参考链接:
[1] 开源内容:https://github.com/siyuxin/AI-3rd-edition-notes
[2] Kimi Chat官网链接


正文笔记 P90
针对 大型问题。
知情搜索(informed search,也称有信息搜索):利用启发式方法,通过限定搜索的深度或宽度来缩小问题空间。用领域知识来避开可能不成功的搜索路径。
Nim 取物游戏、井字游戏、跳棋和国际象棋等博弈游戏。
3 种“永不回头看”的搜索算法,它们分别是爬山法(hill climbing)、最佳优先搜索(best-first search)和集束搜索(beam search)
- 在状态空间中,它们的路径完全由到目标的剩余距离的启发式评估值(近似值)来引导。
总是“向后看”的算法被称为分支定界算法(branch and bound algorithm)。标准的分支定界算法,可以通过剩余距离的启发式估计或只保留到任何中间节点的最佳路径,来进行增强处理。当在搜索中纳入上述两种增强策略时,就得到了著名的 A*算法。
3.1 启发式方法
启发式方法的目的是大幅度减少到达目标状态所要考虑的节点数目,它们非常适合解决那些组合复杂度(combinatorial complexity)快速增长的问题。
启发式搜索(heuristic search)
“heurisitc”(“启发式的”,发音为 hyu-RIS-tik,来自于希腊语“heuriskein”,意为“发现”)
在求解非常复杂的问题时,特别是在语音和图像识别、机器人和博弈策略问题中,启发式方法特别重要。
启发式方法是强人工智能的基础。
3.2 知情搜索
爬山法(hill climbing)
最陡爬山法(steepest-ascent hill climbing)
最佳优先搜索(best-first search)
爬山法的 3 个问题:
1、山丘问题 (局部最大值) ——> 回溯
2、平台问题 ——> 通过多次应用相同的规则,尝试到达搜索空间的新区域。
3、山脊问题 ——> 同时应用几个规则并在多个方向上进行搜索
爬山法的问题在于它是一种只看短期的贪心算法。而最陡爬山法在做出决定之前,由于比较了可能的后继节点,因此它比爬山法看得更长远一些,然而它依然存在着与爬山法一样的问题(山丘问题、平台问题和山脊问题)
——> 最佳优先搜索(best-first search): 为到达目标而考虑探索哪些节点以及探索多少个节点的智能搜索算法。
3.4 集束搜索
由于搜索树中的每一层只扩展最好的 W 个节点,如同形成一种薄的、聚焦的“光束”,如图 3.11 所示,因此这种算法被称为集束搜索(beam search)。
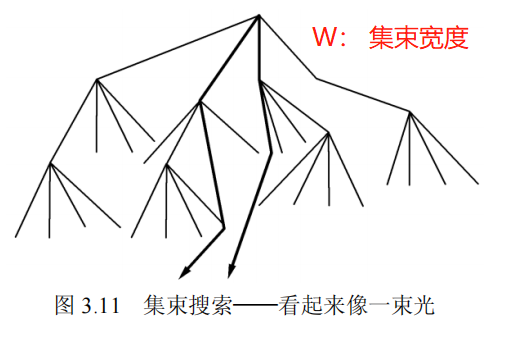
使用更大的集束可以发现更短的路径,而不会耗尽内存。
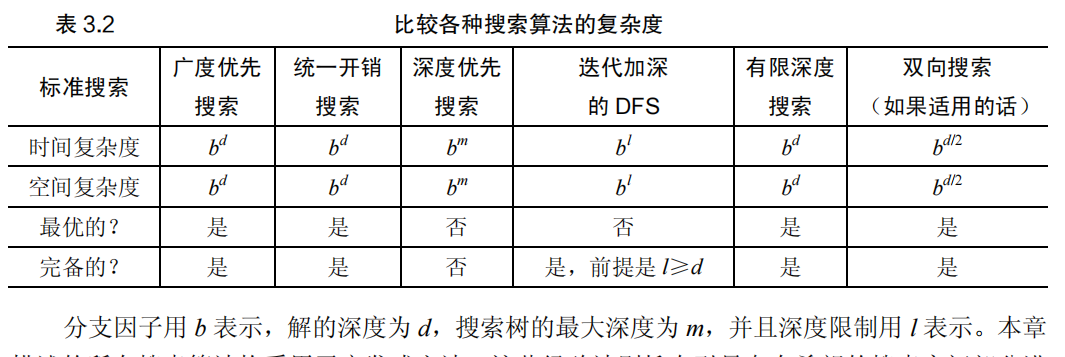
3.6 找最优解
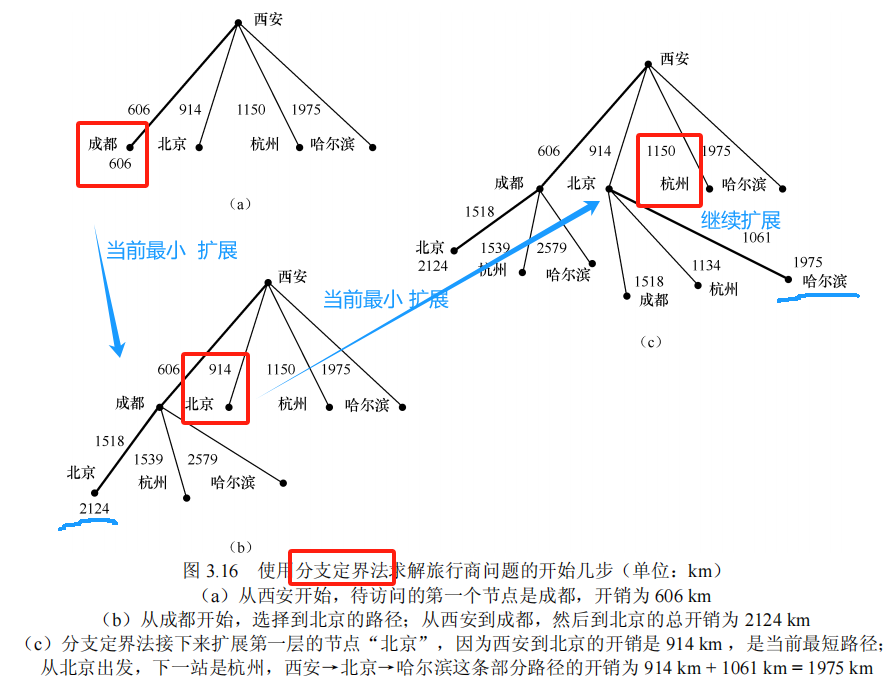
3.6.1 分支定界法
统一开销搜索 或 统一代价搜索(uniform-cost search)
- 按照递增【非递减】的开销来寻找路径。
分支定界法继续生成部分路径,直到每条路径的开销都大于或等于当前所找到的最优路径的开销为止
————————
配套资源验证码 180873
- 提供了相关问题的小游戏界面,可能有点用,其它无用


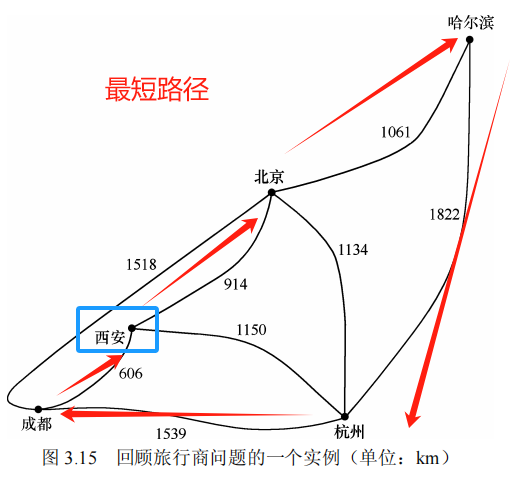
旅行商问题(Traveling Salesperson Problem,TSP,也称旅行销售员问题)是 NP 完全(NP-complete)问题的一个实例。
NP 是一类问题的缩写,如果允许猜测的话,那么这类问题可以在多项式时间内解决。P 代表的是可以在确定性多项式时间(也就是没有采用猜测时的多项式时间)内解决的一类问题。P 类问题包括了计算机科学中许多为人熟知的问题,如排序、确定图 G 是不是欧拉图等等。后面这个欧拉图确定问题可以换一种说法,即如果图 G 拥有一个环,那么这个环能遍历每条边一次且仅有一次。
NP 完全问题包含了许多著名的问题,例如上述旅行商问题、命题逻辑中的可满足性问题 和 哈密顿问题
3.6.3 采用动态规划的分支定界法
最优性原理(Principle of Optimality): 最优路径由最优子路径构建而成。
如果两条或更多的路径到达一个公共节点,那么只有到达该公共节点且具有最小开销的路径才应该被存储(删除其他路径!)。
3.6.4 A*搜索
A*搜索 : 采用了具有剩余距离估计值和动态规划的分支定界法。
问题简化
3.7.1 约束满足搜索 【是否满足约束,减少搜索范围】
在 AI 中,问题简化(problem reduction)是另一个重要方法。
- 在对更大或更复杂的问题进行求解时,可以识别出其中更小的可处理的子问题,这些子问题通过较少的步骤就可以解决。
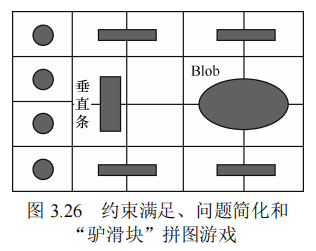
【有趣】拼图游戏: Red Donkey Puzzle
Red Donkey Puzzle 游戏界面链接
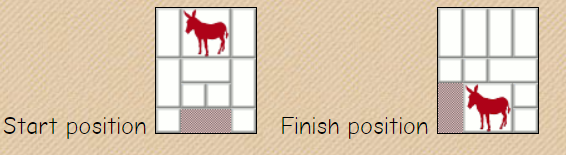
解答链接YouTube: How To Solve The Klotski Forget-Me-Not Puzzle
目标: 将右边的 Blob 移动到垂直条的左边。
1、一个相对盲目的状态空间搜索算法可能需要 800 次移动,并且还需要大量的回溯过程。
2、通过简化问题对求解问题识别出如下子目标,即必须让 Blob 在垂直条之上或之下的两行内(因此它们可以彼此通过)【约束?】。 81次 移动。
3.7.2 与或树 【可用于 问题简化】
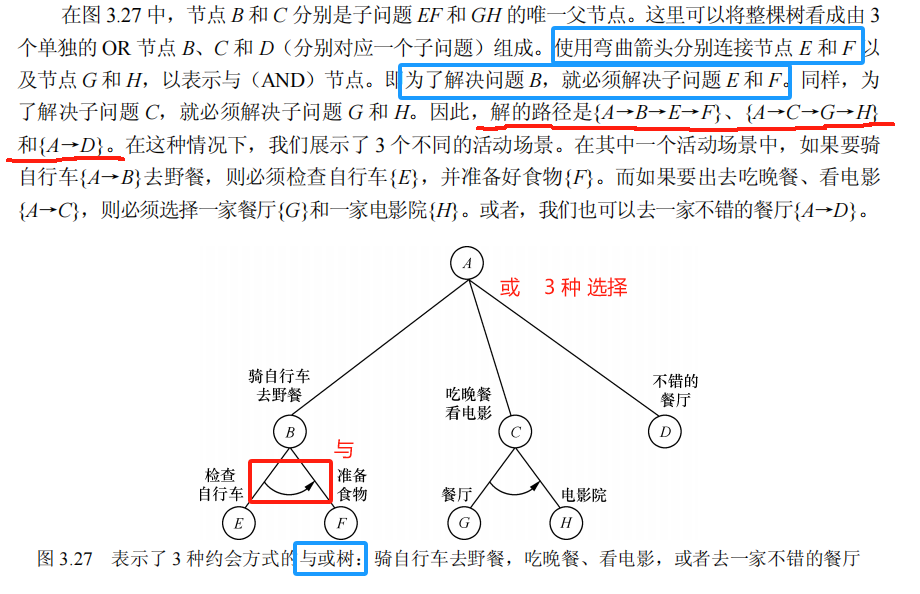
用与或树处理的典型问题包括博弈或拼图,以及其他明确定义的面向状态空间目标的问题,如机器人规划、穿越障碍物或设定机器人在平面上重新组织积木块等等。
3.7.3 双向搜索(bidirectional search)
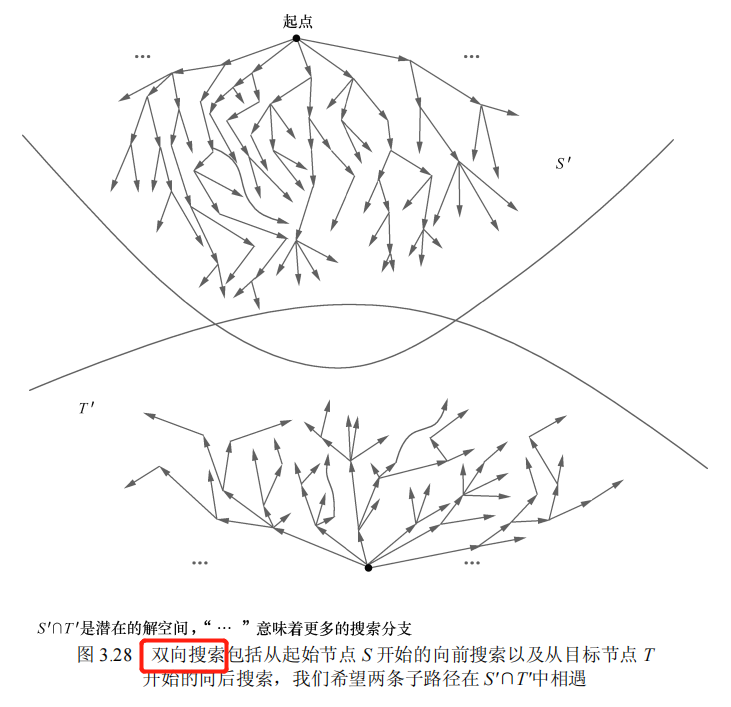
Pohl: 提出
BHPA或传统的前端到终端双向搜索
- 扩展的节点数大约仅相当于单向搜索扩展节点数的 1/4。
认为 可能存在 互相错过的问题 【导弹隐喻】: 导弹和反导弹相互瞄准,然后相互错过。——> 无根据Kwa :
双向搜索(BS*算法)
- 它克服了 BHPA 效率低下的问题
波形规整(wave-shaping)算法,其思想是使两个搜索的“波前”(wave-front)朝向彼此。

“传统的”双向搜索试图存储来自向前和向后搜索两端的节点来寻求解。传统的方法将使用最佳优先搜索,并且当两端试图“发现彼此”时,就会陷入指数级存储需求的泥潭。这就是所谓的边界问题(frontiers problem)。
非传统双向搜索的主要改进在于,从某个前向方向到边界使用周界搜索,然后存储关键信息,并从目标节点开始执行向后搜索,看看是否可以与存储的前向路径相遇。对于这种搜索而言,前端到后端的方法(与前端到前端的方法相比)更有效。
- 使用散列方案存储仅来自一端的节点。
- 仅在一个方向搜索,首先存储节点,然后在另一个方向搜索。
周界: 广度优先搜索的预定深度。
————————
3.8 本章小结
爬山法是一种原始的贪心算法,但是有时候,这种方法也能够“幸运”地找到在最陡爬山法中才能找到的最优方案。更常见的是,爬山法可能会受到 3 个常见问题的困扰:山丘问题、平台问题和山脊问题。比较智能、首选的搜索方法是最佳优先搜索,在使用该搜索方法时,需要维护开放节点队列以反馈从给定路径到解的远近程度。

分支定界法探索部分解,直到任何部分解的开销大于或等于到达目标的最短路径时才停止搜索。
A*算法通过同时采用低估计启发值和动态规划来获得最优结果。
问题简化
- 约束满足搜索
- 使用与或树 分割知识, 缩小问题空间。
讨论题 P120
1.启发式搜索方法与第 2 章讨论的搜索方法有什么区别?
(a)给出启发式搜索的 3 种定义。
(b)给出将启发式信息添加到搜索中的 3 种方式。
扩展结点的位置、后继结点生成的顺序、丢弃部分结点


2.为什么爬山法可以归类为贪心算法?
最简单形式的爬山法没有历史意识,也没有能力从错误或错误路径中恢复。它会使用某种衡量指标(不管是最大化还是最小化这种衡量指标)来引导自己到达目标并确定下一步的选择。
- 在实际应用中,爬山法可能会采用不同的策略,比如模拟退火(Simulated Annealing)或遗传算法(Genetic Algorithm),这些策略允许算法在某些情况下跳出局部最优解,以探索更广阔的搜索空间,从而有可能找到全局最优解。
3.最陡爬山法如何提供最优解?
与仅仅选择一个优于当前状态的“一步”不同,这种方法是在所有给定的可能状态集合中选择“最优”的一步(此时选择的是得分最高的一步)。
4.为什么最佳优先搜索比爬山法更有效?
最佳优先搜索最显著的优势在于可以通过回溯到开放列表中的节点,从错误、假线索、死胡同中恢复。如果要寻找其他解的话,可以重新考虑开放列表中的节点的子节点。如果按照相反的顺序追踪封闭节点列表,并忽略到达死胡同的状态,则可以用来表示所找到的最优解。
5.解释集束搜索的工作原理。
集束搜索(Beam Search)是一种启发式搜索算法,它在最佳优先搜索的基础上进行了优化,以减少搜索空间并提高搜索效率。集束搜索的核心思想是在每一步只保留一小部分最有前途的节点,而不是像最佳优先搜索那样保留所有节点。这种方法通过限制搜索宽度(即在任何给定时间点上保留的节点数量)来避免搜索树的过度膨胀。
- 集束搜索的效率和效果很大程度上依赖于启发式函数的质量以及束宽的选择。如果束宽设置得太小,可能会错过一些重要的路径;如果设置得太大,计算成本会增加。因此,集束搜索需要在搜索深度和计算资源之间找到一个平衡点。
6.启发式方法的可接受性(admissible)是什么意思?
- 启发式函数的可接受性指的是该函数总是低估(或等于)从当前状态到目标状态的实际成本。这意味着启发式函数给出的估计值永远不会比实际值大,这有助于确保搜索算法不会错过最优解。
(a)可接受性与单调性有什么关系?
单调算法总是可接受的。
单调性是可接受性的一个更强的条件。如果一个启发式函数是单调的,那么它必然是可接受的,但反之不一定成立。
(b)可以只有单调性,而不需要可接受性吗?解释原因。
可以。

7.一种启发式方法比另一种启发式方法具有更多的信息,这句话的意思是什么?
- 对于问题的具体结构、约束条件、问题空间等有更深入的理解, 并能基于这些信息提供更有效、更精确的估计。
8.分支定界法背后的思想是什么?
- 分支定界法的关键在于有效地使用启发式函数来估计界限,以及在搜索过程中进行剪枝,这样可以避免无效搜索,节省时间和计算资源。
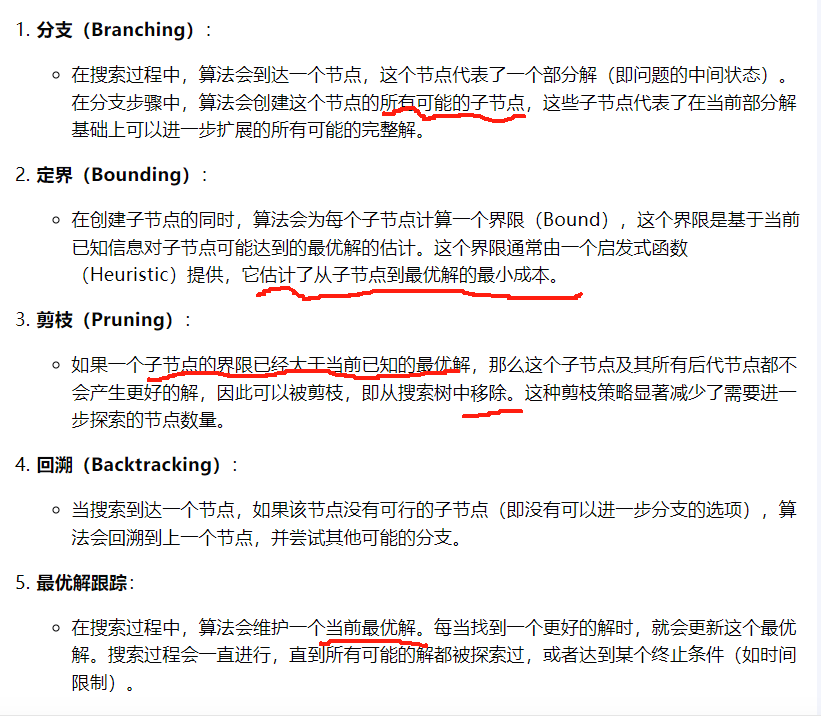
9.请解释低估可能会得到更好的解的原因。
- 低估的启发式函数倾向于引导搜索算法朝着看起来更有可能接近最优解的方向前进。这可以减少搜索过程中不必要的探索,因为算法会优先考虑那些被低估的路径,这些路径实际上可能包含更好的解。
- 在某些情况下,如果启发式函数高估了实际成本,算法可能会过早地陷入局部最优解,因为它可能会错误地认为某些路径的成本已经足够低,不值得进一步探索。而低估的启发式函数则不太可能导致这种情况,因为它总是倾向于探索更多的可能性。
10.关于动态规划:
(a)动态规划的概念是什么?
(b)描述最优性原理。
动态规划(Dynamic Programming,简称DP)的核心思想是将复杂问题分解为更小的子问题,并通过存储子问题的解(即记忆化)来避免重复计算,从而提高计算效率。
- 如果两条或更多的路径到达一个公共节点,那么只有到达该公共节点且具有最小开销的路径才应该被存储(删除其他路径!)。
- 最优性原理可以表述为:一个最优解的子结构也是最优的。换句话说,如果一个问题的最优解可以通过分解为子问题来构建,那么这些子问题的最优解也是它们各自范围内的最优解。这个原理允许我们将复杂问题分解为更小、更易于解决的子问题,并通过解决这些子问题来构建原问题的最优解。
11.为什么 A*算法比使用低估计启发值的分支定界法或使用动态规划的分支定界法更好?
A*搜索兼具两者 : 采用了具有剩余距离估计值和动态规划的分支定界法。
- 分支定界法在某些情况下可能需要更多的计算资源,尤其是在搜索空间非常大时。如果分支定界法中的启发式函数估计值不够准确,可能会导致搜索效率降低,甚至无法保证找到最优解。而动态规划虽然在解决具有最优子结构的问题时非常有效,但它通常需要对问题进行特定的分解,这在某些情况下可能不如A*算法灵活。
总的来说,A* 算法通过结合启发式搜索和优先级队列,能够在保证找到最优解的同时,显著提高搜索效率,这使得它在许多实际应用中比传统的分支定界法或动态规划方法更具优势。
12.解释约束满足搜索背后的思想,以及它是如何应用于“驴滑块”拼图问题的。
约束满足搜索(Constraint Satisfaction Problem, CSP)的核心思想是在一个有限的解空间中找到满足所有给定约束条件的解。

13.解释如何用与或树来划分搜索问题。

14.描述双向搜索的工作原理。
- 双向搜索(Bidirectional Search)是一种搜索算法,它同时从问题的初始状态和目标状态开始搜索,直到两个搜索方向在中间某个点相遇。这种方法结合了正向搜索(从初始状态向目标状态搜索)和逆向搜索(从目标状态向初始状态搜索)的优点,旨在提高搜索效率和减少搜索空间。
(a)它与本章中讨论的其他技术有什么不同?
(b)描述边界问题和导弹隐喻的含义。
“导弹隐喻”问题(Missile Metaphor Problem): 导弹和反导弹相互瞄准,然后相互错过。
“传统的”双向搜索试图存储来自向前和向后搜索两端的节点来寻求解。传统的方法将使用最佳优先搜索,并且当两端试图“发现彼此”时,就会陷入指数级存储需求的泥潭。这就是所谓的边界问题(frontiers problem)。
(c)什么是波形规整算法?
波形规整(wave-shaping)算法,其思想是使两个搜索的“波前”(wave-front)朝向彼此。
— LeetCode_博弈
题单
标签 为 博弈 的题
292. Nim 游戏
题目链接
假设当前的石头数目为 x ,如果 x 为 4 的倍数时,则此时你必然会输掉游戏;
如果 x 不为 4 的倍数时,则此时你只需要取走 x mod 4 个石头时,则剩余的石头数目必然为 4 的倍数,从而对手会输掉游戏。
class Solution:def canWinNim(self, n: int) -> bool:return n % 4 != 0
375. 猜数字大小 II 【动态规划】 ⟮ O ( n 3 ) 、 O ( n 2 ) ⟯ \lgroup O(n^3)、O(n^2) \rgroup ⟮O(n3)、O(n2)⟯
题目链接

题解
class Solution:def getMoneyAmount(self, n: int) -> int:dp = [[0] * (n + 1) for _ in range(n + 1)]for i in range(n - 1, 0, -1):for j in range(i + 1, n + 1):dp[i][j] = j + dp[i][j - 1]for k in range(i, j):dp[i][j] = min(dp[i][j], k + max(dp[i][k - 1], dp[k + 1][j]))return dp[1][n]

486. 预测赢家 【动态规划】 ⟮ O ( n 2 ) 、 O ( n ) ⟯ \lgroup O(n^2)、O(n) \rgroup ⟮O(n2)、O(n)⟯
题目链接

class Solution:def predictTheWinner(self, nums: List[int]) -> bool:# dp[i][j] : 当数组剩下的部分为下标 i 到 下标 j 时, 当前玩家与 另一玩家 的分数之差 的最大值。 !!当家玩家 不一定是 先手。# n = len(nums)dp = [0] * n for i, num in enumerate(nums): # i == j, 只剩一个数, 当前玩家 选dp[i] = num for i in range(n - 2, -1, -1):for j in range(i + 1, n):dp[j] = max(nums[i] - dp[j], nums[j] - dp[j - 1])return dp[n - 1] >= 0

464. 我能赢吗 【记忆化搜索 + 状态压缩】 ⟮ O ( 2 n ⋅ n ) 、 O ( 2 n ) ⟯ \lgroup O(2^n · n)、O(2^n) \rgroup ⟮O(2n⋅n)、O(2n)⟯
题目链接
class Solution:def canIWin(self, maxChoosableInteger: int, desiredTotal: int) -> bool:# !!!两者 抽到的数 都要 加到 total 里# 先手 玩家。 要是 最大值 大于等于 desiredTotal, 先手必赢if maxChoosableInteger >= desiredTotal:return True # 要是 总和 小于 desiredTotal, 则必为 False ,即 先手没赢if maxChoosableInteger * (maxChoosableInteger + 1) // 2 < desiredTotal:return False # 剩余 情形@cache def dfs(usedNumbers, currentTotal):for i in range(1, maxChoosableInteger + 1): # 注意 范围if (usedNumbers >> i) & 1 == 0: # 数 i 没被选# 当前玩家 再选一个 就胜利。 或 让 下一个玩家 下一轮 无法获胜。if currentTotal + i >= desiredTotal or not dfs(usedNumbers | (1 << i), currentTotal + i):return True return False return dfs(0, 0)

810. 黑板异或游戏
题目链接

class Solution:def xorGame(self, nums: List[int]) -> bool:# 如果擦除一个数字后,剩余的所有数字按位异或运算得出的结果等于 0 的话,当前玩家游戏失败。# 如果初始时黑板上所有数字异或结果等于 0,则 Alice 获胜。# 当 数组 的长度 为 偶数, 先手必胜return len(nums) % 2 == 0 or reduce(xor, nums) == 0# reduce: 从 nums 中 依次取 2 个 元素 进行 函数 xor 计算, 结果 插入 nums 前面,继续 取 前两个 元素 进行 xor 运算。 实现: nums 全部元素的 xor 结果

1686. 石子游戏 VI
题目链接
class Solution:def stoneGameVI(self, aliceValues: List[int], bobValues: List[int]) -> int:# 拿 综合 最高的total_value = [a + b for a, b in zip(aliceValues, bobValues)]total_value.sort(reverse = True) # 降序# # 所有Alice能拿到的石头的总价值,其中每个都多拿了Bob的对应石子,再减去本来就是Bob拿的石子,正好是Bob的所有石子diff = sum(total_value[::2]) - sum(bobValues) # alice 比 bob 多的 if diff > 0:return 1 # Alice 赢elif diff == 0:return 0 # 平局else:return -1 # Bob 赢# 假设 排序后 a0 + b0 a1 + b1 a2 + b2 a3 + b3# Alice a0 a2# Bob b1 b3# diff = ( a0 + a2 ) - (b1 + b3) # = ( a0 + b0 + a2 + b2) - (b0 + b2 + b1 + b3) # Alice 先手拿了,对方无法再拿对应位置的。只能拿剩下位置的
别的有空再补。