一、概述
1、k8s有时候会报错The connection to the server ip:6443 was refused - did you specify the right host or port ,本文档提供几种可能产生该报错的原因和排障思路。
二、发现问题
使用任意Kubectl 命令会报错:The connection to the server ip:6443 was refused - did you specify the right host or port
三、可能原因
情况一:集群硬件时间和系统时间不同步,在重启服务器后系统时间会同步硬件时间,集群的时间管理混乱,进而导致此类问题
情况二:查看端口是否被占用或者是否被防火墙、iptables这些拦截下来了
情况三:更改主机名或者服务器重启后出现此报错
情况四:通用排查
四、处理方案
情况一解决方案:此类现象需要重新更改系统时间并把硬件时间和软件时间同步
systemctl status kubelet #首先检查服务是否启动有无报错,如果服务报错进行排查
date #确认系统时间
hwclock #确认硬件 #如果此时系统时间和硬件时间同步,但明显不是服务器重启之前的时间。请继续往下看。否则就不是本情况,请查看其他案例。
date -s "2023-03-25 12:00:00" #首先进行系统时间的修改
hwclock --hctosys #然后用硬件时钟同步系统时钟
timedatectl |awk -F":" '/synchronized/{print $2}' #检查ntp时间同步是否就绪,一般等待20-30分钟左右后会显示yes
kubectl get node #检查是否还会报错

情况二:处理方案
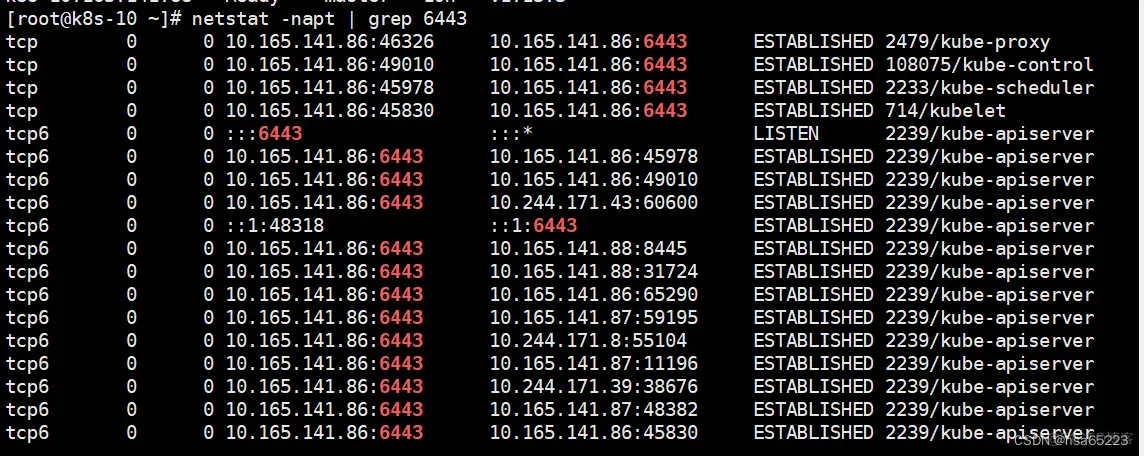
systemctl status kubelet #首先检查服务是否启动有无报错,如果服务报错请进行排查 netstat -napt | grep 6443 #首选确认端口是否被占用 #如果使用firewalld服务,通过firewall添加相应的端口来解决问题
systemctl enable firewalld|
systemctl start firewalld|
firewall-cmd --permanent --add-port=6443/tcp|
firewall-cmd --permanent --add-port=2379-2380/tcp|
firewall-cmd --permanent --add-port=10250-10255/tcp|
firewall-cmd –reload #iptables相关规则/做过相关的安全加固等措施禁用了端口
iptables -nL #查看是否存在6443端口相关规则被禁止,如果出现相关的问题,进行相关排查 kubectl get node #检查是否还会报错
情况三:处理方案
systemctl status kubelet #首先检查服务是否启动有无报错,如果服务报错进行排查
1、通用方案
#重新声明环境变量
ll /etc/kubernetes/admin.conf #查看文件是否存在,如果不存在执行下面的步骤
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile #重新写入环境变量
source ~/.bash_profile
2、containerd容器解决方案
systemctl restart kubelet #尝试重启kubelet测试是否可以重新恢复正常
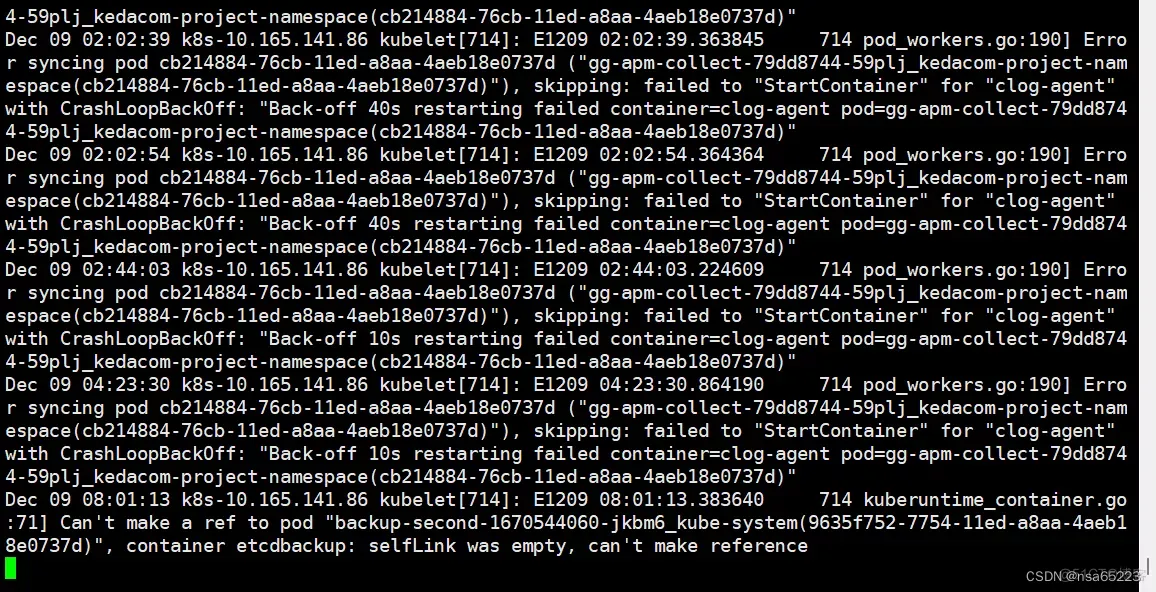
journalctl -xefu kubelet #查看kubelet的日志,里面寻找相应报错
nerdctl -n k8s.io ps #根据iomp版本是用docker或者nerdctl,来查看k8s容器状态 确认相关k8s容器是否正常,如果容器出现异常,进行相关排查
kubectl get node #检查是否还会报错
情况四:解决方案
systemctl status kubelet #首先检查服务是否启动有无报错
journalctl -u kubelet #如果kubelet报错请查看相关日志 #首先确认aip-server有没有挂,如果挂了去查看日志
nerdctl -n k8s.io ps | grep kube-apiserver
docker ps -a | grep kube-apiserver
cd /var/log/pods/kube-system_kube-apiserver # (此处使用tab补全,进入后查看相应的日志报错,根据相应日志去处理对应问题) #接着确认etcd是否挂了,可以去查看相应的报错日志 docker ps -a | grepetcd
nerdctl -n k8s.io ps | grep etcd
cd /var/log/pods/kube-system_etcd #(此处使用tab补全,进入后查看相应的日志报错,根据相应日志去处理对应问题)
kubectl get node #问题初完成后检查是否还会报错