视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
Hadoop入门学习笔记(汇总)
目录
- 七、Hive语法
- 7.1. 数据库相关操作
- 7.1.1. 创建数据库
- 7.1.2. 选择数据库
- 7.1.3. 描述数据库详细信息
- 7.1.4. 创建数据库并指定其在HDFS系统中的存储位置
- 7.1.5. 删除数据库
- 7.1.6. 修改数据库存储位置
- 7.1.7. 查询当前USE的数据库
- 7.2. 数据表操作
- 7.2.1. Hive所支持的数据类型
- 7.2.2. 创建数据表
- 7.2.2.1. 基础建表语句
- 7.2.2.2. 基于其他表的结构建表
- 7.2.2.3. 基于查询结果建表
- 7.2.2.4. 建表时指定Hive数据分隔符
- 7.2.3. 删除表
- 7.2.4. 数据加载和导出
- 7.2.4.1. 数据加载
- 7.2.4.2. 数据导出
- 7.2.5. 分区表
- 7.2.6. 分桶表
- 7.2.6.1. 开启分桶的自动优化(自动匹配Reduce task数量和桶的数量一致)
- 7.2.6.2. 创建分桶表
- 7.2.6.3. 分桶表加载数据
- 7.2.7. 修改表
- 7.2.7.1. 表重命名
- 7.2.7.2. 修改表的属性
- 7.2.7.3. 修改表的分区
- 7.2.7.4. 修改表的列
- 7.2.7.5. 删除表
- 7.2.7.6. 清空表的数据
- 7.2.8. 复杂类型操作
- 7.2.8.1. array(数组类型)
- 7.2.8.2. map(Key-Value型)
- 7.2.8.3. struct(复合类型)
- 7.2.8.4. array、map、struct总结
- 7.3. 数据查询
- 7.3.1. 基本查询
- 7.3.2. RLIKE 正则匹配
- 7.3.3. UNION联合
- 7.3.4. Sampling采样
- 7.3.5. Virtual Columns虚拟列
- 7.4. 函数
- 7.4.1. 数字、集合、转换、日期函数
- 7.4.1.1. Mathematical Functions 数学函数——部分
- 7.4.1.2. Collection Functions集合函数 - 全部
- 7.4.2. 条件、字符串、脱敏、其它函数
七、Hive语法
7.1. 数据库相关操作
7.1.1. 创建数据库
CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION 'path'] [COMMENT database_comment];
IF NOT EXISTS,如存在同名数据库不执行任何操作,否则执行创建数据库操作[LOCATION],自定义数据库存储位置,如不填写,默认数据库在HDFS的路径为:/user/hive/warehouse[COMMENT database_comment],可选,数据库注释
例如:
create database if not exists myhive;
创建一个名字为myhive的数据库,如果该数据已存在,则不再执行创建动作。
7.1.2. 选择数据库
USE db_name;
- 选择数据库后,后续
SQL操作基于当前选择的库执行 - 如不使用use,默认在
default库执行
例如:
use myhive;
使用myhive数据库;
若想切换回使用default库
USE DEFAULT;
7.1.3. 描述数据库详细信息
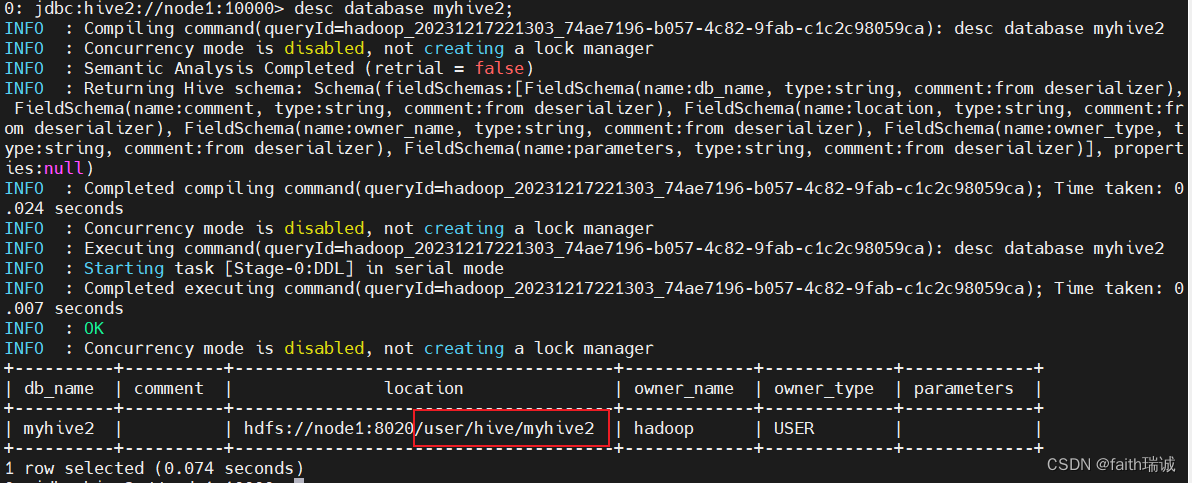
desc database myhive;
可以看到数据库名称、数据库存放路径、所属用户等信息。
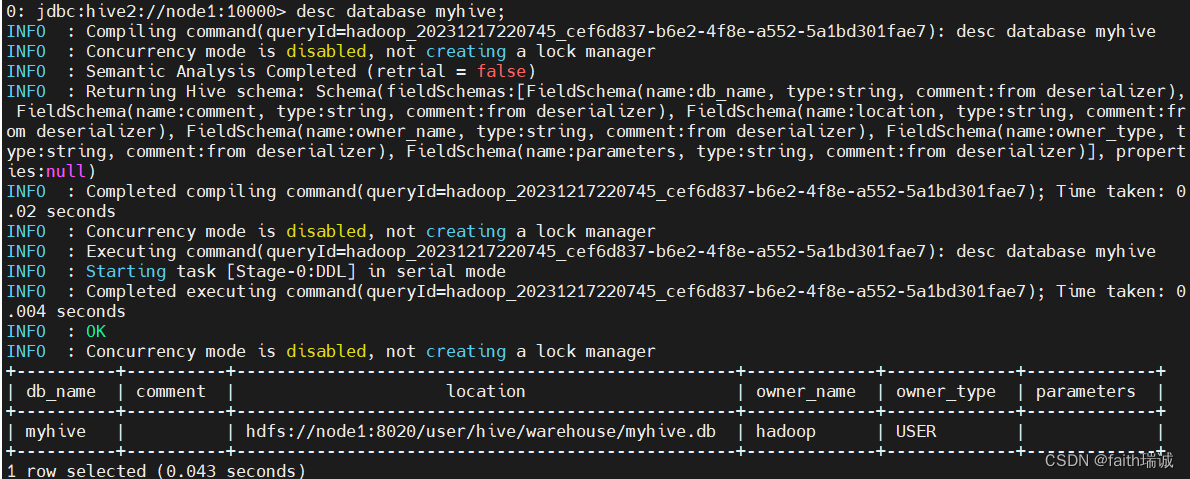
可以使用HDFS命令hadoop fs -ls /user/hive/warehouse查看对应的文件;

7.1.4. 创建数据库并指定其在HDFS系统中的存储位置
create database myhive2 location '/user/hive/myhive2';
此时可以再次使用desc database myhive2查看myhive2数据库的详细信息,可以看到myhive2数据库的存放路径是按照指定的位置存放的。

7.1.5. 删除数据库
DROP DATABASE [IF EXISTS] db_name [CASCADE];
[IF EXISTS],可选,如果存在此数据库执行删除,不存在不执行任何操作[CASCADE],可选,级联删除,即数据库内存在表,使用CASCADE可以强制删除数据库
例如:
删除一个空的数据库(无数据、无表)
drop database myhive;
删除一个非空数据库(有表或有数据)/ 强制删除数据库
drop database myhive2 cascade;
7.1.6. 修改数据库存储位置
ALTER DATABASE db_name SET LOCATION hdfs_path;
不会在HDFS对数据库所在目录进行改名,只是修改location后,新创建的表在新的路径,旧的不变
7.1.7. 查询当前USE的数据库
SELECT current_database();
7.2. 数据表操作
7.2.1. Hive所支持的数据类型
| 分类 | 类型 | 描述 | 字面量示例 |
|---|---|---|---|
| 原始类型 | BOOLEAN | true/false | TRUE |
| TINYINT | 1字节的有符号整数 -128~127 | 1Y | |
| SMALLINT | 2个字节的有符号整数,-32768~32767 | 1S | |
| INT | 4个字节的带符号整数 | 1 | |
| BIGINT | 8字节带符号整数 | 1L | |
| FLOAT | 4字节单精度浮点数1.0 | ||
| DOUBLE | 8字节双精度浮点数 | 1.0 | |
| DEICIMAL | 任意精度的带符号小数 | 1.0 | |
| STRING | 字符串,变长 | “a”,’b’ | |
| VARCHAR | 变长字符串 | “a”,’b’ | |
| CHAR | 固定长度字符串 | “a”,’b’ | |
| BINARY | 字节数组 | ||
| TIMESTAMP | 时间戳,毫秒值精度 | 122327493795 | |
| DATE | 日期 | ‘2016-03-29’ | |
| 时间频率间隔 | |||
| 复杂类型 | ARRAY | 有序的的同类型的集合 | array(1,2) |
| MAP | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) | |
| STRUCT | 字段集合,类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) | |
| UNION | 在有限取值范围内的一个值 | create_union(1,’a’,63) |
7.2.2. 创建数据表
7.2.2.1. 基础建表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] tb_name(col_name col_type [COMMENT col_comment], ......)[COMMENT tb_comment][PARTITIONED BY(col_name col_type, ......)][CLUSTERED BY(col_name, col_name, ......)[SORTED BY(col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][ROW FORMAT DELIMITED FIELDS TERMINATED BY ''][STORED AS SEQUENCEFILE|TEXTFILE|RCFILE][LOCATION 'path']
- [IF NOT EXISTS],若tb_name不存在则创建;
- [COMMENT tb_comment],表注释;
- [EXTERNAL],创建外部表,需与下列属性搭配:
- [ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘’],指定数据的分隔符;
- [LOCATION ‘path’],表在HDFS系统中的存放路径;
- [PARTITIONED BY(col_name col_type, …)],基于列进行分区存储,col_name为表中没有的列名,col_type为列的类型,支持依据多个列分区,这里的列不与表中的原始的数据列相同;
- [CLUSTERED BY(col_name, col_name, …) INTO num_buckets BUCKETS],基于列分桶,col_name为表中已有的列,num_buckets为分桶个数;
- [STORED AS SEQUENCEFILE|TEXTFILE|RCFILE],存储格式,如果文件数据是纯文本可以用TEXTFILE,如果数据需要压缩可以用SEQUENCEFILE;
- [LOCATION ‘path’],存储位置;
1、内部表和外部表的区别
-
内部表(CREATE TABLE table_name …)
未被external关键字修饰的即是内部表, 即普通表。内部表又称管理表,内部表数据存储的位置由hive.metastore.warehouse.dir参数决定(默认:/user/hive/warehouse),删除内部表会直接删除元数据(metadata)及存储数据,即在MySQL的Hive数据库的TBLS表中的数据和在HDFS系统中的文件都会被删除,因此内部表不适合和其他工具共享数据。 -
外部表(CREATE EXTERNAL TABLE table_name …LOCATION…)
被external关键字修饰的即是外部表, 即关联表。外部表的数据可以放在任何位置,通过LOCATION关键字指定。数据存储的不同也代表了这个表在理念是并不是Hive内部管理的,而是可以随意临时链接到外部数据上的。在删除外部表的时候, 仅删除元数据(表的信息),不会删除数据本身,即仅删除MySQL的Hive数据库的TBLS表中的数据,但HDFS系统中的文件不会被删除。
| 表类型 | 创建 | 存储位置 | 删除数据 | 理念 |
|---|---|---|---|---|
| 内部表 | CREATE TABLE … | Hive管理,默认/user/hive/warehouse | - 删除 元数据(表信息) - 删除 数据 | Hiv管理表 持久使用 |
| 外部表 | CREATE EXTERNAL TABLE … LOCATION … | 随意,LOCATION关键字指定 | - 进删除 元数据(表信息) - 保留 数据 | 临时链接外部数据用 |
2、使用内部表
使用以下语句建库、建表、插入数据
CREATE database myhive;
use myhive;
CREATE table stu(id int, name string);
INSERT INTO stu values(1, '周杰轮'), (2, '林君姐');
插入之后,由于是内部表,可以在HDFS系统中的/user/hive/warehouse/myhive.db/stu文件下看到对应的数据表存储文件

此时,使用hadoop fs -cat命令打开这个文件,查看其里面的内容,即是刚才插入的数据

其他一些创建内部表的方式:
-- 基于其它表的结构建表
CREATE TABLE tbl_name LIKE other_tbl;
-- 基于查询结果建表
CREATE TABLE tbl_name AS SELECT ...;
3、使用外部表,关联已有数据
3.1、第一种情况:先有表,后有数据
先在Linux系统中创建一个test_external.txt文件,内容如下(使用\t做为分隔符):
1 itheima
2 itcast
3 hadoop
在创建外部表之前,需要确保外部表所指定的存储位置的目录不存在,在本例中,需要确保HDFS系统中/tmp/test_ext1目录不存在;

然后创建外部表:
CREATE external table test_ext1(id int, name string) row format delimited fields terminated by '\t' LOCATION '/tmp/test_ext1';
创建一个外部表,表名为test_ext1,由2个字段id和name构成,该表的数据分隔符为\t,在HDFS系统中的存储位置为/tmp/test_ext1文件夹;

当前因为没有任何数据,所以该文件夹里面没有任何内容,这时,我们通过hadoop fs -put或hdfs dfs -put命令将前面在Linux中创建的test_external.txt文件上传到/tmp/test_ext1目录下;
hdfs dfs -put test_external.txt /tmp/test_ext1/
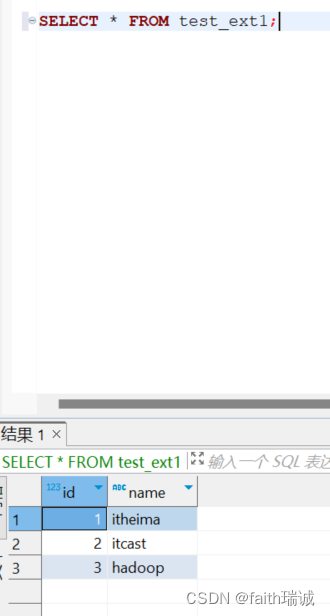
上传完成后,在Hive中执行SELECT * FROM test_ext1;语句,便可以看到刚才上传的文件中的数据了;
3.2、第二种情况:先有数据,后有表
先在HDFS中创建一个test_ext2目录
hadoop fs -mkdir /tmp/test_ext2
将数据文件上传到test_ext2目录下
hadoop fs -put test_external.txt /tmp/test_ext2
然后创建同名(test_ext2)的外部表,并将其存储位置设置为/tmp/test_ext2
CREATE external table test_ext2(id int, name string) row format delimited fields terminated by '\t' LOCATION '/tmp/test_ext2';
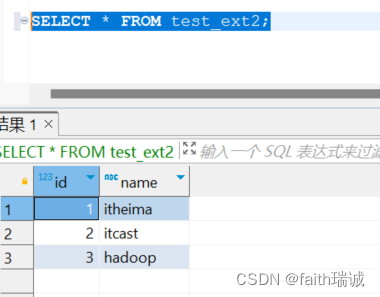
然后使用SELECT * FROM test_ext2;语句查询数据,发现数据可以被Hive读取到。
3.3、删除外部表
在删除表之前,查看元数据库(MySQL的Hive库)中的TBLS表的数据和HDFS文件系统对应位置的文件夹;


然后执行删表语句drop table test_ext1;,执行成功后,再次查看元数据库(MySQL的Hive库)中的TBLS表的数据和HDFS文件系统对应位置的文件夹;

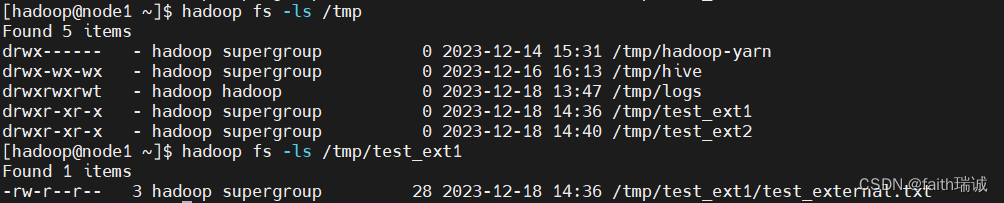
发现,元数据库中的表信息已被删除,但是HDFS系统中的数据文件仍然存在,未受影响。所以,删除外部表,完全不影响数据本身。
4、内外部表转换
创建一个内部表,创建一个外部表
-- 创建内部表t1
CREATE table t1(id int);
-- 创建外部表t2
CREATE external table t2(id int) row format delimited fields terminated by '\t' LOCATION '/tmp/t2';
使用desc formatted t1;语句查看t1表信息,可以看到,该表存储的位置在/user/hive/warehouse文件夹下,且其表类型为MANAGED_TABLE(即管理表,内部表);
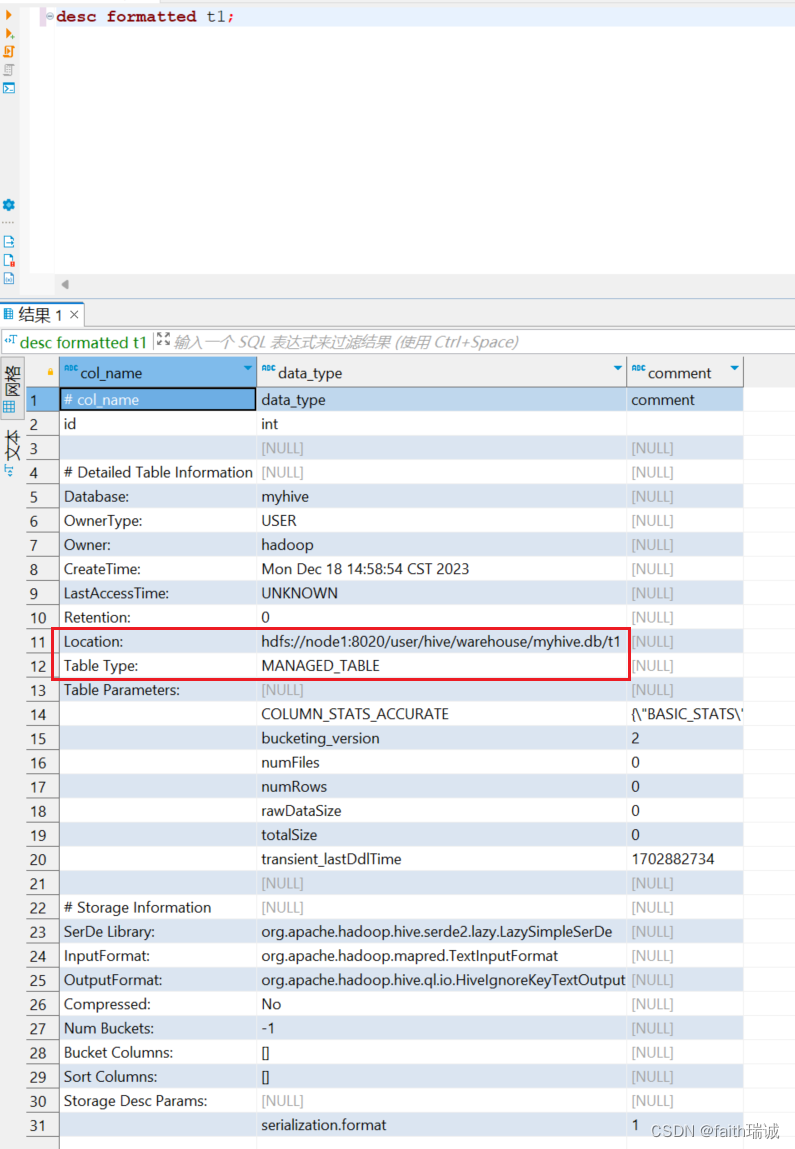
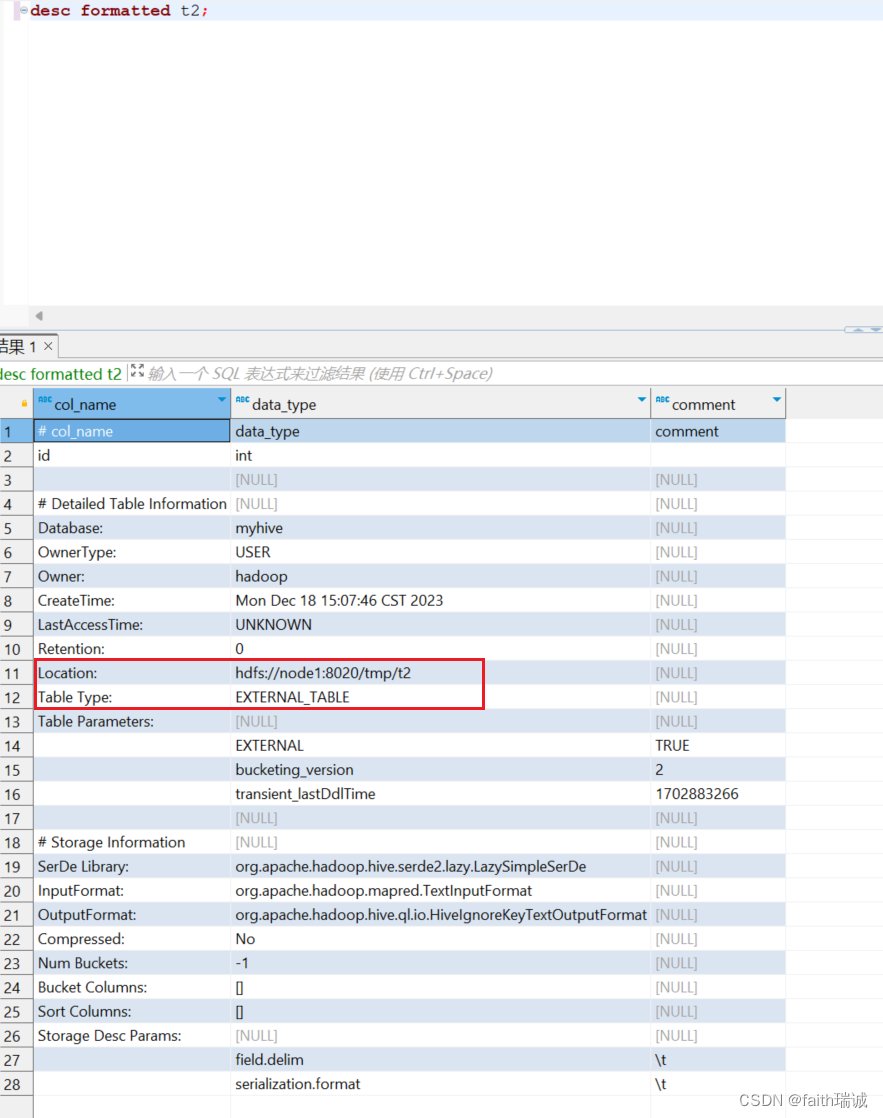
使用desc formatted t2;语句查看t2表信息,可以看到,该表存储的位置在/tmp/t2文件夹下,且其表类型为EXTERNAL_TABLE(即外部表);
4.1、内部表转换成外部表
ALTER table t1 set TBLPROPERTIES ('EXTERNAL'='TRUE');
将t1表从内部表转换成外部表。
4.2、外部表转换成内部表
ALTER table t2 set TBLPROPERTIES ('EXTERNAL'='FALSE');
将t2表从外部表转换成内部表,注意括号里的EXTERNAL和TRUE、FALSE必须大写。
7.2.2.2. 基于其他表的结构建表
CREATE TABLE tbl_name LIKE other_tbl;
7.2.2.3. 基于查询结果建表
CREATE TABLE tbl_name AS SELECT ...;
7.2.2.4. 建表时指定Hive数据分隔符
在HDFS系统中,通过hadoop fs -cat或hdfs dfs -cat命令查看Hive数据文件的内容时,在命令行里是看不到数据列的分隔符,这是因为,默认的分隔符是“\001”,是一个不可见的ASCII码,键盘打不出来,在有些文本编辑器中,其会显示为SOH,如下所示:
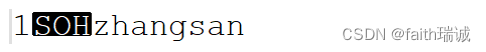
如果我们将Hive数据表文件下载到Linux服务器,然后使用vim工具打开查看,其会显示为^A,如下图所示:

当然,数据分隔符也是可以指定的,在创建表的时候,通过row format delimited fields terminated by可以指定,如将分隔符设置为一个制表符,则建表时可以如下写:
create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t';
7.2.3. 删除表
DROP TABLE tbl;
例如:
DROP table test;
DROP table myhive.test;
删除test表。
7.2.4. 数据加载和导出
7.2.4.1. 数据加载
1、LOAD语法(从文件向表导入数据)
在Hive客户端中执行以下语句:
LOAD DATA [LOCAL] INPATH 'path' [OVERWRITE] INTO TABLE tb_name [PARTITION(partition_key='partition_value')];
[LOCAL],表示要加载的数据文件是否在Linux文件系统中,若在Linux文件系统则需要写上LOCAL,若在HDFS系统则不需要写LOCAL;
‘path’,表示要加载的文件路径;
[OVERWRITE],表示是否要覆盖表中已有的数据(即表中原有的数据都删除,只保留本次导入的数据);
tb_name,为将数据加载进入的表名。
用法:
先创建一个内部表;
CREATE table myhive.test_load(dt string comment '时间',user_id string comment '用户id',search_word string comment '搜索关键词',url string comment '网址'
) comment '搜索引擎日志表' row format delimited fields terminated by '\t'
1.1、从Linux系统加载数据到Hive表中
将课程资料中的search_log.txt文件上传到node1服务器的/home/hadoop目录下;
直接从Linux系统中加载数据到test_load表;
load data local inpath '/home/hadoop/search_log.txt' into table test_load;
此时,数据就已经加载到了test_load表(加载速度很快);
1.2、从HDFS系统中加载数据到Hive表
将前面的search_log.txt文件上传到HDFS系统/tmp目录下;
hdfs dfs -put search_log.txt /tmp/
将HDFS文件系统中的search_log.txt文件加载到test_load表;
load data inpath '/tmp/search_log.txt' into table test_load;
此时,数据已导入test_load表中;
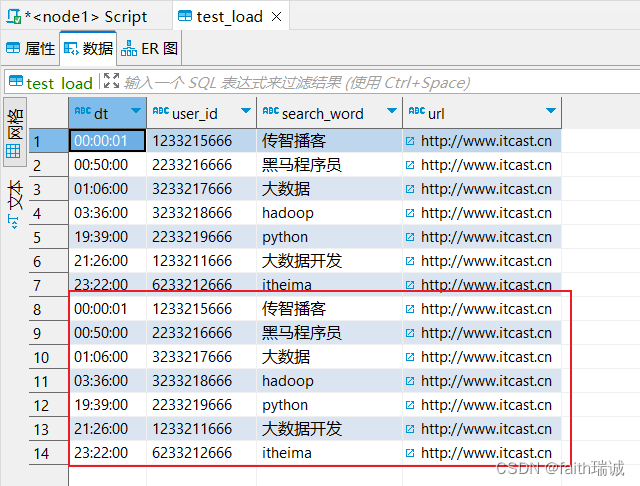
可以看到,数据已经变成了2份,第一份是前面从Linux本地导入的,第二份是从HDFS文件系统导入的;
此时,再次查看HDFS系统的/tmp目录,会发现之前上传的search_log.txt文件已经没有了,其实这个导入操作本质上是移动HDFS文件到Hive库表所在的目录。

1.3、演示overwirte属性
再次执行从Linux本地加载数据,但本次带上overwrite属性
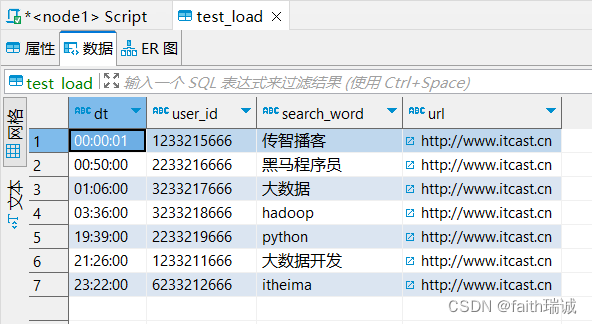
load data local inpath '/home/hadoop/search_log.txt' overwrite into table test_load;
执行完成后,再次查看test_load表的内容,会发现只剩了文件中的内容,而不像之前一样追加,这里是覆盖的写,该表中原有的数据全部被清空,只保留了本次导入的数据。
2、INSERT SELECT语法(从其他表向表导入数据)
在Hive客户端中执行以下语句:
INSERT [OVERWRITE | INTO] TABLE tb_name1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] SELECT select_statement1 FROM from_statement;
将SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表。
[OVERWRITE | INTO],表示覆盖或追加数据,覆盖时用OVERWRITE,追加时用INTO;
tb_name1,表示数据导入目标表的表名;
用法:
先创建一个内部表;
CREATE table myhive.test_load2(dt string comment '时间',user_id string comment '用户id',search_word string comment '搜索关键词',url string comment '网址'
) comment '搜索引擎日志表2' row format delimited fields terminated by '\t';
将test_load表中的数据导入test_load2
INSERT INTO table test_load2 select * FROM test_load;
执行上述语句,会发现又被转换成MapReduce任务执行,所以在大规模数据下与LOAD DATA没有区别,但是在小规模数据下,使用LOAD DATA会更快一些。
此时,test_load2表中已经有了数据。
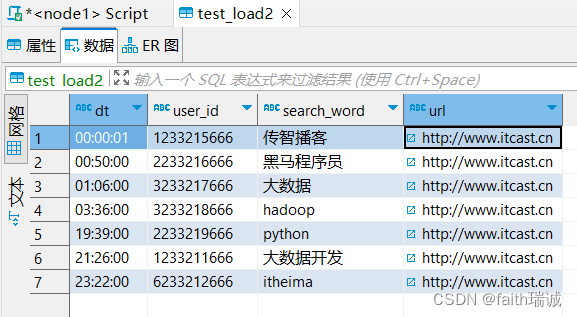
如果再次执行上面的SQL,会发现test_load2表里面的数据会被追加一份。
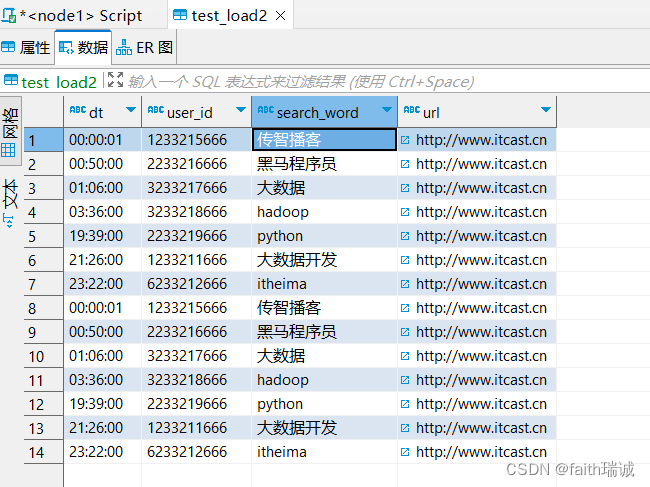
如果将上面的SQL语句修改为:
INSERT OVERWRITE table test_load2 select * FROM test_load;
执行完成后,查看数据,会发现之前的数据被覆盖了,只保留了本次SQL执行的结果。
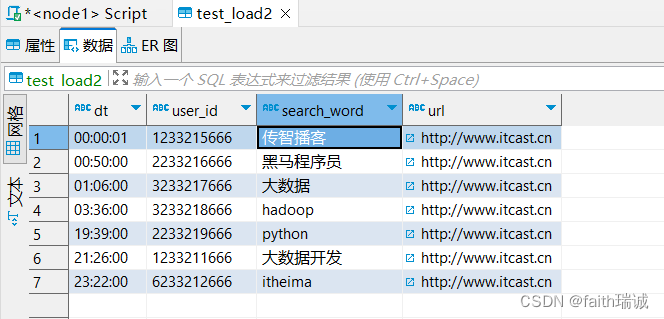
3、数据导入方式的选择
- 数据在Linux本地
- 推荐使用load data local方式加载;
- 数据在HDFS系统
- 如果不需要保留源文件:推荐使用load data方式加载;
- 如果需要保留源文件:推荐使用外部表先关联数据,然后通过insert select方式加载;
- 数据已经在Hive表中
- 只能使用insert select方式加载。
7.2.4.2. 数据导出
1、INSERT OVERWRITE方式
在Hive客户端中执行以下语句:
insert overwrite [local] directory 'path' [row format delimited fields terminated by ''] select select_statement1 FROM from_statement;
将select语句的结果写入指定的文件中。
[local],表示是否导出到Linux系统本地,若是,则带上该参数,若不是,则不用写;
‘path’,表示Linux本地或HDFS系统中的路径,若前面有local,这里写的就是Linux系统路径,若没有local,这里写的就是HDFS文件系统路径,这里的path是一个文件夹;
[row format delimited fields terminated by ‘’],表示指定导出数据时所使用的数据分隔符(与表所使用的数据分隔符无关),默认分隔符为ASCII码\001,不可见。
用法:
1.1、导出数据到本地:
INSERT overwrite local directory '/home/hadoop/export1' select * FROM test_load;
将test_load表中的数据导出到Linux系统的/home/hadoop/export1文件夹中。
执行时发现,该语句需要被转换成MapReduce任务执行;
执行完成后,可以在/home/hadoop目录下看到export1文件夹;

进入该文件夹,并查看其内文件的内容
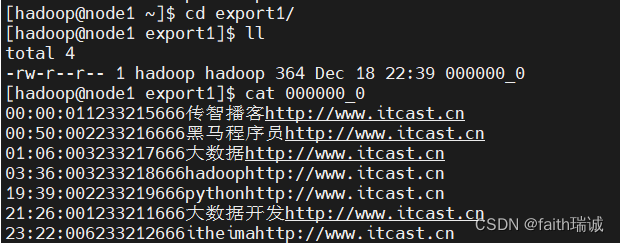
上图可以看到导出的数据,但是由于导出时未指定数据分隔符,所以使用的是默认分隔符,是不可见内容;
将上述导出语句中增加指定分隔符的参数:
INSERT overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * FROM test_load;
此时查看Linux本地的/home/hadoop/export2目录及其内容如下,可以看到导出的数据已通过\t进行了分割:
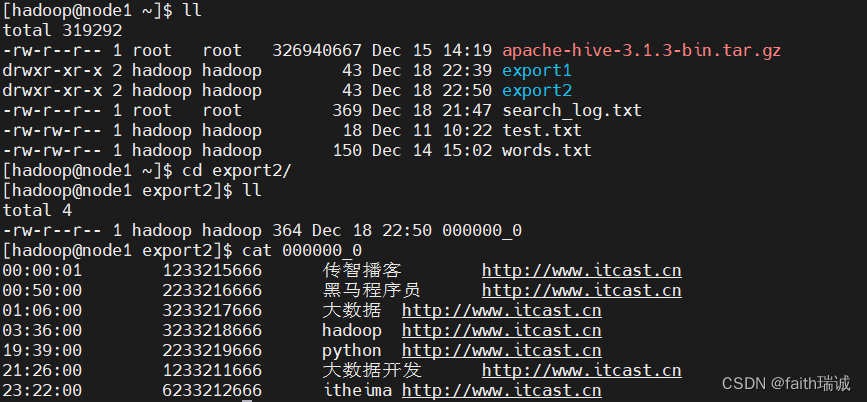
1.2、导出数据到HDFS系统中
INSERT overwrite directory '/tmp/export_to_hdfs1' row format delimited fields terminated by '\t' select * FROM test_load;
执行完成后,查看HDFS文件/tmp目录下的内容
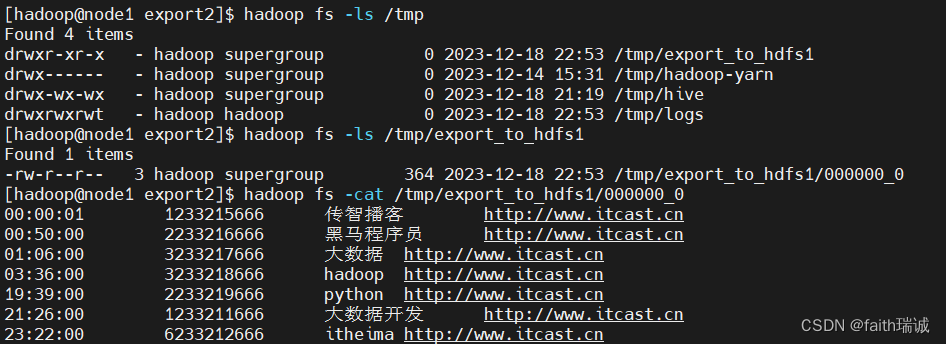
2、hive shell方式
在Linux的命令行下执行:
./hive -e "select ... from ...;" > 'local_path'
# 或
./hive -f 'sql_file_path' > 'local_path'
“select … from …;”,表示要执行的SQL语句;
‘local_path’,表示要导出的Linux文件路径;
‘sql_file_path’,表示要执行的SQL脚本文件在Linux中的路径;
用法:
2.1、通过SQL语句导出数据
# 切换目录
cd /export/server/hive/bin
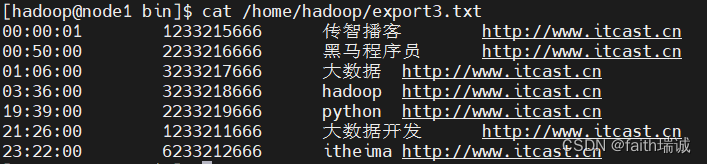
# 将Hive中的myhive库的test_load表的内容导出到Linux系统/home/hadoop/下的export3.txt文件中
./hive -e "select * from myhive.test_load;" > /home/hadoop/export3.txt
# 查看/home/hadoop/export3.txt的
cat /home/hadoop/export3.txt
2.2、通过SQL文件导出数据
在Linux系统/home/hadoop目录下创建一个export.sql文件,写入如下内容:
select * from myhive.test_load;
然后在Linux的命令行中执行如下命令:
# 使用hive -f命令,执行export.sql文件中的SQL语句,将其执行结果导出到当前目录下的export4.txt文件中
/export/server/hive/bin/hive -f export.sql > export4.txt
# 查看export4.txt文件内容
cat export4.txt

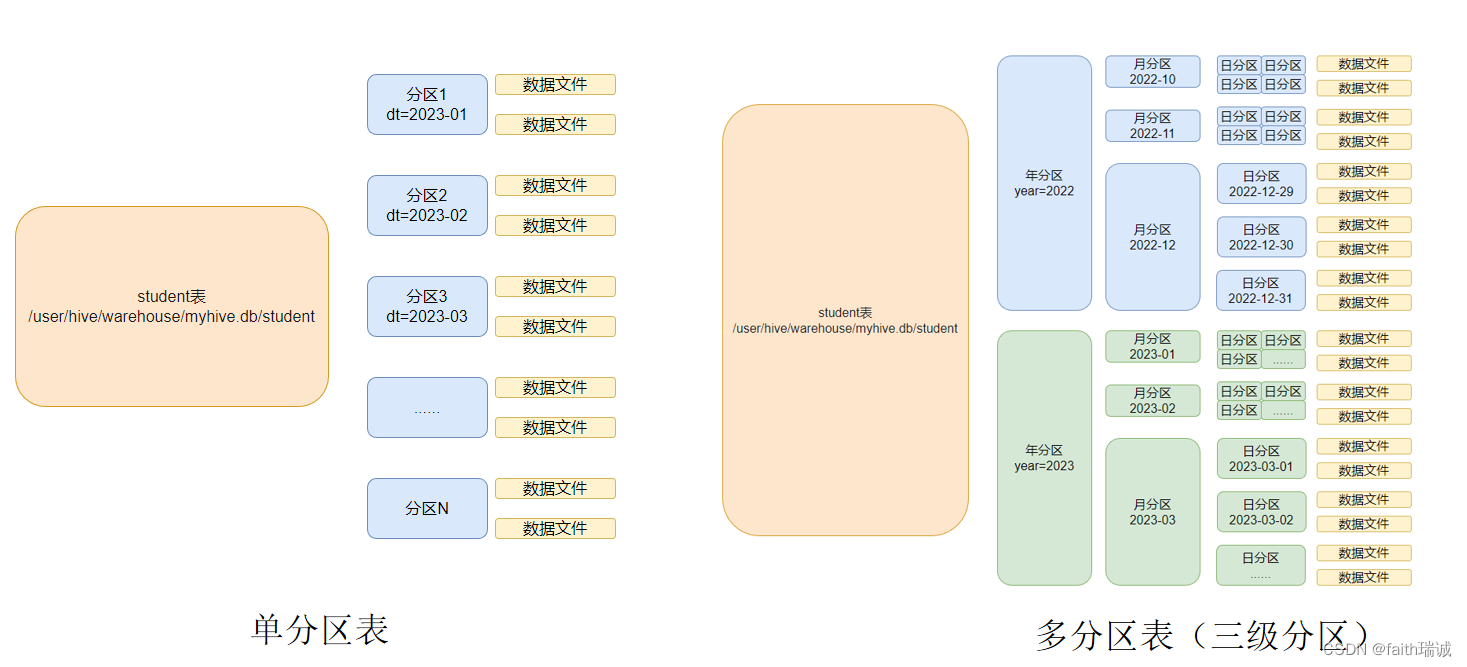
7.2.5. 分区表
在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了。
在hive当中也是支持这种思想的,就是我们可以把大的数据,按照一定的规则(如每天、每小时等)切分成一个个小的文件。
每一个分区,都是一个文件夹。同时,Hive也支持多个字段作为分区,多分区带有层级关系。
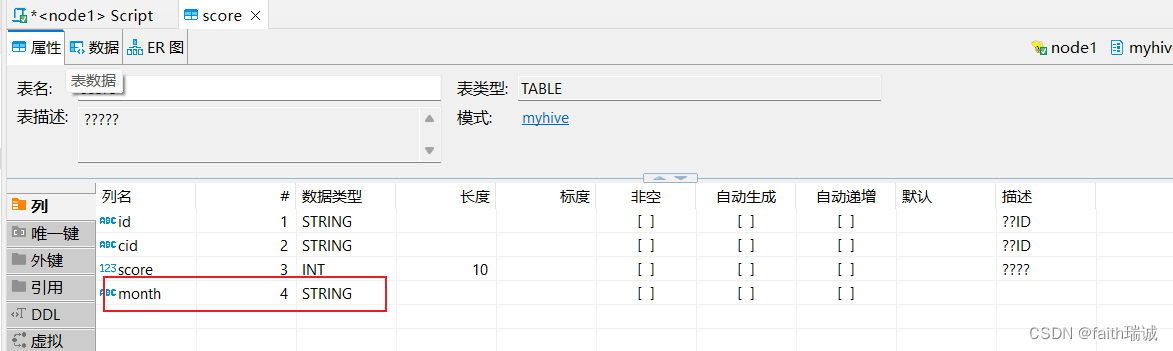
1、创建一个按月进行单分区(按month分区)的学生成绩表,并指定数据分隔符为\t
CREATE table myhive.score(id STRING COMMENT '学生ID',cid STRING COMMENT '课程ID',score int COMMENT '课程分数'
) COMMENT '学生成绩表'
partitioned by (month STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
将课程资料中score.txt文件加载到上表中,并指定分区的月份为202005;
load data local inpath '/home/hadoop/score.txt' into table myhive.score partition(month='202005');
上面创建的表,相当于有4个列,前3个列从数据文件中获取,最后一个列是当数据插入时进行指定;
load data local inpath '/home/hadoop/score.txt' into table myhive.score partition(month='202006');
再加载一次数据,本次指定month为 202006。
然后查看HDFS系统中score表所对应目录的情况;

对Linux本地的score.txt文件修改一些内容,然后再次加载数据
load data local inpath '/home/hadoop/score.txt' into table myhive.score partition(month='202007');
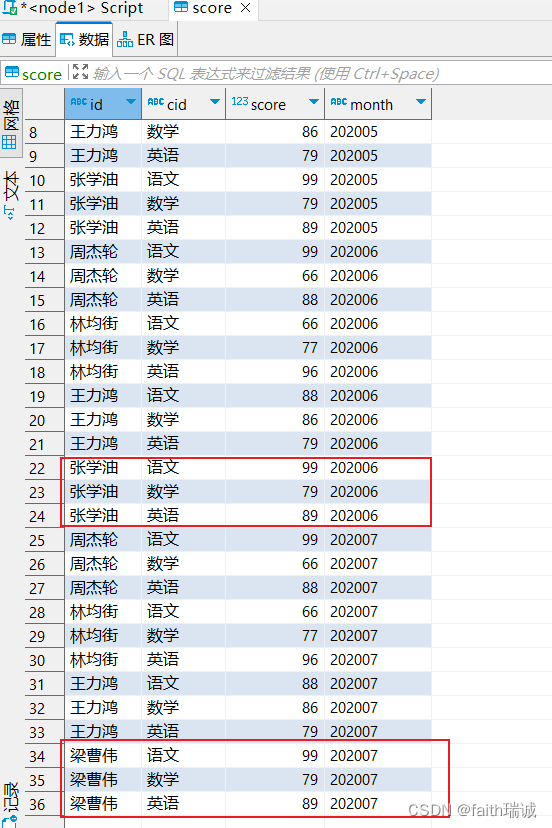

2、创建一个按年、月、日,三个层次的多分区学生成绩表,并指定数据分隔符为\t
CREATE table myhive.score2(id STRING COMMENT '学生ID',cid STRING COMMENT '课程ID',score int COMMENT '课程分数'
) COMMENT '学生成绩表2'
partitioned by (year STRING, month STRING, day STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
这个表实际有6个字段,其中前3个是数据列,后3个是在数据插入时指定的分区列
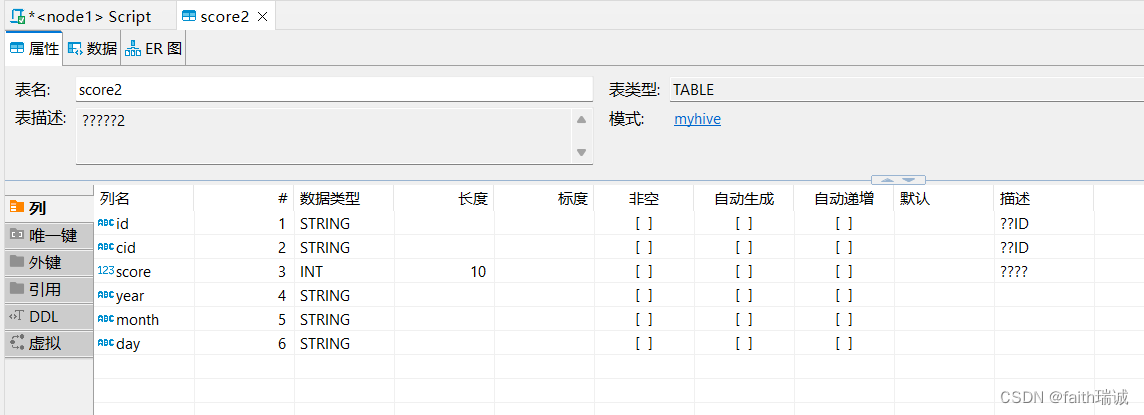
将Linux系统中score.txt的数据加载到上面的多分区表中
load data local inpath '/home/hadoop/score.txt' into table myhive.score2 partition(year="2022", month='01', day="10");
此时,score2表中的数据为,可以看到id,cid和score的数据来自score.txt文件的内容,而year,month,day三个字段的数据来自导入语句指定;
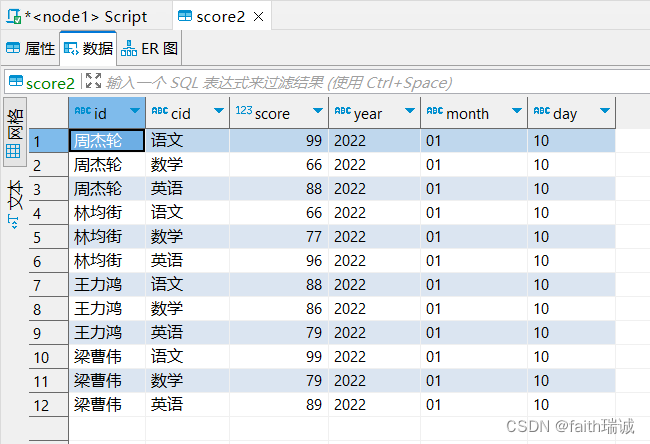
然后再查看HDFS系统中的目录结构
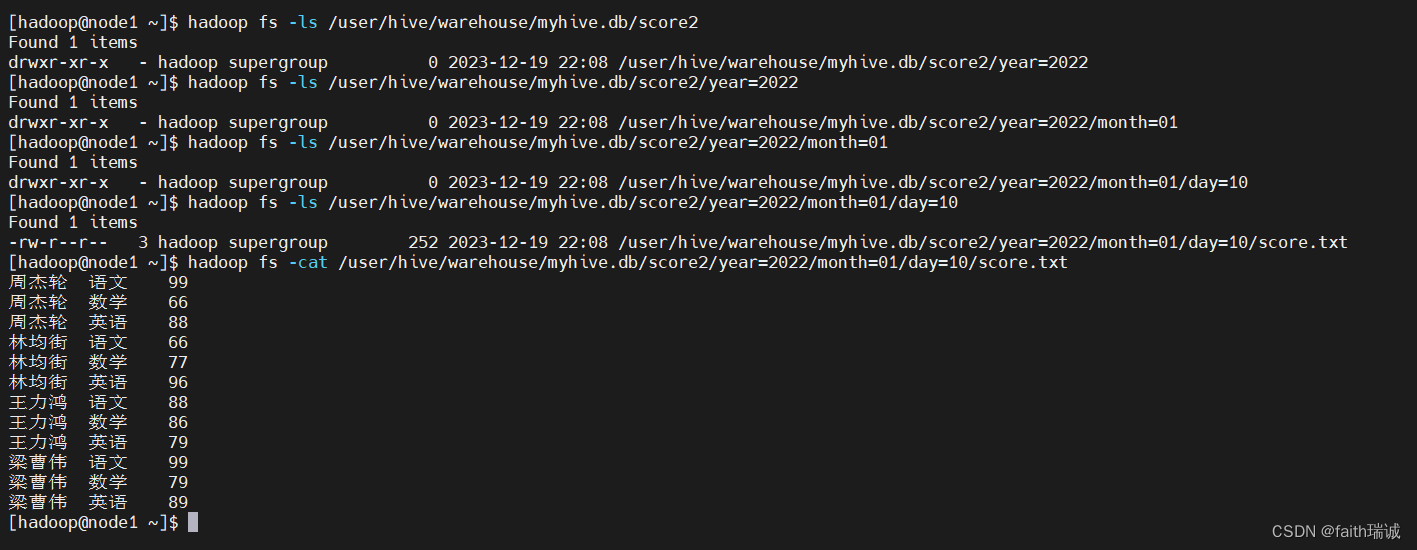
再导入几次数据
load data local inpath '/home/hadoop/score.txt' into table myhive.score2 partition(year="2022", month='01', day="11");
load data local inpath '/home/hadoop/score.txt' into table myhive.score2 partition(year="2023", month='01', day="11");
load data local inpath '/home/hadoop/score.txt' into table myhive.score2 partition(year="2022", month='02', day="11");
此时,再次查看HDFS系统中score2目录下的目录结构
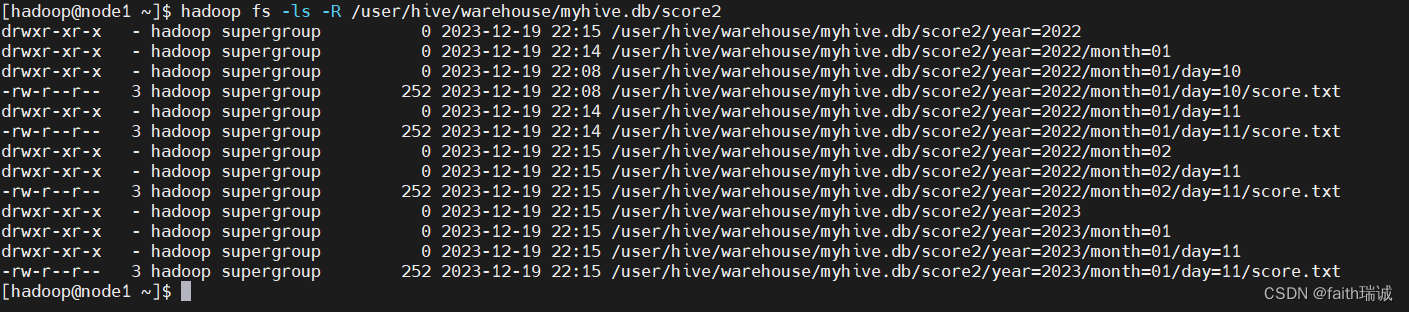
3、分区表在创建时指定的分区字段,在插入数据时必须都要传入,否则Hive会报错。
4、分区表查询时,如果以分区列做为where条件,会极大的提高查询效率,因为只需要读取对应文件夹下的数据即可。
7.2.6. 分桶表
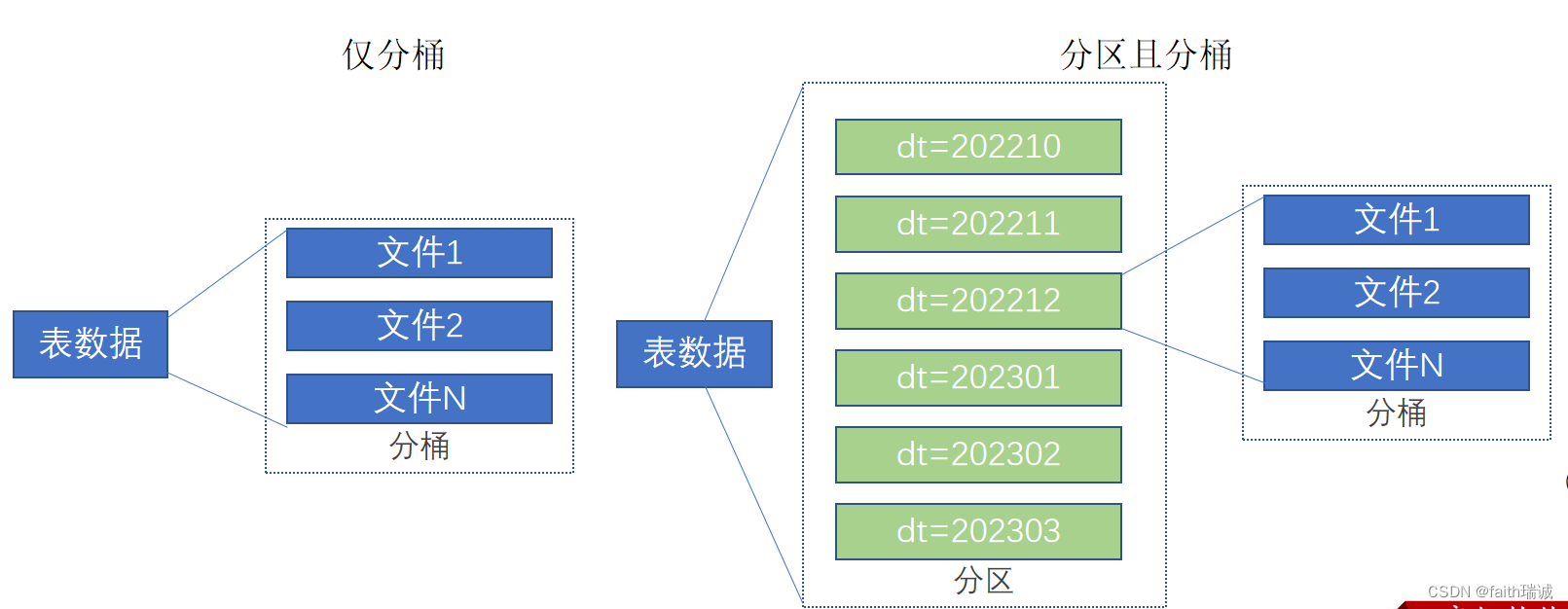
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式
但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。
7.2.6.1. 开启分桶的自动优化(自动匹配Reduce task数量和桶的数量一致)
set hive.enforce.bucketing = TRUE;
7.2.6.2. 创建分桶表
CREATE table myhive.course(c_id string, c_name string, t_id string) clustered by (c_id)
INTO 3 buckets row format delimited fields terminated by '\t';
创建一个course表,根据表中的c_id字段分三个桶;
7.2.6.3. 分桶表加载数据
由于桶表的数据加载通过load data无法执行,只能通过insert select方式加载。
1、创建一个临时表(外部表或内部表均可),通过load data把数据加载到临时表;
-- 创建临时中转表(需要注意,中转表的分隔符需要与分桶表保持一致)
CREATE table myhive.course_temp(c_id string, c_name string, t_id string) row format delimited fields terminated by '\t';
-- 将数据加载到中转表
load data local inpath '/home/hadoop/course.txt' into table myhive.course_temp;
2、从临时表通过insert select方式将数据加载到分桶表;
INSERT overwrite table myhive.course select * FROM myhive.course_temp cluster by(c_id);
这里需要注意,在向分桶表插入数据时,需要使用cluster by标明分桶依赖字段。注意,这里是cluster,而不是建表时缩写的clustered!
此时,我们可以查看HDFS系统中的文件情况hadoop fs -ls /user/hive/warehouse/myhive.db/course。
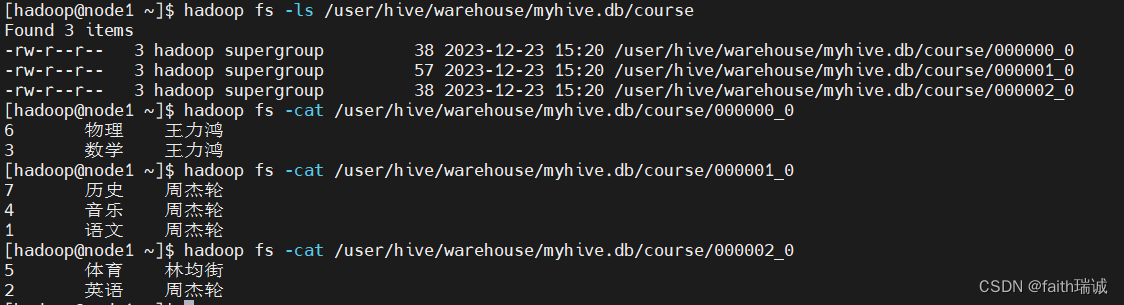
会发现,course表的数据被放在了三个文件中,这里是因为最开始创建分桶表时,指定的分桶数量为3,如果指定其他数量的分桶数,那就会生成对应的文件个数。
3、为什么不可以用load data,必须用insert select插入数据
如果没有分桶设置,插入(加载)数据只是简单的将数据放入到:
- 表的数据存储文件夹中(没有分区);
- 表指定分区的文件夹中(带有分区)。
一旦有了分桶设置,比如分桶数量为3,那么,表内文件或分区内数据文件的数量就限定为3。当数据插入的时候,需要一分为3,进入三个桶文件内。
数据的三份划分基于分桶列的值进行hash取模来决定,由于load data不会触发MapReduce,也就是没有计算过程(无法执行Hash算法),只是简单的移动数据而已,所以无法用于分桶表数据插入。
7.2.7. 修改表
7.2.7.1. 表重命名
语法:
alter table old_table_name rename to new_table_name;
old_table_name,当前的表名;
new_table_name,新的表名。
例如:
--将表score2重命名成score3
ALTER table score2 rename to score3;
7.2.7.2. 修改表的属性
语法:
ALTER TABLE table_name SET TBLPROPERTIES table_properties;
table_properties:: (property_name = property_value, property_name = property_value, ... )
例如:
-- 将score3修改为外部表
ALTER table score3 set TBLPROPERTIES("EXTERNAL"="TRUE");
-- 将score3表的注释修改为this is table comment
ALTER table score3 set TBLPROPERTIES("comment"="this is table comment");
其余属性可参见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-listTableProperties
7.2.7.3. 修改表的分区
1、添加分区
语法:
ALTER TABLE tablename ADD PARTITION (month='201101');
例如:
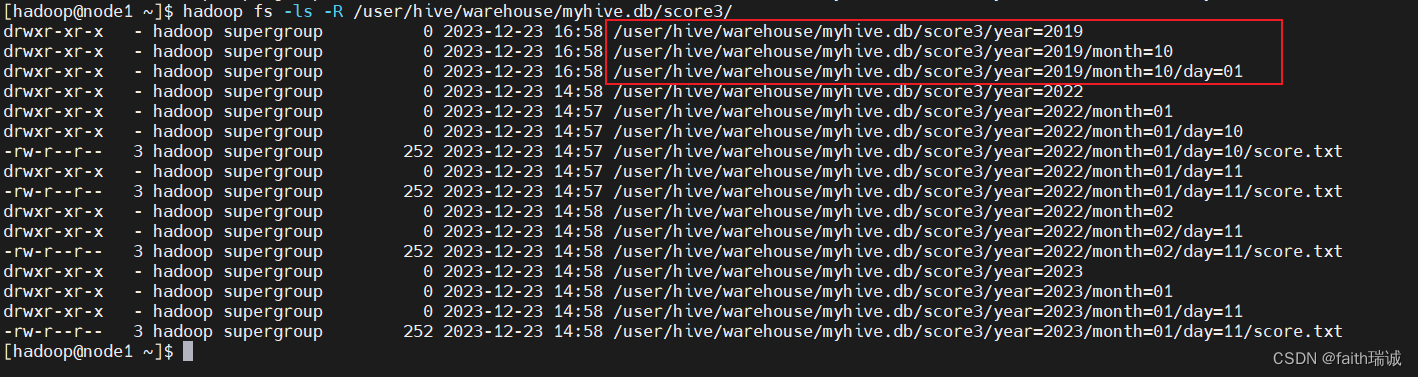
-- 给score3表添加一个year为2019,month为10,day为01的分区
ALTER table score3 add partition(year='2019', month='10', day='01');
分区添加完成之后,因为新分区内还没有数据,所以在Hive中是看不到的,但是可以在HDFS中看到对应的目录;
可以通过手动添加数据文件或者加载数据的方式导入数据;
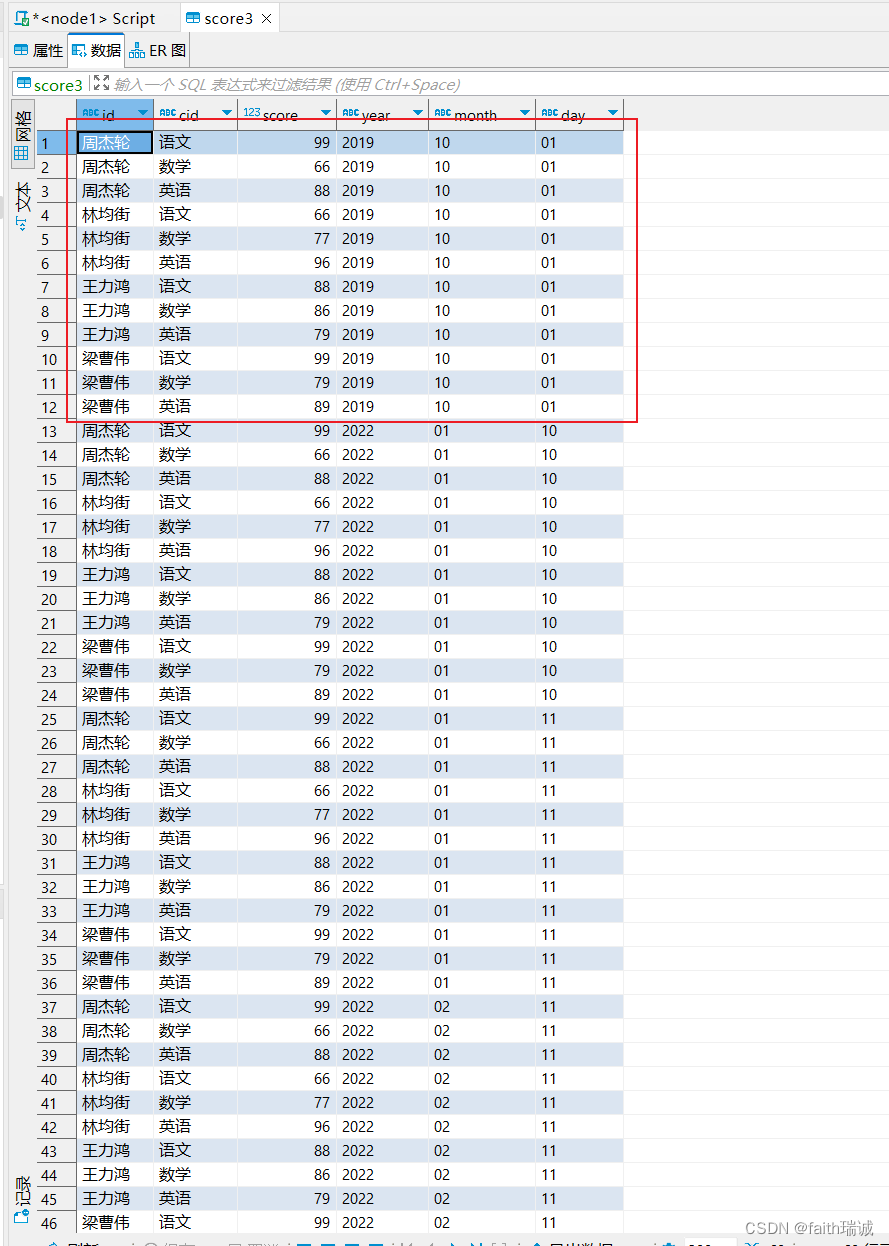
例如,将另一个分区的数据文件复制一份过来hadoop fs -cp /user/hive/warehouse/myhive.db/score3/year=2022/month=01/day=10/score.txt /user/hive/warehouse/myhive.db/score3/year=2019/month=10/day=01/,这时,在DBeaver中就可以看到新分区中出现了数据
2、修改分区值(一般不要修改)
语法:
ALTER TABLE tablename PARTITION (month='202005') RENAME TO PARTITION (month='201105');
例如:
-- 将score3表year为2019,month为10,day为01的分区修改为year为2019,month为10,day为07
ALTER table score3 partition(year='2019', month='10', day='01') rename to partition(year='2019', month='10', day='07');
这时可以查看DBeaver中的数据,发现数据已经被修改了;
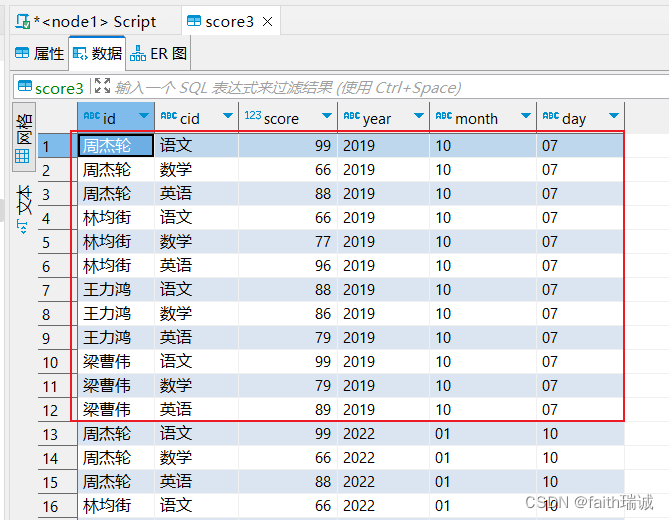
同时,查看HDFS系统中的目录结构,发现文件目录并没有修改。这时因为,修改分区值本质上是修改元数据,而HDFS系统中的文件夹不会被重命名(默认元数据中的分区值和HDFS系统中的文件夹名字是一样的,但是也可以不同)。
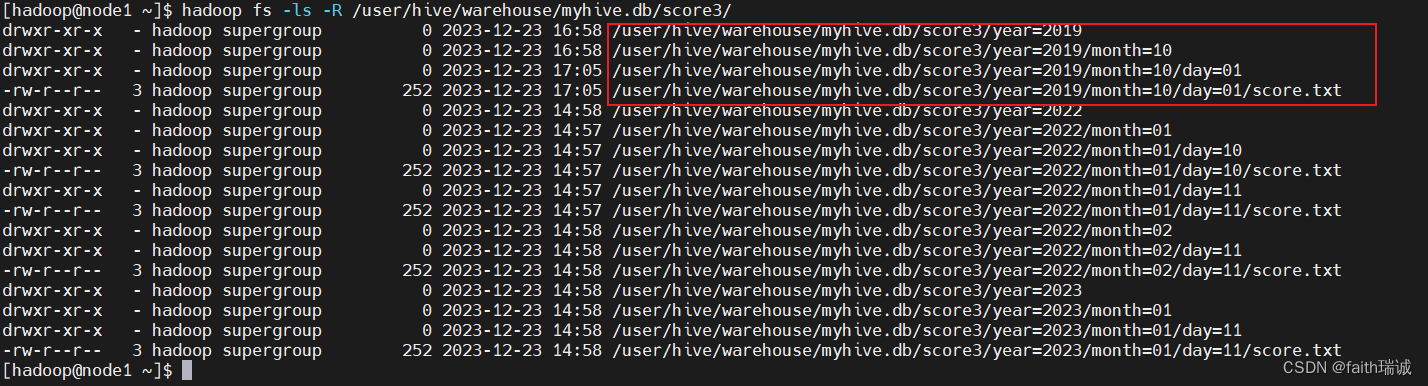
此时,可以连接元数据库(node1服务器上的MySQL数据库),进入hive库,查看PARTITIONS表的内容,会发现分区名字已经变为了year=2019/month=10/day=07,其SD_ID为14,其TBL_ID为5,对应的字典为score3(表名);
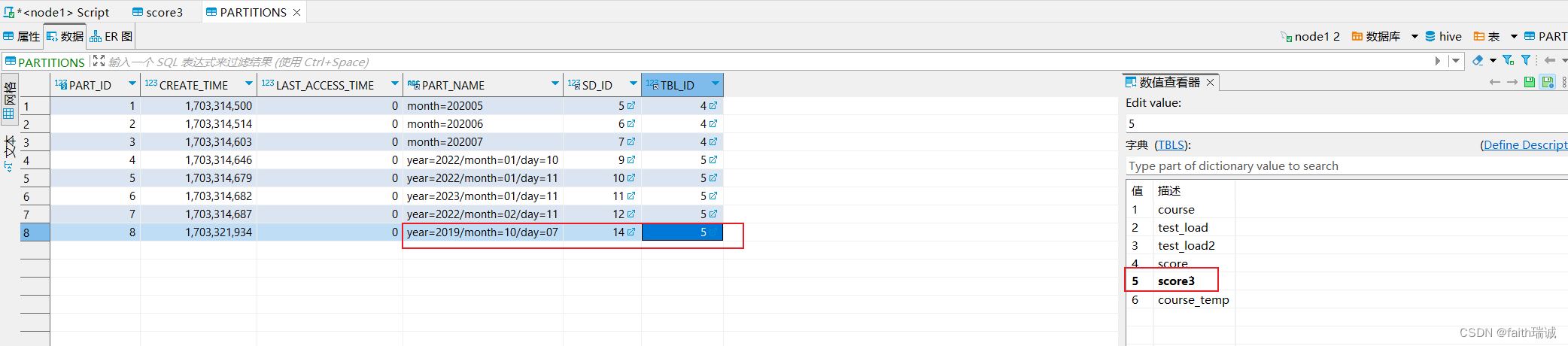
然后再查看SDS表中的数据,会发现SD_ID为14的数据,其对应的LOCATION的值为hdfs://node1:8020/user/hive/warehouse/myhive.db/score3/year=2019/month=10/day=01,通过这两个表实现了分区和HDFS系统中文件夹的对应,同时,也可以看到分区值已经变更了,但是HDFS中的物理存储路径没有变化。
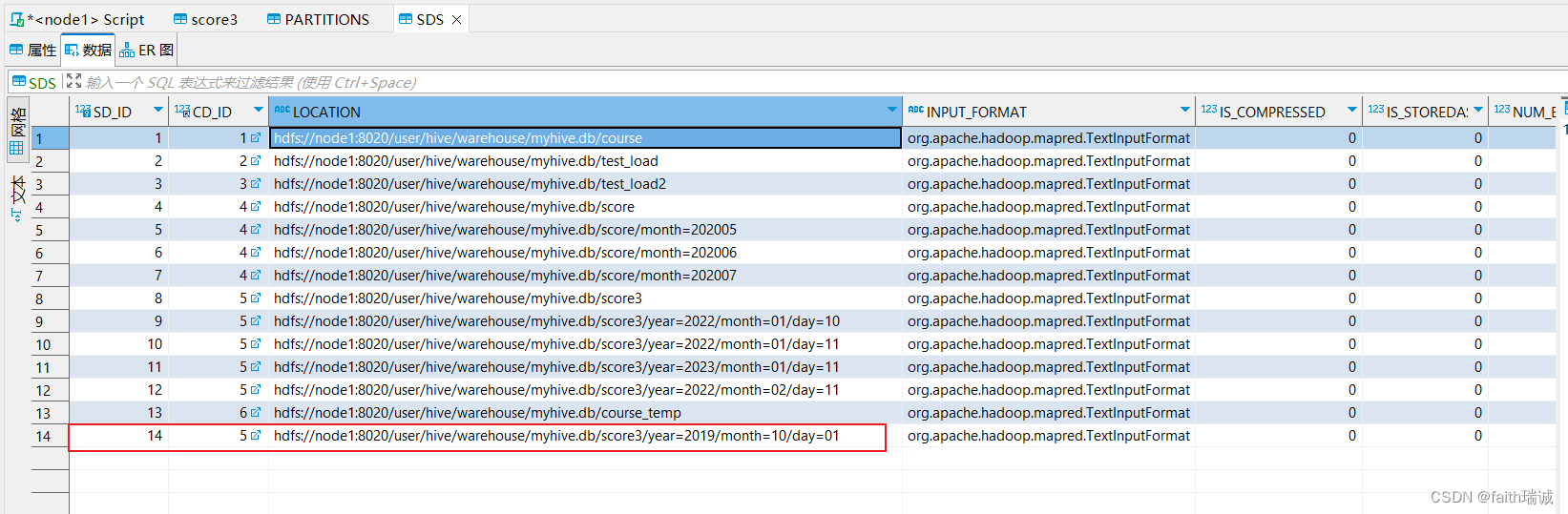
当然,也可以先手动修改HDFS系统中对应路径的文件夹名,然后再来SDS表中修改LOCATION的值到新的路径,就可以实现分区值和HDFS路径一样了。
3、删除分区
语法:
ALTER TABLE tablename DROP PARTITION (month='201105');
例如:
-- 删除score3表中year为2019,month为10,day为07的分区
ALTER table score3 drop partition(year='2019', month='10', day='07');
删除分区后,Hive表中对应分区的数据也会被删除,但是HDFS系统中的相关文件夹和数据文件不会被删除。
这时因为删除分区只是删除了元数据,数据本身还在。
7.2.7.4. 修改表的列
1、添加列
语法:
ALTER TABLE table_name ADD COLUMNS (col_name col_type, col_name col_type, ...);
例如:
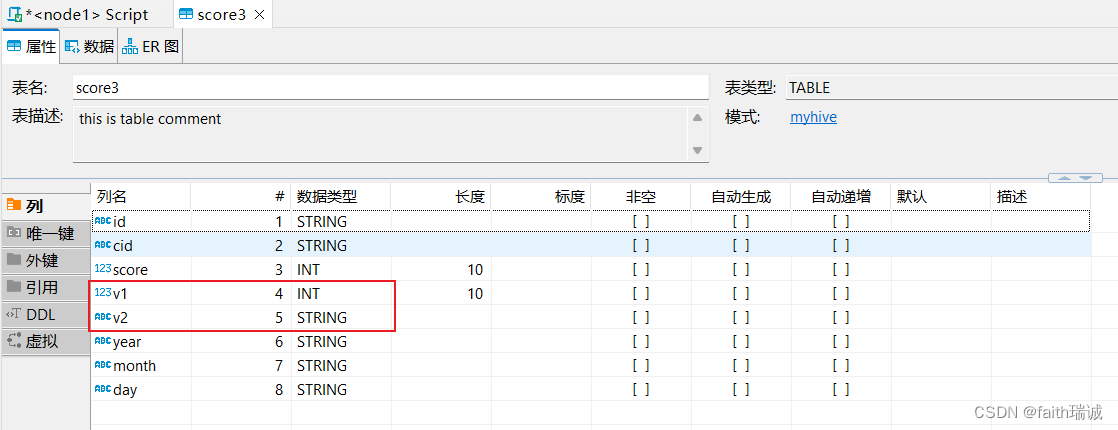
-- 给score3增加v1,v2两列,分别是int型和string型
ALTER table score3 add columns (v1 int, v2 string);
可以看到执行后score3表增加了两个列
2、修改列名
语法:
ALTER TABLE table_name CHANGE old_col_name new_col_name old_col_type;
例如:
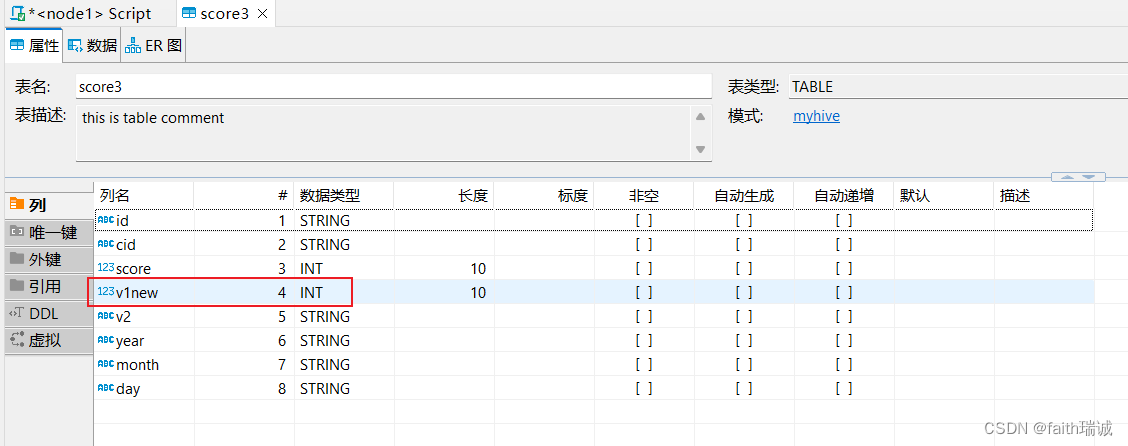
-- 将score3表中的v1列改为v1new列,int型(尽量不要修改类型,有可能会报错)
ALTER table score3 change v1 v1new int;
此时,查看score3表的结构,发现v1列已经改名为v1new列。
7.2.7.5. 删除表
语法:
DROP TABLE tablename;
例如:
-- 删除myhive库下的score3表
DROP table myhive.score3;
7.2.7.6. 清空表的数据
语法:
TRUNCATE TABLE tablename;
例如:
-- 清空course表内的数据
TRUNCATE table course;
尝试清空外部表:
-- 将test_load2表改成外部表
ALTER table test_load2 set TBLPROPERTIES("EXTERNAL"="TRUE");
-- 清空test_load2表内的数据
TRUNCATE table test_load2;
此时,会发现系统会报错。所以外部表无法被Hive清空。
SQL 错误 [10146] [42000]: Error while compiling statement: FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table test_load2.
7.2.8. 复杂类型操作
Hive支持的数据类型很多,除了基本的:int、string、varchar、timestamp等,还有一些复杂的数据类型,如:array(数组类型)、map(映射类型)、struct(结构类型)等。
7.2.8.1. array(数组类型)
Hive中的array类型与Java中的List非常相似,在定义Hive表结构是指定字段为array类型,同时,还需指定array内的元素的类型。
创建数据表:
CREATE table myhive.test_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
COLLECTION ITEMS TERMINATED BY ',';
array<string>,表示work_locations字段的类型为array数组类型,数据内的元素为string型;
row format delimited fields terminated by ‘\t’, 表示数据分隔符是制表符\t;
COLLECTION ITEMS TERMINATED BY ‘,’, 表示集合(array)内元素的分隔符是英文逗号(,);
加载数据:
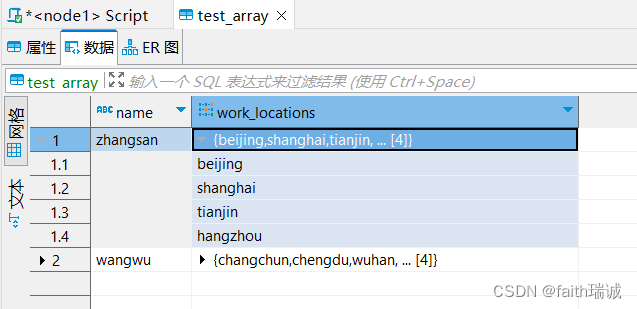
将课程资料中的data_for_array_type.txt放到Linux系统/home/hadoop目录下,然后执行以下SQL:
load data local inpath '/home/hadoop/data_for_array_type.txt' into table test_array;
加载完成后,可以在Hive表中看到对应的数据
查询数据:
-- 查询所有数据
SELECT * from test_array;
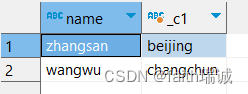
-- 查询每个人工作的第一个城市
SELECT name, work_locations[0] from test_array;
-- 查询array类型中的元素个数
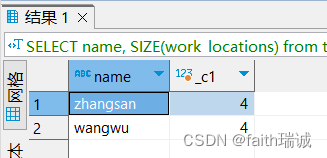
SELECT name, SIZE(work_locations) from test_array;
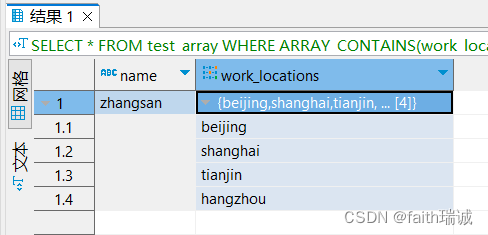
-- 找出在tianjin工作过的人SELECT * FROM test_array WHERE ARRAY_CONTAINS(work_locations, 'tianjin');
7.2.8.2. map(Key-Value型)
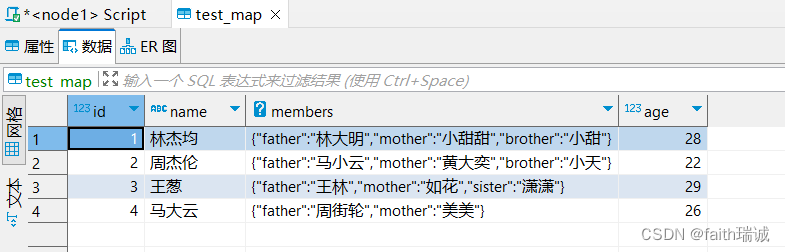
map类型其实就是简单的指代:Key-Value型数据格式。 有如下数据文件,其中members字段是key-value型数据。字段与字段分隔符: “,”;需要map字段之间的分隔符:“#”;map内部k-v分隔符:“:”。
id,name,members,age
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
创建数据表
CREATE table myhive.test_map(id int,name string,members map<string, string>,age int
) row format delimited fields terminated by ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';
map<string, string>,指定members字段的类型为键为string型,值为string型的键值对;
row format delimited fields terminated by ‘,’,指定数据列之间的分隔符为英文逗号(,);
COLLECTION ITEMS TERMINATED BY ‘#’,指定每个键值对之间的分隔符为#号;
MAP KEYS TERMINATED BY ‘:’,指定MAP键和值之间的分隔符为英文冒号(:)。
加载数据
将课程资料中的data_for_map_type.txt放到Linux系统/home/hadoop目录下,然后执行以下SQL:
load data local inpath '/home/hadoop/data_for_map_type.txt' into table test_map;
加载前,可以通过cat data_for_map_type.txt命令查看文件内容如下:

加载完成后,打开test_map表查看数据:
数据查询
-- 查看每行数据members字段中的father和monther元素
SELECT id, name, members['father'], members['mother'] FROM myhive.test_map;

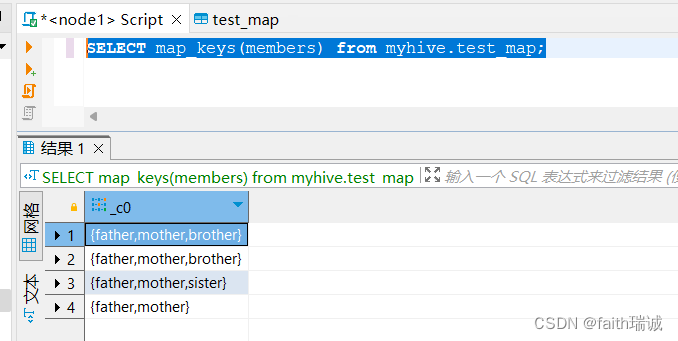
-- 取出map的全部key,map_keys函数返回的类型是array
SELECT map_keys(members) from myhive.test_map;
-- 取出map的全部value,map_values函数返回的类型是array
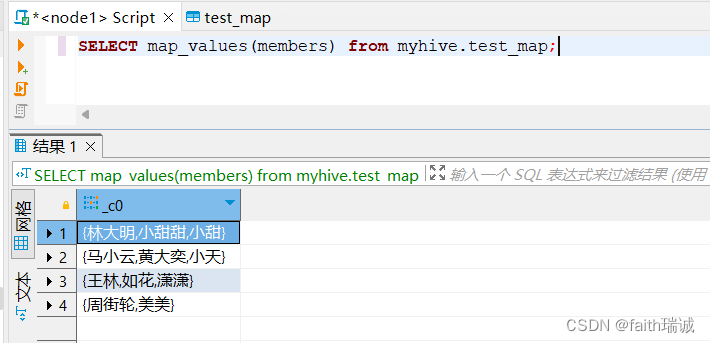
SELECT map_values(members) from myhive.test_map;
-- 查看map的个数,size函数
SELECT id, name, members, SIZE(members), age from myhive.test_map;

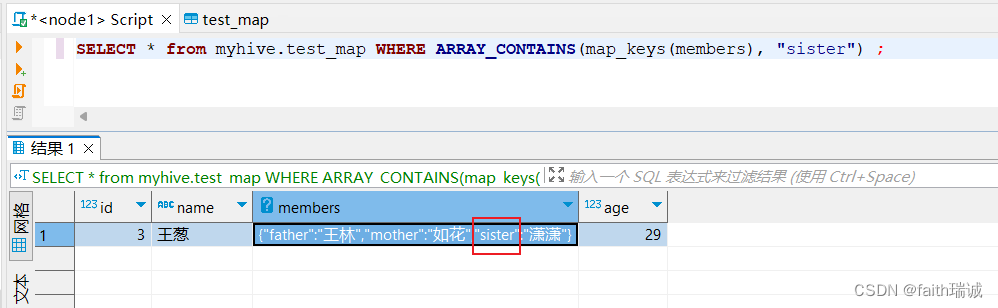
-- 查看指定的数据是否包含在map中,array_contains函数,查看谁有sister这个key
SELECT * from myhive.test_map WHERE ARRAY_CONTAINS(map_keys(members), "sister") ;
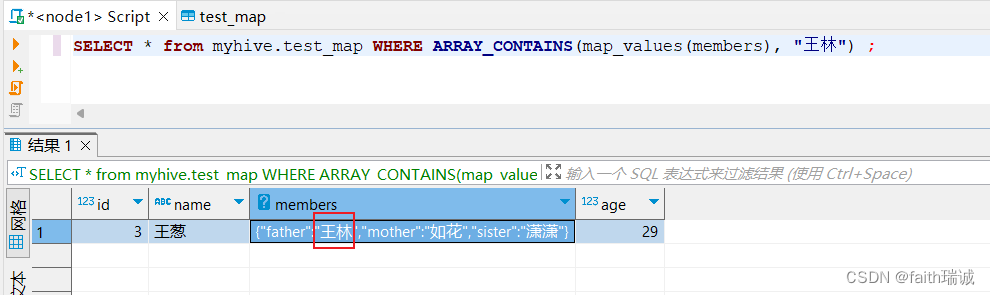
-- 查看指定的数据是否包含在map中,array_contains函数,查看谁有“王林”这个value
SELECT * from myhive.test_map WHERE ARRAY_CONTAINS(map_values(members), "王林") ;
7.2.8.3. struct(复合类型)
struct类型是一个复合类型,可以在一个列中存入多个子列,每个子列允许设置类型和名称。有如下数据文件,字段之间#分割,struct之间冒号分割。
1#周杰轮:11
2#林均杰:16
3#刘德滑:21
4#张学油:26
5#蔡依临:23
创建数据表
CREATE table myhive.test_struct(id string,info struct<name:string, age:int>
) row format delimited fields terminated by '#'
COLLECTION ITEMS TERMINATED BY ':';
info struct<name:string, age:int>,指定info列为stuct型,其内部又分为两个子列,分别是name(string型)和age(int型);
row format delimited fields terminated by ‘#’,指定表的每一列的数据分隔符为#号;
COLLECTION ITEMS TERMINATED BY ‘:’,指定struct型内,每个子列的数据分隔符为英文冒号(:)。
加载数据
将课程资料中的data_for_struct_type.txt放到Linux系统/home/hadoop目录下,然后执行以下SQL:
load data local inpath '/home/hadoop/data_for_struct_type.txt' into table test_struct;
加载前,可以通过vim data_for_map_type.txt命令查看文件内容如下:

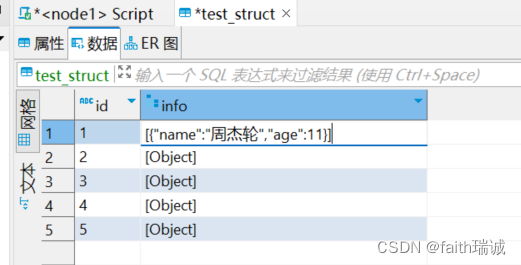
加载完成后,打开test_struct表查看数据:
数据查询
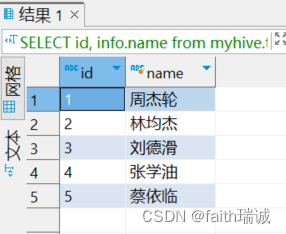
-- 查询id和对应info中的name的值
SELECT id, info.name from myhive.test_struct;
7.2.8.4. array、map、struct总结
| 类型 | 定义 | 示例 | 内含元素类型 | 元素个数 | 取元素 | 可用函数 |
|---|---|---|---|---|---|---|
| array | array<类型> | 如定义为:array<int> 数据为:1,2,3,4,5 | 单值,类型取决于定义 | 动态,不限制 | array[下标索引] 索引从0开始 | size()统计元素个数 array_contains()判断是否包含指定数据 |
| map | map<key类型, value类型> | 如定义为:map<string, int> 数据为:{‘a’:1, ‘b’:2, ‘c’:3} | 键值对,K-V,K和V类型取决于定义 | 动态,不限制 | map[key]取出对应key的value | size()统计元素个数 map_keys()取出全部key,返回array map_values()取出全部value,返回array array_contains()判断是否包含指定数据,须与map_keys()或map_values()配合使用,在where子句中做搜索条件 |
| struct | struct<子列名1 子列类型1, 子列名2 子列类型2, …> | 如定义为:struct<c1 string, c2 int, c3 date> 数据为:‘a’, 1, ‘2023-01-01’ | 单值,类型取决于定义 | 固定,取决于定义的子列数量 | struct.子列名 通过子列名取出子列的值 | 暂无 |
7.3. 数据查询
准备数据
将课程资料中的itheima_orders.txt和itheima_users.txt放到Linux系统/home/hadoop目录下,然后执行以下SQL:
-- 创建新的库
CREATE database itheima;
-- 选择itheima库
use itheima;
-- 创建订单表
CREATE TABLE itheima.orders (orderId bigint COMMENT '订单id',orderNo string COMMENT '订单编号',shopId bigint COMMENT '门店id',userId bigint COMMENT '用户id',orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货',goodsMoney double COMMENT '商品金额',deliverMoney double COMMENT '运费',totalMoney double COMMENT '订单金额(包括运费)',realTotalMoney double COMMENT '实际订单金额(折扣后金额)',payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他',isPay tinyint COMMENT '是否支付 0:未支付 1:已支付',userName string COMMENT '收件人姓名',userAddress string COMMENT '收件人地址',userPhone string COMMENT '收件人电话',createTime timestamp COMMENT '下单时间',payTime timestamp COMMENT '支付时间',totalPayFee int COMMENT '总支付金额'
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 加载数据到orders表中
load data local inpath '/home/hadoop/itheima_orders.txt' into table itheima.orders;
-- 创建用户表
CREATE TABLE itheima.users (userId int,loginName string,loginSecret int,loginPwd string,userSex tinyint,userName string,trueName string,brithday date,userPhoto string,userQQ string,userPhone string,userScore int,userTotalScore int,userFrom tinyint,userMoney double,lockMoney double,createTime timestamp,payPwd string,rechargeMoney double
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 加载数据到users表中
load data local inpath '/home/hadoop/itheima_users.txt' into table itheima.users;
7.3.1. 基本查询
Hive中使用基本查询SELECT、WHERE、GROUP BY、聚合函数、HAVING、JOIN和普通的SQL语句没有区别。
查询语句的基本语法:
SELECT [ALL | DISTINCT]select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BYcol_list]
[HAVING where_condition]
[ORDER BYcol_list]
[CLUSTER BYcol_list| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
整体上和普通SQL差不多,部分有区别,如:CLUSTER BY、DISTRIBUTE BY、SORT BY等。
SELECT基础查询
-- 查询全表数据
SELECT * FROM itheima.orders;-- 查询单列信息
SELECT orderid, userid, totalmoney FROM itheima.orders;-- 查询表中总共有多少条数据(会转成MapReduce任务执行)
SELECT count(*) FROM itheima.orders;-- 查询表中广东省的订单
SELECT * FROM itheima.orders o WHERE o.useraddress LIKE '广东%';-- 找出广东省单笔金额最大的订单(会转成MapReduce任务执行)
SELECT * FROM itheima.orders o WHERE o.useraddress LIKE '广东%' ORDER BY o.totalmoney DESC LIMIT 1;
分组、聚合查询
-- 统计未支付、已支付各自的人数(会转成MapReduce任务执行)
SELECT ispay, COUNT(*) FROM itheima.orders GROUP BY ispay;-- 在已付款的订单中,统计每个用户最高额度一笔消费金额(会转成MapReduce任务执行)
SELECT userid, MAX(totalmoney) FROM itheima.orders WHERE ispay = 1 GROUP BY userid;-- 统计每个用户的平均订单消费额(会转成MapReduce任务执行)
SELECT userid, AVG(totalmoney) FROM itheima.orders GROUP BY userid; -- 统计每个用户的平均订单消费额,并过滤大于10000的数据(会转成MapReduce任务执行)
SELECT userid, AVG(totalmoney) as avg_totalmoney FROM itheima.orders GROUP BY userid HAVING avg_totalmoney > 10000;
JOIN查询
-- JOIN(内关联)订单表和用户表,找出用户名
SELECT o.orderid, o.userid, u.username FROM orders o JOIN users u ON u.userid = o.userid;-- 左外关联,订单表和用户表,找出用户名
SELECT o.orderid, o.userid, u.username FROM orders o LEFT JOIN users u ON u.userid = o.userid;
7.3.2. RLIKE 正则匹配
Hive中提供RLIKE关键字,可以供用户使用正则和数据进行匹配。
RLIKE匹配
-- 查找广东省的数据
SELECT * FROM itheima.orders o WHERE o.useraddress RLIKE '.*广东.*';-- 查找用户地址是:XX省 XX市 XX区的数据
SELECT * FROM itheima.orders o WHERE o.useraddress RLIKE '..省 ..市 ..区';-- 查找用户姓为张、王、邓的数据
SELECT * FROM itheima.orders o WHERE o.username RLIKE '[张王邓].+';
SELECT * FROM itheima.orders o WHERE o.username RLIKE '[张王邓]\\S+';-- 查找手机号复合:188****0***规则的订单
SELECT * FROM itheima.orders o WHERE o.userphone RLIKE '188.{4}0.{3}';
SELECT * FROM itheima.orders o WHERE o.userphone RLIKE '188\\S{4}0[0-9]{3}';
7.3.3. UNION联合
UNION 用于将多个 SELECT 语句的结果组合成单个结果集。但每个 select 语句返回的列的数量和名称必须相同。否则,将引发架构错误。
语法:
SELECT ...UNION [ALL]
SELECT ...
[ALL],表示不对结果中完全一样的数据去重。
准备数据:
将课程资料中的course.txt放到Linux系统/home/hadoop目录下,然后执行以下SQL:
-- 创建数据表
CREATE TABLE itheima.course(c_id string, c_name string, t_id string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 加载数据
load data local inpath '/home/hadoop/course.txt' into table itheima.course;
union语句
-- 基础UNION语句
SELECT * FROM itheima.course c WHERE c.t_id="周杰轮"UNION
SELECT * FROM itheima.course c2 WHERE c2.t_id="林均街";-- 去重演示
SELECT * FROM itheima.courseUNION
SELECT * FROM itheima.course;-- 不去重
SELECT * FROM itheima.courseUNION ALL
SELECT * FROM itheima.course;-- UNION写在FROM,UNION写在子查询中
SELECT t_id, COUNT(*) FROM
(SELECT * FROM itheima.course c WHERE c.t_id="周杰轮"UNION ALLSELECT * FROM itheima.course c2 WHERE c2.t_id="王力鸿"
) AS u GROUP BY t_id;-- 用于INSERT SELECT
CREATE TABLE itheima.course2(c_id string, c_name string, t_id string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';INSERT OVERWRITE TABLE itheima.course2
SELECT * FROM itheima.course UNION
SELECT * FROM itheima.course;
7.3.4. Sampling采样
1、为什么需要抽样表数据
大数据体系下,在真正的企业环境中,很容易出现很大的表,比如体积达到TB级别。对这种表一个简单的SELECT * 都会非常的慢,哪怕LIMIT 10想要看10条数据,也会走MapReduce流程,这个时间等待是不合适的。
Hive提供的快速抽样的语法,可以快速从大表中随机抽取一些数据供用户查看。使用TABLESAMPLE函数实现。
2、随机分桶抽样
语法:
SELECT ... FROM tbl TABLESAMPLE(BUCKET x OUT OF y ON(colname | rand()))
- tbl,表示抽取数据的表名;
- y,表示将tbl表中的数据划分成y份(即y个桶);
- x,表示从y份数据中取第x份数据作为取样样本;
- colname,表示依据基于某个列(这里写的是列名)的值的hash取模结果分桶,只能是非分区列;
- rand(),表示随机的基于基于整行,也就是完全随机了。
本节以之前创建并导入数据的itheima库,orders表为抽样的数据表。
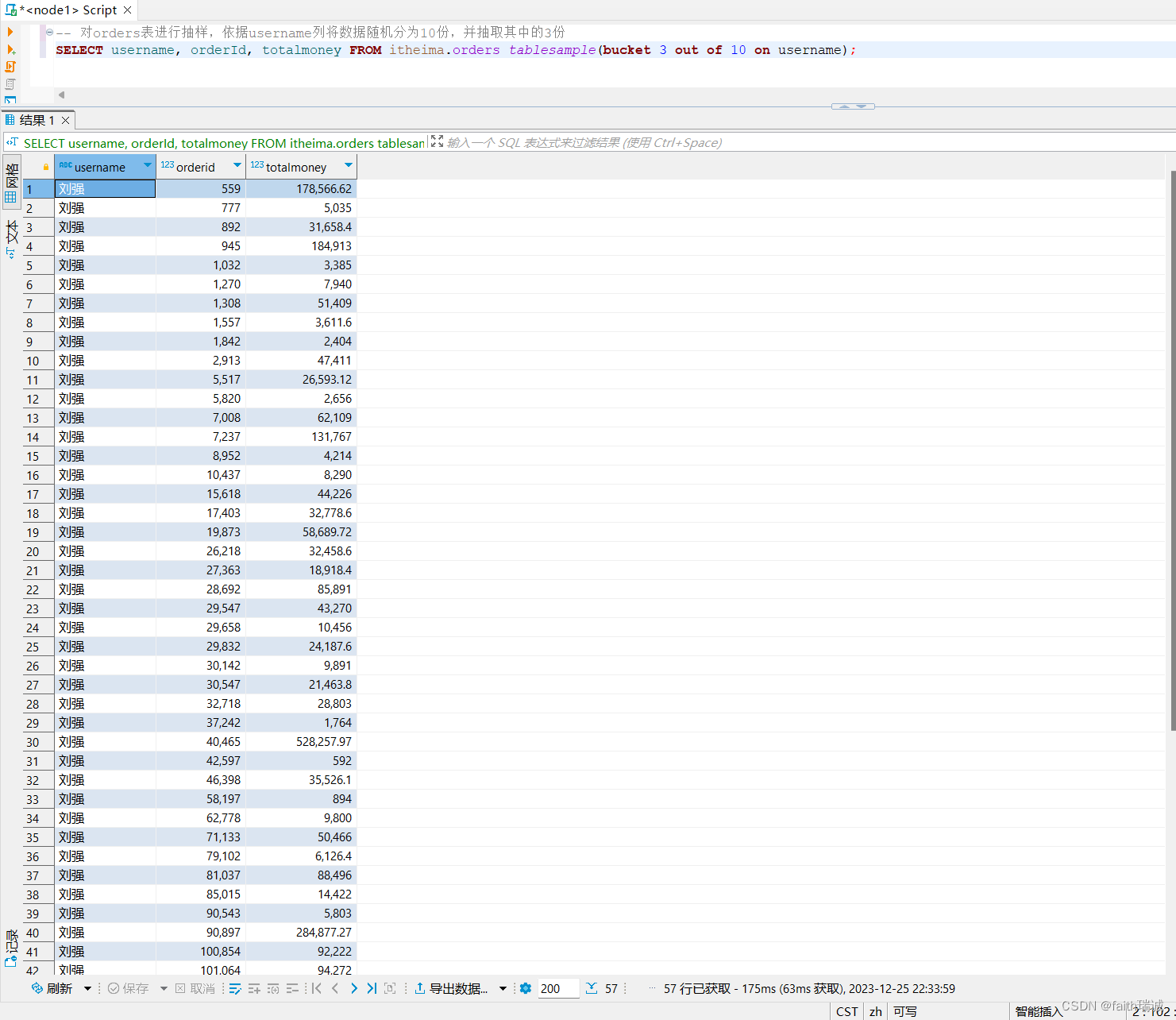
-- 对orders表进行抽样,依据username列将数据随机分为10份,并抽取其中的第3份
SELECT username, orderId, totalmoney FROM itheima.orders tablesample(bucket 3 out of 10 on username);
基于列抽样,会发现运行多次,抽样的结果都是固定的。因为基于列的值进行hash取模分桶的结果是固定的!
若一个表本身就是分桶表的话,使用基于列的抽样,基于分桶列进行抽样,随机的份数与表的分桶数保持一致,效率会非常高。
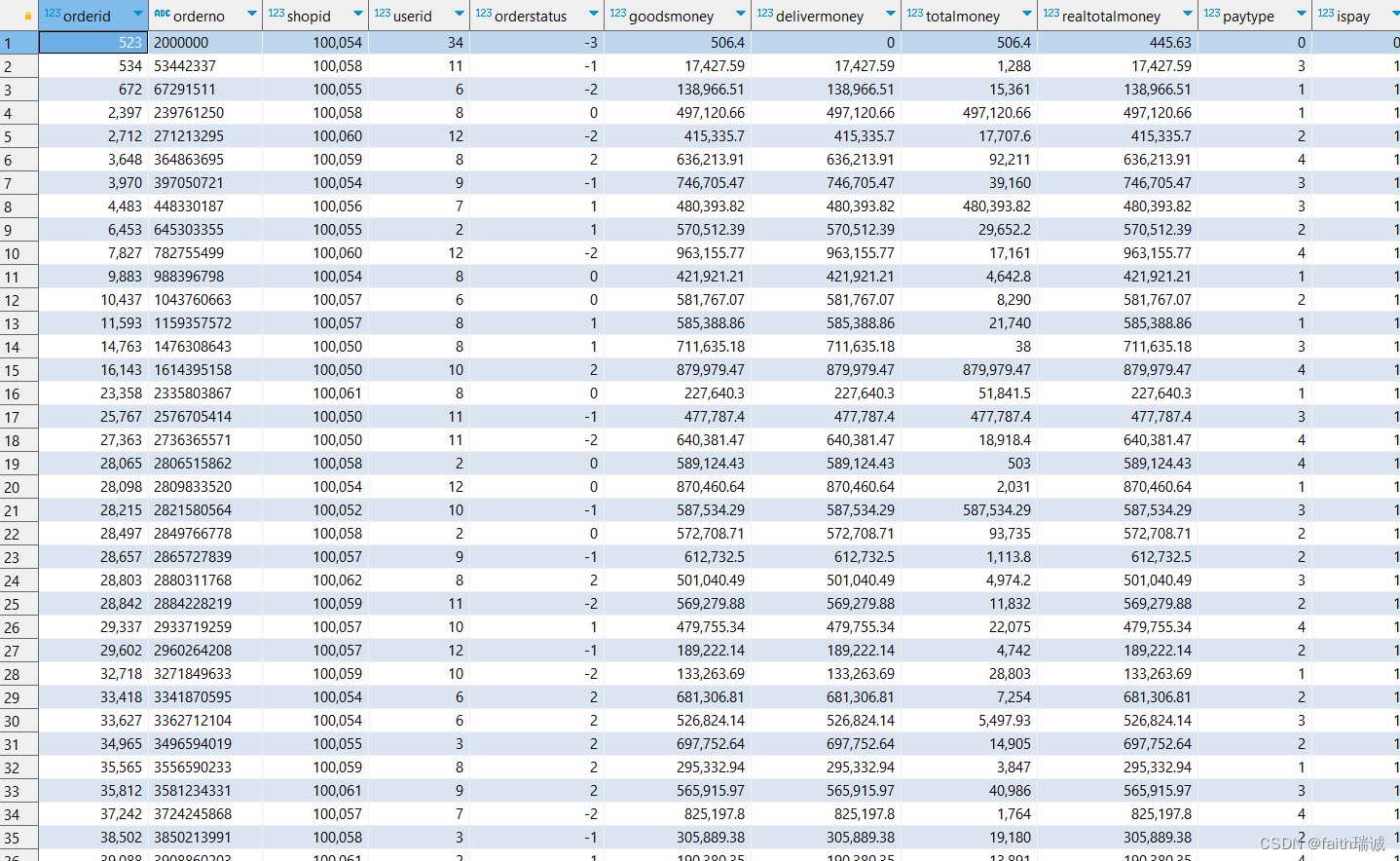
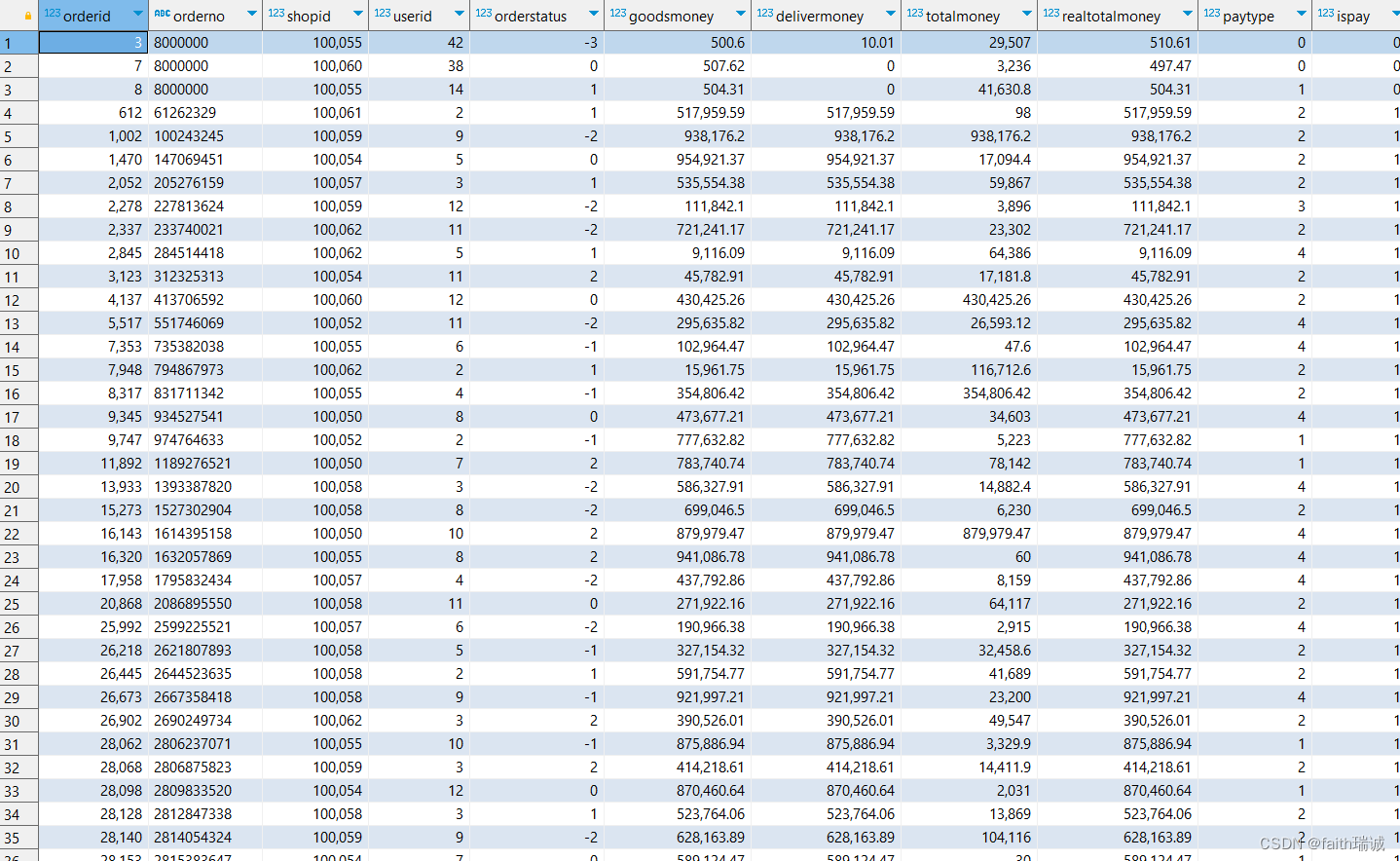
-- 对orders表进行抽样,完全随机将数据分为10份,并抽取其中的第3份
SELECT * FROM itheima.orders tablesample(bucket 3 out of 10 on rand());
基于rand()随机抽样,会发现,每次运行的结果都是不一样的。
3、 基于数据块抽样
语法:
SELECT ... FROM tbl TABLESAMPLE(num ROWS | num PERCENT | num(K|M|G));
- tbl,表示抽取数据的表名;
- num ROWS,表示总共抽取num条数据;
- num PERCENT,表示抽取百分之num比例的数据(不是数据条数的百分比,而是数据大小的百分比);
- num(K|M|G),表示抽取num大小的数据,单位可以是K、M、G分别代表KB、MB、GB。
注意:
使用这种语法抽样,条件不变的话,每一次抽样的结果都一致。即无法做到随机,只是按照数据顺序从前到后取数据。
例如:
-- 抽取前100条数据
SELECT * FROM itheima.orders tablesample(100 rows);-- 抽取前10%的数据
SELECT * FROM itheima.orders tablesample(1 percent);-- 抽取前1KB的数据
SELECT * FROM itheima.orders tablesample(1K);
7.3.5. Virtual Columns虚拟列
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。
Hive目前可用3个虚拟列:
- INPUT__FILE__NAME:显示数据行所在的具体文件;
- BLOCK__OFFSET__INSIDE__FILE:显示数据行所在文件的偏移量;
- ROW__OFFSET__INSIDE__BLOCK:显示数据所在的HDFS块的偏移量;
- 此虚拟列需要设置:
SET hive.exec.rowoffset=true才能使用。
- 此虚拟列需要设置:
本节使用itheima库中的orders表进行演示。
-- 开启ROW__OFFSET__INSIDE__BLOCK虚拟列
SET hive.exec.rowoffset=true
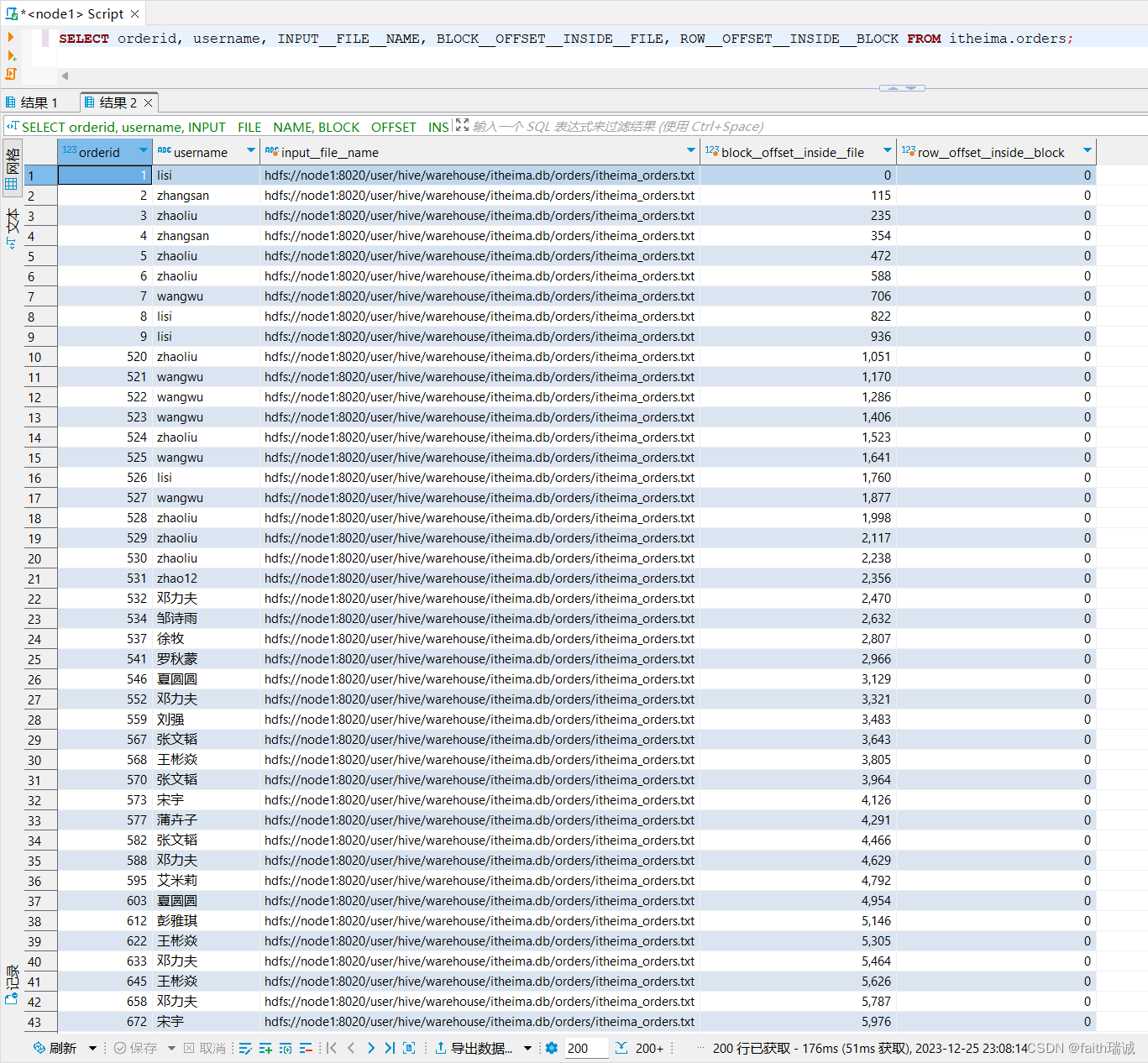
-- 查询orders表中每行数据所处的文件、数据行文件偏移量和数据块偏移量
SELECT orderid, username, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM itheima.orders;
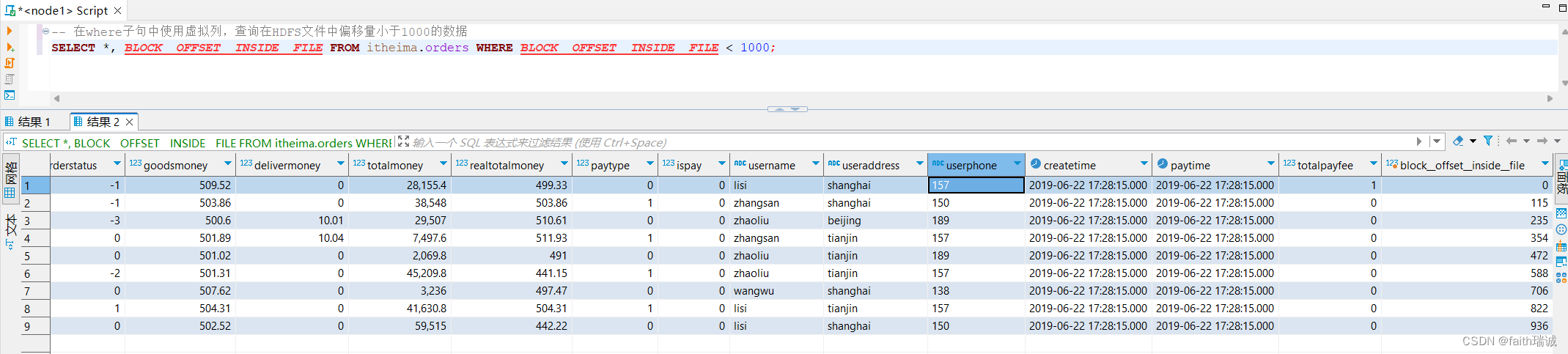
-- 在where子句中使用虚拟列,查询在HDFS文件中偏移量小于1000的数据
SELECT *, BLOCK__OFFSET__INSIDE__FILE FROM itheima.orders WHERE BLOCK__OFFSET__INSIDE__FILE < 1000;
-- 开启分桶的自动优化功能
set hive.enforce.bucketing = TRUE;-- 构建一个基于orders的分桶表,基于orderId字段的值,分10个桶
CREATE TABLE itheima.orders_bucket (orderId bigint COMMENT '订单id',orderNo string COMMENT '订单编号',shopId bigint COMMENT '门店id',userId bigint COMMENT '用户id',orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货',goodsMoney double COMMENT '商品金额',deliverMoney double COMMENT '运费',totalMoney double COMMENT '订单金额(包括运费)',realTotalMoney double COMMENT '实际订单金额(折扣后金额)',payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他',isPay tinyint COMMENT '是否支付 0:未支付 1:已支付',userName string COMMENT '收件人姓名',userAddress string COMMENT '收件人地址',userPhone string COMMENT '收件人电话',createTime timestamp COMMENT '下单时间',payTime timestamp COMMENT '支付时间',totalPayFee int COMMENT '总支付金额'
) CLUSTERED BY (orderId) INTO 10 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';-- 从oredrs表中向分桶表加载数据
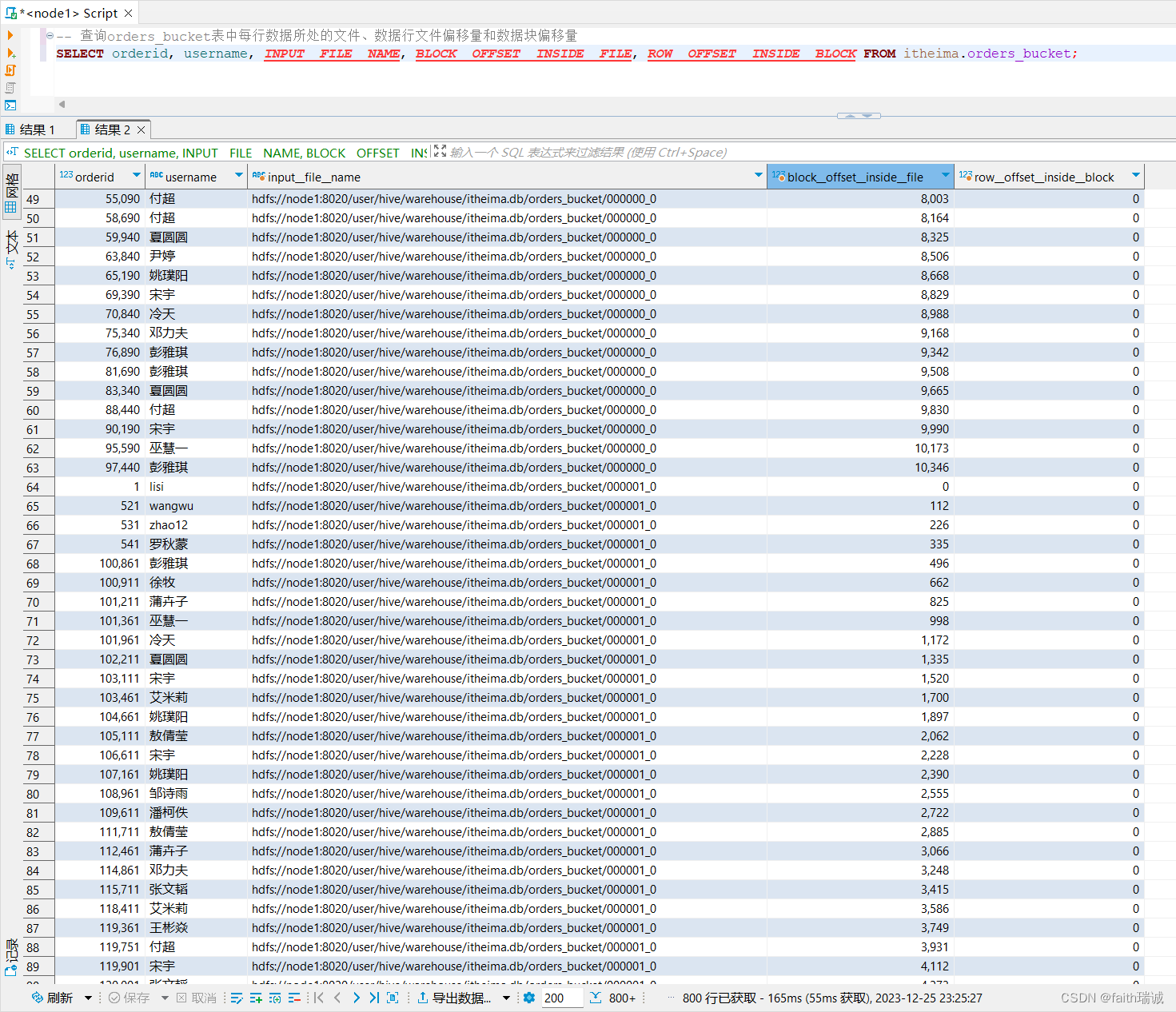
INSERT overwrite table itheima.orders_bucket SELECT * FROM itheima.orders cluster by(orderId);-- 查询orders_bucket表中每行数据所处的文件、数据行文件偏移量和数据块偏移量
SELECT orderid, username, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM itheima.orders_bucket;-- 统计每个桶文件中各自存放了多少条数据(在GROUP BY子句中使用虚拟列)
SELECT INPUT__FILE__NAME, COUNT(*) FROM itheima.orders_bucket GROUP BY INPUT__FILE__NAME;

7.4. 函数
Hive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数UDF(User-Defined Functions):

Hive的函数共计有上百种,这里无法一一演示,会挑选一些常用的进行演示。
详细的函数使用可以参阅:官方文档
查看Hive内建函数
-- 查看所有可用函数
show functions;-- 查看某个函数的使用方式(这里以count函数为例)
describe function extended count;
7.4.1. 数字、集合、转换、日期函数
7.4.1.1. Mathematical Functions 数学函数——部分
--取整函数:round(double a) 返回double类型的整数部分(四舍五入)
SELECT round(3.1415926);--指定精度取整函数:round(double a, int b) 返回指定小数点位数b的double类型(四舍五入)
--指定保留小数点后4位
SELECT round(3.1415926, 4);--获取1以内的随机数(完全随机数)
SELECT rand();--根据指定种子生成随机数,种子一样,生成的随机数也一样
SELECT rand(3);--求绝对值
SELECT abs(-3);--得到π的值
SELECT pi();
7.4.1.2. Collection Functions集合函数 - 全部
| 返回值类型 | 函数定义 | 函数说明 |
|---|---|---|
| int | size(Map<K,V>) | 返回map类型的元素个数 |
| int | size(Array<T>) | 返回array类型的元素个数 |
| array<K> | map_keys(Map<K,V>) | 返回map内所有的key |
| array<V> | map_values(Map<K,V>) | 返回map内所有的value |
| boolean | array_contains(Array<T>, value) | 如果array包含value,返回True |
| array<T> | sort_array(Array<T>) | 根据数组元素的自然顺序按升序对输入数组进行排序并返回 |
--求元素个数
SELECT size(work_locations) FROM test_array;
SELECT size(members) FROM test_map;--取出map的所有key
SELECT map_keys(members) FROM test_map;--取出map的所有value
SELECT map_values(members) FROM test_map;--检查array中是否包含有指定的value
SELECT * FROM test_array WHERE ARRAY_CONTAINS(work_locations, "tianjin"); --对数组进行升序排序
SELECT *, sort_array(work_locations) FROM test_array;
![ESP32入门六(读取引脚的模拟信号[2]:信号出现误差的原因)](https://img-blog.csdnimg.cn/direct/3220b52c153d446a837851615aa18033.png)