实验条件:
| 主机名 | IP地址 | 组件 | 作用 |
| master01 | 20.0.0.17 | kube-apiserver、kube-controller-manager、kube-scheduler、etcd | k8s部署 |
| master02 | 20.0.0.27 | kube-apiserver、kube-controller-manager、kube-scheduler | |
| node01 | 20.0.0.37 | kubelet、kube-proxy、etcd | |
| node02 | 20.0.0.47 | kubelet、kube-proxy、etcd | |
| nginx01 | 20.0.0.11 | nginx、keepalived | 负载均衡 |
| nginx02 | 20.0.0.21 | nginx、keepalived |
实验步骤:
【所有主机】
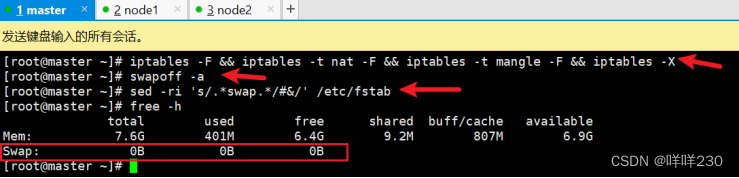
1、清空所有策略、关闭swap交换分区
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
2、安装时间同步工具
yum install ntpdate -y
ntpdate ntp.aliyun.com


3、主机映射
![]()

4、优化内核参数
vim /etc/sysctl.d/k8s.conf(创建k8s.conf文件)
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
sysctl --system
![]()


5、安装dokcer

【master节点】
6、部署 etcd 集群
(1)准备cfssl证书生成工具
chmod +x /usr/local/bin/cfssl*

(2)生成Etcd证书
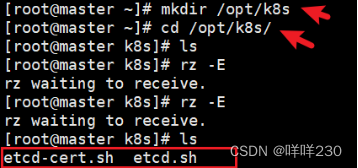
mkdir /opt/k8s
cd /opt/k8s/
#上传 etcd-cert.sh 和 etcd.sh 到 /opt/k8s/ 目录中
chmod +x etcd-cert.sh etcd.sh
![]()
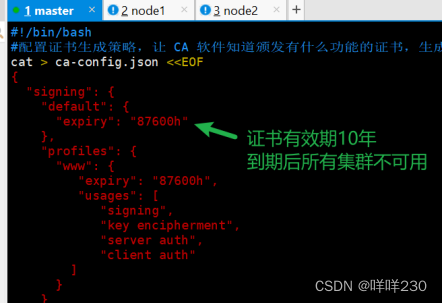


(3)创建用于生成CA证书、etcd 服务器证书以及私钥的目录
mkdir /opt/k8s/etcd-cert
mv etcd-cert.sh etcd-cert/
cd /opt/k8s/etcd-cert/
./etcd-cert.sh #生成CA证书、etcd 服务器证书以及私钥


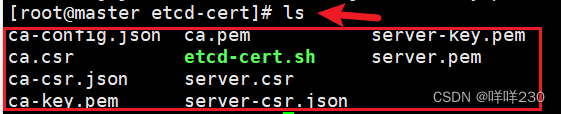
| ca-config.json | 证书颁发机构的配置文件,定义了证书生成的策略,默认的郭旗时间和模板 |
| ca-csr.json | 签名的请求文件,包括一些组织信息和加密方式 |
| ca.pem | 根证书文件,用于给其他组件签发证书 |
| server.csr | etcd的服务器签发证书的请求文件 |
| server-key.pem | etcd服务器的私钥文件 |
| ca.csr | 根证书签发请求文件 |
| ca-key.pem | 根证书的私钥文件 |
| etcd-cert.sh | 脚本 |
| server-csr.json | 用于生成etcd的服务器证书和私钥签名文件 |
| server.pem | etcd服务器的证书文件,用于加密和认证etcd节点之间的通信 |
(4)上传 etcd-v3.4.9-linux-amd64.tar.gz 到 /opt/k8s 目录中,启动etcd服务
https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz
cd /opt/k8s/
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz

(5)创建用于存放 etcd 配置文件,命令文件,证书的目录
mkdir -p /opt/etcd/{cfg,bin,ssl}
cd /opt/k8s/etcd-v3.4.9-linux-amd64/
mv etcd etcdctl /opt/etcd/bin/
cp /opt/k8s/etcd-cert/*.pem /opt/etcd/ssl/
cd /opt/k8s/
./etcd.sh etcd01 20.0.0.17 etcd02=https://20.0.0.37:2380,etcd03=https://20.0.0.47:2380
![]()


| etcd | 二进制文件 |
| etcdctl | 命令行执行工具 |
![]()
进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,
服务会卡在那里,直到集群中所有etcd节点都已启动,可忽略这个情况
可另外打开一个窗口查看etcd进程是否正常
ps -ef | grep etcd

(6)把etcd相关证书文件、命令文件和服务管理文件全部拷贝到另外两个etcd集群节点
scp -r /opt/etcd/ root@20.0.0.37:/opt/
scp -r /opt/etcd/ root@20.0.0.47:/opt/

验证node1、node2节点上是否已收到


scp /usr/lib/systemd/system/etcd.service root@20.0.0.37:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service root@20.0.0.47:/usr/lib/systemd/system/

【node1】

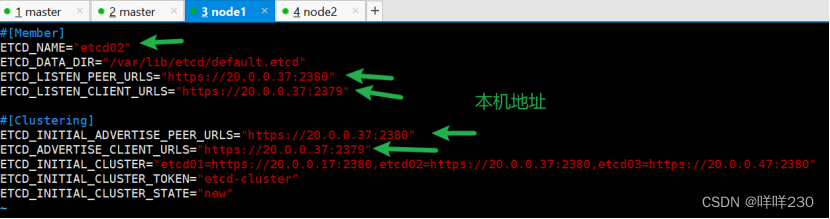
【node2】

ETCD安装完成
(7)依次启动ETCD,谁先启动谁是主

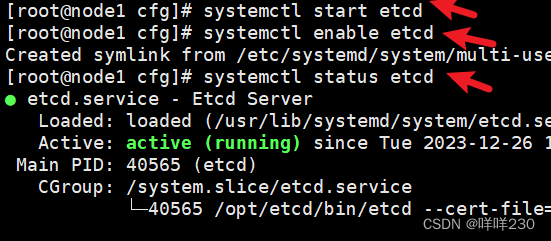
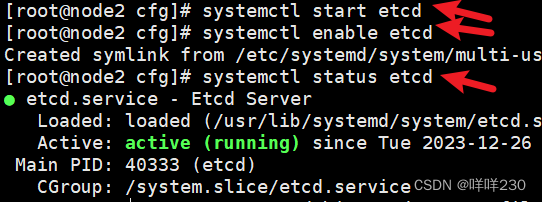
查看etcd集群成员列表
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://20.0.0.17:2379,https://20.0.0.37:2379,https://20.0.0.47:2379" --write-out=table member list

检查etcd群集状态
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://20.0.0.17:2379,https://20.0.0.37:2379,https://20.0.0.47:2379" endpoint health --write-out=table

7、部署 Master 组件
【master】
(1)上传 master.zip 和 k8s-cert.sh 到 /opt/k8s 目录中,解压 master.zip 压缩包
cd /opt/k8s/
unzip master.zip
chmod +x *.sh

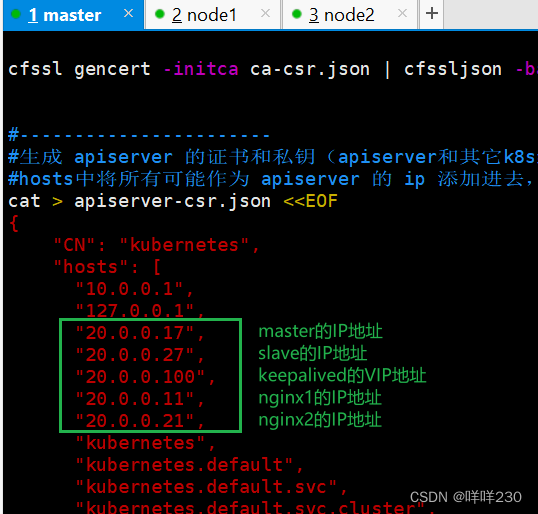
![]()
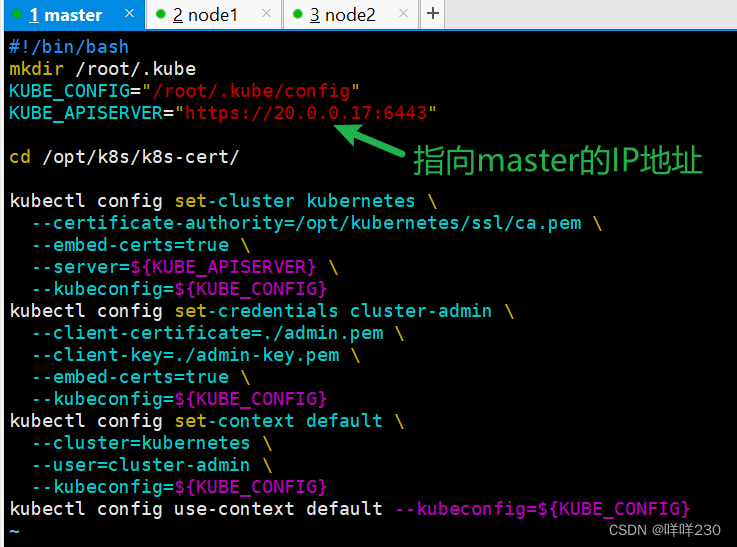
| context | 上下文,定义连接到哪个k8s集群,以及使用哪个用户的身份进行操作,上下文包含集群、用户、可选命名空间的信息。目的:在k8s的集群环境中进行切换 |
![]()

![]()

(2)创建kubernetes工作目录
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}

(2)创建用于生成CA证书、相关组件的证书和私钥的目录
mkdir /opt/k8s/k8s-cert
mv /opt/k8s/k8s-cert.sh /opt/k8s/k8s-cert
cd /opt/k8s/k8s-cert/
./k8s-cert.sh #生成CA证书、相关组件的证书和私钥


(3)复制CA证书、apiserver相关证书和私钥到 kubernetes工作目录的 ssl 子目录中
cp ca*pem apiserver*pem /opt/kubernetes/ssl/

(4)上传 kubernetes-server-linux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 kubernetes 压缩包
#下载地址:https://github.com/kubernetes/kubernetes/blob/release-1.20/CHANGELOG/CHANGELOG-1.20.md
#注:打开链接你会发现里面有很多包,下载一个server包就够了,包含了Master和Worker Node二进制文件。
cd /opt/k8s/
tar zxvf kubernetes-server-linux-amd64.tar.gz
![]()
(5)复制master组件的关键命令文件到 kubernetes工作目录的 bin 子目录中
cd /opt/k8s/kubernetes/server/bin
cp kube-apiserver kubectl kube-controller-manager kube-scheduler /opt/kubernetes/bin/
ln -s /opt/kubernetes/bin/* /usr/local/bin/

(6)创建 bootstrap token 认证文件,apiserver 启动时会调用,然后就相当于在集群内创建了一个这个用户,
接下来就可以用 RBAC 进行授权
cd /opt/k8s/
vim token.sh
#!/bin/bash
#获取随机数前16个字节内容,以十六进制格式输出,并删除其中空格
BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ' ')
#生成 token.csv 文件,按照 Token序列号,用户名,UID,用户组 的格式生成
cat > /opt/kubernetes/cfg/token.csv <<EOF
${BOOTSTRAP_TOKEN},kubelet-bootstrap,10001,"system:kubelet-bootstrap"
EOF
![]()
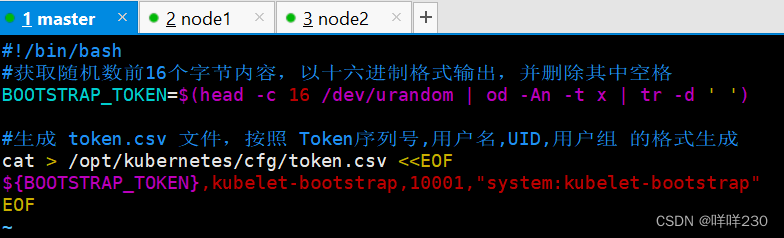
chmod +x token.sh
./token.sh
cat /opt/kubernetes/cfg/token.csv
![]()
![]()
![]()
(7)二进制文件、token、证书都准备好后,开启 apiserver 服务
cd /opt/k8s/
./apiserver.sh 20.0.0.17 https://20.0.0.17:2379,https://20.0.0.37:2379,https://20.0.0.47:2379
![]()
检查进程是否启动成功
ps aux | grep kube-apiserver
netstat -natp | grep 6443 #安全端口6443用于接收HTTPS请求,用于基于Token文件或客户端证书等认证

(8)启动 scheduler 服务
cd /opt/k8s/
./scheduler.sh
ps aux | grep kube-scheduler

(9)启动 controller-manager 服务
./controller-manager.sh
ps aux | grep kube-controller-manager

(10)生成kubectl连接集群的kubeconfig文件
./admin.sh

(11)通过kubectl工具查看当前集群组件状态
kubectl get cs

(12)查看版本信息
kubectl version

8、部署node 组件
【node1、node2】
(1)创建kubernetes工作目录
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}

(2)上传 node.zip 到 /opt 目录中,解压 node.zip 压缩包,获得kubelet.sh、proxy.sh
cd /opt/
unzip node.zip
chmod +x kubelet.sh proxy.sh
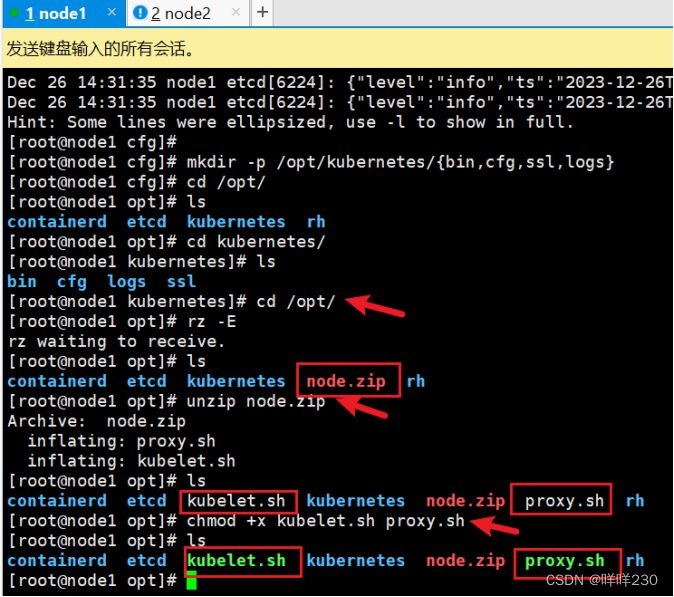
【master】
(3)把 kubelet、kube-proxy 拷贝到 node 节点
cd /opt/k8s/kubernetes/server/bin
scp kubelet kube-proxy root@20.0.0.37:/opt/kubernetes/bin/
scp kubelet kube-proxy root@20.0.0.47:/opt/kubernetes/bin/
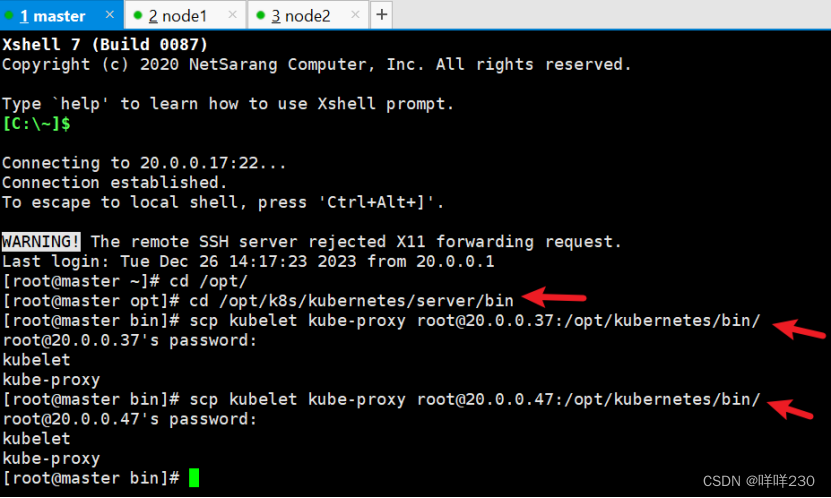
(4)上传kubeconfig.sh文件到/opt/k8s/kubeconfig目录中,生成kubelet初次加入集群引导kubeconfig文件和kube-proxy.kubeconfig文件
#kubeconfig 文件包含集群参数(CA 证书、API Server 地址),
客户端参数(上面生成的证书和私钥),集群 context 上下文参数(集群名称、用户名)
Kubenetes 组件(如 kubelet、kube-proxy)通过启动时指定不同的 kubeconfig 文件可以切换到不同的集群,
连接到 apiserver
mkdir /opt/k8s/kubeconfig
cd /opt/k8s/kubeconfig
chmod +x kubeconfig.sh
./kubeconfig.sh 20.0.0.17 /opt/k8s/k8s-cert/

(5)把配置文件 bootstrap.kubeconfig、kube-proxy.kubeconfig 拷贝到 node 节点
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@20.0.0.37:/opt/kubernetes/cfg/
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@20.0.0.47:/opt/kubernetes/cfg/

(6)RBAC授权,使用户 kubelet-bootstrap 能够有权限发起 CSR 请求证书
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
若执行失败,可先给kubectl绑定默认cluster-admin管理员集群角色,授权对整个集群的管理员权限
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
![]()
【node1】
(7)启动 kubelet 服务
cd /opt/
./kubelet.sh 20.0.0.37
ps aux | grep kubelet

【master】
(8)在 master01 节点上操作,通过 CSR 请求
#检查到 node01 节点的 kubelet 发起的 CSR 请求,Pending 表示等①待集群给该节点签发证书
kubectl get csr
②通过 CSR 请求
kubectl certificate approve node-csr-1yB8Di5O7ViXLgOr3yqnSWkAh2ug4IqN5QYFWQKzGQc
③Approved,Issued 表示已授权 CSR 请求并签发证书
kubectl get csr

【node2】
(9)启动 kubelet 服务
cd /opt/
./kubelet.sh 20.0.0.47
ps aux | grep kubelet

【master】
(10)在 master01 节点上操作,通过 CSR 请求
#检查到 node01 节点的 kubelet 发起的 CSR 请求,Pending 表示等①待集群给该节点签发证书
kubectl get csr
②通过 CSR 请求
kubectl certificate approve node-csr-1yB8Di5O7ViXLgOr3yqnSWkAh2ug4IqN5QYFWQKzGQc
③Approved,Issued 表示已授权 CSR 请求并签发证书
kubectl get csr

④查看节点,由于网络插件还没有部署,节点会没有准备就绪NotReady
kubectl get node

【node1】
(11)加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done

(12)启动proxy服务
cd /opt/
./proxy.sh 20.0.0.37
ps aux | grep kube-proxy

【node2】
(13)加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done

(14)启动proxy服务
cd /opt/
./proxy.sh 20.0.0.47
ps aux | grep kube-proxy

【master】
kubectl get cs
kubectl get node

注:自动补齐命令
![]()
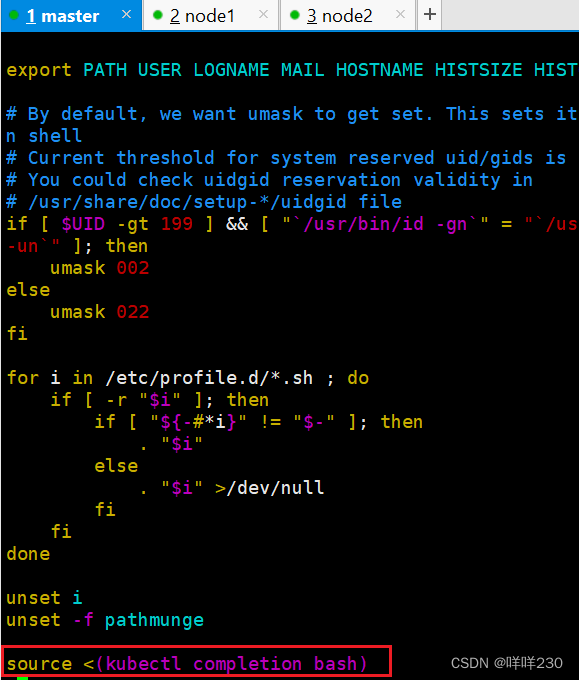
![]()
【所有node节点】
9、部署网络
方式1:vxlan模式
【node01】
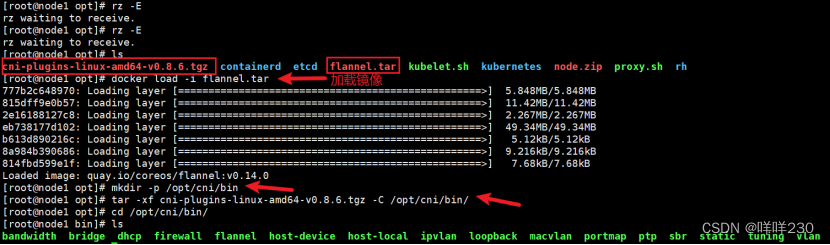
(1)上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tar
mkdir -p /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
【node2】
(2)上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tar
mkdir -p /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin

【master】
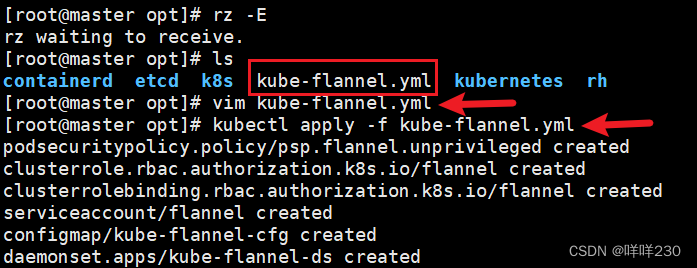
(3)上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
kubectl apply -f kube-flannel.yml
kubectl get pods -n kube-system
kubectl get nodes


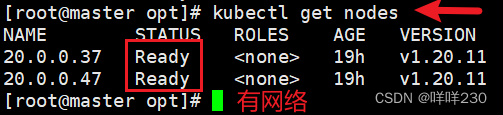
查看node1节点

查看node2节点

方式2:calico
【master】
(1)上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
vim calico.yaml
#修改里面定义 Pod 的网络(CALICO_IPV4POOL_CIDR),需与前面 kube-controller-manager 配置文件指定的 cluster-cidr 网段一样
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16" #Calico 默认使用的网段为 192.168.0.0/16
kubectl apply -f calico.yaml
kubectl get pods -n kube-system



等 Calico Pod 都 Running,节点也会准备就绪
kubectl get nodes

查看node节点

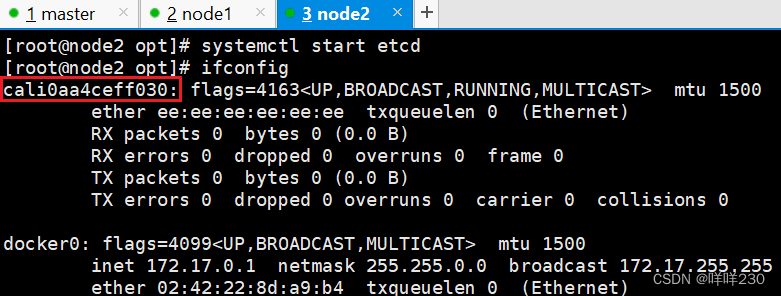
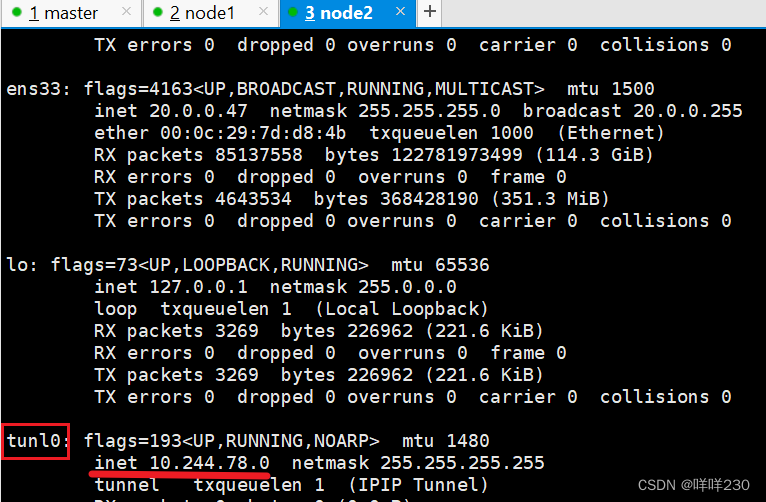
创建一个pod
kubectl create deployment nginx1 --image=nginx --replicas=3


每创建一个pod,就会生成一个cali网卡

每创建一个容器会生成一个路由表,路由表会越来越多,降低转发效率,需要定期维护
删除pod节点,会自动删除相应的网卡和路由表
10、部署多节点
【所有节点】
(1)主机映射
vim /etc/hosts

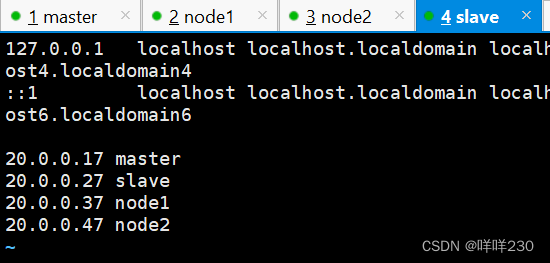


【slave】
(2)安装时间同步
yum install ntpdate -y
ntpdate ntp.aliyun.com

(3)清空所有策略、关闭swap交换分区
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab

(4)调整内核参数
sysctl --system
【master】
(5)从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点
scp -r /opt/etcd/ root@20.0.0.27:/opt/
scp -r /opt/kubernetes/ root@20.0.0.27:/opt
scp -r /root/.kube root@20.0.0.27:/root
scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service root@20.0.0.27:/usr/lib/systemd/system/

修改配置文件kube-apiserver中的IP
vim /opt/kubernetes/cfg/kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=true \
--v=4 \
--etcd-servers=https://20.0.0.17:2379,https://20.0.0.37:2379,https://20.0.0.47:2379 \
--bind-address=20.0.0.27 \ #修改
--secure-port=6443 \
--advertise-address=20.0.0.27 \ #修改
![]()
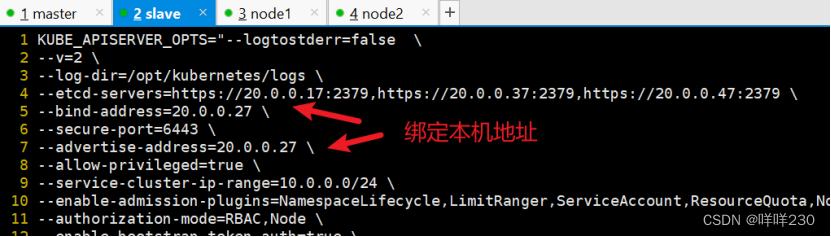
(6)在 slave节点上启动各服务并设置开机自启
systemctl start kube-apiserver.service
systemctl enable kube-apiserver.service
systemctl start kube-controller-manager.service
systemctl enable kube-controller-manager.service
systemctl start kube-scheduler.service
systemctl enable kube-scheduler.service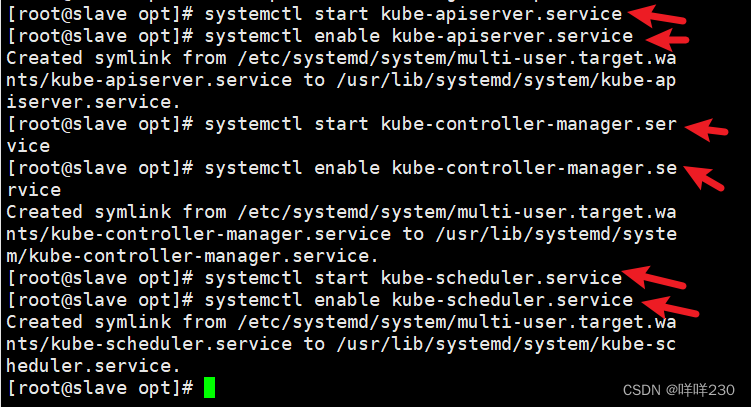
(7)查看node节点状态
ln -s /opt/kubernetes/bin/* /usr/local/bin/
kubectl get nodes
kubectl get nodes -o wide #-o=wide:输出额外信息;对于Pod,将输出Pod所在的Node名

此时在slave节点查到的node节点状态仅是从etcd查询到的信息,
而此时node节点实际上并未与master02节点建立通信连接,因此需要使用一个VIP把node节点与master节点都关联起来
11、负载均衡部署
【所有nginx节点】
不能用epel源下载nginx,用官方源或者编译安装1.22.0下载,支持四层代理
【nginx1】
(1)配置nginx的官方在线yum源,配置本地nginx的yum源
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOF
yum install nginx -y

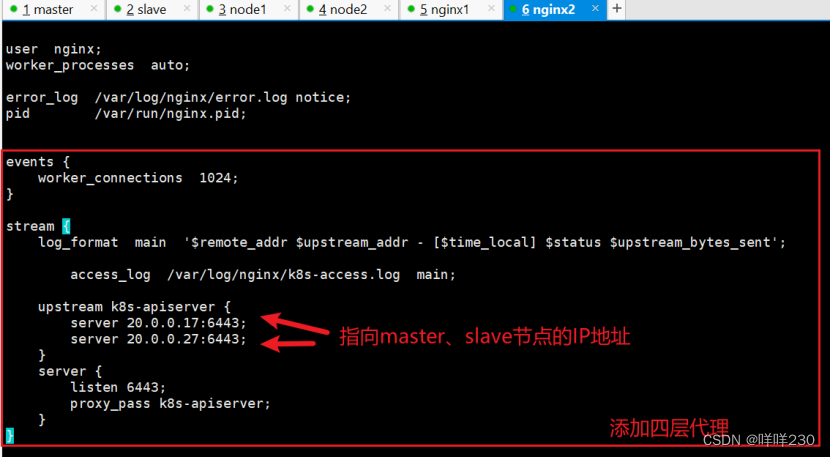
(2)修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
vim /etc/nginx/nginx.conf
events {
worker_connections 1024;
}
#添加
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
#日志记录格式
#$remote_addr: 客户端的 IP 地址。
#$upstream_addr: 上游服务器的地址。
#[$time_local]: 访问时间,使用本地时间。
#$status: HTTP 响应状态码。
#$upstream_bytes_sent: 从上游服务器发送到客户端的字节数。
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.233.91:6443;
server 192.168.233.92:6443;
}
server {
listen 6443;
proxy_pass k8s-apiserver;
}
}
http {
......

(3)检查配置文件语法
nginx -t

(4)启动nginx服务,查看已监听6443端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx

【nginx2】
(5)配置nginx的官方在线yum源,配置本地nginx的yum源
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOF
yum install nginx -y


(6)修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
vim /etc/nginx/nginx.conf
events {
worker_connections 1024;
}
#添加
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
#日志记录格式
#$remote_addr: 客户端的 IP 地址。
#$upstream_addr: 上游服务器的地址。
#[$time_local]: 访问时间,使用本地时间。
#$status: HTTP 响应状态码。
#$upstream_bytes_sent: 从上游服务器发送到客户端的字节数。
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.233.91:6443;
server 192.168.233.92:6443;
}
server {
listen 6443;
proxy_pass k8s-apiserver;
}
}
http {
......
(7)检查配置文件语法
nginx -t

(8)启动nginx服务,查看已监听6443端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx

12、部署keepalived服务
【所有nginx节点】
yum install keepalived -y


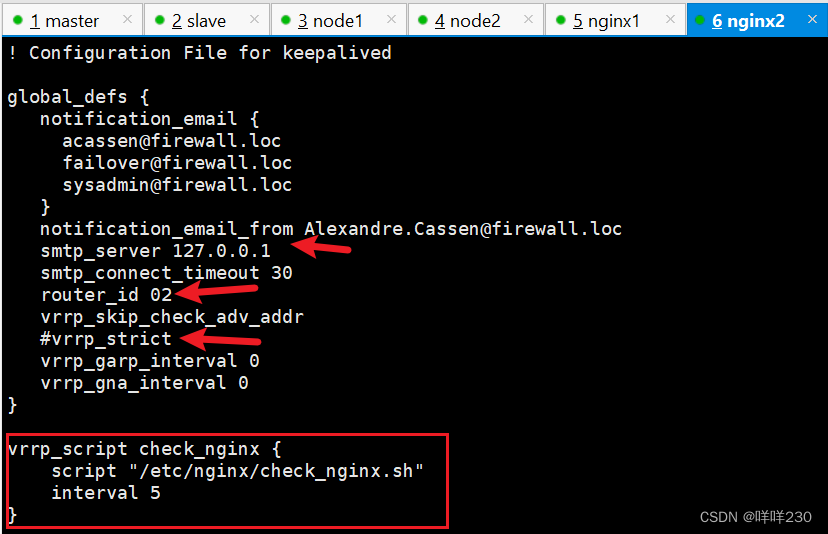
(1)修改keepalived配置文件
vim /etc/keepalived/keepalived.conf



(2)创建nginx状态检查脚本
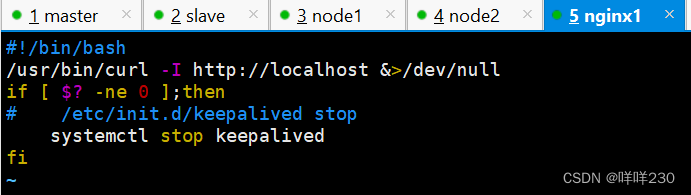
【nginx1】
vim /etc/nginx/check_nginx.sh
#!/bin/bash
/usr/bin/curl -I http://localhost &>/dev/null
if [ $? -ne 0 ];then
# /etc/init.d/keepalived stop
systemctl stop keepalived
fi
chmod +x /etc/nginx/check_nginx.sh
![]()
(3)启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)
systemctl start keepalived
systemctl enable keepalived
ip a #查看VIP是否生成


关闭nginx、keepalived测试vip地址是否能漂移到备服务器
停止主服务器的nginx
![]()
查看vip地址是否漂移到备服务器上
ip addr

结论:keepalived高可用正常
【所有node节点】
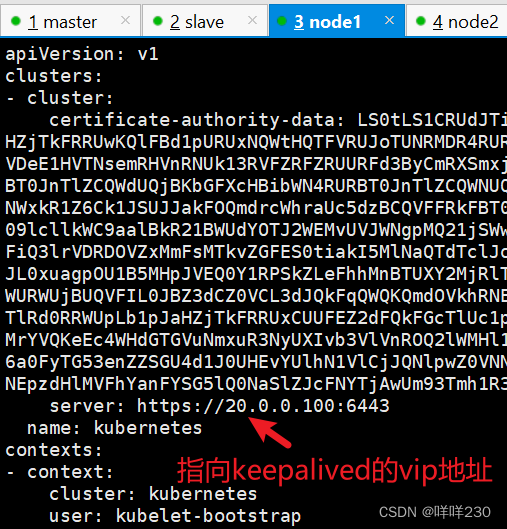
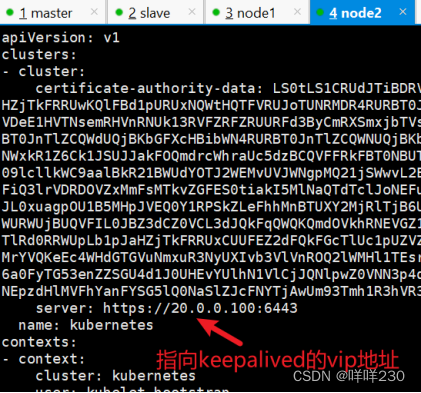
(4)修改node节点上的bootstrap.kubeconfig,kubelet.kubeconfig配置文件为VIP
cd /opt/kubernetes/cfg/
vim bootstrap.kubeconfig
server: https://20.0.0.100:6443
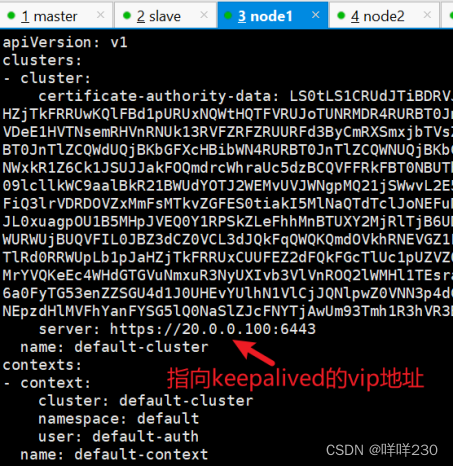
vim kubelet.kubeconfig
server: https://20.0.0.100:6443
vim kube-proxy.kubeconfig
server: https://20.0.0.100:6443
【node1】

![]()
![]()
![]()

【node2】

![]()
![]()

![]()

(5)重启kubelet和kube-proxy服务
systemctl restart kubelet.service
systemctl restart kube-proxy.service

![]()
(6)在主服务器 nginx1上查看 nginx 和 node 、 master 节点的连接状态
netstat -natp | grep nginx

搭建完成
13、部署 Dashboard
【master】
Dashboard仪表盘,k8s的可视化界面,在这个可视化界面,可以对k8s进行可视化管理
(1)上传 recommended.yaml 文件到 /opt/k8s 目录中
cd /opt/k8s
vim recommended.yaml
kubectl apply -f recommended.yaml


(2)创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin

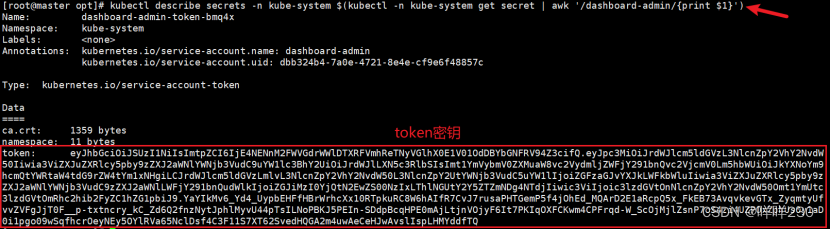
(3)获取token值
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
(4)使用输出的token登录Dashboard【node节点访问火狐浏览器,谷歌】
https://20.0.0.37:30001





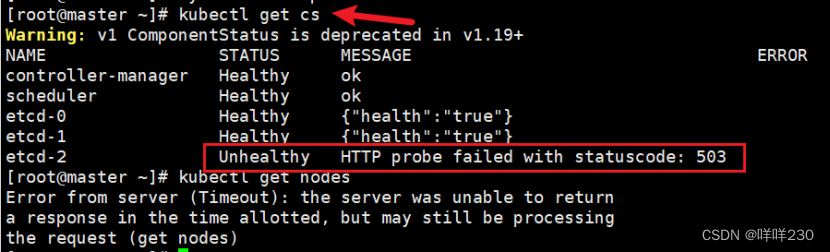
集群中的node节点出现故障,怎么解决?
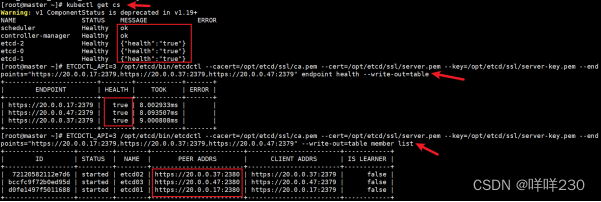
kubectl get cs
查看etcd集群成员列表
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://20.0.0.17:2379,https://20.0.0.37:2379,https://20.0.0.47:2379" --write-out=table member list
检查etcd群集状态
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://20.0.0.17:2379,https://20.0.0.37:2379,https://20.0.0.47:2379" endpoint health --write-out=table
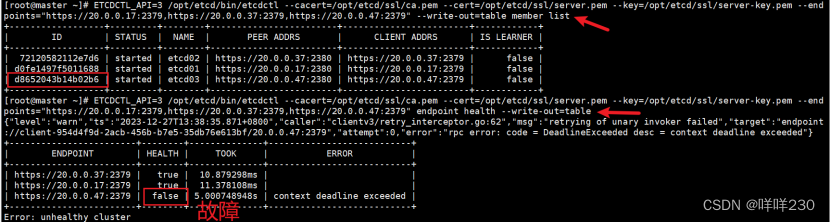
将有故障的etcd节点remove出集群
/opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://20.0.0.17:2379,https://20.0.0.37:2379,https://20.0.0.47:2379" member remove 故障节点的id

来到故障节点
rm -rf /var/lib/etcd/default.etcd/member/
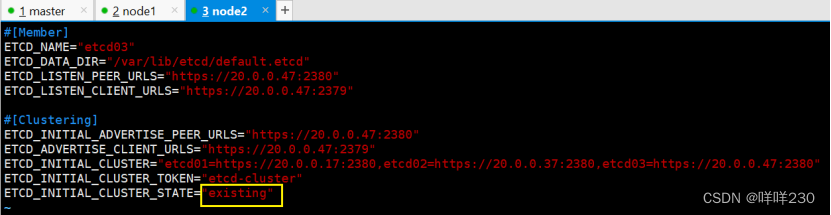
修改etcd配置文件,将下面new修改为:
vim /opt/etcd/cfg/etcd
修改前:
ETCD_INITIAL_CLUSTER_STATE="new"
修改后:
ETCD_INITIAL_CLUSTER_STATE="existing"
重新加入etcd集群
/opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://20.0.0.17:2379,https://20.0.0.37:2379,https://20.0.0.47:2379" member add etcd03 --peer-urls=https://20.0.0.47:2380

重启etcd故障节点
![]()
在master节点查看



![构建搜索引擎,而非向量数据库(Vector DB) [译]](https://img-blog.csdnimg.cn/img_convert/8321c354d095da7d382a47f13b76d7b9.png)