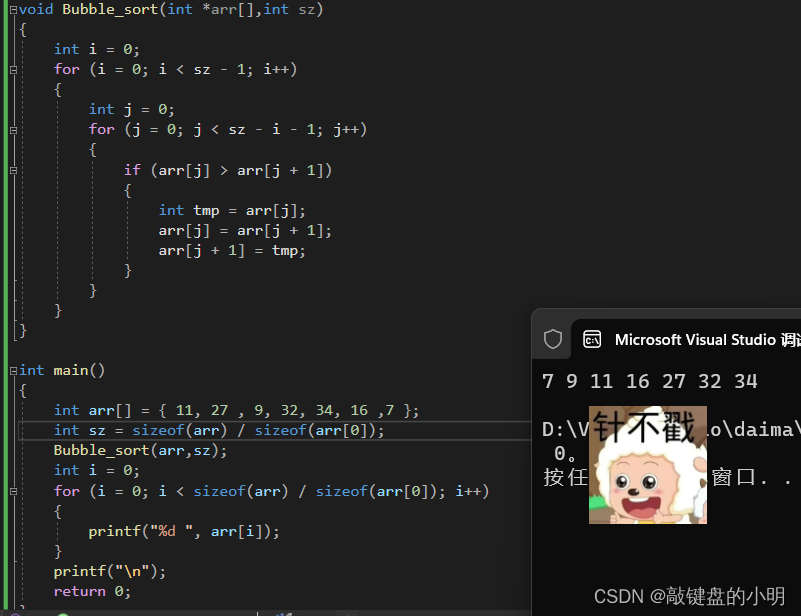
所以,我们把数组的大小作为参数传过去就可以实现冒泡排序了,大家也可以打开自己心爱的编译器,试一试冒泡排序的写法。
完结
好啦,阅读到这里就已经看完了本期博客的全部内容了

,以及在linux对项目进行部署。](https://img-blog.csdnimg.cn/direct/c0b9ecb52cb74bdcaaec6235729f04f2.png)







![[C/C++]排序算法 快速排序 (递归与非递归)](https://img-blog.csdnimg.cn/direct/5c52cdda0ab24fad9918cf051f1adb32.png)